
We are excited to announce that StreamNative and OVHcloud are open-sourcing “Kafka on Pulsar" (KoP). KoP brings the native Apache Kafka protocol support to Apache Pulsar by introducing a Kafka protocol handler on Pulsar brokers. By adding the KoP protocol handler to your existing Pulsar cluster, you can now migrate your existing Kafka applications and services to Pulsar without modifying the code. This enables Kafka applications to leverage Pulsar’s powerful features, such as:
- Streamlined operations with enterprise-grade multi-tenancy
- Simplified operations with a rebalance-free architecture
- Infinite event stream retention with Apache BookKeeper and tiered storage
- Serverless event processing with Pulsar Functions
What is Apache Pulsar?
Apache Pulsar is an event streaming platform designed from the ground up to be cloud-native deploying a multi-layer and segment-centric architecture. The architecture separates serving and storage into different layers, making the system container-friendly. The cloud-native architecture provides scalability, availability and resiliency and enables companies to expand their offerings with real-time data-enabled solutions. Pulsar has gained wide adoption since it was open-sourced in 2016 and was designated an Apache Top-Level project in 2018.
The Need for KoP
Pulsar provides a unified messaging model for both queueing and streaming workloads. Pulsar implemented its own protobuf-based binary protocol to provide high performance and low latency. This choice of protobuf makes it convenient to implement Pulsar clients and the project already supports Java, Go, Python and C++ languages alongside third-party clients provided by the community. However, existing applications written using other messaging protocols had to be rewritten to adopt Pulsar’s new unified messaging protocol.
To address this, the Pulsar community developed applications to facilitate the migration to Pulsar from other messaging systems. For example, Pulsar provides a Kafka wrapper on Kafka Java API, allows existing applications that already use Kafka Java Client to switch from Kafka to Pulsar without code change. Pulsar also has a rich connector ecosystem, connecting Pulsar with other data systems. Yet, there was still a strong demand from those looking to switch from other Kafka applications to Pulsar.
StreamNative and OVHcloud's collaboration
StreamNative was receiving a lot of inbound requests for help migrating from other messaging systems to Pulsar and recognized the need to support other messaging protocols (such as AMQP and Kafka) natively on Pulsar. StreamNative began working on introducing a general protocol handler framework in Pulsar that would allow developers using other messaging protocols to use Pulsar.
Internally, OVHcloud had been running Apache Kafka for years. Despite their experience in operating multiple clusters with millions of messages per second on Kafka, they met painful operational challenges. For example, putting thousands of topics from thousands of users into a single cluster was difficult without multi-tenancy.
As a result, OVHcloud decided to shift and build the foundation of their topic-as-a-service product, called ioStream, on Pulsar instead of Kafka. Pulsar’s multi-tenancy and the overall architecture with Apache Bookkeeper simplified operations compared to Kafka.
After spawning the first region, OVHcloud decided to implement it as a proof-of-concept proxy capable of transforming the Kafka protocol to Pulsar on the fly. They encountered some issues, mainly on how to simulate and manipulate offsets and consumer groups as they did not have access to low-level storage details. During this process, OVHcloud discovered that StreamNative was working on bringing the Kafka protocol natively to Pulsar, and they joined forces to develop KoP.
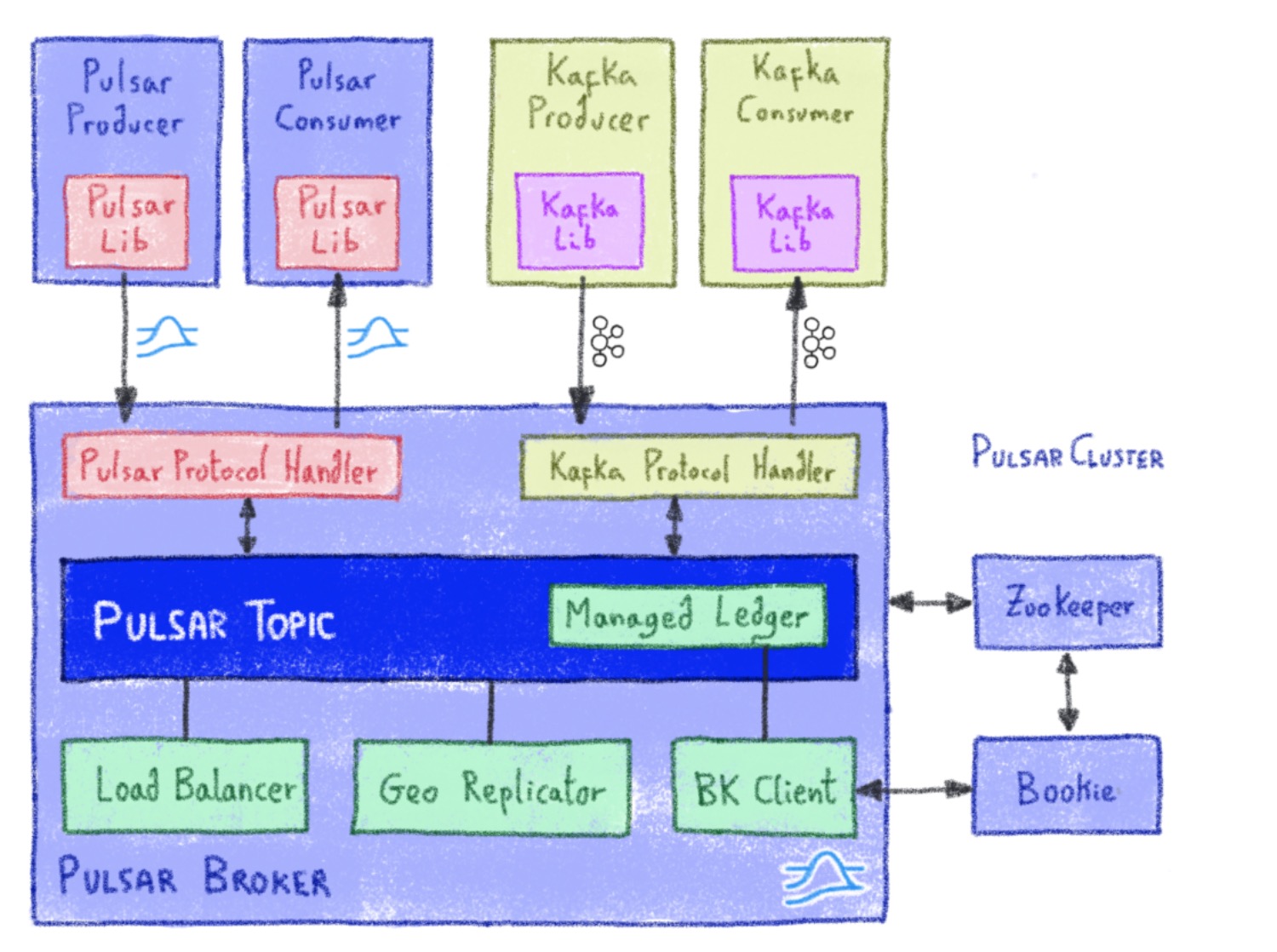
KoP was developed to provide a streamlined and comprehensive solution leveraging Pulsar and BookKeeper’s event stream storage infrastructure and Pulsar’s pluggable protocol handler framework. KoP is implemented as a protocol handler plugin with protocol name "kafka". It can be installed and configured to run as part of Pulsar brokers.
Distributed log
Both Pulsar and Kafka share a very similar data model around log for both pub/sub messaging and event streaming. For example, both are built on top of a distributed log. A key difference between these two systems is how they implement the distributed log. Kafka implements the distributed log in a partition-basis architecture, where a distributed log (a partition in Kafka) is designated to store in a set of brokers, while Pulsar deploys a segment-based architecture to implement its distributed log by leveraging Apache BookKeeper as its scale-out segment storage layer. Pulsar’s segment based architecture provides benefits such as rebalance-free, instant scalability, and infinite event stream storage. You can learn more about the key differences between Pulsar and Kafka in this Splunk blog and in this blog from the Bookkeeper project.
Since both of the systems are built on a similar data model, a distributed log, it is very simple to implement a Kafka-compatible protocol handler by leveraging Pulsar’s distributed log storage and its pluggable protocol handler framework (introduced in the 2.5.0 release).
Implementation
The implementation is done by comparing the protocols between Pulsar and Kafka. We found that there are a lot of similarities between these two protocols. Both protocols are comprised of the following operations:
- Topic Lookup: All the clients connect to any broker to lookup the metadata (i.e. the owner broker) of the topics. After fetching the metadata, the clients establish persistent TCP connections to the owner brokers. Produce: The clients talk to the owner broker of a topic partition to append the messages to a distributed log.
- Consume: The clients talk to the owner broker of a topic partition to read the messages from a distributed log.
- Offset: The messages produced to a topic partition are assigned with an offset. The offset in Pulsar is called MessageId. Consumers can use offsets to seek to a given position within the log to read messages.
- Consumption State: Both systems maintain the consumption state for consumers within a subscription (or a consumer group in Kafka). The consumption state is stored in __offsets topic in Kafka, while the consumption state is stored as cursors in Pulsar.
As you can see, these are all the primitive operations provided by a scale-out distributed log storage such as Apache BookKeeper. The core capabilities of Pulsar are implemented on top of Apache BookKeeper. Thus it is pretty easy and straightforward to implement the Kafka concepts by using the existing components that Pulsar has developed on BookKeeper.
The following figure illustrates how we add the Kafka protocol support within Pulsar. We are introducing a new Protocol Handler which implements the Kafka wire protocol by leveraging the existing components (such as topic discovery, the distributed log library - ManagedLedger, cursors and etc) that Pulsar already has.
Topic
In Kafka, all the topics are stored in one flat namespace. But in Pulsar, topics are organized in hierarchical multi-tenant namespaces. We introduce a setting kafkaNamespace in broker configuration to allow the administrator configuring to map Kafka topics to Pulsar topics.
In order to let Kafka users leverage the multi-tenancy feature of Apache Pulsar, a Kafka user can specify a Pulsar tenant and namespace as its SASL username when it uses SASL authentication mechanism to authenticate a Kafka client.
Message ID and offset
In Kafka, each message is assigned with an offset once it is successfully produced to a topic partition. In Pulsar, each message is assigned with a MessageID. The message id consists of 3 components, ledger-id, entry-id, and batch-index. We are using the same approach in Pulsar-Kafka wrapper to convert a Pulsar MessageID to an offset and vice versa.
Message
Both a Kafka message and a Pulsar message have key, value, timestamp, and headers (note: this is called ‘properties’ in Pulsar). We convert these fields automatically between Kafka messages and Pulsar messages.
Topic lookup
We use the same topic lookup approach for the Kafka request handler as the Pulsar request handler. The request handler does topic discovery to lookup all the ownerships for the requested topic partitions and responds with the ownership information as part of Kafka TopicMetadata back to Kafka clients.
Produce Messages
When the Kafka request handler receives produced messages from a Kafka client, it converts Kafka messages to Pulsar messages by mapping the fields (i.e. key, value, timestamp and headers) one by one, and uses the ManagedLedger append API to append those converted Pulsar messages to BookKeeper. Converting Kafka messages to Pulsar messages allows existing Pulsar applications to consume messages produced by Kafka clients.
Consume Messages
When the Kafka request handler receives a consumer request from a Kafka client, it opens a non-durable cursor to read the entries starting from the requested offset. The Kafka request handler converts the Pulsar messages back to Kafka messages to allow existing Kafka applications to consume the messages produced by Pulsar clients.
Group coordinator & offsets management
The most challenging part is to implement the group coordinator and offsets management. Because Pulsar doesn’t have a centralized group coordinator for assigning partitions to consumers of a consumer group and managing offsets for each consumer group. In Pulsar, the partition assignment is managed by broker on a per-partition basis, and the offset management is done by storing the acknowledgements in cursors by the owner broker of that partition.
It is difficult to align the Pulsar model with the Kafka model. Hence, for the sake of providing full compatibility with Kafka clients, we implemented the Kafka group coordinator by storing the coordinator group changes and offsets in a system topic calledpublic/kafka/__offsets in Pulsar. This allows us to bridge the gap between Pulsar and Kafka and allows people to use existing Pulsar tools and policies to manage subscriptions and monitor Kafka consumers. We add a background thread in the implemented group coordinator to periodically sync offset updates from the system topic to Pulsar cursors. Hence a Kafka consumer group is effectively treated as a Pulsar subscription. All the existing Pulsar toolings can be used for managing Kafka consumer groups as well.
Bridge two popular messaging ecosystems
At both companies, we value customer success. We believe that providing a native Kafka protocol on Apache Pulsar will reduce the barriers for people adopting Pulsar to achieve their business success. By integrating two popular event streaming ecosystems, KoP unlocks new use cases. Customers can leverage advantages from each ecosystem and build a truly unified event streaming platform with Apache Pulsar to accelerate the development of real-time applications and services.
With KoP, a log collector can continue collecting log data from its sources and producing messages to Apache Pulsar using existing Kafka integrations. The downstream applications can use Pulsar Functions to process the events arriving in the system to do serverless event streaming.
Try it out
KoP is open sourced under Apache License V2 in https://github.com/streamnative/kop. It is available as part of StreamNative Platform. You can download the StreamNative platform to try out all the features of KoP. If you already have a Pulsar cluster running and would like to enable Kafka protocol support on it, you can follow the instructions to install the KoP protocol handler to your existing Pulsar cluster.
Here is more information on KoP code and document. We are looking forward to your issues, and PRs. You can also join #kop channel in Pulsar Slack to discuss all things about Kafka-on-Pulsar.
StreamNative and OVHcloud are also hosted a webinar on KoP. You can watch the recording here.

Thanks
The KoP project was originally initiated by StreamNative. The OVHcloud team joined the project to collaborate on the development of the KoP project. Many thanks to Pierre Zemb and Steven Le Roux from OVHcloud for their contributions to this project!
Have something to say about this article? Share it with us on Twitter or contact us.






