
Elasticity is fundamental to cloud-native computing, enabling businesses to rapidly scale, enhance system resilience, and reduce costs. At StreamNative, we cater to a wide range of customers who demand robust and cost-efficient data infrastructure. They seek a genuinely cloud-native data streaming platform that seamlessly scales across global data centers without the complexity of implementation.
To satisfy the need for modern streaming data pipelines, we developed Apache Pulsar with a cloud-native architecture designed to significantly enhance the platform's horizontal scalability. We didn't just improve it; we revolutionized it, boosting Apache Pulsar's elasticity by 100x to even 1000x, compared to other data streaming technologies such as Apache Kafka. But what exactly did we do to achieve such a leap in performance?
Understanding How Apache Kafka Scales
To comprehend why Apache Pulsar is 100x or 1000x more elastic than Kafka, it is crucial to understand how Apache Kafka scales.
Consider a cluster consisting of three brokers. This cluster retains messages for 30 days and receives an average of 100 MBps from its producers. With a replication factor of three, the cluster holds up to 777.6 TB of storage, approximately 259.2 TB per broker if evenly distributed.
When the cluster is expanded by adding another broker to increase capacity, the dynamics change. Now with four brokers, the new broker must be integrated to start handling reads and writes. Assuming optimal data balancing, this new broker would need to store about 194.4 TB (777.6 TB divided by 4), which must be transferred from the existing brokers. On a 10 gigabit network, this data rebalance would take about 43 hours using Apache Kafka, and potentially even longer in practical scenarios.
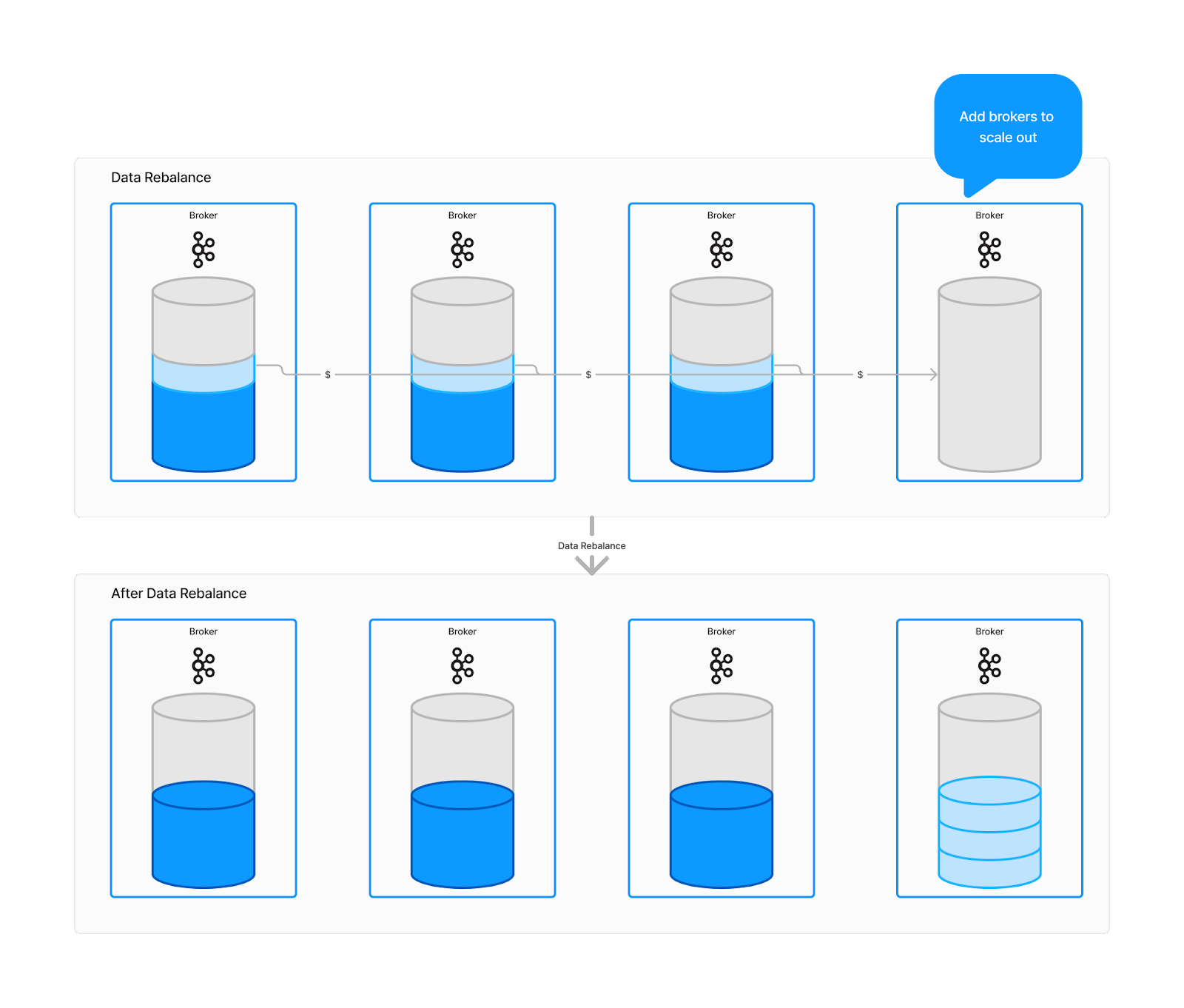
Delivering 1000x elasticity with Apache Pulsar
With Apache Pulsar, scaling up is 1000x faster than with Apache Kafka—without the typical burdens of capacity planning, data rebalancing, or other operational challenges involved in scaling streaming data infrastructure. The key to this 1000x elasticity is Apache Pulsar’s rebalance-free architecture.
In Apache Kafka, the capabilities of data serving and data storage are bound together on the same machines. This setup requires data rebalancing and movement whenever the cluster topology changes, such as when adding new nodes, removing old nodes, or when nodes fail. This data movement and rebalancing can be minimized but is often inevitable.
In contrast, Apache Pulsar decouples data serving and storage into two distinct layers: the serving and storage layers. This allows for independent scalability based on capacity needs without the risk of overprovisioning. Crucially, Pulsar uses a segment-based storage architecture that does not require data rebalancing when scaling up storage.
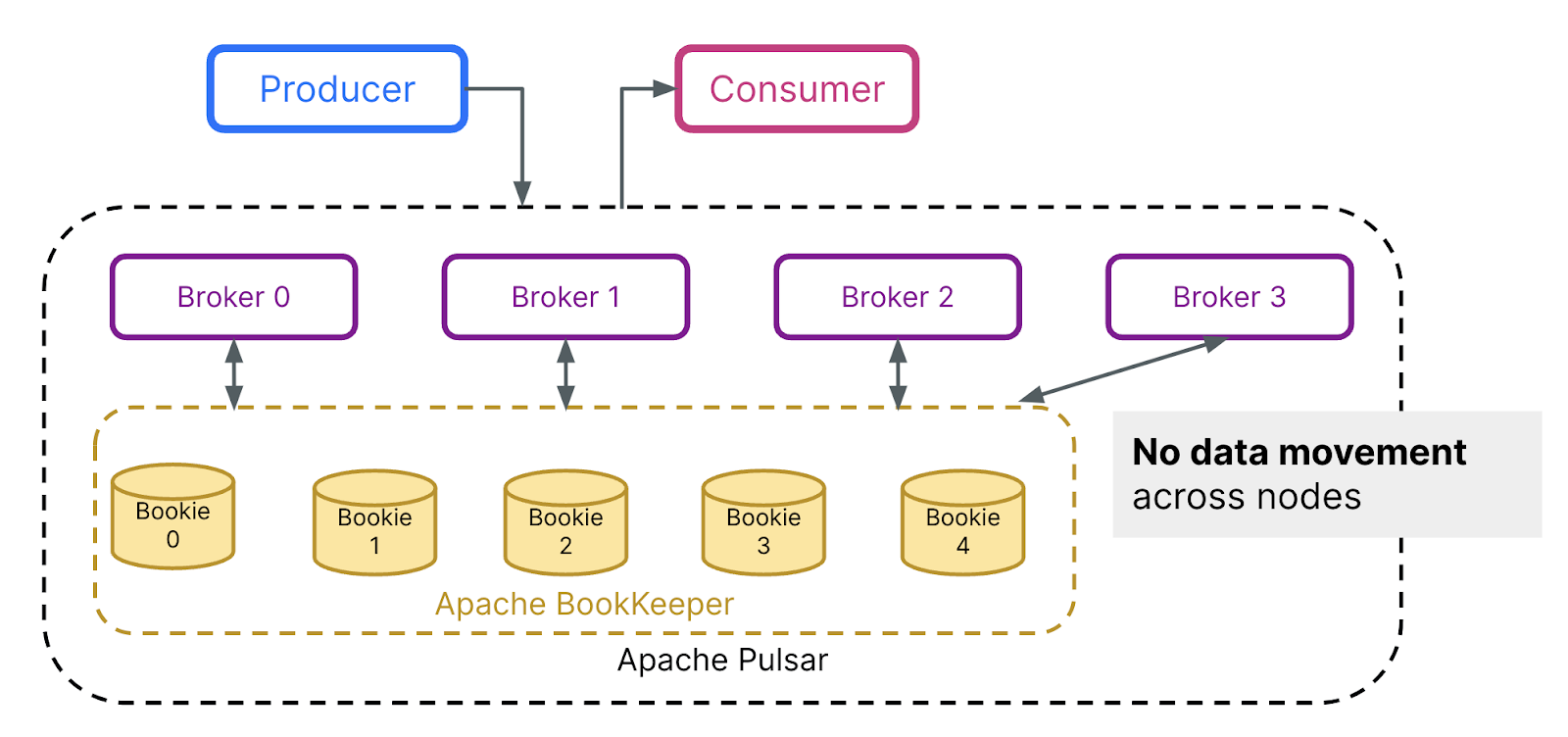
So how does this work in practice? Brokers in Apache Pulsar divide the partitions into segments, which are evenly distributed across storage nodes. The location metadata of these segments is stored in a metadata storage for rapid access. Adding a broker is straightforward and immediate, as there is no actual data rebalancing or movement—since the data resides in the storage layer. Pulsar simply needs to rebalance the ownership of a given topic, which typically takes just seconds and involves only metadata retrieval. Similarly, adding a storage node is both easy and instantaneous. It does not affect the topic ownership at the broker layer, nor is there a need to move old segments from existing storage nodes to the new one. New data segments are immediately allocated in the newly added nodes, allowing for instant scalability.
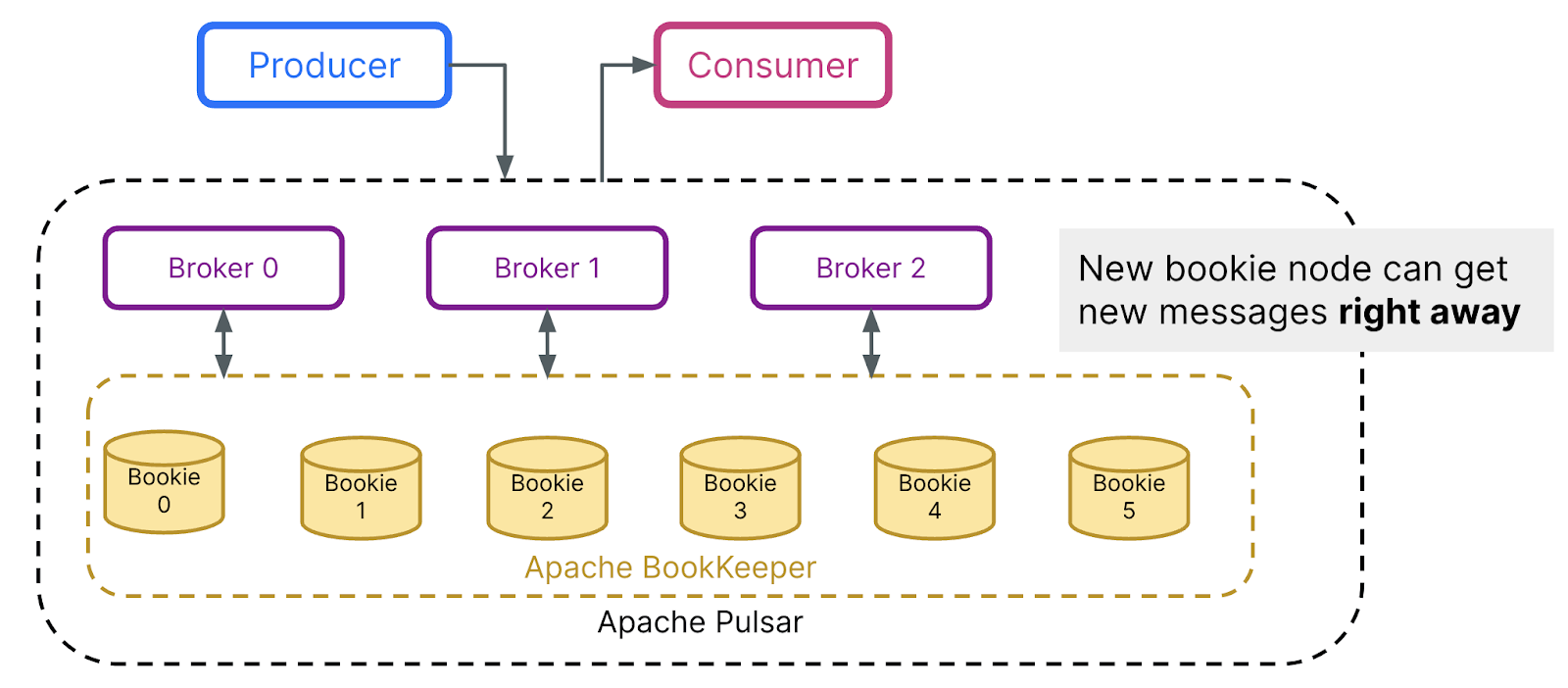
When scaling the Pulsar cluster, the operation begins as soon as the system is prompted for more resources. The entire process is conducted online, meaning there is no downtime, no data rebalancing, and no service degradation. Typically, the complete scaling operation can be completed within a minute. Compared to the 43 hours required with Apache Kafka, this represents an improvement of up to 2580x faster! In reality, scaling an Apache Kafka cluster can take a couple of days, and it usually makes the clusters unavailable during the rebalance period.
Mitigating Data Rebalancing Impact with Tiered Storage
Many Kafka vendors aim to enhance elasticity by integrating various forms of tiered storage, which utilize multiple layers of cloud storage and workload heuristics to accelerate data rebalancing and movement. However, tiering data involves significant trade-offs between cost and performance, as efficiently moving data among in-memory caches, local disks, and object storage is a complex task. Despite these efforts, tiered storage doesn’t eliminate the need for data rebalancing during scaling events.
The strategy relies on the principle that faster data movement within the system equates to quicker scaling. For instance, consider a scenario where Kafka brokers store most of their data in object storage, keeping only a small fraction on local disks. Assuming a dynamic ratio where one day’s worth of data resides on local disks and the remainder in object storage—about a 1-to-30 ratio:
In this setup, each broker holds 8.6 TB locally and 251.6 TB in object storage. When the cluster is scaled up by adding a broker, tiered storage significantly reduces the amount of data that needs to be moved—only the data on physical brokers (resulting in 6.5 TB total, or 2.2 TB per broker) along with minimal references to the data in object storage. On a 10 Gigabit network, the scaling operation might only take 1.4 hours, which is up to 30 times faster than Kafka without tiered storage. Yet, when compared to Apache Pulsar, which requires no data rebalancing, it is still 84 times slower.
Apache Pulsar also incorporates tiered storage, being the first data streaming system in the market to do so. This feature allows for longer data retention in more cost-effective storage solutions, although it is not designed to address the inherent limitations of data streaming architectures that require data rebalancing during scaling events.
The Hidden Costs of Data Rebalancing
Removing data rebalancing from an architecture doesn't only speed up scaling; it also eradicates the associated hidden costs. These costs include:
- Cross-AZ networking costs during data rebalancing
- Labor costs for managing data rebalancing operations
- Infrastructure and licensing costs for tools and automatic data rebalancers from Kafka vendors.
For instance, in a typical Kafka setup managing 194.4 TB of data on local disks that needs rebalancing data across three zones, approximately two-thirds of the traffic is cross-AZ during scaling events. This generates costs of around $2,654 per scaling operation, potentially higher with larger clusters.
Additionally, a Site Reliability Engineer (SRE) or operator, costing on average $140,000 annually in the US (~$50 per hour), may spend 43 hours on a rebalance operation, adding roughly $2,150 to each event. Although the SRE may not dedicate 100% of their time exclusively to data rebalancing, this process often leads to service degradation and unavailability. The duration of these interruptions can extend to a few days, depending on the volume of data flowing into the clusters, and significantly affect availability. Such disruptions can have a substantial impact on business revenue and divert the SRE's focus from other responsibilities. Consequently, in most cases, SREs find themselves primarily engaged in managing and executing these data rebalancing events.
Disregarding the cost implications of service degradation and unavailability caused by data rebalancing, and focusing solely on the combined networking and labor costs, a single scaling event could cost nearly $5,000. If scaling events occur monthly, both up and down, the total annual expense could amount to $120,000.
While optimizing the work of an SRE with open-source tools or purchasing vendor solutions for automatic rebalancing might reduce some expenses, it still represents a significant cost.
Conversely, by adopting a rebalance-free platform like Apache Pulsar, these costs are almost eliminated. This allows organizations to reallocate capital towards developing and enhancing business applications, speeding up time to market significantly.
Elasticity is beyond faster scaling
Making Apache Pulsar 1000x more elastic than Apache Kafka doesn't only enhance the speed of scaling. With the fully managed Apache Puslar services like StreamNative, it also automates the operations and facilitates the reduction of cluster size when demand decreases, increases resilience against failures, and reduces the total cost of ownership.
Adapting to Changing Workloads
After peak periods like the holiday rush, you wouldn’t want an excessively provisioned cluster continuing to incur costs. Unlike teams using Apache Kafka, who face limited and time-consuming options for resizing—requiring complex processes of sizing, provisioning new clusters, setting up networks, and balancing traffic across brokers and partitions—Pulsar's architecture supports quick and efficient scaling both up and down. Often, the effort involved in Kafka systems does not justify the savings from operating a smaller cluster, leading to costly excess capacity just to avoid downtime risks.
Resiliency Through Elastic Rebalance-Free Architecture
In the cloud, rapid response to failures is crucial. Apache Pulsar’s elastic nature ensures resilience by promptly addressing failures. For instance, managing a broker node failure is as simple as transferring topic ownership without moving any data. If a storage node fails or a service volume slows down, Pulsar's storage layer automatically detects and starts to decommission the faulty node, re-replicating data to functioning nodes—all without client disruption. This capability is pivotal, as Pulsar’s architecture requires no data rebalancing when cluster topology changes.
Upgrades also benefit from this elasticity. With no need for data rebalancing, Pulsar’s clusters are more agile, allowing for rapid system-wide updates, such as during critical vulnerabilities like the log4j issue, with no downtime. These frequent, disruption-free updates prevent costly outages and security breaches.
Broker Autoscaling
Leveraging its rebalance-free architecture, Apache Pulsar efficiently adapts to fluctuating workloads by easily scaling its brokers. Although Site Reliability Engineering (SRE) teams often integrate systems like Kubernetes' Horizontal Pod Scaler to maximize this architecture, StreamNative Cloud simplifies the process with its built-in auto-scaling features. These features dynamically adjust resources in response to changes in workload, capable of managing abrupt increases in traffic or downscaling during quieter periods to optimize resource utilization and performance. Additionally, auto-scaling enhances load balancing across brokers, distributing message processing loads evenly and preventing any single broker from becoming a bottleneck, thereby enhancing system reliability and maintaining high throughput and low latency even under heavy load conditions.
Reducing Total Cost of Ownership
Combining these features, Pulsar’s rebalance-free data streaming architecture not only speeds up elasticity but also substantially lowers the total cost of ownership. This enables users to:
- Avoid Over-Provisioning: Unlike Kafka, which requires clusters to be provisioned for peak usage well in advance, Pulsar can scale up just hours before needed, avoiding weeks of unutilized capacity. Similarly, it can quickly scale down, saving costs on unnecessary capacity.
- Deliver Faster, More Cost-Effective Service: Leveraging a rebalance-free architecture and object storage for tiered storage, Pulsar provides services at lower latency and competitive prices.
- Eliminate Unnecessary Operational Efforts: Scaling with StreamNative can be automated using Kubernetes Operators or simply done with a click in the Cloud Console, freeing up engineering resources from routine tasks to focus on innovation and unique business solutions.
These aspects highlight how Apache Pulsar not only enhances operational efficiency but also positions businesses for better agility and economic performance.
With StreamNative Cloud, you can access a cloud-native data streaming platform that is fully compatible with Kafka but offers elastic scaling, resiliency in the face of failure, and a lower total cost of ownership, all powered by a rebalance-free architecture.
To experience how StreamNative Cloud scales faster than Apache Kafka by leveraging a rebalance-free architecture, sign up for a free trial.




