
This past Saturday marked an eventful day in Beijing, as we hosted a one-day gathering dedicated to Apache Pulsar. Known as "Apache Pulsar Meetup Beijing 2023," this event served as a condensed version of the renowned Pulsar Summit APAC. It's been four years since we convened the very first in-person "Apache Pulsar Meetup Beijing" in collaboration with Tencent and Yahoo! JAPAN back in 2019. Despite the numerous virtual Pulsar Summits held during the pandemic, there was palpable excitement in bringing together the APAC community once again to delve into the world of Apache Pulsar and real-time data streaming.
Held in the heart of Beijing, this meetup drew approximately 100 in-person attendees, featuring adoption stories and best practices from tech giants such as Tencent, WeChat, Didi, Huawei, and Zhaopin.com. These companies are operating Pulsar at a large scale in their production environments. The event boasted a total of 12 engaging talks, each led by domain experts.
Without further ado, let's explore the highlights of this gathering.

Pulsar 3.0 and Beyond
Matteo Merli, the co-creator of Pulsar and the CTO of StreamNative, set the stage by sharing his inspirational journey of initiating Pulsar at Yahoo. He also narrated how the Pulsar community transformed Pulsar from a distributed pub-sub messaging platform into a multi-protocol streaming data platform. This metamorphosis led to Pulsar's full compatibility with other popular messaging and streaming protocols, including the likes of Kafka, AMQP, and MQTT. An interesting tidbit he shared was that Apache Pulsar was the pioneer in introducing the concept of tiered storage – a feature that has since been emulated by the competition, such as Kafka, Confluent, and Redpanda.
Matteo then pulled the curtain back on Pulsar 3.0, giving us a peek at the innovations and features nestled within this momentous release.
Pulsar 3.0 marked the introduction of the Long Term Support (LTS) release model, designed to provide prolonged support for releases. This approach aims to free users from the constant pressure of upgrading while still paving the way for rapid innovation to make Pulsar even more powerful.
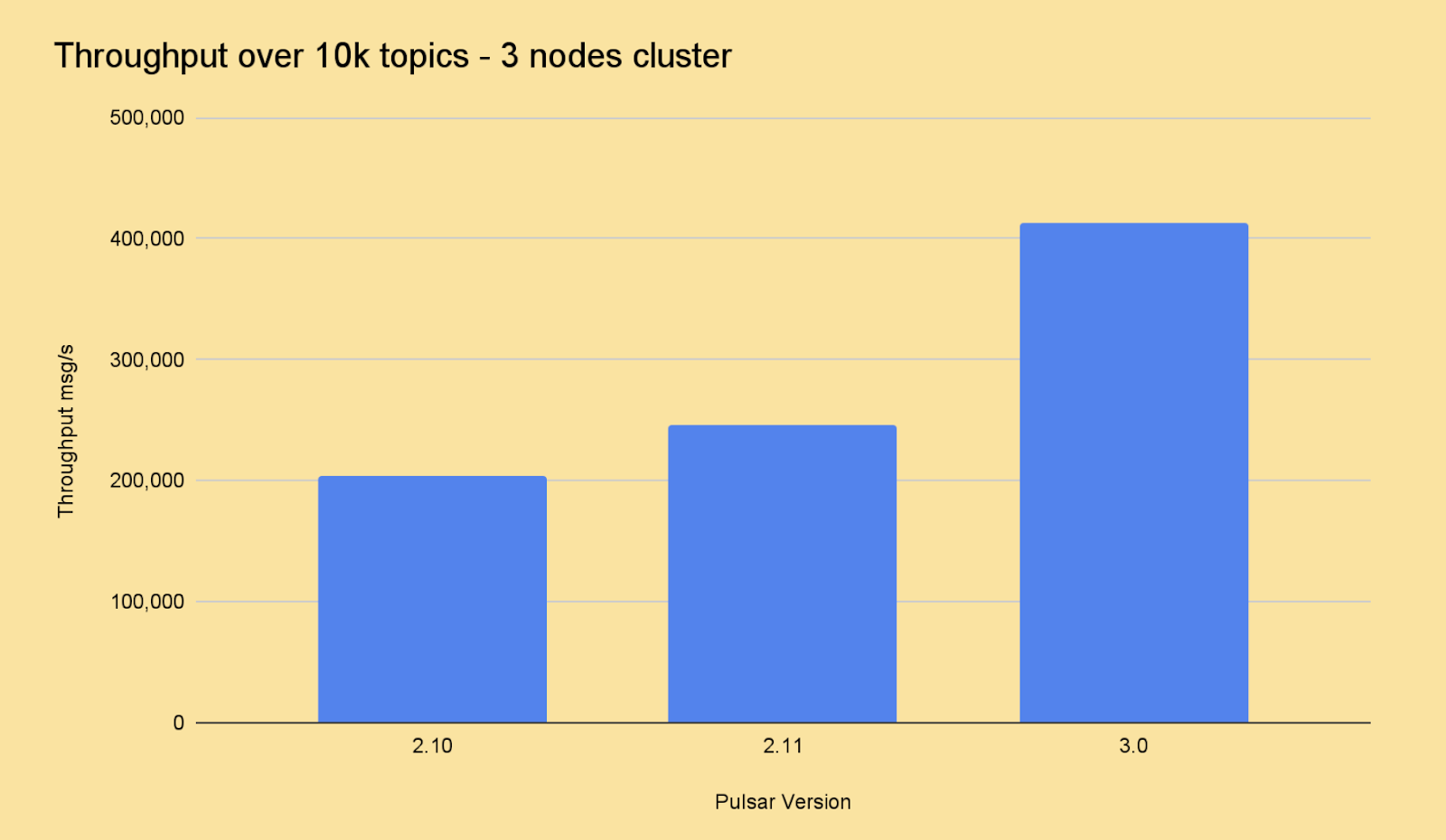
Interestingly, Pulsar 3.0 also introduced BookKeeper 4.16, which came with numerous improvements aimed at decreasing both CPU usage and contention. These enhancements resulted in a remarkable boost in throughput and latency, particularly in scenarios involving numerous topics and scenarios where message batching was either ineffective or disabled. To put this into perspective, it almost doubled throughput when compared to running Pulsar 2.10 on a modest 3-node cluster housing over 10,000 topics.
Pulsar 3.0 didn't stop there; it introduced features such as scalable delayed delivery, a novel load balancer, and support for multi-arch images. These additions promised to elevate Pulsar's performance and user-friendliness across a spectrum of use cases.
While Pulsar 3.0 represents a significant milestone, there are exciting innovations looming on the horizon. Matteo divulged that the Pulsar community's focal point is enhancing the user experience, scaling Pulsar to handle an excess of 1 million topics efficiently, and possibly even accommodating 10 million or 100 million topics to unlock previously unattainable use cases. The advent of Oxia, a scalable metadata storage solution crafted for modern cloud-native ecosystems, is set to tackle metadata and coordination challenges at an unprecedented scale. Furthermore, there is a concerted effort to address issues concerning metrics, service discovery, and session establishment within expansive clusters.
Pulsar 3.0 has inaugurated a new chapter in Pulsar's release management, with a plethora of improvements already introduced in 3.0 and 3.1, and many more slated for 2024. The Pulsar community now stands better equipped to expedite the delivery of features and enhancements, all while ensuring robustness and quality.
Session Highlights
Attempting to encapsulate all the sessions and panel discussions within the confines of a single blog post would be a Herculean task. Fret not, though – in a week's time, you can revisit this page here to catch all the session recordings. In the interim, here's a sneak peek at some overarching themes encompassing use cases, deep dives into technology, and the ecosystem.
Message Queue Emerges as Pulsar's Killer Use Case
Were you aware that Didi, China's ridesharing giant, has harnessed the power of Apache Pulsar for several years to enrich the real-time experience for both its drivers and passengers? Qiang Huang from Didi graced the stage and regaled the audience with Didi's evolution from Kafka to RocketMQ, and eventually to Pulsar within their DDMQ (Didi Message Queue) platform. The DDMQ platform now spans thousands of machines, serving over 10,000 topics and processing trillions of messages daily, with peak traffic reaching a staggering 10 million messages per second. Remarkably, the DDMQ platform boasts a staggering 99.996%+ availability.

Qiang delved into the rationale behind Didi's decision to transition from RocketMQ and Kafka-based backends to Pulsar. The motivations ranged from embracing a cloud-native architecture, drastically reducing operating costs (thanks to Pulsar's lower CPU usage, write latency, and end-to-end latency), exploiting the flexibility of SSDs and HDDs for storage, leveraging high-performance capabilities, and basking in the collaborative spirit of the rapidly growing Pulsar community.
Qiang further elucidated how Didi executed the seamless migration from RocketMQ and Kafka to Pulsar using the Protocol Handler framework, ensuring a frictionless transition. It's worth noting that this framework also serves as the bridge to facilitate protocol compatibility with Kafka Protocol and various other messaging and streaming protocols.
Qiang then passed the baton to his colleague Bo Cong, a committer for both Pulsar and BookKeeper. Bo underscored Didi's prominent role as one of the largest contributors in China, with over 400 contributions to both Pulsar and BookKeeper communities. He shed light on some of the challenges encountered during Didi's adoption of Pulsar, including discussions around the incorporation of Pulsar-native features such as delayed messages and tiered storage.
These revelations from Didi perfectly aligned with our observations in Current 2023. Notably, message queues have emerged as a leading use case for Pulsar, propelling its adoption. Additionally, our radar picked up on the trend of cost reduction and the strategic deployment of tiered storage solutions.
Tiered Storage: The Art of Cost-Efficient Data Streaming Infrastructure
Yingqun Zhong from WeChat graced the stage to present WeChat's adept utilization of Pulsar's tiered storage. He commenced by elaborating on the various facets of data lifecycle and use cases within WeChat. Remarkably, only 1% of WeChat's use cases demand real-time data processing, characterized by message lifecycles of less than 10 minutes. In contrast, 9% of use cases necessitate catch-up reads and batch processing, relying on data freshness within a 2-hour window. The remaining 90% of use cases revolve around data replay and data backup, spanning data older than 2 hours. Within WeChat's operations, Pulsar holds the position of a mission-critical infrastructure. Yet, in certain scenarios, businesses require the long-term storage of data within Pulsar. This poses a cost challenge, particularly when employing BookKeeper with SSDs for storage.

Enter Pulsar's tiered storage, also known as the offload framework, which proved to be a silver bullet solution for WeChat's challenges. With Pulsar's multi-layered architecture, WeChat adeptly segregates data – "Hot Data" remains in the brokers, "Warm Data" finds its home in the BookKeeper storage layer, while "Cold Data" is gracefully offloaded to more cost-effective storage options, such as cloud object stores or on-premises HDFS.
Zhong then delved into the meticulous optimizations performed to fine-tune Pulsar's tiered storage performance, ensuring it aligns seamlessly with WeChat's requirements. He also highlighted the collaborative efforts with StreamNative in adopting Lakehouse as a tiered storage solution for Pulsar. The resounding message was clear – tiered storage significantly diminishes data storage expenses, amplifies operational stability when Pulsar acts as the data bus, and propels Pulsar into the realm of infinite storage capacity.
Performance and Scalability: Pulsar's North Star
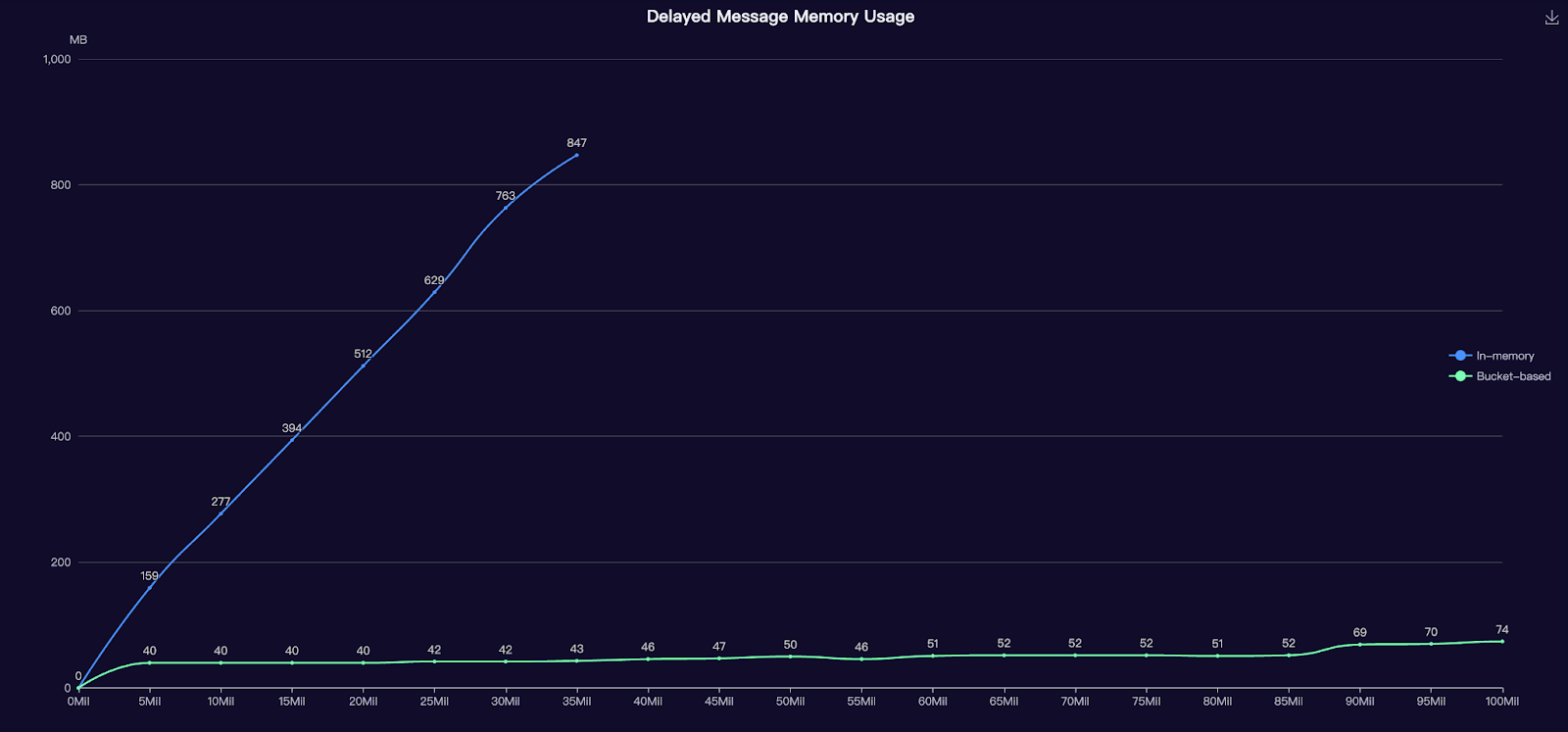
In addition to the insightful use case presentations, many talks by Pulsar committers and contributors shone a spotlight on features and performance enhancements within Pulsar. Cong Zhao introduced a new implementation of Delayed Message, illuminating their genesis and evolution from an in-memory priority queue-based solution to a bucket-based solution. The revamped Delayed Message implementation can seamlessly accommodate arbitrary delayed messages while maintaining a low memory footprint (i.e., 40 MB memory usage to support 100 million delayed messages) and reducing delay message recovery time substantially. For example, it took 6120 seconds to recover a topic with 30 million delayed messages using in-memory priority queue-based solution, while it only took 90 seconds to recover a topic with 100 million delayed messages using the bucket-based solution.
Yong Zhang, a BookKeeper committer, plunged into the AutoRecovery implementation – the linchpin ensuring data durability and fault tolerance within BookKeeper. Recognizing the shifting landscape where most Pulsar clusters are deployed within containerized or cloud environments, StreamNative is diligently evolving the AutoRecovery implementation into a modern cloud-native implementation, anchored by the Kubernetes operator.
Functions emerged as a hot topic of discussion. Rui Fu from StreamNative dissected the challenges associated with running functions using Function Worker on Kubernetes, showcasing how StreamNative developed Function Mesh to bolster reliability. Meanwhile, Pengcheng shed light on a generic runtime implementation within Apache Pulsar. This innovation circumvents existing limitations by providing a framework that supports multiple programming languages, based on Rust and WebAssembly. As a cherry on top, any compiled WebAssembly modules can effortlessly slot into Pulsar Functions. The alpha version of this generic runtime for Pulsar Functions is set to debut on StreamNative Cloud in the near future – stay tuned for more!
Last but certainly not least, Penghui Li embarked on a comprehensive exploration of Topic Compaction, unraveling the intricacies within both Apache Pulsar and Apache Kafka. He explained how Topic Compaction was successfully implemented in Kafka on Pulsar, adding yet another feather to Pulsar's cap.
The Rise of Data Streaming Beyond Flink
As highlighted in our Current 2023 blog post, Apache Flink has firmly established itself as the gold standard in streaming data processing. However, new innovators are emerging, poised to challenge Apache Flink's dominance. One such trailblazer is Risingwave, and we were thrilled to have Zilin Chen from Risingwave grace the meetup stage. He walked through the design details of Risingwave, how it is integrated with Apache Pulsar, and what is the difference between Apache Flink and Risingwave. The integration between Risingwave and Pulsar is now fully available in Risingwave. You can experience firsthand by downloading Risingwave and taking it for a spin.
Summary
The gathering of the APAC community and the vibrant showcase of Pulsar's pivotal role as a mission-critical component for real-time data streaming workloads left us brimming with excitement. This event served as a spirited prelude to the impending Pulsar Summit North America 2023, just around the corner. We eagerly anticipate meeting more of our community members face-to-face at the summit – a reunion that is set to be quite exciting. Sign up today!




