
Protocol handlers were introduced in Pulsar 2.5.0 (released in January 2020) to extend Pulsar’s capabilities to other messaging domains. By default, Pulsar brokers only support Pulsar protocol. With protocol handlers, Pulsar brokers can support other messaging protocols, including Kafka, AMQP, and MQTT. This allows Pulsar to interact with applications built on other messaging technologies, expanding the Pulsar ecosystem.
Kafka-on-Pulsar (KoP) is a protocol handler that brings native Kafka protocol into Pulsar. It enables developers to publish data into or fetch data from Pulsar using existing Kafka applications without code change. KoP significantly lowers the barrier to Pulsar adoption for Kafka users, making it one of the most popular protocol handlers.
KoP works by parsing Kafka protocol and accessing BookKeeper storage directly via streaming storage abstraction provided by Pulsar. While Kafka and Pulsar share many common concepts, such as topic and partition, there is no corresponding concept of Kafka’s offset in Pulsar. Early versions of KoP tackled this problem with a simple conversion method, which did not allow continuous offset and was prone to problems.
To solve this pain point, broker entry metadata was introduced in KoP 2.8.0 to enable continuous offset. With this update, KoP is available and production-ready. It is important to note that with this update backward compatibility is broken. In this blog, we dive into how KoP implemented offset before and after 2.8.0. and explain the rationale behind the breaking change.
Note on Version Compatibility
Since Pulsar 2.6.2, KoP version has been updated with Pulsar version accordingly. The version of KoP x.y.z.m conforms to Pulsar x.y.z, while m is the patch version number. For instance, the latest KoP release 2.8.1.22 is compatible with Pulsar 2.8.1. In this blog, 2.8.0 refers to both Pulsar 2.8.0 and KoP 2.8.0.
Message Identifier in Kafka and Pulsar
Offset in Kafka
In Kafka, offset is a 64-bit integer that represents the position of a message in a specific partition. Kafka consumers can commit an offset to a partition. If the offset is committed successfully, after the consumer restarts, it can continue consuming from the committed offset.
Kafka's offset is continuous as it follows the following constraints:
- The first message's offset is 0.
- If the latest message's offset is N, then the next message's offset will be N+1.
Kafka stores messages in each broker's file system:
- Each partition is divided into segments
- Each segment is a file that stores messages of an offset range
- Each offset has a position, which is the message's start file offset (A file offset is the character's location within a file, while a Kafka offset is the index of a message within a partition.)
Since each message records the message size in the header, for a given offset, Kafka can easily find its segment file and position.
Message ID in Pulsar
Unlike Kafka, which stores messages in each broker's file system, Pulsar uses BookKeeper as its storage system. In BookKeeper:
- Each log unit is an entry
- Streams of log entries are ledgers
- Individual servers storing ledgers of entries are called bookies
A bookie can find any entry via a 64-bit ledger ID and a 64-bit entry ID. Pulsar can store a message or a batch (one or more messages) in an entry. Therefore, Pulsar finds a message via its message ID that consists of a ledger ID, an entry ID, and a batch index (-1 if it’s not batched). In addition, the message ID also contains the partition number.
Just like a Kafka consumer can commit an offset to record the consumer position, a Pulsar consumer can acknowledge a message ID to record the consumer position.
How Does KoP Deal with a Kafka Offset
KoP needs the following Kafka requests to deal with a Kafka offset:
- PRODUCE: After messages from a Kafka producer are persisted, KoP needs to tell the Kafka producer the offset of the first message. However, the BookKeeper client only returns a message ID.
- FETCH : When a Kafka consumer wants to fetch some messages from a given offset, KoP needs to find the corresponding message ID to read entries from the ledger.
- LIST_OFFSET: Find the earliest or latest available message, or find a message by timestamp.
We must support computing a specific message offset or locating a message by a given offset.
How KoP Implements Offset before 2.8.0
The Implementation
As explained earlier, Kafka locates a message via a partition number and an offset, while Pulsar locates a message via a message ID. Before Pulsar 2.8.0, KoP simply performed conversions between Kafka offsets and Pulsar message IDs. A 64-bit offset is mapped into a 20-bit ledger ID, a 32-bit entry id, and a 12-bit batch index. Here is a simple Java implementation.
public static long getOffset(long ledgerId, long entryId, int batchIndex) {
return (ledgerId >> (32 + 12);
long entryId = (offset & 0x0F_FF_FF_FF_FF_FFL) >>> BATCH_BITS;
// BookKeeper only needs a ledger id and an entry id to locate an entry
return new PositionImpl(ledgerId, entryId);
}
In this blog, we use (ledger id, entry id, batch index) to represent a message ID. For example, assuming a message's message ID is (10, 0, 0), the converted offset will be 175921860444160. This works in some cases because the offset is monotonically increasing. But it’s problematic when a ledger rollover happens or the application wants to manage offsets manually. The section below goes into details about the problems of this simple conversion implementation.
The Problems of the Simple Conversion
The converted offset is not continuous, which causes many serious problems.
For example, let’s assume the current message's ID is (10, 5, 100). The next message's ID could be (11, 0, 0) if a ledger rollover happens. In this case, the offsets of these two messages are 175921860464740 and 193514046488576. The delta value between the two is 17,592,186,023,836.
KoP leverages Kafka's MemoryRecordBuilder to merge multiple messages into a batch. The MemoryRecordBuilder must ensure the batch size is less than the maximum value of a 32-bit integer (4,294,967,296). In our example, the delta value of the two continuous offsets is much greater than 4,294,967,296. This will result in an exception that says Maximum offset delta exceeded.
To avoid the exception, before KoP 2.8.0, we must configure maxReadEntriesNum (this config limits the maximum number of entries read by the BookKeeper client) to 1. Naturally, reading only one entry for each FETCH request worsens the performance significantly.
However, even with the workaround of maxReadEntriesNum=1, this conversion implementation doesn’t work in some scenarios. For example, the Kafka integration with Spark relies on the continuance of Kafka offsets. After it consumes a message with an offset of N, it will seek the next offset (N+1). However, the offset N+1 might not be able to convert to a valid message ID.
There are other problems caused by the conversion method. And before 2.8.0, there is no good way to implement the continuous offset.
The Continuous Offset Implementation since 2.8.0
The solution to implement continuous offset is to record the offset into the metadata of a message. However, an offset is determined at the broker side before publishing messages to bookies, while the metadata of a message is constructed at the client side. To solve this problem, we need to do some extra jobs at the broker side:
- Deserialize the metadata
- Set the "offset" property of metadata
- Serialize the metadata again, including re-computing the checksum value
This results in a significant increase in CPU overhead on the broker side.
Broker Entry Metadata
PIP 70 introduced lightweight broker entry metadata. It's a metadata of a BookKeeper entry and should only be visible inside the broker.
The default message flow is:
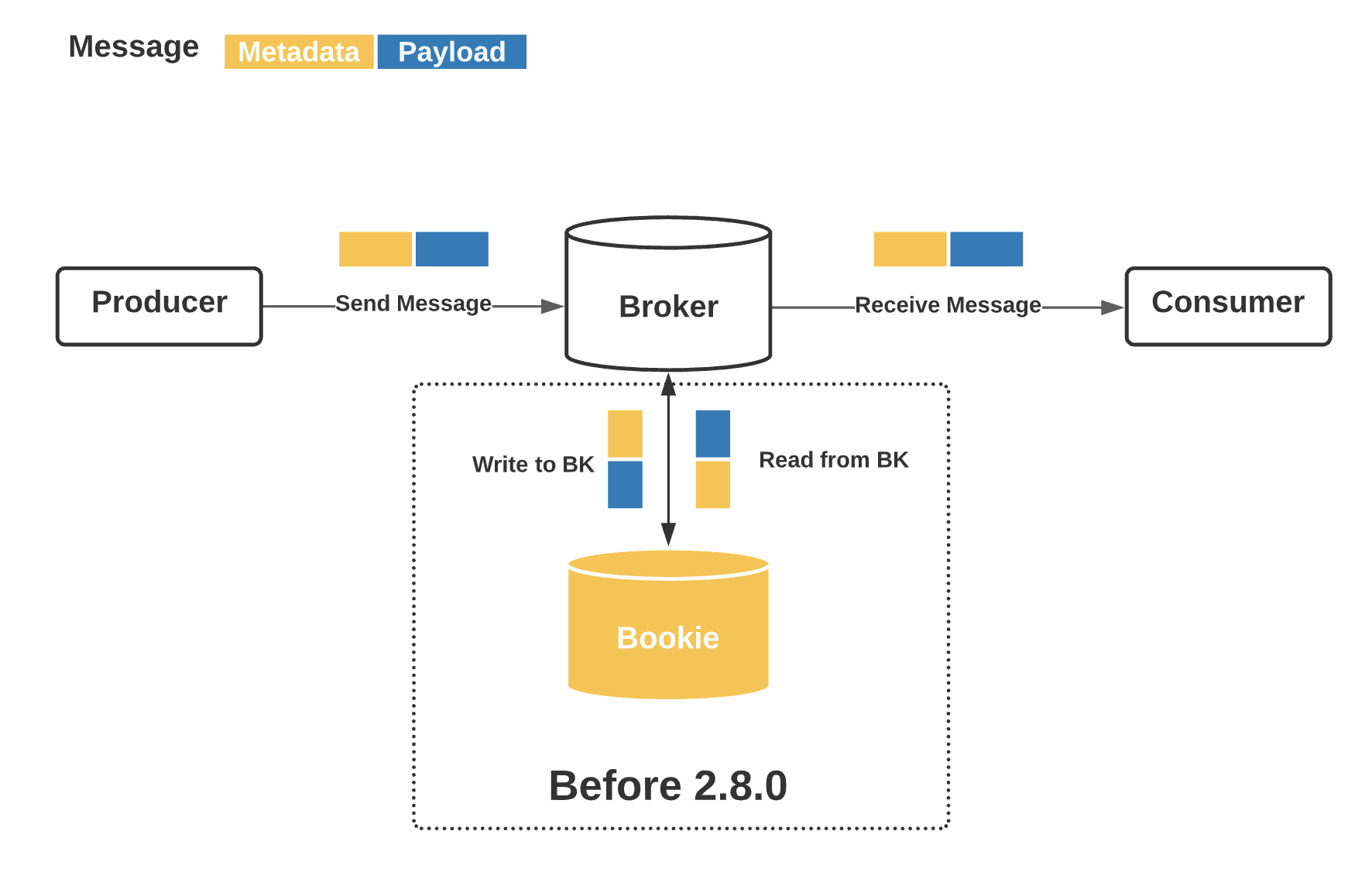
If you configured brokerEntryMetadataInterceptors, which represents a list of broker entry metadata interceptors, then the message flow would be:
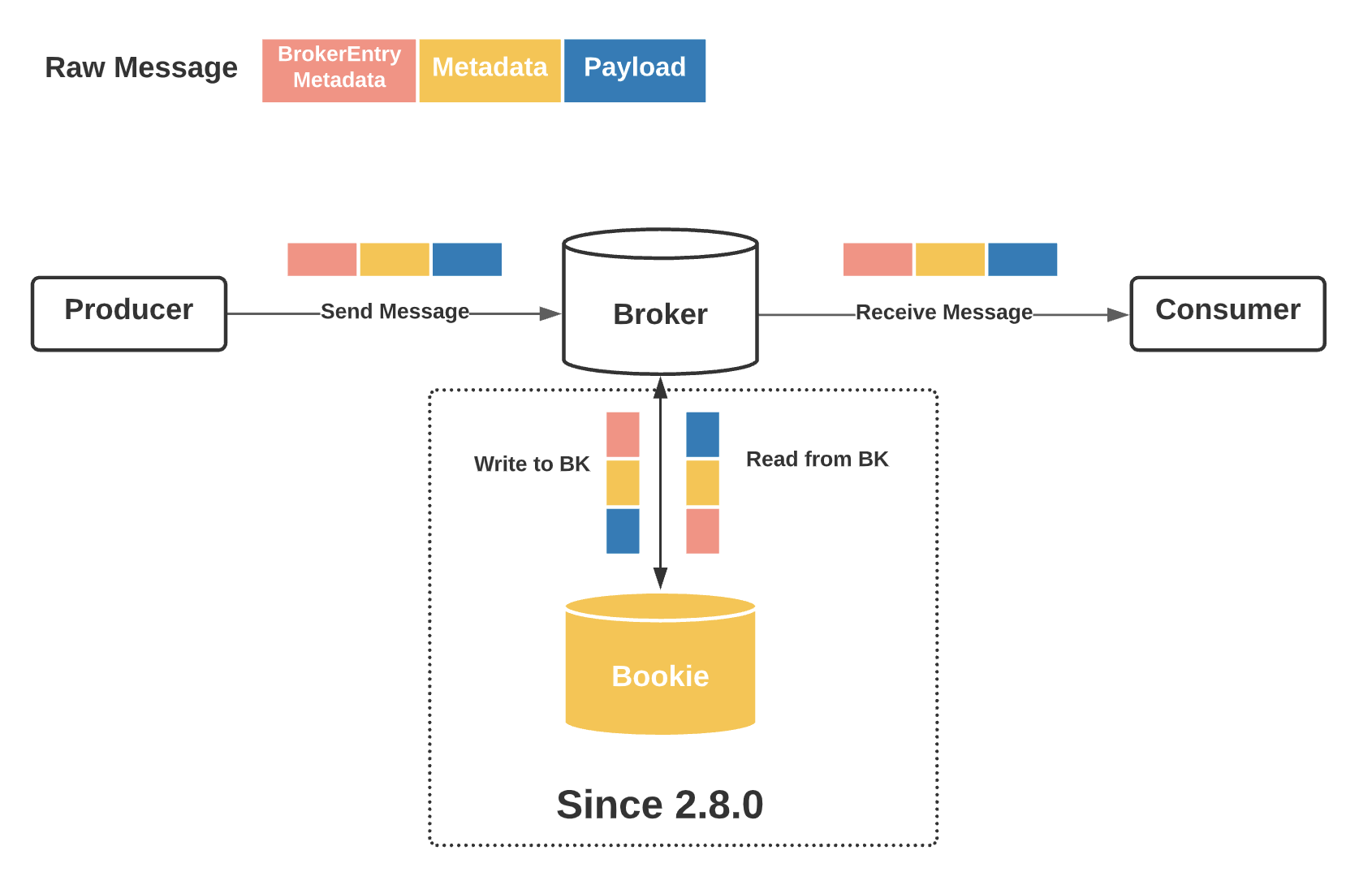
We can see the broker entry metadata is stored in bookies, but is not visible to a Pulsar consumer.
From 2.9.0, a Pulsar consumer can be configured to read the broker entry metadata.
Each broker entry metadata interceptor adds the specific metadata (called "broker entry metadata") before the message metadata. Since the broker entry metadata is independent of the message metadata, the broker does not need to deserialize the message metadata. In addition, the BookKeeper client supports sending a Netty CompositeByteBuf that is a list of ByteBuf without any copy operation. From the perspective of a BookKeeper client, only some extra bytes are sent into the socket buffer. Therefore, the extra overhead is low and acceptable.
The Index Metadata
We need to configure the AppendIndexMetadataInterceptor (we say index metadata interceptor) to support the Kafka offset.
brokerEntryMetadataInterceptors=org.apache.pulsar.common.intercept.AppendIndexMetadataInterceptor
In Pulsar brokers, there is a component named "managed ledger" that manages all ledgers of a partition. The index metadata interceptor maintains an index that starts from 0. The "index" term is used instead of "offset".
Each time before an entry is written to bookies, the following two things happen:
- The index is serialized into the broker entry metadata.
- The index increases by the number of messages in the entry.
After that, each entry records the first message's index, which is equivalent to the "base offset" concept in Kafka.
Now, we must make sure even if the partition's owner broker was down, the index metadata interceptor would recover the index from somewhere.
There are some cases where the managed ledger needs to store its metadata (usually in ZooKeeper). For example, when a ledger is rolled over, the managed ledger must archive all ledger IDs in a z-node. Here we don't look deeper into the metadata format. We only need to know there is a property map in the managed ledger's metadata.
Before metadata is stored in ZooKeeper (or another metadata store):
- Retrieve the index from the index metadata interceptor, which represents the latest message's index.
- Add the property whose key is "index" and value is the index to the property map.
Each time a managed ledger is initialized, it will restore the metadata from the metadata store. At that time, we can set the index metadata intercerptor's index to the value associated with the "index" key.
How KoP Implements the Continuous Offsets
Let's look back to the How does KoP deal with a Kafka offset section and review how we deal with the offset in following Kafka requests.
- PRODUCE
When KoP handles PRODUCE requests, it leverages the managed ledger to write messages to bookies. The API has a callback that can access the entry's data.
@Override
public void addComplete(Position pos, ByteBuf entryData, Object ctx) {
- We only need to parse the broker entry metadata from entryData and then retrieve the index. The index is just the base offset returned to the Kafka producer.
- FETCH
- The task is to find the position (ledger id and entry id) for a given offset. KoP implements a callback that reads the index from the entry and compares it with the given offset. It then passes the callback to a class named OpFindNewest, which uses binary search to find an entry.
- The binary search could take some time. But it only happens on the initial search unless the Kafka consumer disconnects. After the position is found, a non-durable cursor will be created to record the position. The cursor will move to a newer position as the fetch offset increases.
- LIST_OFFSET
- Earliest: Get the first valid position in a managed ledger. Then read the entry of the position, and parse the index.
- Latest: Retrieve the index from the index metadata interceptor and increase by one. It should be noted that the latest offset (or called LEO) in Kafka is the next offset to be assigned to a message, while the index metadata interceptor's index is the offset assigned to the latest message.
- By timestamp: First leverage broker's timestamp based binary search to find the target entry. Then parse the index from the entry.
You can find more details about the offset implementation in the following PRs:
- https://github.com/apache/pulsar/pull/8618
- https://github.com/apache/pulsar/pull/9039
- https://github.com/streamnative/kop/pull/296
Upgrade from KoP Version before 2.8.0 to 2.8.0 or Higher
KoP 2.8.0 implements continuous offset with a tradeoff – the backward compatibility is broken. The offset stored by KoP versions before 2.8.0 cannot be recognized by KoP 2.8.0 or higher.
If you have not tried KoP, please upgrade your Pulsar to 2.8.0 or higher and then use the corresponding KoP. As of this writing, the latest KoP release for Pulsar 2.8.1 is 2.8.1.22.
If you have already tried KoP before 2.8.0, you need to know that there's a breaking change from version less than 2.8.0 to version 2.8.0 or higher. You must delete the __consumer_offsets topic and all existing topics previously used by KoP.
There is a latest feature in KoP that can skip these old messages by enabling a config. It would be included in 2.8.1.23 or later. Note that the old messages still won’t be accessible. It just saves the work of deleting old topics.
Summary
In this blog, we first explained the concept of Kafka offset and the similar concept of message ID in Pulsar. Then we talked about how KoP implemented Kafka offset before 2.8.0 and the related problems.
To solve these problems, the broker entry metadata was introduced from Pulsar 2.8.0. Based on this feature, index metadata is implemented via a corresponding interceptor. After that, KoP can leverage the index metadata interceptor to implement the continuous offset.
Finally, since it's a breaking change, we talked about the upgrade from KoP version less than 2.8.0 to 2.8.0 or higher. It's highly recommended to try KoP 2.8.0 or higher directly.
More Resources
- To learn more about KoP, read Announcing Kafka-on-Pulsar: Bringing native Kafka protocol support to Apache Pulsar.
- Read the 2022 Pulsar vs. Kafka Benchmark Report for the latest performance comparison on maximum throughput, publish latency, and historical read rate.
- Make an inquiry: Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.
- Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Engage with the community by submitting a CFP or becoming a community sponsor (no fee required).




