The state-of-the-art real-time data storage and processing approach
In the field of massively parallel data analysis, AMPLab's "One stack to rule them all" proposes to use Apache Spark as a unified engine to support all commonly used data processing scenarios, such as batch processing, stream processing, interactive query, and machine learning. Structured streaming is the new Apache Spark API released in Spark 2.2.0 that lets you express computation on streaming data in the same way you express a batch computation on static data, and Spark SQL engine performs a wide range of optimizations for both scenarios internally.
On the other hand, Apache Flink get in the public eye around 2016 with many appealing features, for example, better stream processing support at the time, the built-in watermark support, and exactly-once semantics. Flink has quickly become a strong competitor for Spark. Regardless of the platform, users nowadays are more concerned about how to quickly discover the value of data. Streaming data and static data are no longer separate entities, but two different representations through the data lifecycle.
A natural idea arises: can I keep all streaming data in messaging systems as they are collected? For traditional systems, the answer is no. Take Apache Kafka as an example, in Kafka, storage of topics is partition-based—a topic partition is entirely stored within and accessed by a single broker, whose capacity is limited by the capacity of the smallest node. Therefore, as data size grows, capacity expansion can only be achieved by partition rebalancing, which in turn requires recopying the whole partition for balancing both data and traffic to newly added brokers. Recopying data is expensive and error-prone, and it consumes network bandwidth and IO. To make matters worse, Kafka is designed to run on physical machines, as we are moving towards container-based cloud architecture, it lacks many key features such as I/O isolation, multi-tenancy, and scalability.
Due to the limitations of existing streaming platforms, organizations utilize two separate systems for streaming data storage: a messaging system for newly imported data, and later off-load aged data to cold storage for the long-time store. The separation of data store into two systems brought in two main obstacles inevitably:
- On the one hand, to guarantee the correctness and real-time of analysis results, users are required to be aware of boundaries of each data and need to perform joint queries with data stored in two systems;
- On the other hand, dumping streaming data to file or object storage periodically requires additional operation and maintenance costs as well as a considerable consumption of cluster computation resources.
A short introduction to Apache Pulsar
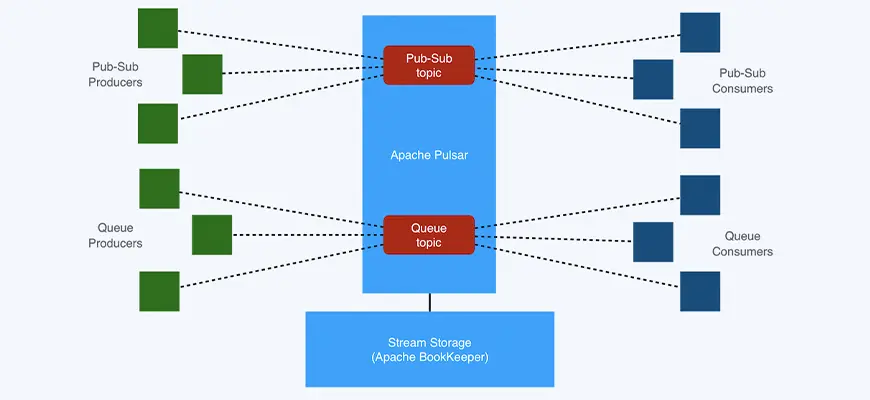
Apache Pulsar is an enterprise-grade distributed messaging system created at Yahoo and now it is a top-level open source project in the Apache Software Foundation. Pulsar follows the general pub-sub pattern, where a producer publishes a message to a topic; a consumer can subscribe to the topic, processes a received message, and send a confirmation after the message is processed (Ack). A subscription is a named configuration rule that determines how messages are delivered to consumers. Pulsar enables four types of subscriptions that can coexist on the same topic, distinguished by subscription name:
- Exclusive subscription—only a single consumer is allowed to attach to the subscription.
- Shared subscriptions—can be subscribed by multiple consumers; each consumer receives a portion of the messages.
- Failover subscriptions—multiple consumers can attach to the same subscription, but only one consumer can receive messages. Only when the current consumer fails, the next consumer in line begins to receive messages.
- Key-shared subscriptions (beta)—Multiple consumers can attach to the same subscription, and messages with the same key or same ordering key are delivered to only one consumer.
Pulsar was created from the ground up as a multi-tenant system. To support multi-tenancy, Pulsar has a concept of tenants. Tenants can be spread across clusters and can have their authentication and authorization scheme applied to them. They are also the administrative unit at which storage quotas, message TTL, and isolation policies can be managed. The multi-tenant nature of Pulsar is reflected mostly visibly in topic URLs, which have this structure: persistent://tenant/namespace/topic. As you can see, the tenant is the most basic unit of categorization for topics (more fundamental than the namespace and topic name).
Why Pulsar fits best
A fundamentally layered architecture and segment-centric storage (with Apache BookKeeper) are two key design philosophies that make Apache Pulsar more advanced compared with other messaging systems. An Apache Pulsar cluster is composed of two layers: a stateless serving layer, comprised of a set of brokers that receive and deliver messages, and a stateful persistence layer, comprised of a set of Apache BookKeeper storage nodes called bookies that durably store messages. Let's investigate the designs one by one:
Layered architecture
Similar to Kafka, Pulsar stores messages based on topic partitions, each topic partition is assigned to one of the living brokers in Pulsar, which is called the owner broker of that topic partition. The owner broker serves message-reads from the partition and message-writes to the partition. If a broker fails, Pulsar automatically moves the topic partitions that were owned by it to the remaining available brokers in the cluster. Since brokers are "stateless", Pulsar only transfers ownership from one broker to another during nodes failure or broker cluster expansion, no data copy occurred during this time.
Segment-centric storage
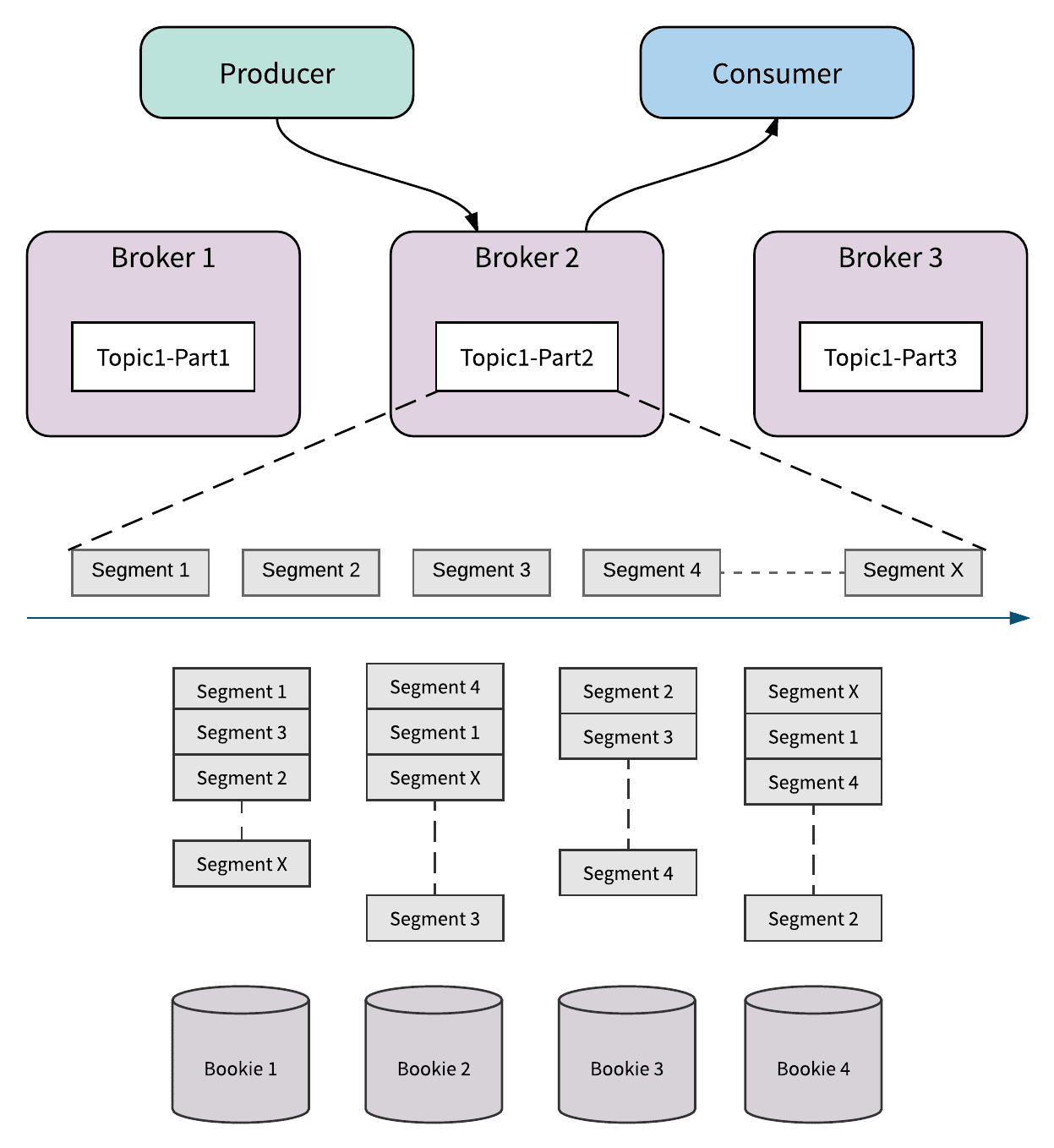
As shown in Figure 1, messages on a Pulsar topic partition are stored in a distributed log, and the log is further divided into segments. Each segment is stored as an Apache BookKeeper ledger that is distributed and stored in multiple bookies in the cluster. A new segment is created either after a previous segment has been written for longer than a configured interval (aka time-based rolling), or if the size of the previous segment has reached a configured threshold (aka size-based rolling), or whenever the ownership of topic partition is changed. With segmentation, the messages in a topic partition can be evenly distributed and balanced across all the bookies in the cluster, which means the capacity of a topic partition is not limited only by the capacity of one node. Instead, it can scale up to the total capacity of the whole BookKeeper cluster.
The two design philosophies in Apache Pulsar provide several significant benefits such as unlimited topic partition storage, instant scaling without data rebalancing, and independent scalability of serving and storage clusters. Besides, tiered storage brings in Pulsar 2.0 provides an alternative way to reduce storage cost for aged data. With tiered storage, older messages in bookies can be moved to cheaper storage such as HDFS or S3.
Last but not least, Pulsar provides typed messages storage via Pulsar Schema; therefore you can designate data schema while creating a topic, and Pulsar does the rest of the intricate work for you, such as message validation, message serialization to and message deserialization from the wire format.
Pulsar Spark Connector
We have developed a Pulsar Spark Connector that enables Spark to execute streaming or batch job against messages stored in Pulsar and writes job results back to Pulsar.
Pulsar Spark Connector API
Since the Structured Streaming in Spark 2.2.0, Spark keeps SparkSession as the only entrance to write a program, and you could use the declarative API called DataFrame/DataSet to meet your needs. In such a program, you declare how a DataFrame is generated, transformed, and finally written. Spark SQL engine does other optimizations and runs your code distributedly on a cluster. Take the following codes as illustrative examples to use Pulsar as a data source or data sink:
- Construct a streaming source using one or more topics.
val df = spark
.readStream
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("admin.url", "http://localhost:8080")
.option("topicsPattern", "topic.*") // Subscribe to a pattern
// .option("topics", "topic1,topic2") // Subscribe to multiple topics
// .option("topic", "topic1"). //subscribe to a single topic
.option("startingOffsets", startingOffsets)
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)").as[(String, String)]
- Construct a batch source.
val df = spark
.read
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("admin.url", "http://localhost:8080")
.option("topicsPattern", "topic.*")
.option("startingOffsets", "earliest")
.option("endingOffsets", "latest")
.load()
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]
- Sink streaming results continuously to Pulsar topics
val ds = df
.selectExpr("__topic", "CAST(__key AS STRING)", "CAST(value AS STRING)") // the __topic field is used to choose the right topic for each record
.writeStream
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.start()
- Write batch results to Pulsar.
df.selectExpr("CAST(__key AS STRING)", "CAST(value AS STRING)")
.write
.format("pulsar")
.option("service.url", "pulsar://localhost:6650")
.option("topic", "topic1")
.save()
Tip
Pulsar Spark Connector support DataSet/DataFrame read from and write to Pulsar messages directly, the metadata fields of a message, such as an event time, message Id, are prefixed with two underscores (e.g.eventTime) to avoid potential naming conflict with messages' payload.
Pulsar Spark Connector internals
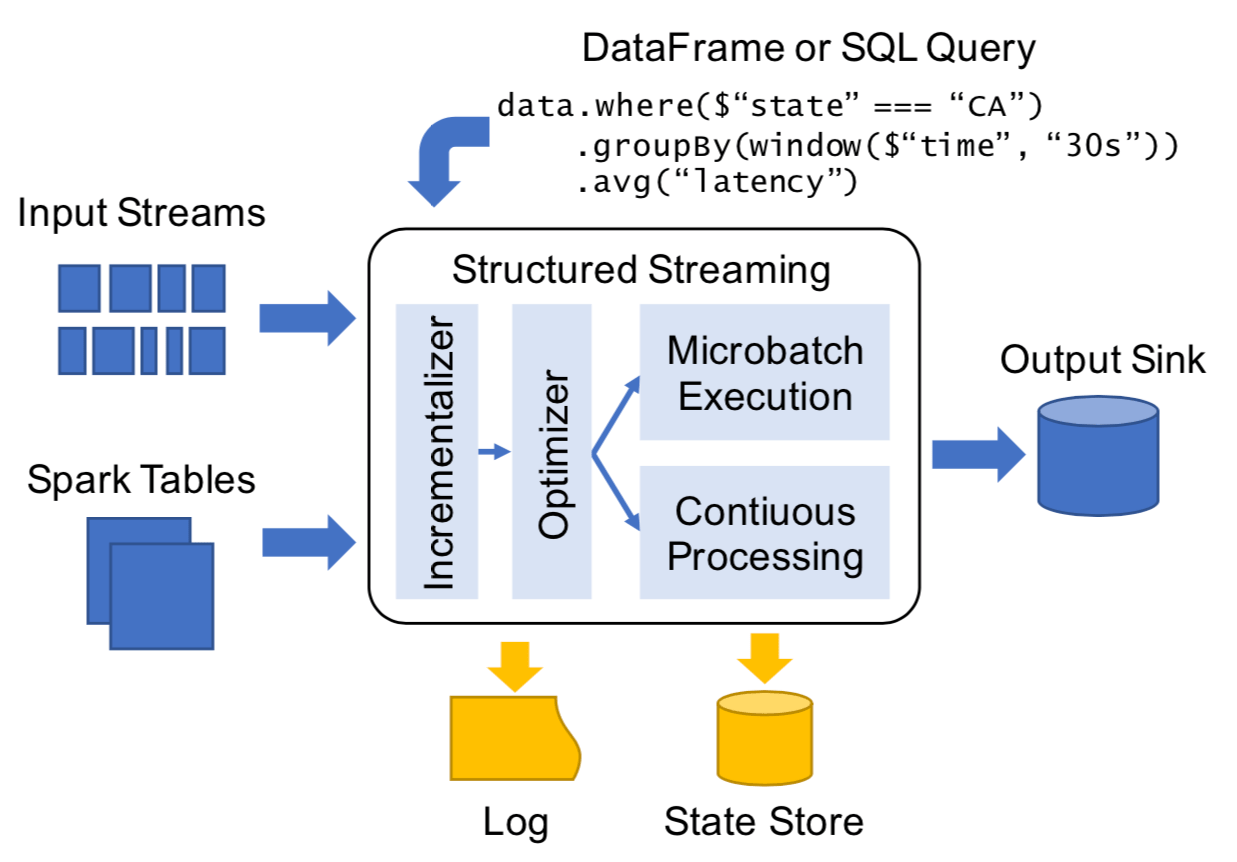
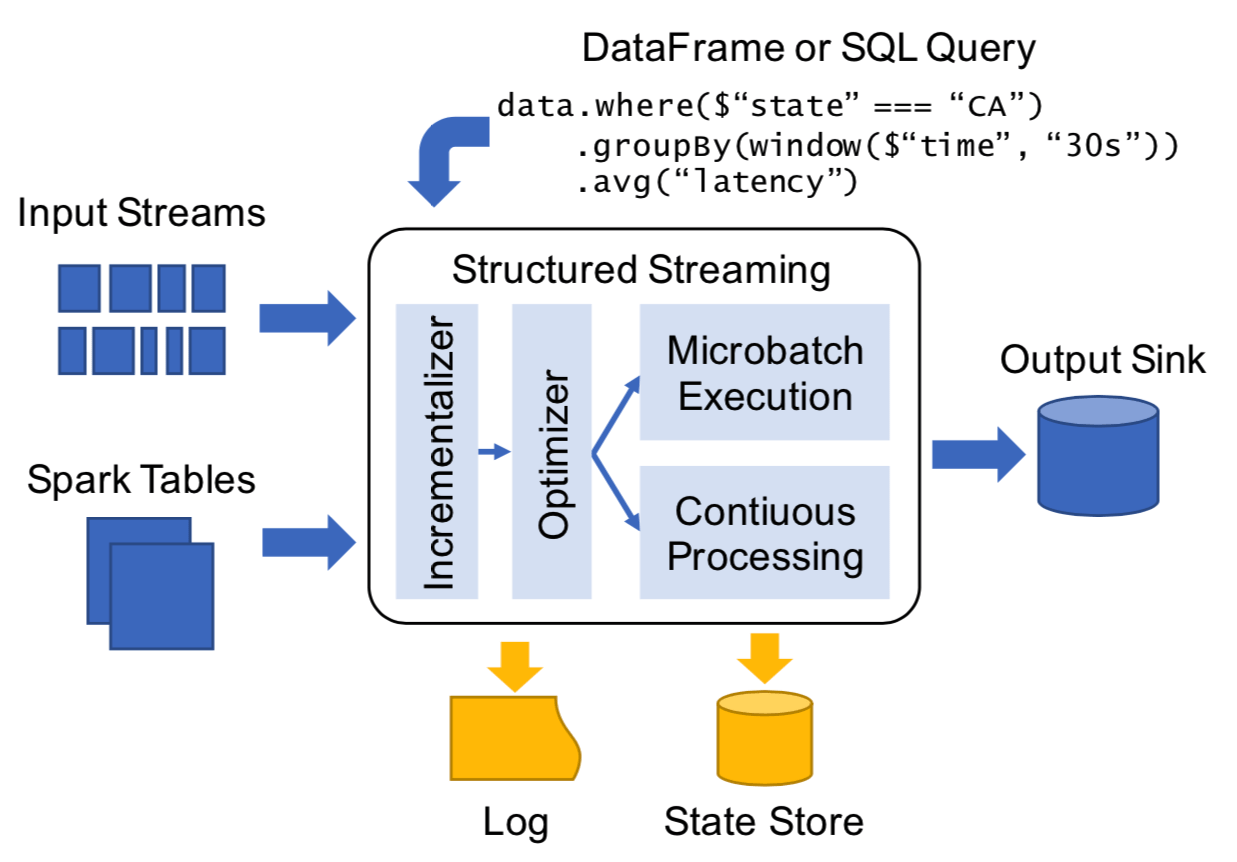
Figure 2 shows the main components of Structured Streaming (abbreviated as ''SS'' hereafter):
- Input and Output—provides fault tolerance. SS requires input sources which must be replayable, allowing re-read recent input data if a node crashes (Pulsar Spark Connector guarantees this). Output sinks must support idempotent writes to provide ''exactly-once'' (Pulsar Spark Connector cannot do this currently, we provide ''at-least-once'' guarantee and you could deduplicate messages in later Spark jobs through a primary key).
- API—batch and streaming programs share Spark SQL batch API, with several API features to support streaming specifically.
- Triggers control how often the engine attempts to compute a new result and update the output sink.
- Users can use watermark policy to determine when to stop handling late arrived data.
- Stateful operators allow users to track and update mutable state by keys in case of complex processing.
- Execution layer—On receiving a DataFrame query, SS determines how to run it incrementally (for streaming queries), optimizes it and runs it through one of the execution models:
- Microbatch model by default for higher throughput with dynamic load balancing, rescaling, fault recovery, and straggler mitigation.
- Continuous model for low-latency circumstances.
- Log and state store—Write-ahead-Log is written first for tracking consumed positions in each source. A large scale state store takes snapshots of the internal state of operators and facilitates the recovering procedure during failure.
The execution flow for a streaming job
For Pulsar Spark Connector, source and sink in Spark defines how we should implement read/write logic:
trait Source {
def schema: StructType
def getOffset: Option[Offset]
def getBatch(start: Option[Offset], end: Offset): DataFrame
def commit(end: Offset): Unit
def stop(): Unit
}
trait Sink {
def addBatch(batchId: Long, data: DataFrame): Unit
}
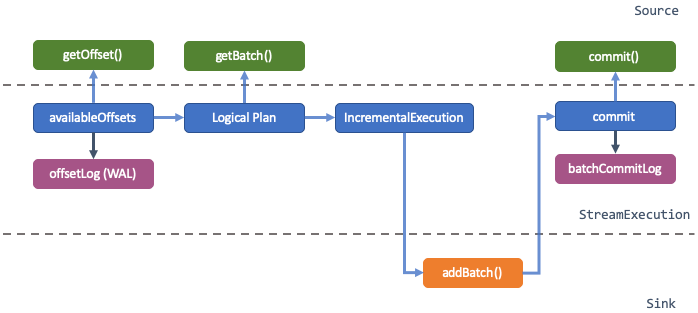
StreamExecution handles the execution logic internally. Figure 3 shows a microbatch execution flow inside StreamExecution: 1. At the very beginning of each microbatch, SS asks the source for available data (getOffset) and persist it to the WAL. 2. The source then provides the data inside a batch (getBatch) based on the start and end offsets provided by SS. 3. SS triggers the optimization and compilation of the logical plan and writes the calculation result to sink (addBatch). Note: the actual data acquisition and calculation happen here. 4. Once the data is successfully written to the sink, SS notifies the source that the data can be discarded (commit) and the successfully executed batchId is written to the internal commitLog.
Back to Pulsar Spark Connector, we do the following stuff:
- During the query planning phase, topics schema would be fetched from Pulsar, check for compatibility (topics in a query should share the same schema) and transformed to DataFrame schema.
- Create a consumer for each topic partition and return data between (start, end].
- On receiving commit calls from SS, we resetCursor on a topic partition, notify Pulsar the data could be cleaned.
- For DataFrame we received from addBatch, records are sent to corresponding topics through producer send.
Topic/partition add/delete discovery
Streaming jobs are long-running by nature. During their execution, topics or partitions may be deleted or added. Pulsar Spark Connector enables topic/partition discovery at the beginning of each microbatch or each epoch in continuous execution, by listing all partitions available and comparing these with the partitions from the last microbatch or epoch, we could easily find which partitions are newly added or which partitions are gone, and scheduling new tasks or remove existing tasks accordingly.
More information
- Pulsar Spark Connector
- A tutorial on how to set up the development environment and start using the Pulsar Spark Connector.
- If you are interested in Pulsar community news, Pulsar development details, and Pulsar user stories on production, follow StreamNative Medium or @streamnativeio on Twitter.
References
- Pulsar Documentation
- Structured Streaming: A Declarative API for Real-Time Applications in Apache Spark in SIGMOD 2018
- From Messaging systems to Data Platform - A great Chinese blog introduces the evolution of the messaging systems