
Bringing Real-Time Streaming Data into the Snowflake AI Data Cloud
Real-time data is becoming a critical foundation for AI, analytics, and modern data applications, making it essential for organizations to seamlessly connect streaming platforms with governed data ecosystems. In February 2025, StreamNative announced support for Snowflake Open Catalog, enabling organizations to stream real-time data into Apache Iceberg™ tables as part of an open lakehouse architecture.
Today, StreamNative is deepening this integration as part of the launch of its managed Kafka service, adding support for Snowflake Horizon Catalog---Snowflake's strategic unified governance platform for the AI Data Cloud. This expansion enables organizations to operationalize real-time Kafka data as governed, trusted, and AI-ready data products in Snowflake, helping enterprises accelerate their journey from streaming ingestion to AI-driven insights.
StreamNative Kafka Service, powered by Ursa Engine, enables organizations to continuously publish Kafka topic data into open table formats like Apache Iceberg while Snowflake Horizon Catalog provides centralized governance, RBAC enforcement, metadata management, and integration with Snowflake's AI and analytics ecosystem.
Together, StreamNative and Snowflake enable organizations to transform Kafka streams into governed, discoverable, and AI-ready enterprise data assets.
The Need for Unified Streaming and Governance Architectures
As data architectures evolve toward lakehouse and AI-driven models, organizations increasingly require real-time data to be governed with the same rigor as warehouse data.
Two key challenges commonly emerge:
Complexity and cost of traditional Kafka ingestion architectures
Many organizations rely on connector-based pipelines or batch ingestion approaches to move Kafka data into analytics environments. These approaches often introduce:
- Additional compute infrastructure for ingestion pipelines
- Operational complexity managing connectors and transformations
- Delays between ingestion and analytics readiness
- Fragmented data movement architectures
Organizations are increasingly seeking architectures where Kafka data can directly become analytics and AI ready without additional ingestion layers.
Lack of consistent governance across streaming and enterprise data platforms
Streaming platforms often operate outside enterprise governance frameworks, creating challenges such as:
- Inconsistent RBAC enforcement between systems
- Limited lineage visibility for streaming datasets
- Governance gaps between operational and analytical data
- Difficulty integrating streaming datasets into AI workflows
Modern data architectures require real-time data to be governed, discoverable, and trusted just like enterprise warehouse data.
StreamNative Kafka Service: A Modern Streaming Foundation for Lakehouse Architectures
StreamNative Kafka Service is built on Ursa Engine, a modern streaming architecture designed around separation of compute and storage and lakehouse-native data management.

This architecture enables several advantages:
- Reduced infrastructure costs through the elimination of leader-based replication overhead
- Storage efficiency through direct use of cloud object storage and columnar data formats
- Real-time data availability for analytics and AI workloads
- Simplified data pipelines by reducing dependency on external ingestion systems
Ursa's architecture allows Kafka data to be continuously organized into analytics-ready table formats while preserving Kafka semantics such as replay and retention.
This allows StreamNative Kafka Service to serve both as a streaming platform and a real-time ingestion layer for enterprise lakehouse platforms.
Snowflake Horizon Catalog: Bringing Enterprise Governance to Streaming Data
Snowflake Horizon Catalog provides unified governance capabilities across the Snowflake AI Data Cloud, enabling organizations to manage data access, discovery, optimization, and compliance from a centralized governance framework.
By integrating StreamNative Kafka Service with Snowflake Horizon Catalog, organizations can extend Snowflake governance capabilities to real-time streaming datasets.
Key Snowflake Horizon capabilities enabled through this integration include:
- Unified RBAC policies ensuring consistent access controls across streaming and warehouse data
- Centralized data discovery allowing Kafka-derived datasets to be searchable alongside enterprise datasets
- Automated table optimization services improving performance and storage efficiency
- Built-in data lineage and governance controls
- Integration with Snowflake AI Data Cloud services including Cortex and analytics workloads
This integration ensures Kafka data can participate fully in enterprise governance frameworks rather than remaining isolated within streaming infrastructure.
Turning Kafka Streams into Governed Enterprise Data Products
Through this integration, StreamNative Kafka Service enables Kafka topic data to be continuously materialized into lakehouse tables that can be governed through Snowflake Horizon Catalog.
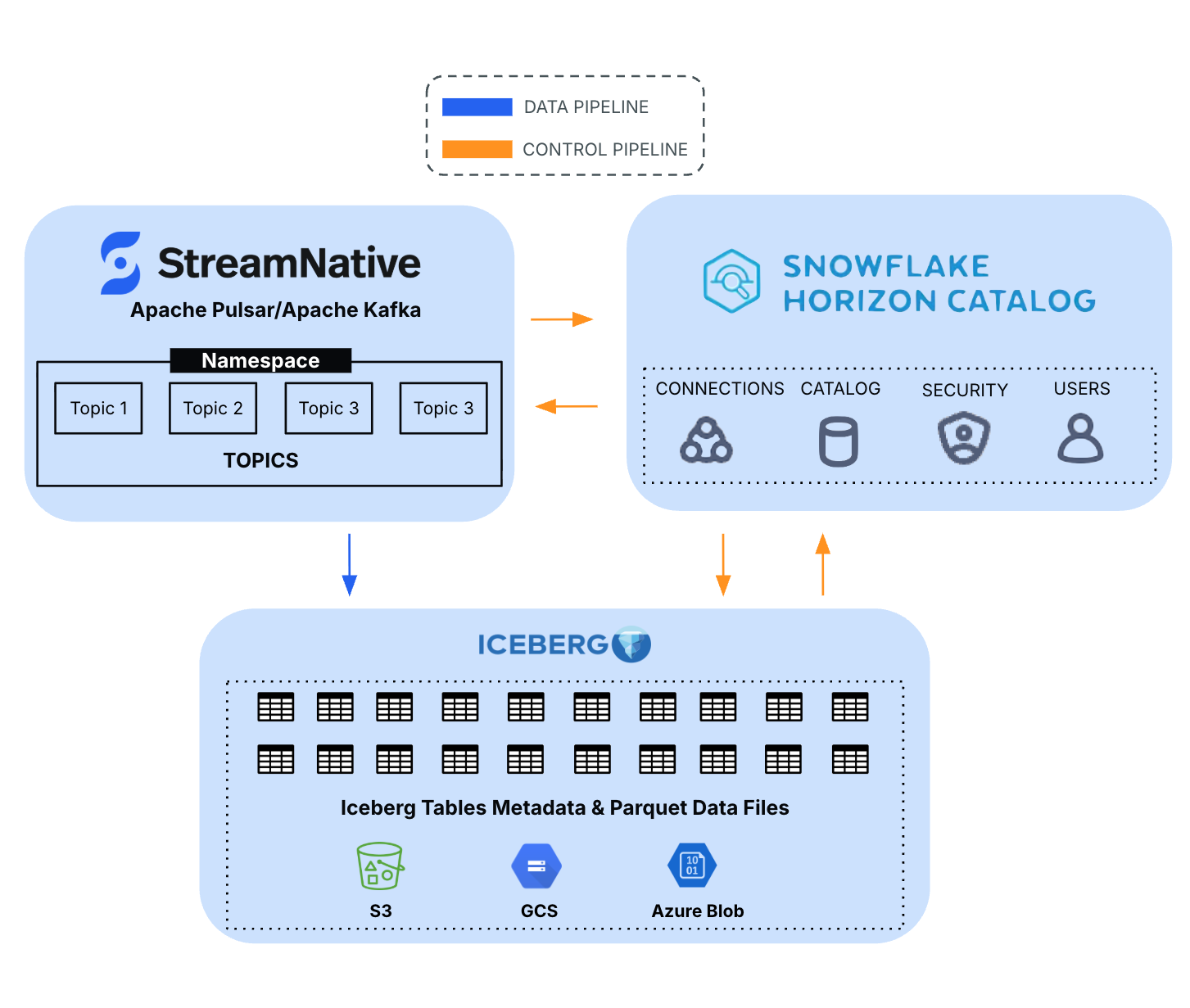
StreamNative Cloud acts as the real-time ingestion layer while Snowflake provides governance and consumption capabilities.
This allows organizations to:
- Continuously ingest Kafka data into governed datasets
- Register datasets within Snowflake governance frameworks
- Enable secure enterprise-wide access
- Support AI and analytics workloads on fresh data
- Reduce the complexity of streaming-to-analytics pipelines
This architecture helps organizations treat Kafka data as a governed enterprise data product rather than an isolated operational data stream.
How the Integration Works
StreamNative Kafka Service leverages its lakehouse integration capabilities to continuously publish topic data into governed table formats discoverable through Snowflake.
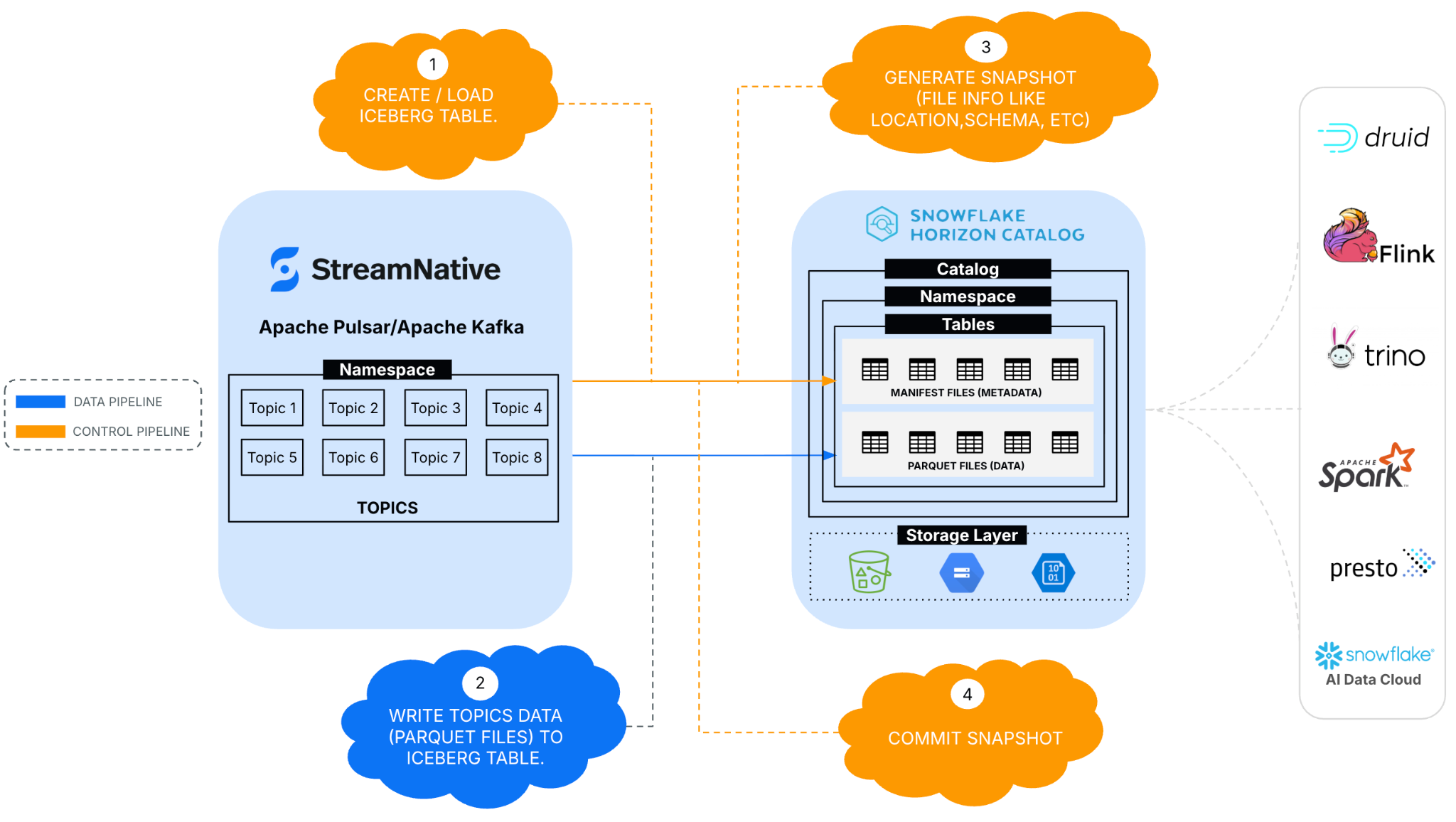
The integration of StreamNative Cloud with Snowflake Horizon Catalog leverages Iceberg libraries to ingest data as Iceberg tables and register them within Snowflake's Horizon Catalog.
- Create and register an iceberg table -- StreamNative Cloud utilizes Apache Iceberg libraries to authenticate with Snowflake's Horizon Catalog service and execute REST APIs for table creation and registration.
- Write topics data to Iceberg table -- Topic data is written to Parquet files, with a corresponding Iceberg table created for each topic.
- Generate snapshot -- StreamNative Cloud runtime creates a new snapshot. This process occurs with each update to the Iceberg table, capturing all associated data and manifest files. Snapshots enable time-travel queries and support rollback operations.
- Commit snapshot -- Snapshot created in the previous step is committed in this step. Committing a snapshot is the process of atomically applying changes to an Iceberg table through the REST Catalog API. This ensures consistency and correctness in a distributed environment.
- Query and Analyze Iceberg Data in Snowflake AI Data Cloud -- Users can access and analyze the ingested data with the Snowflake AI Data Cloud and a variety of tools.
This native integration enables users to effortlessly configure a cluster for streaming data directly into Iceberg with just a few clicks, allowing them to quickly gain insights from their data.
StreamNative's integration with Snowflake Horizon Catalog provides unified governance, enabling visibility and access controls across streaming and non-streaming data as it moves from ingestion to processing, storage, and consumption. This integration also enables interoperability with a vendor-neutral, open source foundation in Apache Iceberg and Apache Polaris, giving organizations flexibility to read and write with a variety of engines.
Snowflake AI Data Cloud consumption
Once governed, datasets can be accessed through Snowflake services including:
- Snowflake SQL
- Snowflake Cortex AI
- Notebooks and data science workflows
- BI integrations
- AI and agentic applications
This enables real-time Kafka data to become immediately useful for enterprise AI and analytics workflows.
Integration Setup
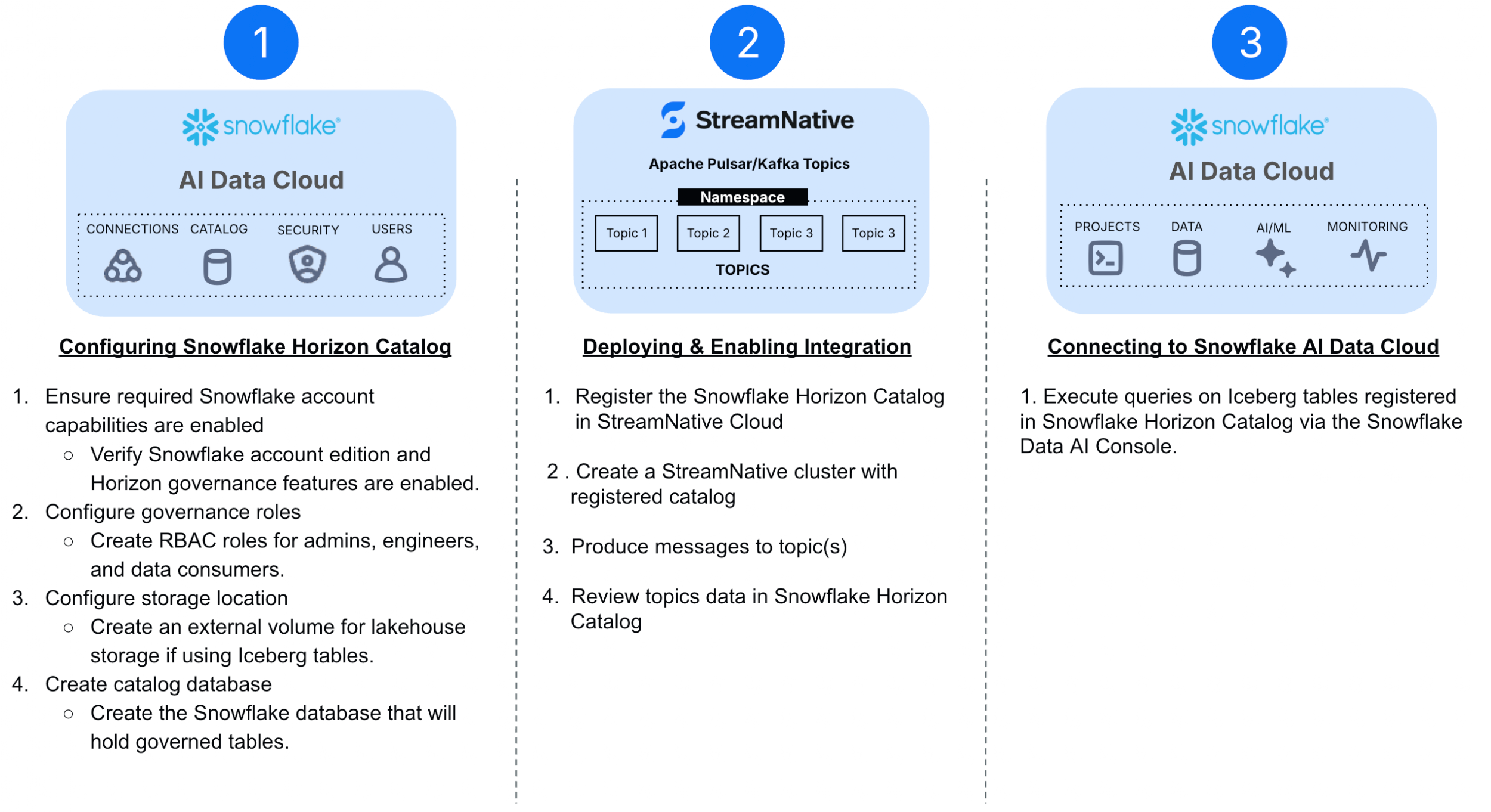
To establish an integration between StreamNative and Snowflake Horizon Catalog, three key steps must be followed:
- Configuring Snowflake Horizon Catalog -- Begin by setting up Snowflake Horizon Catalog to enable seamless integration with StreamNative Cloud for data streaming.
- Deploying and Enabling Integration -- Create a cluster and activate the Snowflake Horizon Catalog integration within StreamNative Cloud.
- Connecting to Snowflake AI Data Cloud -- Configure Snowflake AI Data Cloud to access and query data published in Snowflake Horizon Catalog, ensuring seamless interoperability.
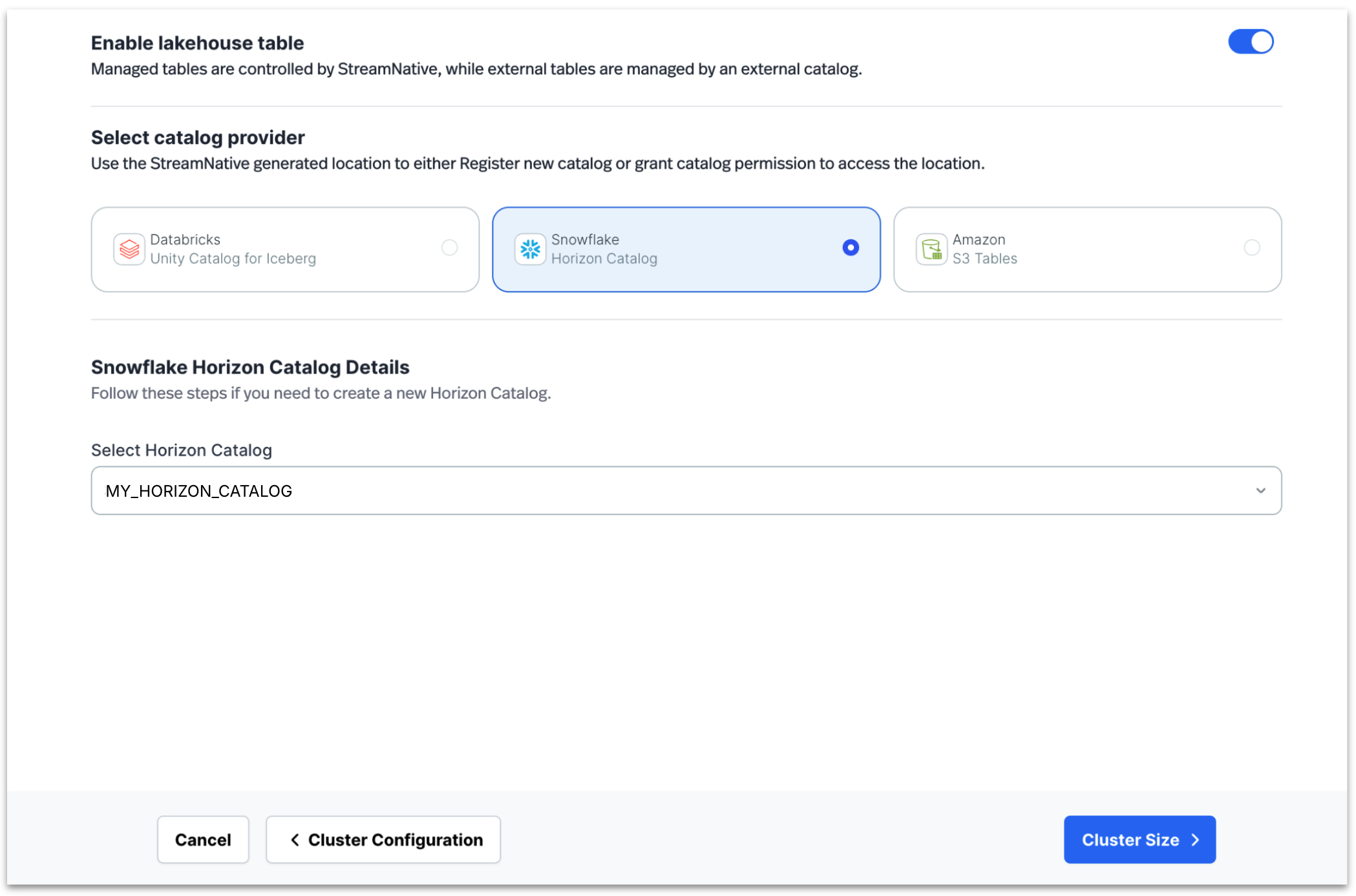
Simple Deployment Experience
StreamNative and Snowflake enable a simplified deployment experience allowing organizations to connect streaming and governance workflows quickly.
Integration typically involves three steps:
Configure Snowflake governance integration
Organizations configure governance connectivity and policies within Snowflake.
Deploy StreamNative Kafka Service with lakehouse integration enabled
Users deploy Kafka clusters with lakehouse publishing capabilities enabled.
Enable Snowflake consumption
Once configured, Snowflake services can immediately discover and query datasets.
This streamlined experience reduces the time required to make Kafka data enterprise-ready.
Enabling Real-Time AI and Analytics Use Cases
By combining StreamNative Kafka Service and Snowflake Horizon Catalog, organizations can enable new classes of real-time data applications:
- AI feature pipelines powered by continuously updated Kafka data
- Real-time operational dashboards
- Continuous ML training pipelines
- Agentic AI workflows powered by governed streaming data
- Data products combining streaming and warehouse datasets
This integration helps organizations unlock the full value of real-time data within their Snowflake AI strategies.
Joint Vision for Real-Time AI Data Platforms
StreamNative and Snowflake share a vision of enabling organizations to unify real-time streaming and governed data platforms to support modern AI-driven enterprises.
This integration represents an important step toward enabling:
- Real-time data as part of enterprise governance strategies
- Reduced complexity in streaming architectures
- AI-ready data pipelines
- Unified data platforms combining streaming and warehouse data
Together, StreamNative and Snowflake help organizations accelerate their journey toward real-time, AI-powered data platforms.
Conclusion
The integration between StreamNative Kafka Service and Snowflake Horizon Catalog enables organizations to connect real-time streaming data with enterprise governance and AI platforms.
By combining StreamNative's modern Kafka architecture with Snowflake's governance and AI ecosystem, organizations can:
- Continuously ingest Kafka data into governed lakehouse environments
- Apply consistent governance policies across streaming datasets
- Simplify real-time data architectures
- Enable AI-ready real-time data platforms
- Unlock greater value from streaming data investments
As enterprises continue modernizing their data platforms, integrating real-time streaming into governed data ecosystems will be critical. StreamNative and Snowflake together enable this next generation of real-time data architecture.
Get Started
Try it yourself: Sign up for a free trial to experience how Kafka data from StreamNative can be seamlessly ingested into the Snowflake Horizon Catalog.




