
The open source data technology framework Apache Pulsar provides a built-in stream processor for lightweight computations, called Pulsar Functions. I recently gave a talk at Pulsar Summit Virtual Conference 2020 on Pulsar Functions. In this post, I will provide a deep dive into its architecture and implementation details.
A Brief Introduction on Pulsar Functions
Pulsar Functions are the core computing infrastructure of the Pulsar messaging system. They enable the creation of complex processing logic on a per message basis and bring simplicity and serverless concepts to event streaming, thereby eliminating the need to deploy a separate system such as Apache Storm or Apache Heron.
These lightweight compute functions consume messages from one or more Pulsar topics, apply user-supplied processing logic to each message, and publish computation results to other topics. The benefits of Pulsar Functions include increased developer productivity, easier troubleshooting and operational simplicity because there is no need for an external processing system.
Moreover, developers do not need to learn new APIs with Pulsar Functions. Any developer that knows the Java programming language, for instance, can use the Java SDK to write a function. For example:
import java.util.function.Function;
public class ExclamationFunction implements Function
@Override
public String apply(String input) {
return input + "!";
}
}
The goal of Pulsar Functions is not to replace heavyweight streaming engines, such as Spark or Flink. It's to use a simple API and execution framework for the most common streaming use cases, such as filtering, routing and enrichment.
Anyone can write a Pulsar Functions, submit it to the Pulsar cluster and use it right away with the built in full lifecycle management capabilities of Pulsar Functions. With its CRUD-based REST API, a developer can also submit functions from any workflow and have them up and running immediately.
Submission Workflows
The workflow process of submitting a function is called a Function Representation. It's structure, called a FunctionConfig, has a tenant, a namespace and a name. The functions consume inputs and outputs, user configurations, secret management support by submitting a JAR file or a Python, for example. You can run one function, or even ten, at once.
public class FunctionConfig {
private String tenant;
private String namespace;
private String name;
private String className;
private Collection inputs;
private String output;
private ProcessingGuarantees processingGuarantees;
private Map userConfig;
private Map secrets;
private Integer parallelism;
private Resources resources;
...
}
After submitting the function, a Submission Check or validations are run to verify that the user has privileges to submit the function to the specific namespace and tenant. For Java, the classes are loaded at the submission time to make sure that the specified classes are actually in the JAR file. All of this is done so that the user gets an error message as quickly as possible, avoiding having to look at the error logs themselves.
The next step is copying the code to the BookKeeper. All of the parameters of the code are represented as FunctionMetaData in a protocol buffer structure as below:
message FunctionMetaData {
FunctionDetails functionDetails ;
PackageLocationMetaData packageLocation;
uint64 version ;
uint64 createTime;
map instanceStates ;
FunctionAuthenticationSpec functionAuthSpec ;
}
This FunctionMetaData structure is all managed by the Function MetaData Manager. From a Worker perspective, the Function MetaData Manager maintains the system of record. It maps from the Fully Qualified Function Name (FQFN) to the Function MetaData that is all backed by the information in the Pulsar Topic with the namespace and function information. It also updates and manages the machine states, as well as any conflicts when multiple Workers are submitted, based on what is submitted, and writes the metadata to the Topic.
Scheduling Workflows
Once the system has accepted a function, it gets scheduled using the Pluggable Scheduler. It's invoked once a new function is submitted and executed only by a Leader. A Leader is elected by having a Failover Subscription on a Coordination Topic. The consumer of the Topic is then elected as the Leader.
The Leader writes assignments to the Topics, known as Assignment Topics. They exist within a particular namespace within Pulsar and are assigned to individual Workers. All Workers know about all Assignments which are compacted and include all system logic such as the FQFN and Instance ID within the Assignment Tables.
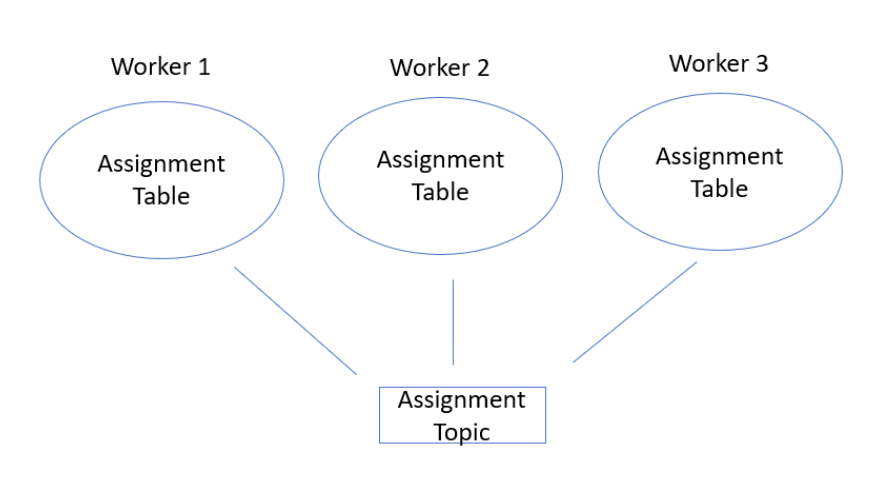
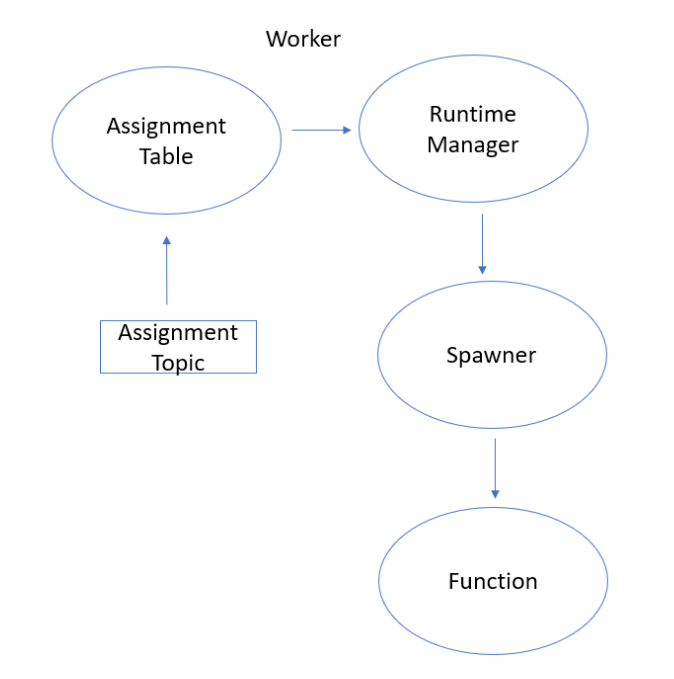
Execution Workflows
The execution workflow is triggered by changes to the Assignment Table. The components within the worker, called the Function RunTime Manager, manage the function lifecycle assignment such as starting or stopping a message using a Spawner.
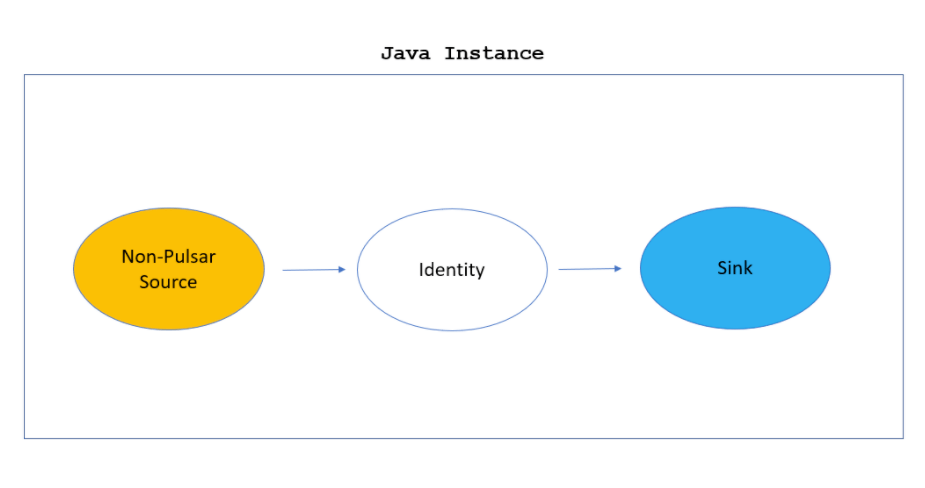
Java Instances and Pulsar IO
The Pulsar Java Instance itself is encapsulated as a Source, a function, which is the actual logic, and a Sink ensemble. Source is a construct that abstracts reading from input Topics and Sink abstracts writing from Topics.
With a regular function, the "Source" is a Pulsar Source that is reading from Pulsar, and a "Sink" is a Pulsar Sink because it writes to a Pulsar Topic.
However, if a non-Pulsar Source is submitted, such as a Google Pub Sub, that becomes a connector using Pulsar IO which acts like a Pulsar Function. The function is an Identity Function and lets data pass through the system. The Pulsar Sink then writes it to a Topic. A non-Pulsar Sink writes to an external system. The ability to consume external data is the reason Pulsar IO is written on top of Pulsar Functions.
Getting Started on Pulsar Functions
Pulsar Functions increase developer productivity, provide easier troubleshooting and operational simplicity because there is no need for an external processing system. They use a simple, lightweight SDK-less API and execution framework for the ninety percent of streaming use cases which are filtering, routing and enrichment. Anyone can write a Pulsar function, submit it to a Pulsar cluster and use it right away with the built in full lifecycle management capabilities of Pulsar Functions. Moreover, with Pulsar IO, non-Pulsar sources can be processed and written to external systems.
To find out more, you can view my presentation here, or join the Apache Pulsar Slack channel to engage directly with the community.




