
We recently announced the Public Preview release of Catalog integration within StreamNative Cloud, marking a significant milestone in enabling seamless data management and analytics in the streaming ecosystem. This integration allows organizations to effortlessly connect their streaming data pipelines to popular Lakehouse catalogs, such as Unity Catalog, Iceberg REST Catalog, and others, unlocking advanced capabilities for real-time data management and analytics. This blog will primarily highlight the integration of Databricks Unity Catalog with StreamNative Cloud. Among the various catalog solutions available, Unity Catalog is the first and only unified catalog for data and AI that is production grade and has garnered significant market interest and adoption. As a result, developing a native integration with Unity Catalog was a strategic priority for StreamNative.
In today’s data-driven world, Lakehouse catalogs play a pivotal role in bridging the gap between streaming and warehousing, offering a unified approach to managing structured and unstructured data at scale. They empower enterprises to streamline data governance, enable schema evolution, and optimize query performance, making them indispensable in modern data architectures.
Although the catalog integration supports multiple options, Lakehouse Storage with Databricks Unity Catalog offers a modern approach to data management, blending the strengths of data lakes and data warehouses. By enabling unified governance and seamless data access, Databricks Unity Catalog provides a centralized solution for managing metadata, permissions, and lineage across all data assets within the Lakehouse architecture. This ensures consistency, scalability, and efficient query performance while empowering organizations to handle diverse workloads, from real-time data streaming to batch analytics. Unity Catalog is a critical component in simplifying data governance and unlocking the full potential of the Lakehouse paradigm for modern data-driven enterprises.
StreamNative Cloud provides seamless, out-of-the-box integration with Databricks Unity Catalog, enabling users to stream data directly into the Databricks Data Intelligence Platform within seconds.
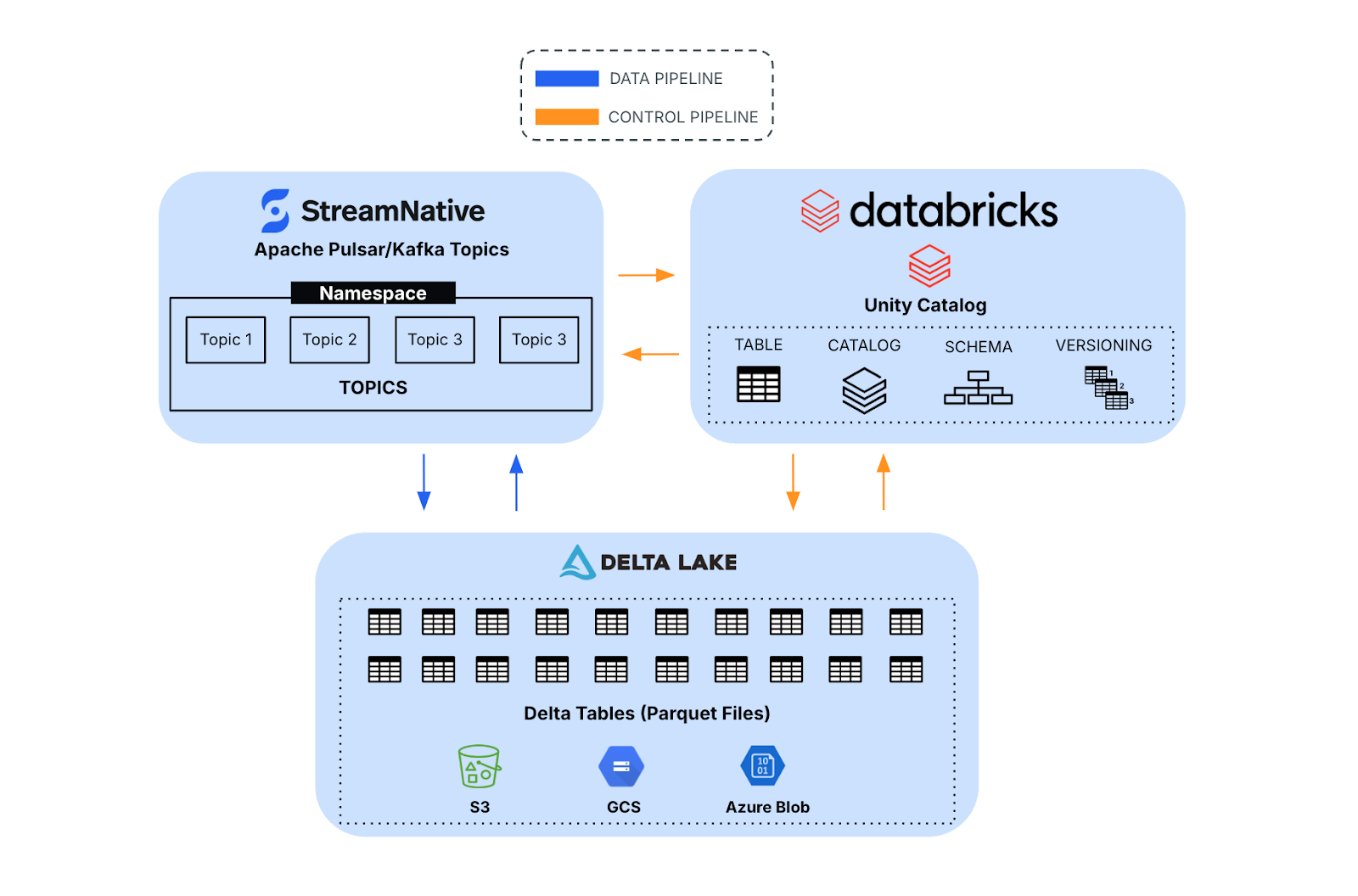
Integration Built On Open Standards
StreamNative's integration with Databricks Unity Catalog is built on open standards,
- Kafka protocol – Enables scalable, real-time data streaming.
- Delta Lake – Provides reliable, ACID-compliant storage and transaction management. Delta Lake is optimized for high-throughput ingestion, appending new data efficiently without frequent updates or deletes, making it ideal for streaming and batch ingestion from Apache Kafka and Pulsar.
- Unity Catalog – Ensures unified data governance and access control for data and AI assets across the Lakehouse.
The importance of a simplified experience to ingest data directly into a Lakehouse, ready to be consumed by AI applications, cannot be overstated—it streamlines access, enhances governance, and accelerates real-time analytics and AI outcomes. Here’s a quote from Reynold Xin, Co-Founder and Chief Architect at Databricks who underscores this vision.
We're extremely excited about StreamNative's integration with Unity Catalog. Analytics on real-time data is one of the core use cases of Databricks, and the rapid growth in AI has increased the need for real-time data exponentially. With this release, our customers gain an efficient and simple way to get access to the data that their mission-critical analytics and AI applications require and have it immediately benefit from the unified governance that Unity Catalog provides." - Reynold Xin, Co-Founder and Chief Architect at Databricks
StreamNative Cloud: The Ideal Ingestion Layer for Databricks Unity Catalog
StreamNative Cloud serves as a powerful ingestion layer for Databricks Unity Catalog, enabling seamless, real-time data streaming directly into Databricks Data Intelligence Platform. StreamNative Cloud allows enterprises to ingest, process, and manage high-velocity data streams across diverse sources while maintaining schema consistency and lineage through Unity Catalog. This streamlined integration not only simplifies data management but also accelerates data accessibility for downstream analytics and AI workloads, empowering organizations to unlock actionable insights from fresh, AI-ready data at scale.
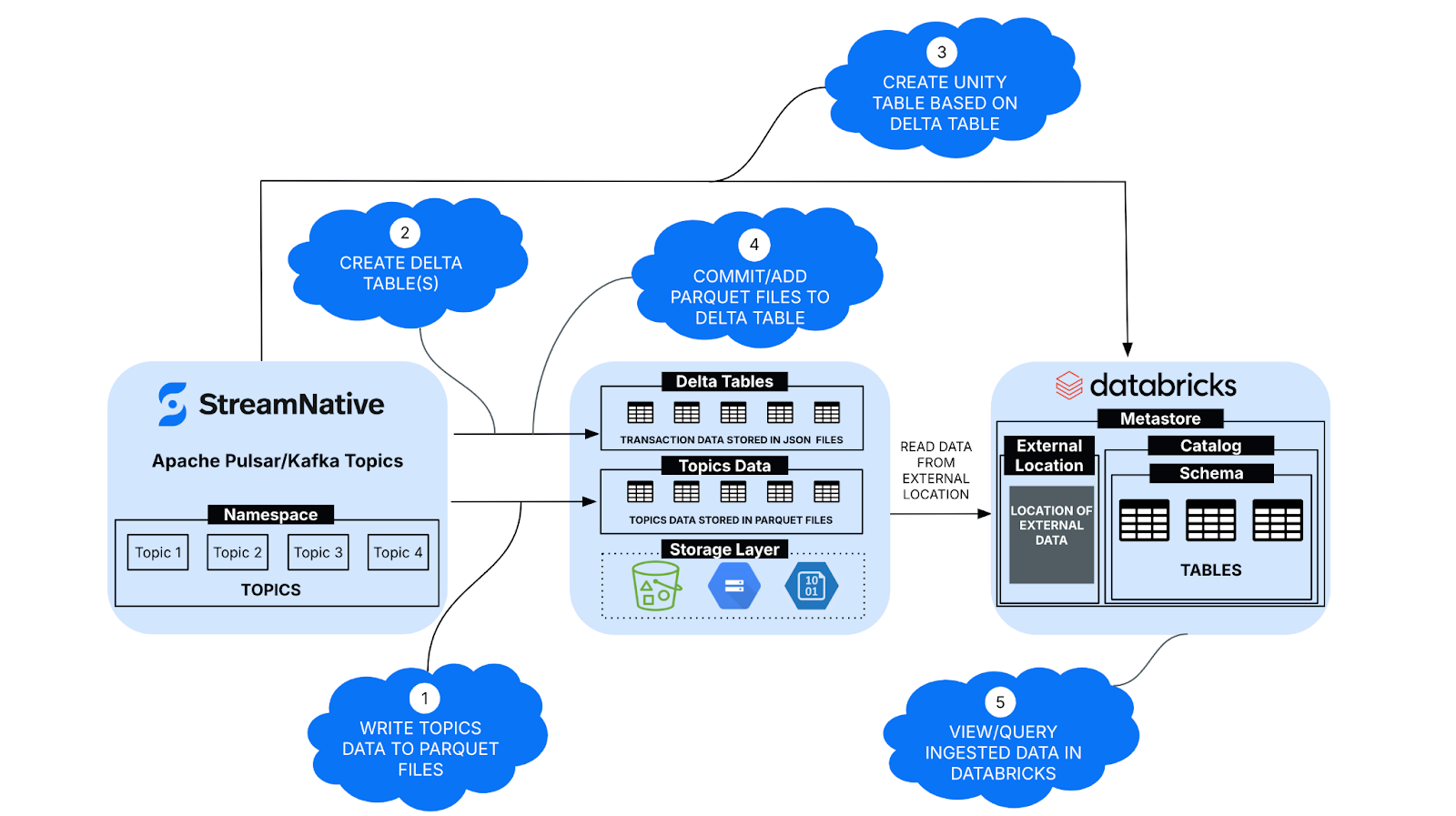
The integration of StreamNative Cloud with Databricks Unity Catalog leverages Unity Catalog APIs , Delta Lake SDK, and Databricks SDK to enable seamless connectivity between real-time data streaming pipelines and the Lakehouse ecosystem.
- Ingest and Store Topic Data in Parquet Format – Incoming data from various sources is written to a cost-efficient storage service such as AWS S3, Google Cloud Storage, or Azure Blob Storage in Parquet format.
- Create Delta Tables – StreamNative Cloud utilizes the Delta SDK to create a Delta Table, which includes a dedicated _delta_logs folder where all transactions are logged in JSON format.
- Register Unity Table – The Unity Catalog API is invoked to create a Unity Table, defining the schema and specifying the storage location of the corresponding Delta Table.
- Commit Parquet Files to Delta Table – The Parquet files generated in Step 1 are added to the Delta Table as transactions, which are recorded in JSON log files within the Delta Table structure.
- Query and Analyze Ingested Data in Databricks – Users can access and analyze the ingested data within the Databricks workspace by querying the registered catalog.
This native integration enables users to effortlessly configure a cluster for streaming data directly into Databricks with just a few clicks, allowing them to quickly gain insights from their data.StreamNative's integration with Unity Catalog provides end-to-end lineage, enabling full visibility into data as it moves from ingestion to processing, storage, and consumption. This ensures better governance, compliance, and debugging, allowing organizations to track data flows seamlessly across their streaming and analytics pipelines.
Streaming Data to Lakehouse Storage: A Walkthrough of Direct Ingestion and Cost-Effective Offloading
StreamNative Cloud provides a seamless, out-of-the-box solution for streaming data directly into Lakehouse Storage while enabling its publication in Databricks Unity Catalog for efficient discovery and processing. Watch the workshop Augment Your Lakehouse with Streaming Capabilities for Real-Time AI to get an end-to-end overview of StreamNative’s integration with Databricks Unity Catalog.
Setup Databricks environment
Before initiating the integration of Databricks with StreamNative Cloud, please ensure the following prerequisites are fulfilled:
Setup StreamNative Cluster
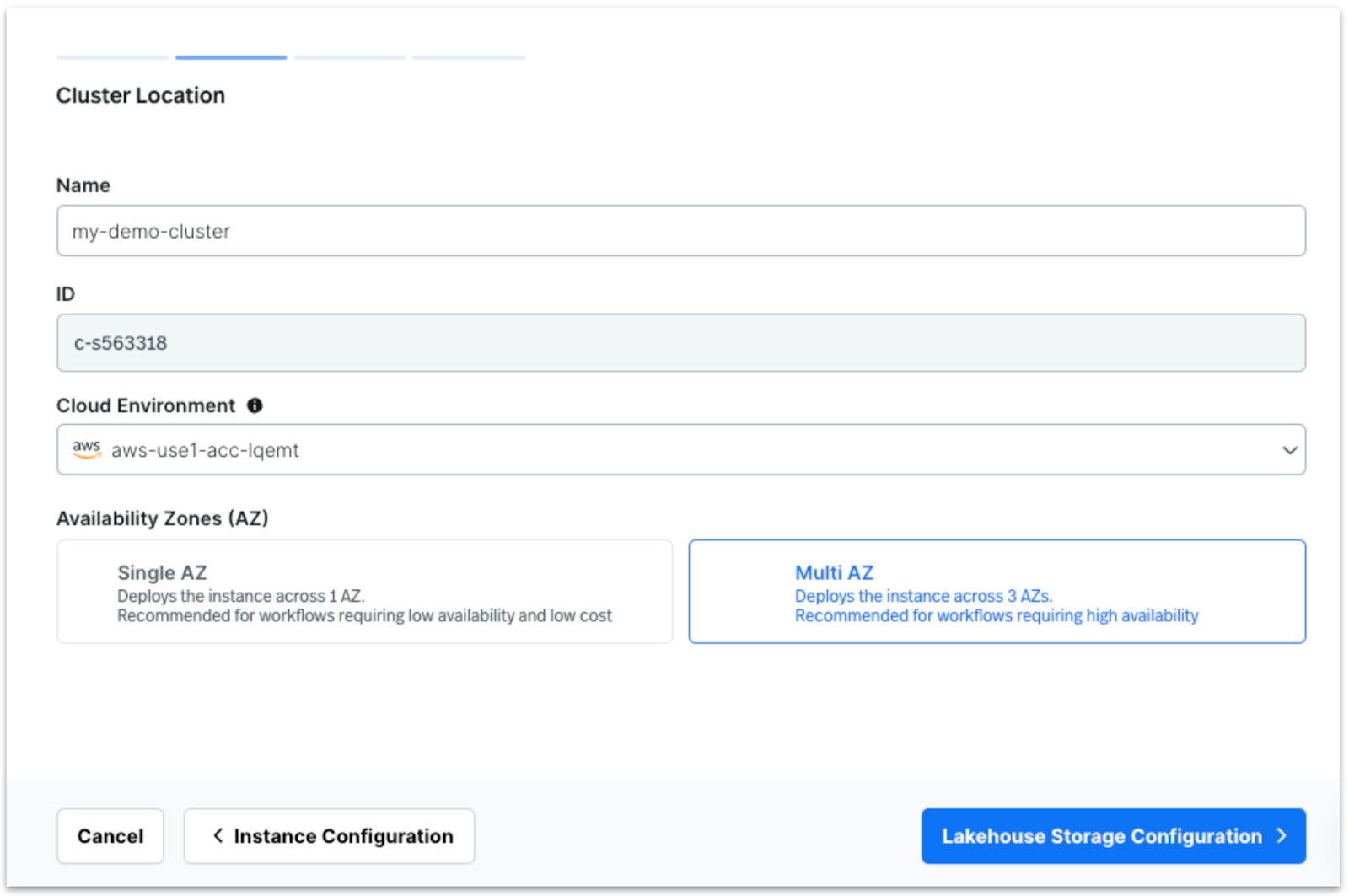
To create a new instance, enter the instance name, configure the Cloud Connection, select the URSA Engine, and then specify the Cluster Location.

To create a cluster, provide the cluster name, select the Cloud Environment and Availability Zone, and proceed to configure the Lakehouse Storage settings.
There are two options for selecting a storage location: you can either specify your own storage bucket or utilize a pre-created bucket provided by the BYOC environment. In this example, we will use the pre-created bucket.To configure Databricks Unity Catalog, select Unity Catalog as the catalog provider and complete the remaining catalog configuration details. Click Deploy to finish catalog configuration.
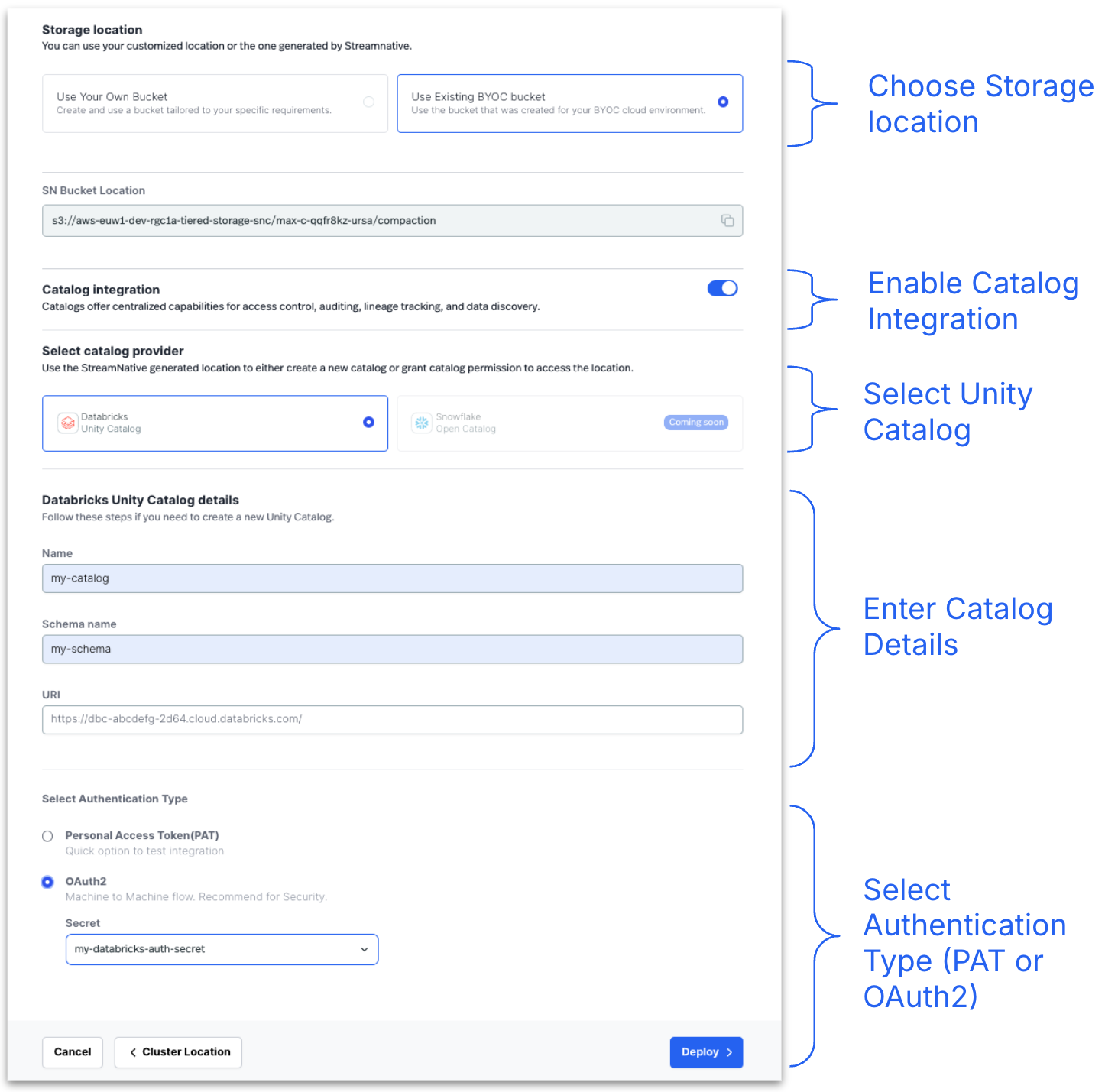
Click Deploy to complete cluster creation.
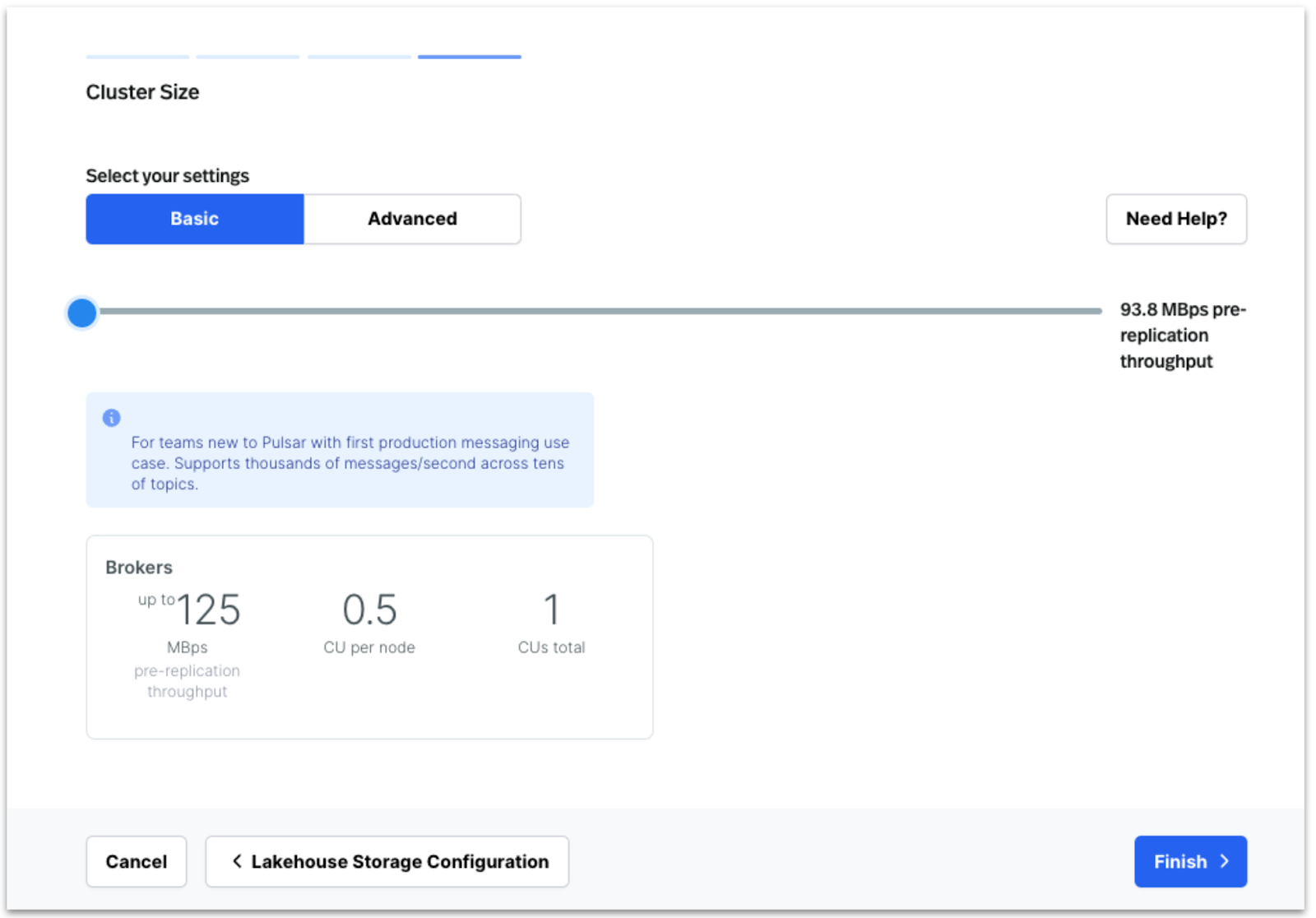
Once the cluster is created, populate the StreamNative cluster to stream data directly into storage by creating and running a producer, where it is stored as Delta tables and published to Databricks Unity Catalog for discovery and analysis.
Authentication Types Supported With Databricks Unity Catalog
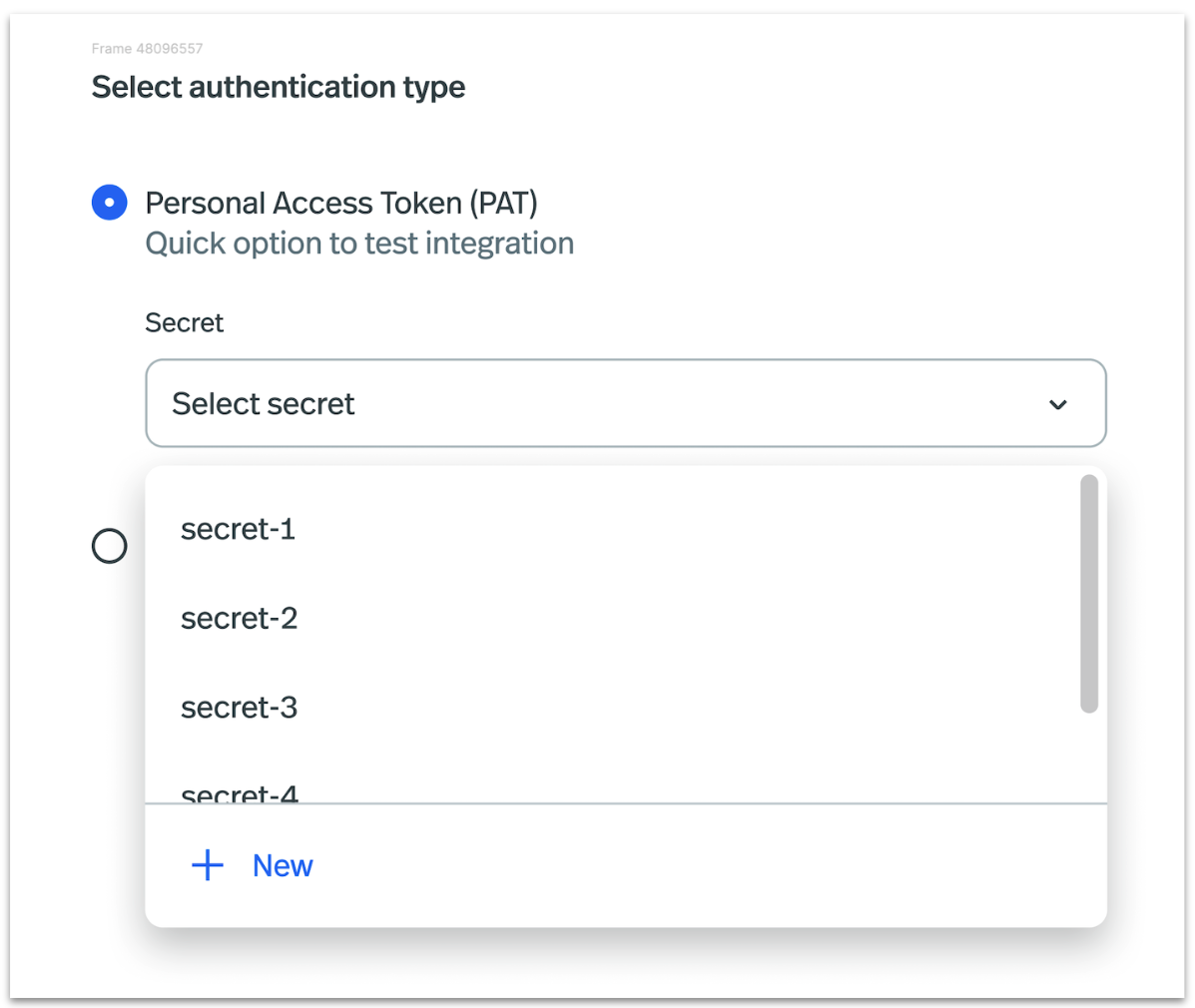
StreamNative supports two types of authentication with Databricks Unity Catalog.
Personal Access Token (PAT) : A Databricks Personal Access Token is a secure authentication method that allows users to access Databricks REST APIs and command-line interfaces without sharing their login credentials.
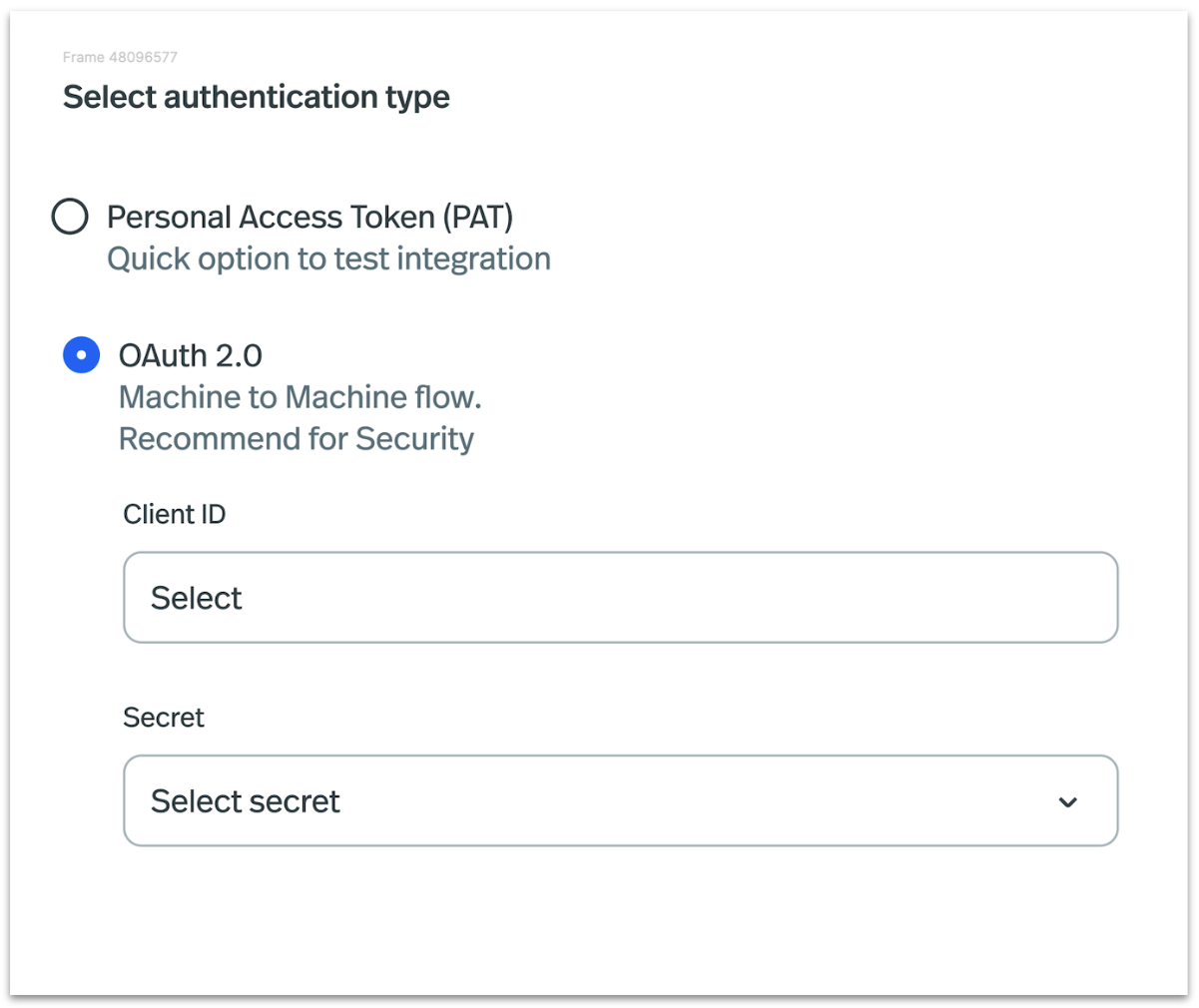
OAuth 2 (M2M) : The OAuth2 Machine-to-Machine authentication flow enables secure, automated communication between servers or applications by using client credentials to obtain access tokens for API authorization without user involvement.
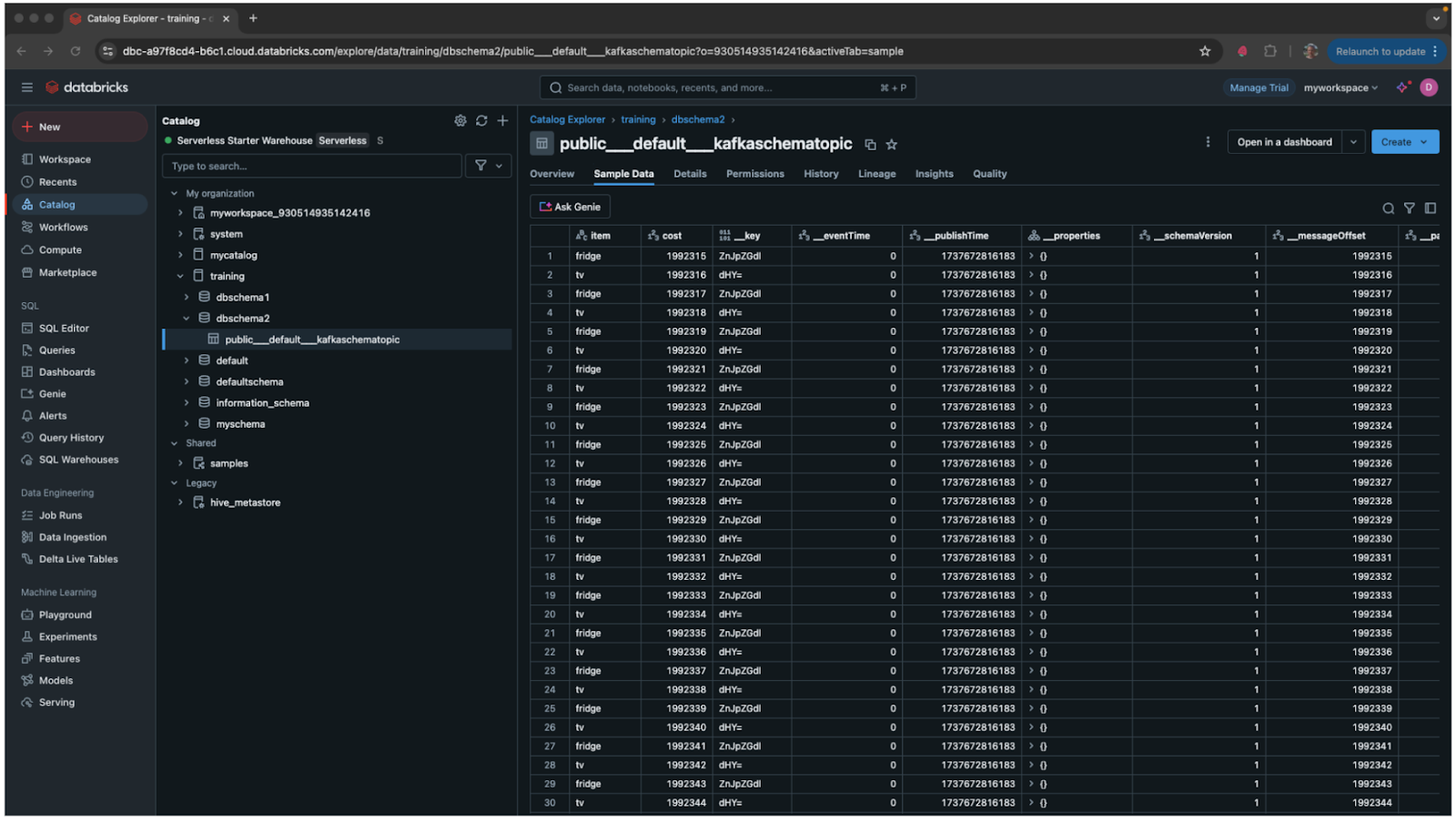
Review Ingested Data In Databricks Unity Catalog
Once ingested, the data becomes discoverable within the catalog and can be efficiently queried for analysis. The Delta tables generated by StreamNative Cloud are seamlessly integrated and visible within the designated schema in the catalog.
Conclusion
The Public Preview release of Catalog integration within StreamNative Cloud represents a transformative step in connecting real-time data streaming pipelines to Lakehouse Storage, particularly through Databricks Unity Catalog. Built on open standards like Apache Kafka, Delta Lake, and Unity Catalog, this integration ensures interoperability while providing robust data governance, seamless schema evolution, and efficient metadata management. Organizations can ingest data directly into Delta tables, enable effortless discovery in Unity Catalog, and streamline analytics workflows, making it easier to extract actionable insights from streaming data. With end-to-end data lineage, organizations gain full visibility into data movement, transformations, and consumption, ensuring better governance, compliance, and debugging. Explore how this open, standards-based integration can revolutionize your data-driven strategy.
Here are a few resources for you to explore:
- Checkout StreamNative's recent benchmark about Ursa Engine: See how Ursa sustains a 5GB/s Kafka workload at just 5% of the cost of traditional streaming engines like Kafka and Redpanda.
- Read the detailed architectural blog post of Ursa Engine: Learn how leaderless architecture and lakehouse storage reduce 95% of Kafka cost.
- Watch our workshop: Augment Your Lakehouse with Streaming Capabilities for Real-Time AI to get an end-to-end overview of StreamNative’s integration with Databricks Unity Catalog.
- Documentation for Unity Catalog Integration : Follow these steps to integrate StreamNative Cloud with Databricks Unity Catalog.
- Join our joint webinar: Don’t miss the Databricks and StreamNative webinar on February 20th, where we’ll explore cutting-edge integrations.
Try it yourself: Sign up for a trial to explore StreamNative's Ursa Engine and experience the power of real-time data in action.




