
Over the past few years, we have used different streaming solutions for a variety of use cases. They have helped us meet different requirements for scalability, high availability, disaster recovery, load balancing, low costs, multi-tenancy, and many more. With so many tools in the market, streaming becomes more like a battlefield where each character spares no effort to survive and thrive.
In this blog, we will first talk about the streaming war facing different streaming systems and what tools they should have in their arsenal. Next, we will compare each of them and explain why we think Apache Pulsar will win the battle. Lastly, we will demonstrate how to migrate to Pulsar from other platforms.
Game and arsenal
Simply put, the game has producers that publish messages to the middleware solution, which are then consumed by applications or microservices. They can either keep them to themselves or sink them into a big data store.
If you want to win a battle, you need to have sharpened tools and sufficient ammunition. Similarly, when choosing a streaming framework that backs your production workloads, you want it to have the best features so you can be well-prepared to ace any production use cases. Here are some of the weapons that are required for a modern streaming arsenal.
- Real-time messaging. Today, speed plays an important role in a variety of use cases. For an e-commerce application, for example, if there's something wrong on the checkout page, you want to detect it and fix it as soon as possible. Otherwise, you may lose business for the delayed time, as your customers have poor user experiences like payment failure.
- Scalability. Mobile phones, IoT devices, and microservices are producing large amounts of data every day. Therefore, your application needs to be able to work with a framework that can scale flexibly to handle the traffic if required.
- High availability. If your website or application is not highly available, you will effectively lose revenue during the downtime (for example, due to single points of failure).
- Disaster recovery. If your data is synchronized and replicated across regions, you need to have the redundancy to recover from any disaster situation.
- Load balancing. Load balancing allows you to distribute data across your storage and computing clusters judiciously. It prevents nodes from being more loaded or less loaded. It is also one of Pulsar’s distinguishing features.
- Low cost of operations. Cost is undoubtedly very important for the infrastructure you are using. Currently, we are running Pulsar at a low operation cost. We will compare the costs of using Kafka, Pulsar, and Kinesis later.
- Multi-tenancy. A multi-tenant system allows you to separate out different use cases and run them in isolation. If there are heavy loads in one of the use cases, only that one is stressed while other parts of the cluster work properly.
- Flexibility. For a given use case, you may need high availability while another may require strong consistency. A flexible system should support configurations for varied use cases that allow you to perform operations at different tenancy levels.
Game characters
Next, we will be looking at the pros and cons of popular streaming frameworks including Apache Pulsar, Apache Kafka, Amazon Kinesis Data Streams, and NATS.
Apache Pulsar
As an open-source project, Pulsar is completely driven by the community. If there are any major improvements, like API changes, the community will send out a voting request so that community members can discuss how Pulsar moves forward.
Pulsar has a multi-layered architecture where storage is separated from computing. This means that you can scale either part independently. For us, as we deploy our Pulsar cluster on AWS, this loosely-coupled structure makes it very easy to select the type of nodes for scaling if required.
Multi-tenancy achieves different levels of resource isolation. It is one of Pulsar’s enterprise features from day one. All other features that came after were well integrated with all of its enterprise features.
On the flip side, since Pulsar is a modular system, you may feel intimidated when you start installing it for the first time. The deployment time is longer than Kafka and Kinesis. That said, if you are already using Kubernetes, you can use operators to quickly deploy Pulsar. Another thing that may cause trouble to Pulsar users is its ecosystem (like connectors), which is relatively small compared to Kafka. However, this is by no means a problem as we do have workarounds, which will be covered later.
Apache Kafka
Kafka is also an open-source Apache project. It is battle-tested for the longest time in the streaming space with a mature community and an amazing ecosystem of connectors.
Unlike Pulsar, Kafka has a monolithic architecture, which means storage and computing are bundled together. When scaling your Kafka cluster, you may find it complicated and tricky to select the right types of nodes (for example, on AWS). Therefore, it is less flexible compared with Pulsar in terms of scaling.
Pulsar vs. Kafka
Before we introduce the next character, let’s look at how Pulsar performs compared with Kafka. We carried out extensive performance tests on both Pulsar and Kafka and ultimately chose Pulsar. The following is a summary of our understanding based on the tests.
- 2.5x maximum throughput compared to Kafka
- 100x lower single-digit publish latency than Kafka
- 1.5x faster historical read rate than Kafka
- Preinstalled schema registry in Pulsar
- Pulsar is enterprise-ready from day one
- Local disk (Kafka) vs. Tiered/decoupled storage (Pulsar)
- Kafka wins on community support and ecosystem
Our tests show that Pulsar outperforms Kafka in terms of throughput, latency, and historical read rate. Pulsar features a segment-oriented architecture for every topic (partition), so you don’t have the problem of some topics being hot but others being cold. The data is spread wonderfully across the storage nodes of Pulsar, which are managed by BookKeeper. This is also the reason why Pulsar has faster historical reads.
Pulsar has almost everything open-sourced. Its schema registry is already integrated with Pulsar's broker. Kafka, on the other hand, does not have it in the open-source version.
As mentioned above, Pulsar is enterprise-ready with an arsenal of effective weapons. Geo-replication has been one of them since day one. As opposed to Pulsar, Kafka implements geo-replication through MirrorMaker while there are still some rough edges. Some features are probably not working that well with it.
There are also many other blogs comparing Pulsar and Kafka. For more information, see the Reference section below.
Amazon Kinesis Data Streams
Amazon Kinesis Data Streams is a serverless streaming data service provided by AWS. You can use it to collect and process large streams of data in real time. It’s available as a service so you can easily get started with only a few clicks.
The benefit of using Amazon Kinesis Data Streams is that it requires less maintenance work as AWS manages the infrastructure for you. Additionally, it works seamlessly with other AWS services like S3, DynamoDB, and Lambda.
However, it is not an ideal solution for us due to the following reasons:
- It is more costly compared to Pulsar, which will be explained later.
- It is a closed-source system, which means we cannot customize it based on our needs.
- As AWS manages everything for you, it is less flexible.
- ~ The retention period is fixed at 24 hours or up to 365 days. Storing data for a longer period of time than your need means unnecessary overhead.
- ~ The average record size cannot be more than 1 MB.
- ~ Data is always replicated to 3 availability zones (AZs). If your use case does not require more than 2 AZs, it comes with more cost.
- Vendor lock-in.
NATS
Another character in the game is NATS, a CNCF incubating open-source project. It is a connective technology that powers modern distributed systems.
The design philosophy behind NATS is simple, agile, performant, secure, and resilient. Users can easily get started with NATS as it supports various flexible deployments. You can literally deploy it anywhere (on-premises, IoT, edge, and hybrid use cases). Additionally, it provides a base set of functionalities and qualities, also known as Core NATS, which supports models like Publish-Subscribe, Request-Reply, and Queue Groups.
NATS has a built-in distributed persistence system called JetStream. It enables new functionalities and higher qualities of service on top of the base Core NATS. However, it's not as mature as Kafka or Pulsar, and it still has much room for improvement, especially in disaster recovery.
For the consumer metadata like offsets, we want to duplicate and store them on different servers for better redundancy. As NATS makes a raft group for every consumer application, millions of consumers mean millions of Raft groups. This will cause considerable pressure on the network.
To learn more about NATS, see The power of NATS: Modernising communications on a global scale.
With a basic understanding of these systems, we think Pulsar is a better choice for cloud-native applications. For IoT, edge, or hybrid use cases, we recommend NATS because of its lightweight server. Users can deploy NATS anywhere and use one cluster that spreads across different environments like cloud, IoT devices, edge, and even on-premises.
Let the battle begin
To make a more comprehensive evaluation, we conducted some performance tests in one of our use cases and compared their respective costs. Here are the rules of the game:
- Ingest 12 TB/day: about 5 million messages daily with a size of 2.5 MB per message
- Retention period: 24 hours
- Replication factor: 2 (24 TB/day)
- Data stored in multiple availability zones
- Producers/consumers preferably in the same availability zone as stream data
Pulsar cost
Figure 1 depicts the schematic architecture of our Pulsar cluster.
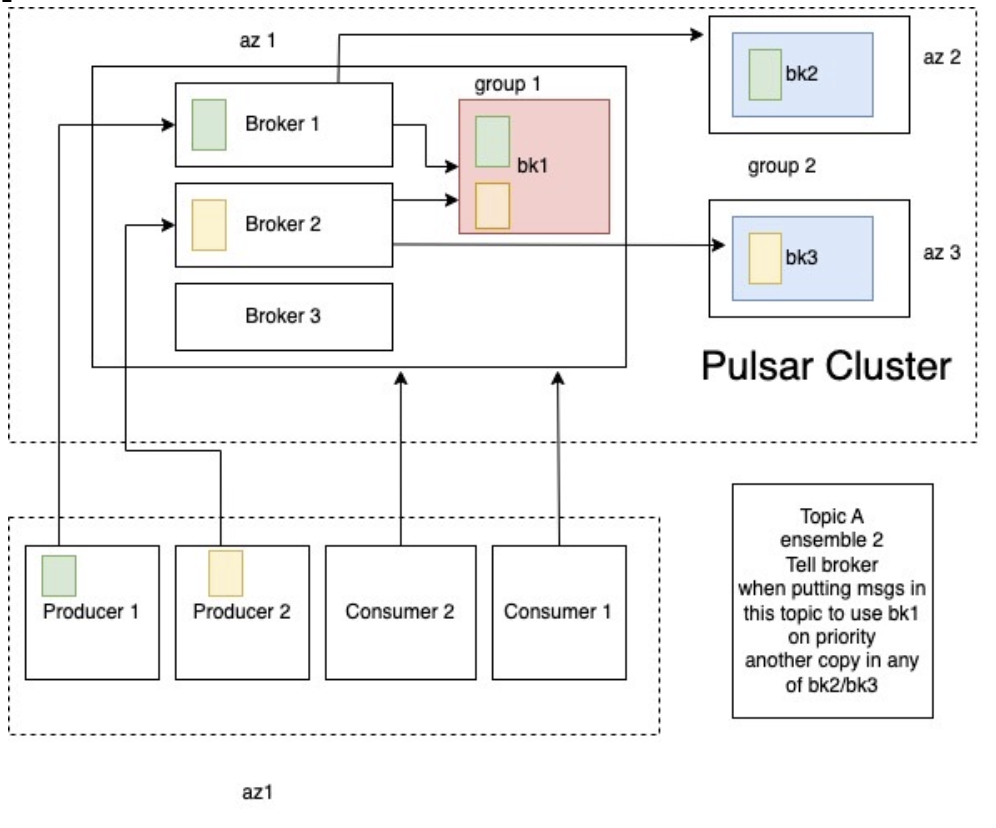 Figure 1. Pulsar cluster schematic architecture
We used the following commands to configure bookies and affinity groups in different AZs, with group-bookie1 (bk1) being the primary group and group-bookie2 (bk2 and bk3) being the secondary group. Because Pulsar brokers are stateless, we put all the brokers in the same AZ (az1).
Figure 1. Pulsar cluster schematic architecture
We used the following commands to configure bookies and affinity groups in different AZs, with group-bookie1 (bk1) being the primary group and group-bookie2 (bk2 and bk3) being the secondary group. Because Pulsar brokers are stateless, we put all the brokers in the same AZ (az1).
bin/pulsar-admin bookies set-bookie-rack --bookie pulsar-bookie-1:3181 --hostname pulsar-bookie-1:3181 --groupgroup-bookie1 --rack rack1
bin/pulsar-admin bookies set-bookie-rack --bookie pulsar-bookie-2:3181,pulsar-bookie-3:3181 --hostname pulsar-bookie-2:3181,pulsar-bookie-3:3181 --group group-bookie2 --rack rack2
bin/pulsar-admin namespaces set-bookie-affinity-group public/default --primary-group group-bookie1 --secondary-group group-bookie2
These configurations mean that whenever a broker is trying to write data on bookies, it will put one copy on bk1 and the other on either bk2 or bk3. This helps reduce data transfer costs between the AZs.
If brokers need to be deployed in different AZs, you can use the following command to set the primary brokers for the namespace.
bin/pulsar-admin ns-isolation-policy set --auto-failover-policy-type min_available --auto-failover-policy-params min_limit=1,usage_threshold=80 --namespaces public/default --primary pulsar-broker-node-1 --secondary pulsar-broker-node-2
Our Pulsar cluster was deployed on AWS instances. Table 1 and Table 2 show the breakdown of the cost.
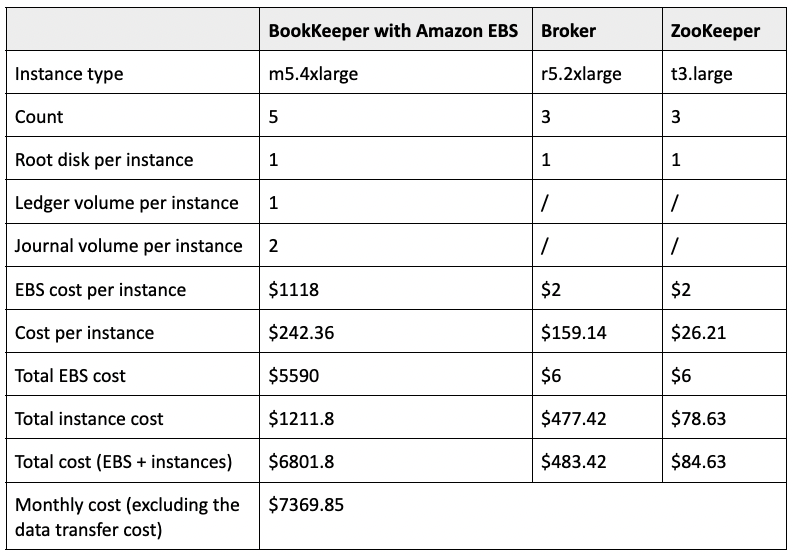 Table 1. Pulsar cluster cost breakdown
Table 1. Pulsar cluster cost breakdown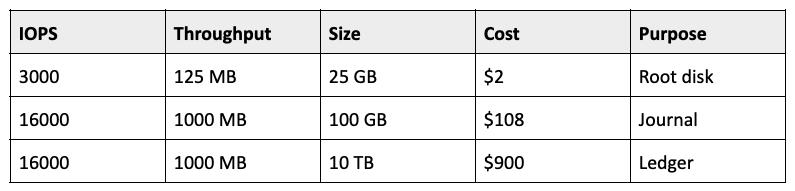 Table 2. BookKeeper EBS monthly cost
We deployed bookies on m5.4xlarge instances (16 vCPUs and 64 GB of memory), with 10 TB of storage attached to each of them for ledgers. We chose r5.2xlarge (8 vCPUs and 64 GB of memory) instances for brokers and t3.large (2 vCPUs and 8 GB of memory) instances for ZooKeeper. The total monthly cost was about $7.4K without data transfer. If we included the data transfer cost for 360 TB (about 12 TB of data per day as mentioned above), it would add another $7K, so the total monthly cost would be about $14K.
Table 2. BookKeeper EBS monthly cost
We deployed bookies on m5.4xlarge instances (16 vCPUs and 64 GB of memory), with 10 TB of storage attached to each of them for ledgers. We chose r5.2xlarge (8 vCPUs and 64 GB of memory) instances for brokers and t3.large (2 vCPUs and 8 GB of memory) instances for ZooKeeper. The total monthly cost was about $7.4K without data transfer. If we included the data transfer cost for 360 TB (about 12 TB of data per day as mentioned above), it would add another $7K, so the total monthly cost would be about $14K.
Kafka cost
Figure 2 depicts the schematic architecture of our Kafka cluster. Kafka has the same options available in replica assignment which uses a comma-separated list of preferred replicas.
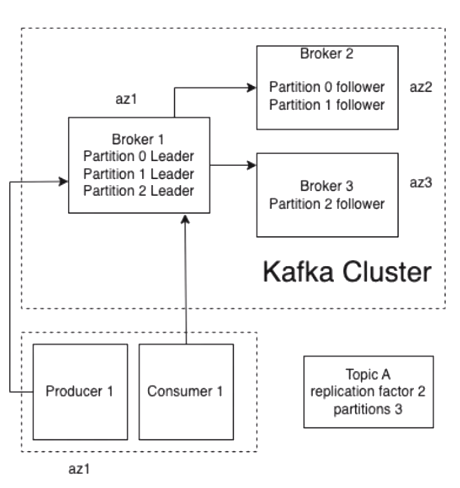 Figure 2. Kafka cluster schematic architecture
We used the following commands to assign replicas.
Figure 2. Kafka cluster schematic architecture
We used the following commands to assign replicas.
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic topicA --replica-assignment 0:1,0:1,0:2 --partitions 3
bin/kafka-topics.sh --alter --zookeeper localhost:2181 --topic topicA --replica-assignment 0:1,0:1,0:2,0:2 --partitions 4
In order to have all the data available in one AZ, broker 1 should have the leaders of all partitions. In Kafka, writes only go to the leaders. In our case, all the data was available in one broker for less data transfer costs between the AZs.
Whenever a broker goes down, Kafka will restore the leadership to the broker that comes first in the list with the preferred replicas. This is the default behavior enabled in the latest version of Kafka with auto.leader.rebalance.enable=true.
In our performance test, the Kafka cluster was managed by Amazon MSK, using 5 m5.4xlarge broker instances, each having 16 vCPUs, 64 GB of memory, and 10 TB of storage. There is 50 TB in total, enough for 24 TB of data (replication factor set to 2) per month. In addition to the infrastructure, we had to pay for the intra-region data transfer cost between the AZs. The total monthly cost was almost $20K.
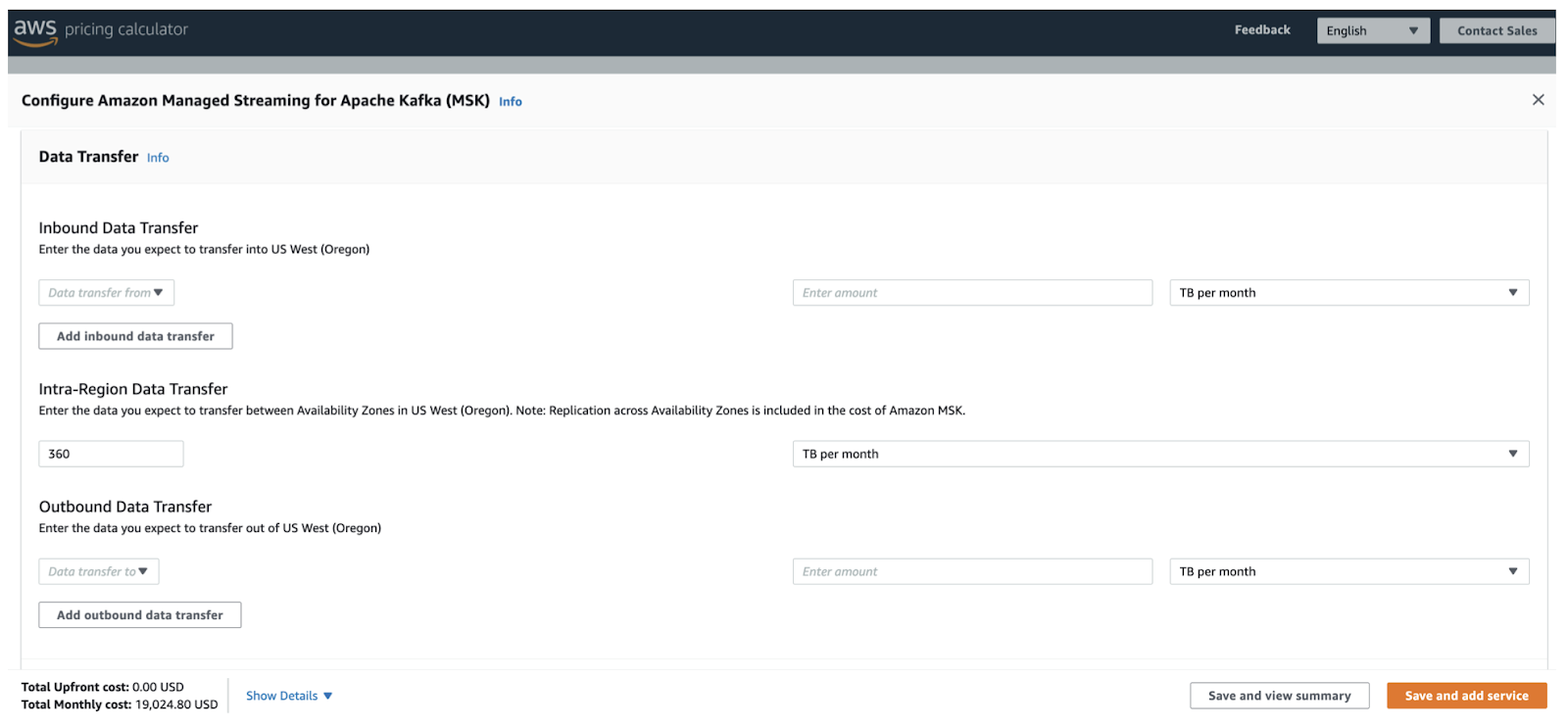 Figure 3. Kafka cluster monthly cost
Figure 3. Kafka cluster monthly cost
Kinesis Data Streams cost
As Amazon manages the Kinesis Data Streams service for us, we will only focus on the cost in this section.
As mentioned above, the average message size cannot be more than 1 MB for Kinesis Data Streams. Our internal team came up with a workaround that they put messages in S3 and provided the S3 path inside Kinesis. This means that the solution had extra S3 costs. To make up for that, I put 180 baseline records per second as per 1 MB of data.
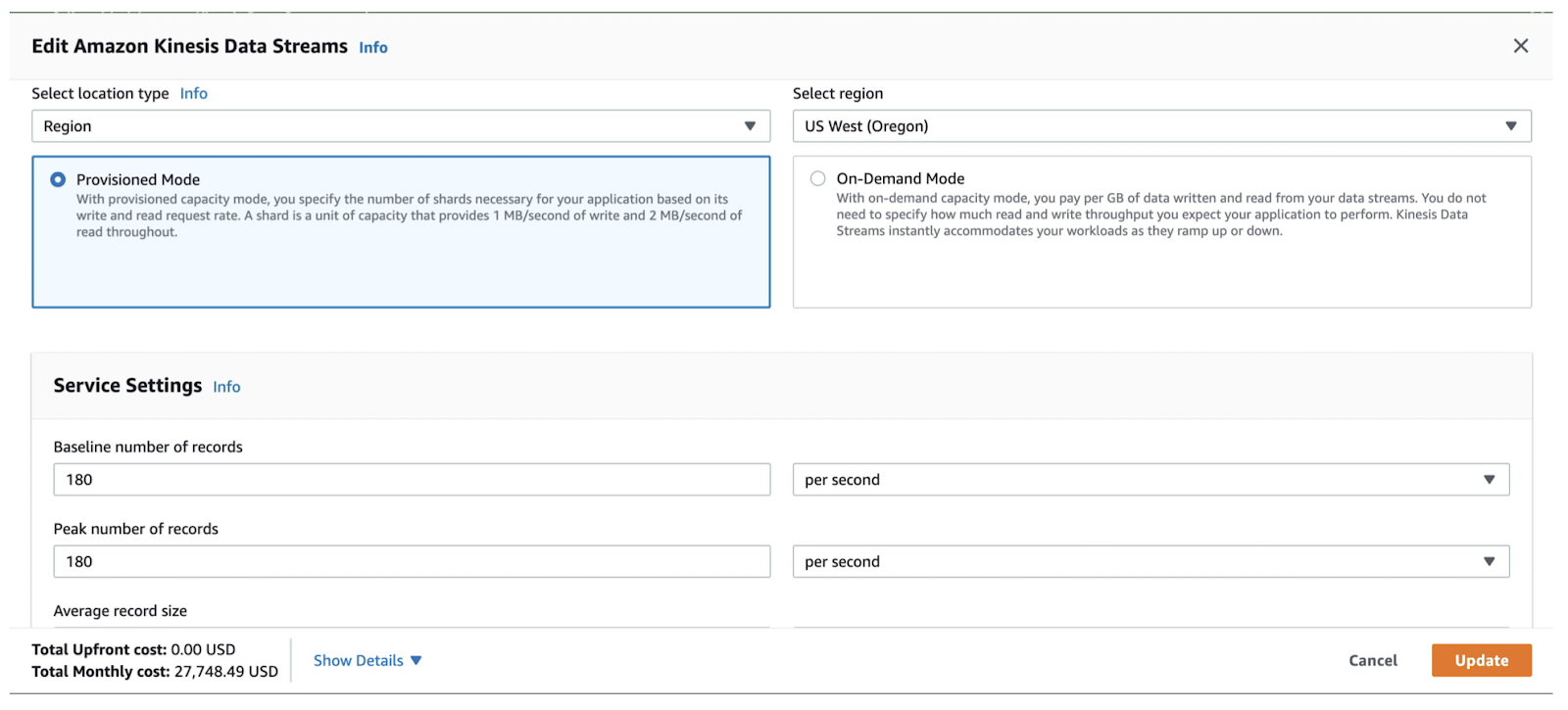 Figure 4. 180 baseline records per second
We set the buffer for growth to 20% and the number of enhanced fan-out consumers to 3. Each consumer had dedicated throughput. If you increase the number of fan-out consumers, the cost will increase linearly.
Figure 4. 180 baseline records per second
We set the buffer for growth to 20% and the number of enhanced fan-out consumers to 3. Each consumer had dedicated throughput. If you increase the number of fan-out consumers, the cost will increase linearly.
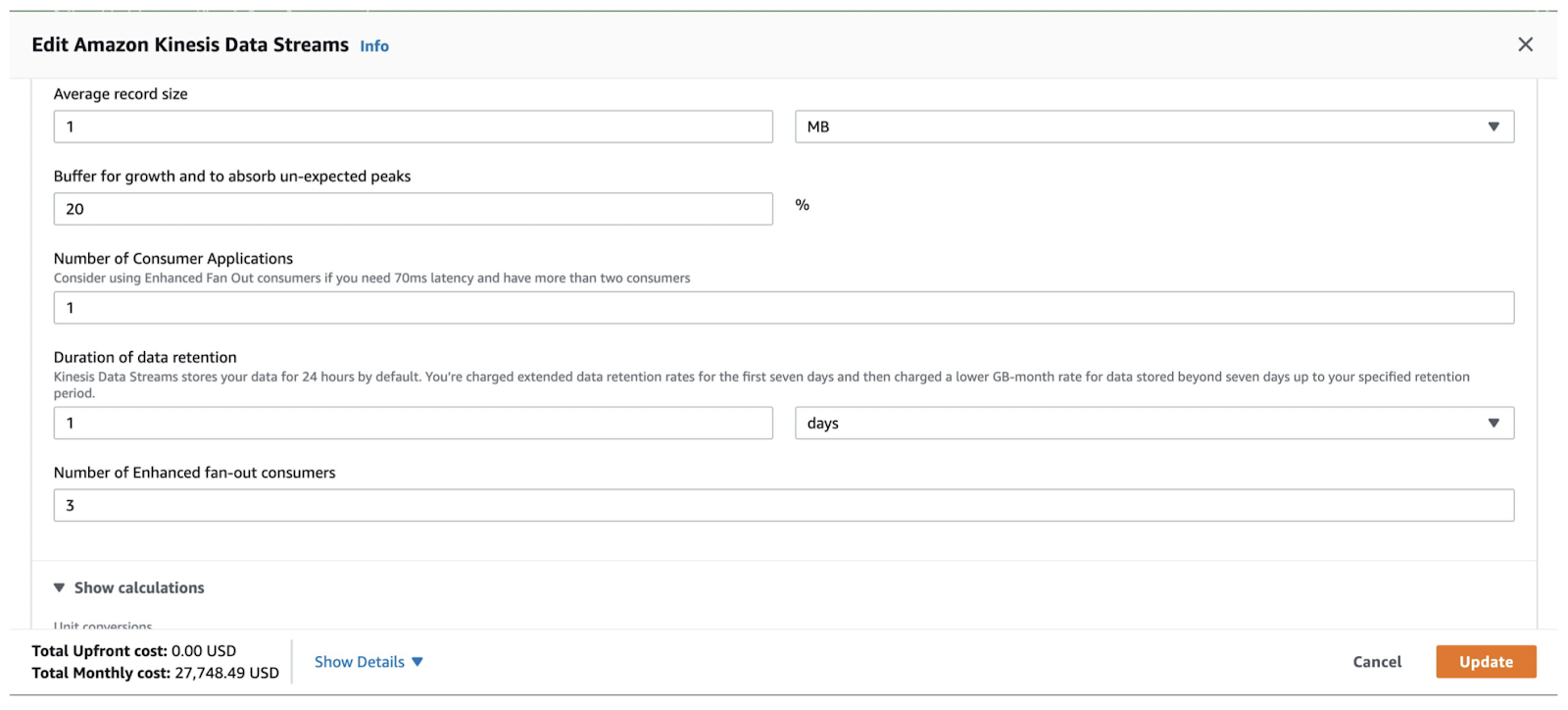 Figure 5. The growth buffer and the number of enhanced fan-out consumers
The total monthly cost reached about 28K. Figure 6 shows the cost details.
Figure 5. The growth buffer and the number of enhanced fan-out consumers
The total monthly cost reached about 28K. Figure 6 shows the cost details.
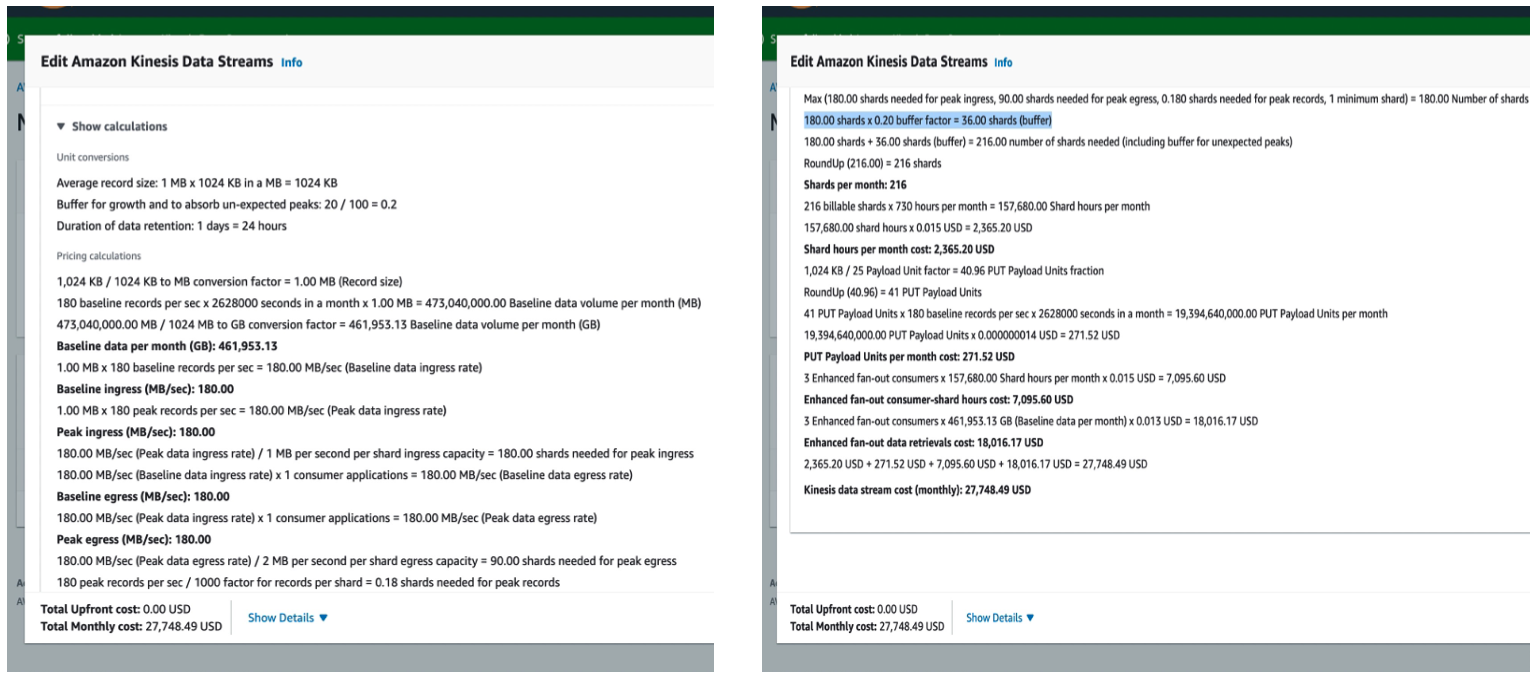 Figure 6. Amazon Kinesis Data Streams monthly cost
The results show that Pulsar stands out as the most cost-effective option with only $14K per month compared to Kafka ($20K) and Kinesis ($28K). That's why our primary selection for streaming data is Pulsar.
Figure 6. Amazon Kinesis Data Streams monthly cost
The results show that Pulsar stands out as the most cost-effective option with only $14K per month compared to Kafka ($20K) and Kinesis ($28K). That's why our primary selection for streaming data is Pulsar.
Change the game: Migrate to Pulsar
Now that we know how Pulsar aces the game, let’s look at how to migrate to Pulsar from other systems like Kafka.
Kafka-on-Pulsar (KoP)
KoP leverages a Kafka protocol handler on Pulsar brokers, which processes Kafka messages. It allows you to easily migrate your existing Kafka applications and services to Pulsar without modifying the code. You only need to make minor changes on the Pulsar server side. Clients do not even need to know whether they are connected to Kafka or Pulsar. Specifically, to get started with KoP, you need to do the following:
- Add KoP configurations (for example, messagingProtocols and entryFormat) to broker.conf or standalone.conf.
- Add the protocol handler (a nar file) to your server.
- Remember to change the Kafka cluster URL to the Pulsar cluster URL in your client code.
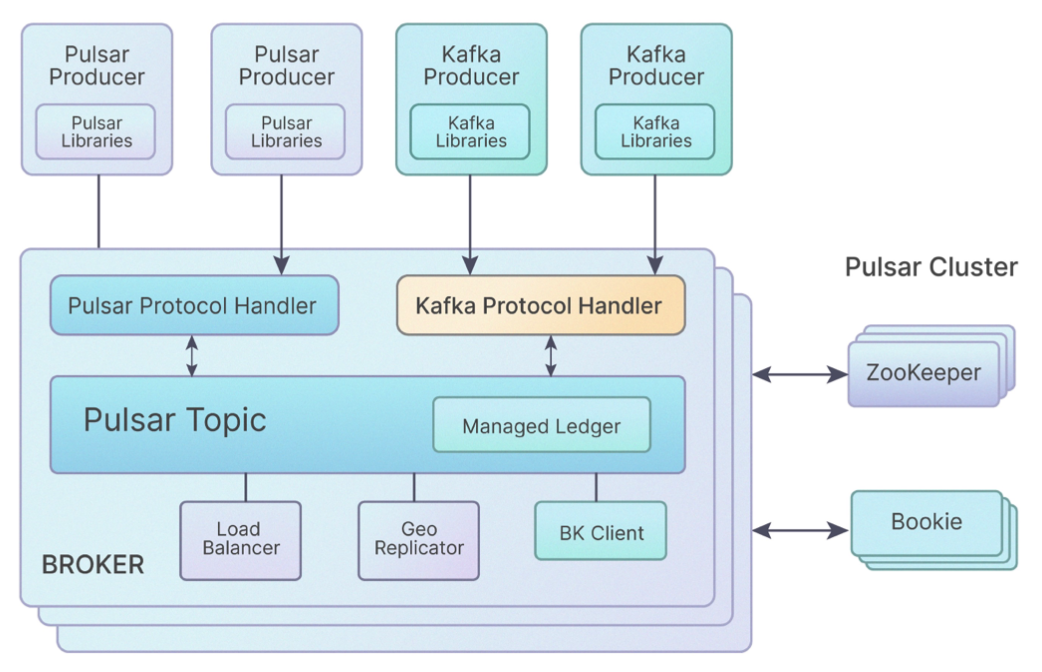 Figure 7. KoP architecture
For more information, see the demo video.
Figure 7. KoP architecture
For more information, see the demo video.
Pulsar adaptor for Apache Kafka
This tool was developed before KoP to help users migrate to Pulsar. To use it, you need to change the regular Kafka client dependency and replace it with the Pulsar Kafka wrapper. We don’t recommend it as it is only applicable to Java-based clients and it is not suitable for our use case.
AMQP-on-Pulsar (AoP)
Similar to KoP, AoP is implemented as a Pulsar protocol handler. Messaging systems like RabbitMQ and ActiveMQ use the AMQP protocol for their messages.
Connectors: How to make the best use of them
Pulsar’s ecosystem still has a long way to go compared with Kafka’s, especially for Pulsar connectors. Currently, Pulsar supports connectors for popular systems like Spark, Flink, and Elasticsearch, while there are more Kafka connectors available. In this connection, you can use the KoP-enabled Pulsar cluster with Kafka connectors to implement Pulsar connectors.
One such connector we created is the Pulsar-Druid connector. As the Kafka-Druid connector is already available, you can enable KoP for your Pulsar cluster; after Kafka clients publish live events to the Pulsar cluster, end users can query the live data as they are synchronized by the Kafka-Druid connector. For more information, see the demo video.
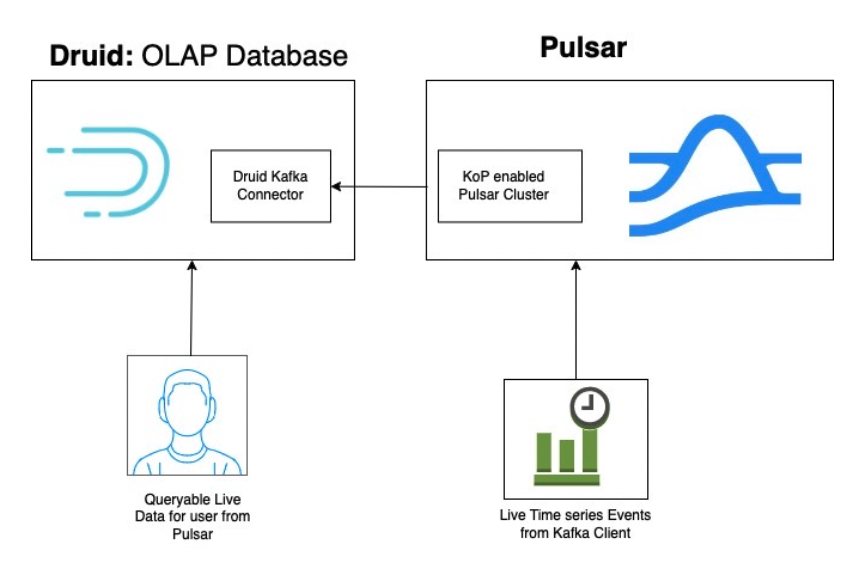 Figure 8. Implement the Pulsar-Druid connector with the KoP-enabled Pulsar cluster
Figure 8. Implement the Pulsar-Druid connector with the KoP-enabled Pulsar cluster
Conclusion
In this blog, we discussed some common requirements for data streaming and introduced popular systems with their advantages and disadvantages. We performed some tests on these systems and explained why we ultimately selected Apache Pulsar as our messaging platform. To help migrate from other tools to Pulsar, the Pulsar community provides the protocol handler plugin to support a safe transition. In addition, you can also use it to achieve new Pulsar connectors with existing Kafka connectors.
More Resources
Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Engage with the community by submitting a CFP or becoming a community sponsor (no fee required). Meanwhile, check out the following resources:
- Apache Pulsar vs. Apache Kafka 2022 Benchmark
- Apache Pulsar vs Kafka: Which is Better?
- Why Nutanix Beam went ahead with Apache Pulsar instead of Apache Kafka?
- Amazon Kinesis Data Streams FAQs
- The power of NATS: Modernising communications on a global scale
- The Matrix Dendrite Project move from Kafka to NATS
- How to use the Kafka replication tool
- KoP documentation
- Pulsar adaptor for Apache Kafka





