
When we talk about Apache Pulsar’s performance, we are usually referring to the throughput and latency associated with message writes and reads. Pulsar has certain configuration parameters that allow you to control how the system handles message writes or reads. To effectively tune Pulsar clusters for optimal performance, you need to understand Pulsar’s architecture and its storage layer, Apache BookKeeper.
In this blog, we explain some basic concepts and how messages are sent (produced) and received (consumed) in Apache Pulsar. You will learn key components, data flow and key metrics to monitor for Pulsar performance tuning.
1. Apache Pulsar Basic Concepts
The basic concepts and terminology explained in this section are key to understanding how Apache Pulsar works.
1.1 Message
The basic unit of data in Pulsar is called a message. Producers send messages to brokers, and brokers send messages to consumers using flow control. For an in-depth discussion of Pulsar’s flow command, click here.
Messages contain the data written to the topic by the producer, along with some important metadata.
In Pulsar, a message can be either of two types: a batch message or a single message. A batch message is a sequence of single messages. (See Section 1.5.1 below for more detailed information about batch messages.)
1.2 Topic
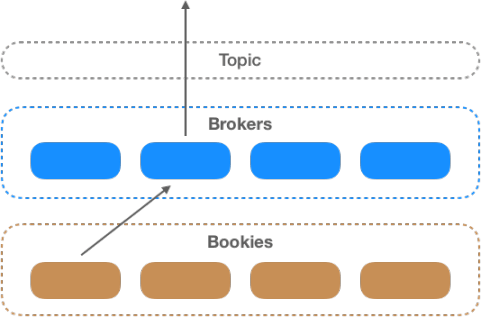
A topic is a category or feed name to which messages are published (produced). Topics in Pulsar can have multiple producers and/or consumers. Producers write messages to the topic, and consumers consume messages from the topic. Figure 1 shows how they work together.

1.3 Bookie
Apache Pulsar uses Apache BookKeeper as its storage layer. Apache BookKeeper is a scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads. Messages published by clients are stored in a server instance of Bookkeeper, which is called a bookie.
1.3.1 Entry and Ledger
Entry and ledger are basic terms used within BookKeeper. An entry contains the data written to the ledger, along with some important metadata. A ledger is the basic unit of storage in BookKeeper. A ledger is a sequence of entries. Entries are written to a ledger sequentially.
1.3.2 Journal
A journal file contains BookKeeper transaction logs. Before a ledger update takes place, the bookie ensures that a transaction describing the update, called a transaction log entry, is written to non-volatile storage. A new journal file is created when a bookie is first started, or when the older journal file reaches the specified journal file size threshold.
1.3.3 Entry Log
An entry log file manages the written entries received from BookKeeper clients. Entries from different ledgers are aggregated and written sequentially, while their offsets are kept as pointers in a ledger cache for fast lookup.
A new entry log file is created when the bookie is started, o r when the older entry log file reaches the specified entry log size threshold. The Garbage Collector Thread removes old entry log files when they are no longer associated with any active ledgers.
1.3.4 Index DB
A bookie uses RocksDB as the entry index DB. RocksDB is a high-performance, embeddable, persistent, key-value store based on log-structured merge (LSM) trees. Understanding the mechanics of an LSM tree will provide additional insights into the mechanics of Bookkeeper. More information about the design of the LSM tree is available in its original paper which can be found at here。
When a BookKeeper client writes an entry to a ledger, the bookie writes the entry to the journal and sends a response to a client after the journal is written. A background thread writes the entry to an entry log. When the bookie’s background thread flushes data to the entry log, the index is simultaneously updated. This process is illustrated in Figure 2.
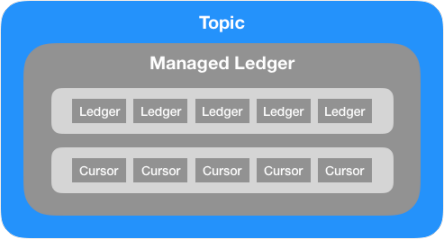
The cursor uses the ledger to store the mark delete position of a subscription. The mark delete position is similar to an offset in Apache Kafka®, but it is more than a simple offset because Pulsar supports multiple subscription modes.
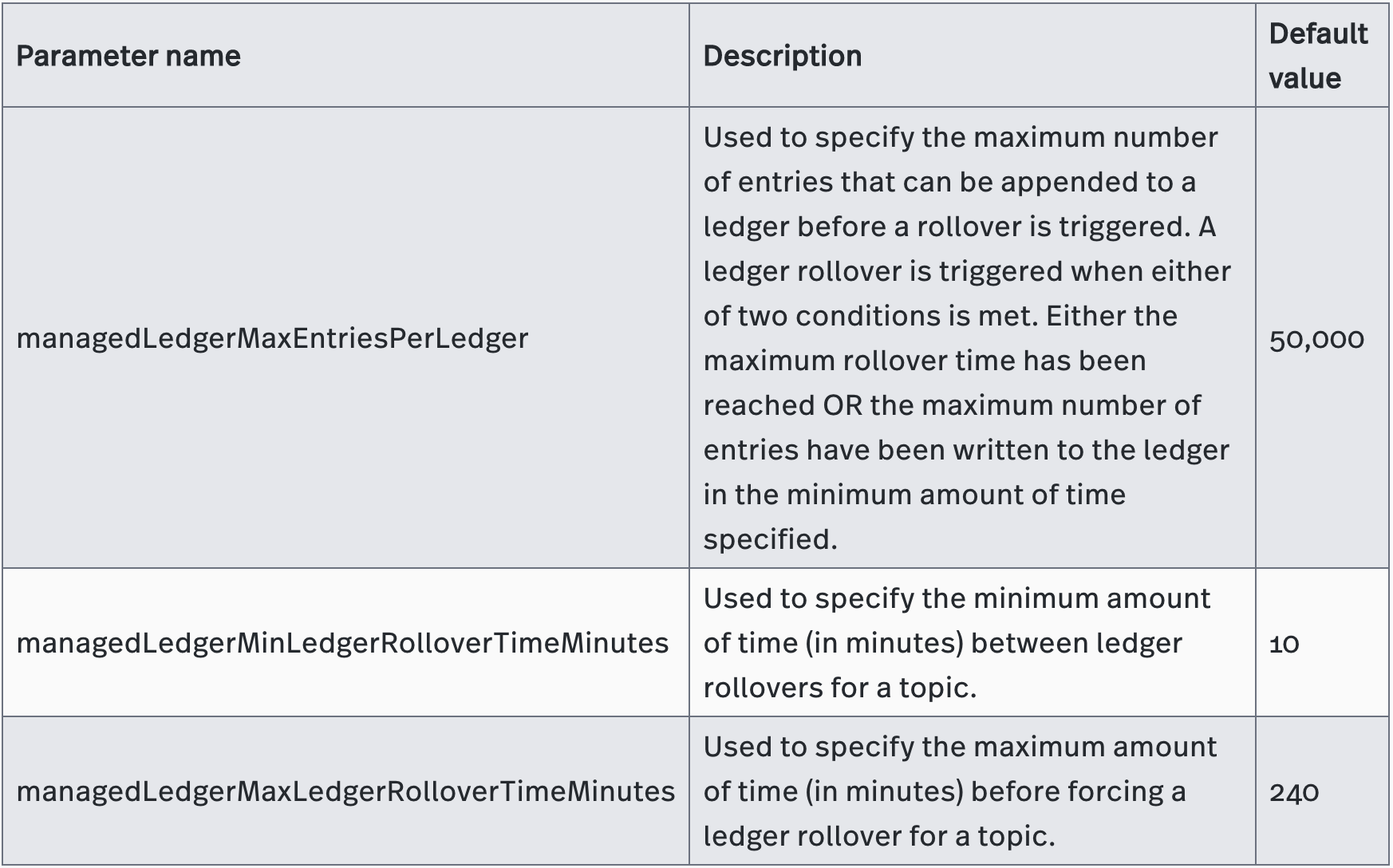
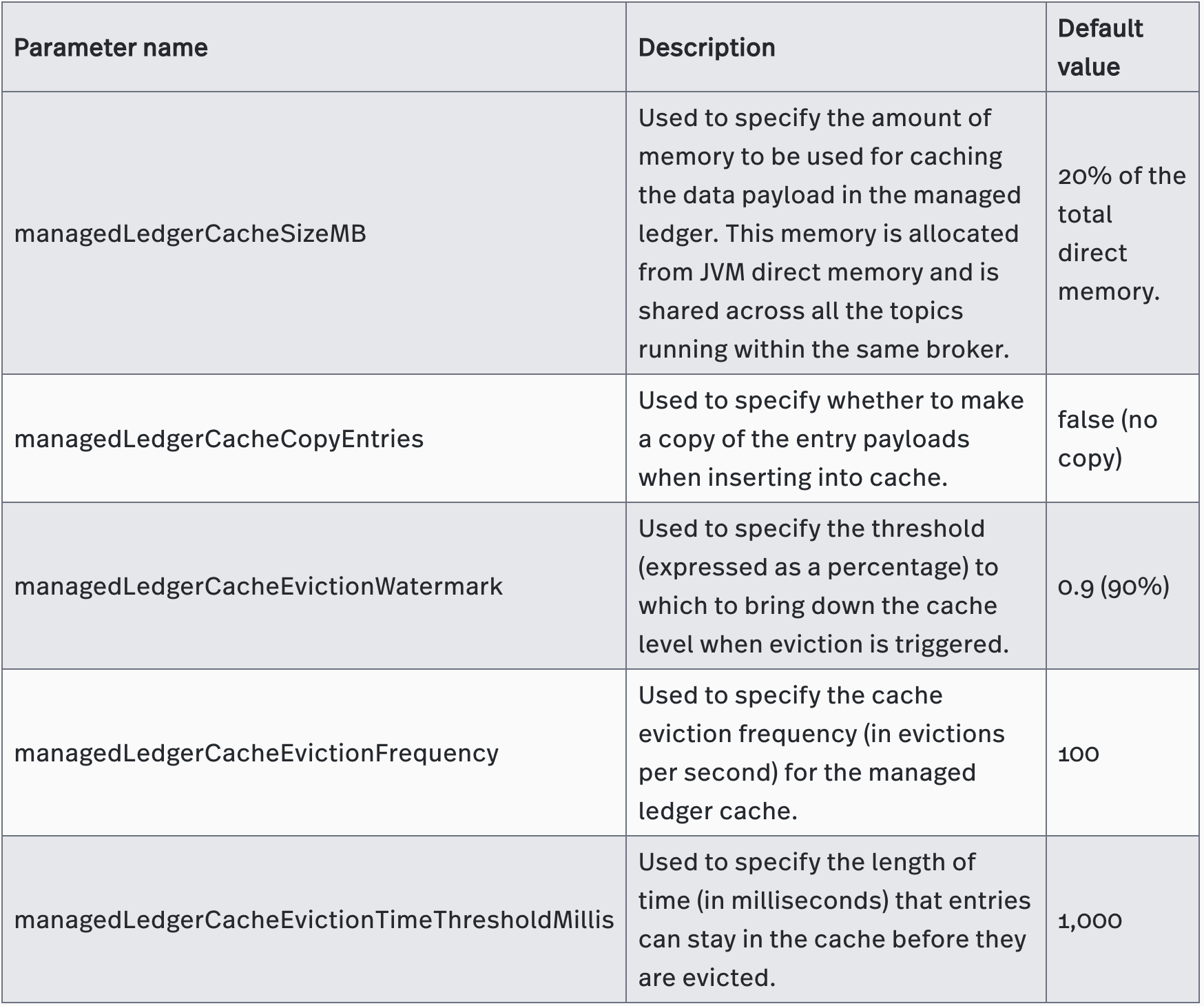
A managed ledger has many ledgers, so how does the managed ledger decide whether to start a new ledger? If a ledger is too large, data recovery time increases. If a ledger is too small, the ledger must switch more frequently, and the managed ledger calls upon Meta Store more often to update the metadata in the managed ledger. The ledger rollover policy for the managed ledger determines how frequently a new ledger is created. You use the following Pulsar parameters to control ledger behavior in broker.conf:
1.4.2 Managed Ledger Cache
Managed ledger cache is a type of cache memory used for storing tailing messages across topics. For tailing reads, consumers read the data from the serving broker. Because the broker already has the data cached in memory, there’s no need to read from disk or compete for resources with writes.
1.5 Client
Users utilize Pulsar clients to create producers (which publish messages to topics) or consumers (which consume messages from topics). There are many Pulsar client libraries available. For more details, visit here.
1.5.1 Batch Message
A batch message consists of a set of single messages that are assumed to represent a single contiguous sequence. Using a batch can reduce the overhead on both the client and server sides. Messages are grouped into small batches to achieve some of the performance advantages of batch processing without increasing the latency for each task too much.
In Pulsar, when using batch processing, producers send the batch to the broker. After the batch reaches the broker, the broker coordinates with the bookie, which then stores the batch in BookKeeper. When the consumer reads messages from the broker, the broker also dispatches the batch to the consumer. So, both combining batches and splitting batches occurs in the client. The sample code below shows how to enable and configure message batching for a producer:
client.newProducer()
.topic(“topic-name”)
.enableBatching(true)
.batchingMaxPublishDelay(2, TimeUnit.MILLISECONDS) .batchingMaxMessages(100)
.batchingMaxBytes(1024 * 1024)
.create();
In this example, the producer flushes the batch when the size of the batch exceeds 100 messages or 1MB of data. If these parameters are not met within two milliseconds, the producer will trigger batch flushing.
Therefore, your parameter settings will depend on message throughput and whatever publish latency you deem acceptable when publishing messages.
1.5.2 Message Compression
Message compression can reduce message size by paying some CPU overhead. The Pulsar client supports multiple compression types, such as lz4, zlib, zstd, and snappy. Compression types are stored in the message metadata, so consumers can adopt different compression types automatically, as needed.
When you enable message batching, the Pulsar client provides improved compression by reducing the size of the batch. The sample code below shows how to enable compression type for a producer:
client.newProducer()
.topic(“topic-name”)
.compressionType(CompressionType.LZ4)
.create();
1.5.3 Setting the Maximum Number of Pending Messages for a Producer
Each producer uses a queue to hold the messages that are waiting to receive acknowledgments from the broker. Increasing the size of this queue can improve the throughput of published messages. However, doing so can cause unwanted memory overhead.
The sample code below shows how to configure the size of the pending messages queue for a producer:
client.newProducer()
.topic(“topic-name”)
.maxPendingMessages(2000)
.create();
When setting the value of maxPendingMessages, it is important to consider the memory impact on the client application. To estimate the memory impact, multiply the number of bytes per message by the number of maxPendingMessages. For example, if each message is 100 KB, setting 2000 maxPendingMessages may add 200 MB (2000 * 100 KB = 200,000 KB = 200 MB) of additional required memory.
1.5.4 Configuring the Size of the Receiver Queue for a Consumer
The consumer’s receiver queue controls how many messages the consumer is allowed to accumulate before the messages are taken away by the user’s application. Making the receiver queue size larger could potentially increase consumption throughput at the expense of higher memory utilization.
The sample code below shows how to configure the size of the receiver queue for a consumer:
client.newConsumer()
.topic(“topic-name”)
.subscriptionName(“sub-name”)
.receiverQueueSize(2000)
.subscribe();
2. How Message Writing Works on the Server Side
To be able to tune message writing performance effectively, you first need to understand how message writing works.
2.1. Interactions Between Brokers and Bookies
When a client publishes a message to a topic, the message is sent to the broker that is serving the topic, and the broker writes data in parallel to the storage layer.
As shown in Figure 4, having more data replicas makes the broker pay more network bandwidth overhead. You can mitigate the impact on network bandwidth by configuring persistence parameters at the following levels:
- In Pulsar
- At the broker level
- At namespace level
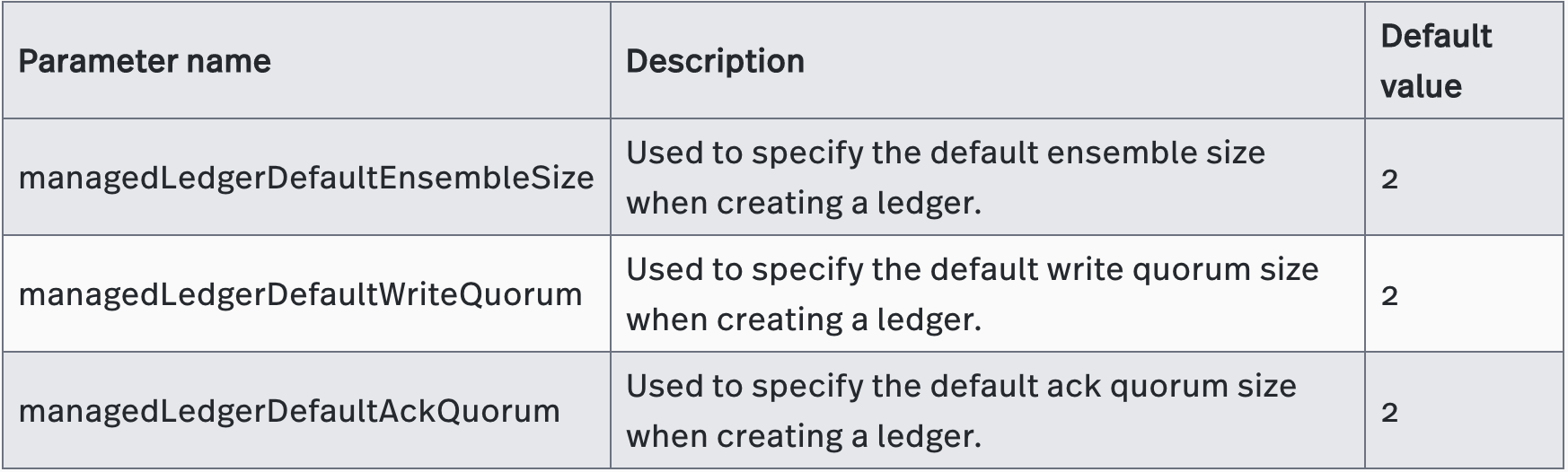
2.1.3 Configuring Persistence Parameters at the Namespace Level
Optionally, you can overwrite the persistence parameters at namespace level policy. In the example shown below, all three persistence parameters have been set to a value of "3".
$ bin/pulsar-admin namespaces set-persistence --bookkeeper-ack-quorum 3 --bookkeeper-ensemble 3 --bookkeeper-write-quorum 3 my-tenant/my-namespace
2.1.4 Configuring the Size of the Worker Thread Pool
To guarantee that the messages within a topic are stored in the order in which they are written, the broker uses a single thread for writing the managed ledger entries associated with a topic. The broker takes a thread from the managed ledger worker thread pool that bears the same name. You use the following parameter to configure the size of the worker thread pool in broker.conf.
Parameter managedLedgerNumWorkerThreads is used to specify the number of threads to be used for dispatching managed ledger tasks. Negative numbers are not allowed. If no value has been specified, the system will use the number of processors available to the Java virtual machine by default.8
2.2 Understanding How Bookies Handle Entry Requests
This section provides a more detailed, step-by-step explanation of how a bookie handles the addition of entry requests. The diagram in Figure 5 gives you an overview of the process.

When the request processor appends the new entries to the journal log, which is a type of write-ahead log (WAL), a bookie asks the processor to provide a thread from the write thread pool associated with the ledger ID. You can configure the size of the thread pool and the maximum number of pending requests in each thread for handling entry write requests.

If the number of pending requests of adding entry exceeds the maximum number of pending requests of adding entry specified in bookkeeper.conf, the bookie will reject new requests of adding entry.
By default, all journal log entries are synchronized to disk to avoid data loss in the event that a machine loses power. So, the latency of data synchronization has the most important influence on write throughput and latency. If you use the HDD as journal disks, be sure to disable the journal sync mechanism so the bookie client gets responses after the entry writes to the OS page cache successfully. Use the following parameter to enable or disable journal data synchronization in bookkeeper.conf:

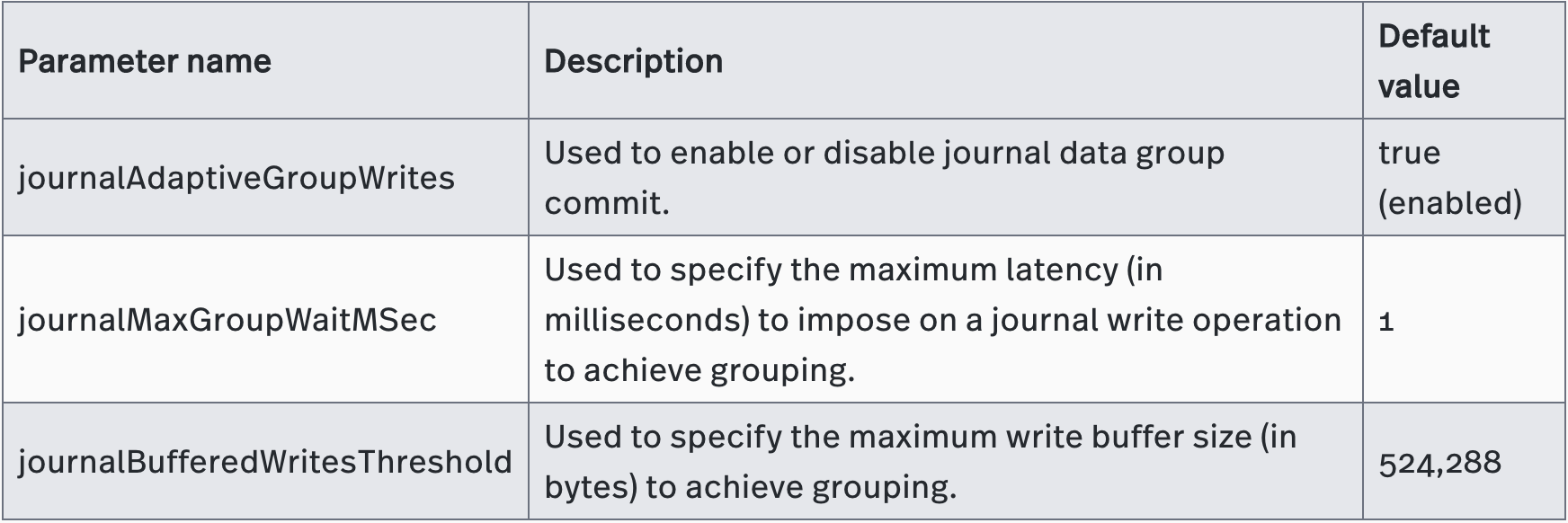
The group commit mechanism allows any tasks that are waiting to be executed to be grouped into small batches. This technique achieves better performance for batch processing without a sharp increase in latency for each task. Bookies can also use the same method to improve the throughput for journal data writes. Enabling group committing for journal data can reduce disk operations and avoid excessive small file writes. However, to avoid an increase in latency, you can disable group commit.
Use the following parameters to enable or disable the group commit mechanism in bookkeeper.conf:
After the entry is written to the journal, the entry is also added to the ledger storage. By default, the bookie uses the value you specify in DbLedgerStorage as the ledger storage. DbLedgerStorage is an implementation of ledger storage that uses RocksDB to keep the indices for entries stored in entry logs. Requests of adding entry in ledger storage are completed after the entry is successfully written to the memory table, and then the requests on the bookie’s client-side are completed. The memory table will periodically flush to the entry logs and build the indices for entries stored in entry logs, also called the checkpoint.
The checkpoint introduces much random disk I/O. If journal directories and ledger directories are located on separate devices, then flushing will not affect performance. But, if journal directories and ledger directories are located on the same device, then performance degrades significantly due to frequent flushing. You can consider increasing a bookie’s flush interval to improve performance. However, if you increase the flush interval, recovery will take longer when the bookie restarts (for example, after a failure).
For optimal performance, the memory table should be big enough to hold a substantial number of entries during the flush interval. Use the following parameters to set up the write cache size and the flush interval in bookkeeper.conf:

3. How Message Reading Works on the Server Side
Apache Pulsar is a multi-layer system that allows message reading to be split into tailing reads and catch-up reads. Tailing reads refers to reading the most recently written data. Catch-up reads read historical data. In Pulsar, there are different approaches for tailing reads and catch-up reads.
3.1 Tailing Reads
For tailing reads, consumers read the data from the serving broker, which already has that data stored in managed ledger cache. This process is illustrated in Figure 6.
3.2 Catch-up reads
Catch-up reads go to the storage layer to read data. This process is illustrated in Figure 7.
The bookie server uses a single thread to handle entries that read requests from a ledger. The bookie server takes a thread from the read worker thread pool associated with the ledger ID. You use the following parameters in bookkeeper.conf to set up the size of the read worker thread pool and the maximum number of pending read requests for each thread:

When reading entries from ledger storage, the bookie will first find an entry's position in the entry logs through the index file. DbLedgerStorage uses RocksDB to store the index for ledger entries. So, be sure to allocate enough memory to hold a significant portion of the index database to avoid swap-in and swap-out index entries.
For optimum performance, the size of the RocksDB block-cache needs to be big enough to hold a significant portion of the index database, which has been known to reach ~2GB in some cases.
You use the following parameter in bookkeeper.conf to control the size of the RocksDB block cache:

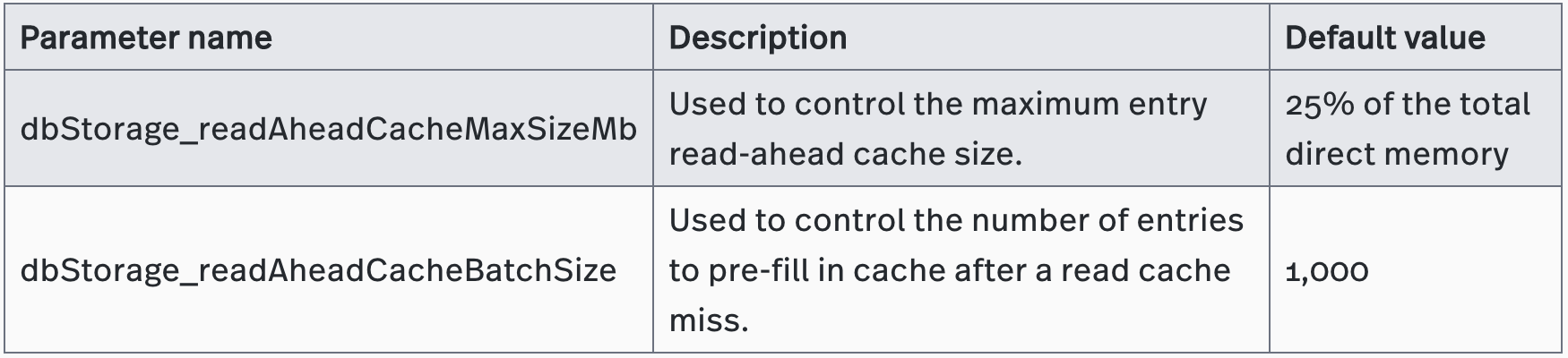
Enabling the entry read-ahead cache can reduce the operation of the disk for sequential reading. You use the following parameters to configure the entry read-ahead cache size in bookkeeper.conf:
4. Metadata Storage Optimization
Pulsar uses Apache® ZookeeperTM as its default metadata storage area. ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Zookeeper performance tuning is not discussed in this post. For excellent guidance on how to tune Zookeeper, visit here. Of the recommendations mentioned in that document, pay special attention to those pertaining to disk I/O.
5. Conclusion
Hopefully, this introduction has given you a better understanding of some Pulsar basic concepts and, in particular, some insights into how pulsar handles message writing and reading. To review, we addressed the following concepts:
- Improving read and write I/O isolation gives bookies higher throughput and lower latency.
- Taking advantage of I/O parallelism between multiple disks allows us to optimize the performance of the journal and ledger.
- For tailing reads, the entry cache in the broker can reduce resource overhead and avoid competing for resources with writes.
- Improving Zookeeper performance maximizes system stability.
6. More Pulsar Resources
- Interested in fully-managed Apache Pulsar with enhanced reliability, tools, and features? Contact us now!
- Learn Pulsar from the original creators of Pulsar. Watch on-demand videos, enroll in self-paced courses, and complete our certification program to demonstrate your Pulsar knowledge.
- Read the 2022 Pulsar vs. Kafka Benchmark Report for a side-by-side comparison of Pulsar and Kafka performance, including tests on throughput, latency, and more.
- Watch sessions from Pulsar Summit San Francisco 2022 for best practices and the future of messaging and event streaming technologies.
- Sign up for the monthly StreamNative Newsletter for Apache Pulsar.




