
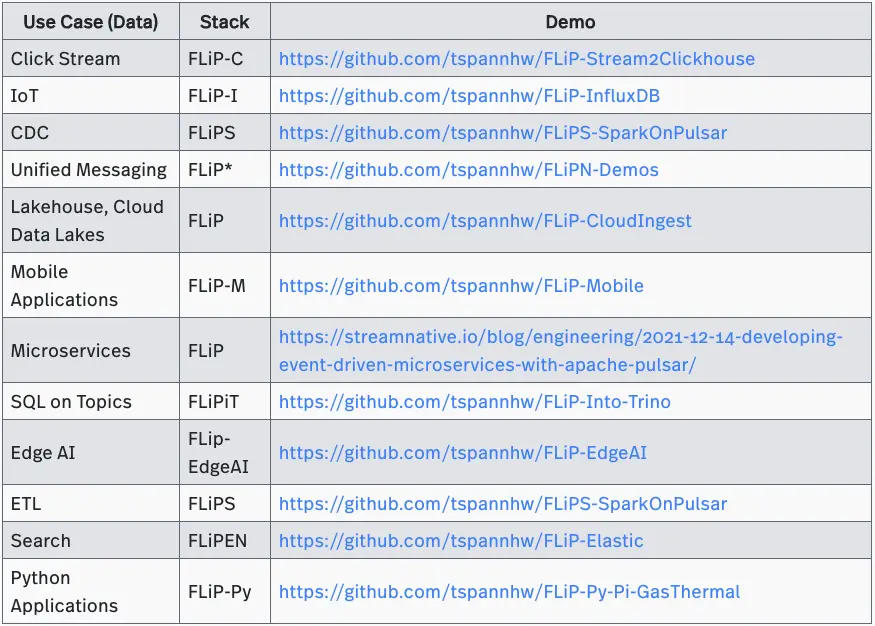
Introduction to FLiP Stack
In this article on the FLiP Stack, we will explain how to build a real-time event driven application using the latest open source frameworks. We will walk through building a Python IoT application utilizing Apache Pulsar, Apache Flink, Apache Spark, and Apache NiFi. You will see how quickly we can build applications for a plethora of use cases. The easy, fast, scalable way: The FLiP Way.
The FLiP Stack is a number of open source technologies that work well together. FLiP is a best practice pattern for building a variety of streaming data applications. The projects in the stack are dictated by the needs of that use case; the available technologies in the builder’s current stack; and the desired end results. As we shall see, there are several variations of the FLiP stack built upon the base of Apache Flink and Apache Pulsar.
For some use cases like log analytics, you will need a nice dashboard for visualizing, aggregating, and querying your log data. For that one you would most likely want something like FLiPEN, as an enhancement to the ELK Stack. As you can tell, FLiP+ is a moving list of acronyms for open source projects that are commonly used together.
Common Use Cases
With so many variations of the FLiP stack, it might be difficult to figure out which one is right for you. Therefore, we have provided some general guidelines for selecting the proper FLiP+ stack to use based on your use case. We already mentioned Log Analytics, which is a common use case. There are many more, driven usually by data sources and data sinks.
Flink-Pulsar Integration
A critical component of the FLiP stack is utilizing Apache Flink as a stream processing engine against Apache Pulsar data. This is enabled by the Pulsar-Flink Connector that enables developers to build Flink applications natively and stream in events from Pulsar at scale as they happen. This allows for use cases such as streaming ELT and continuous SQL on joined topic streams. SQL is the language of business that can drive event-driven, real-time applications by writing simple SQL queries against Pulsar streams with Flink SQL, including aggregation and joins.
The connector builds an elastic data processing platform enabled by Apache Pulsar and Apache Flink that is seamlessly integrated to allow full read and write access to all Pulsar messages at any scale. As a citizen data engineer or analyst you can focus on building business logic without concern about where the data is coming from or how it is stored.
Check out the resources below to learn more about this connector:
- Blog What's New in the Pulsar Flink Connector 2.7.0
- Blog Flink SQL on StreamNative Cloud
- Code Streaming Analytics with Apache Pulsar and Apache Flink SQL
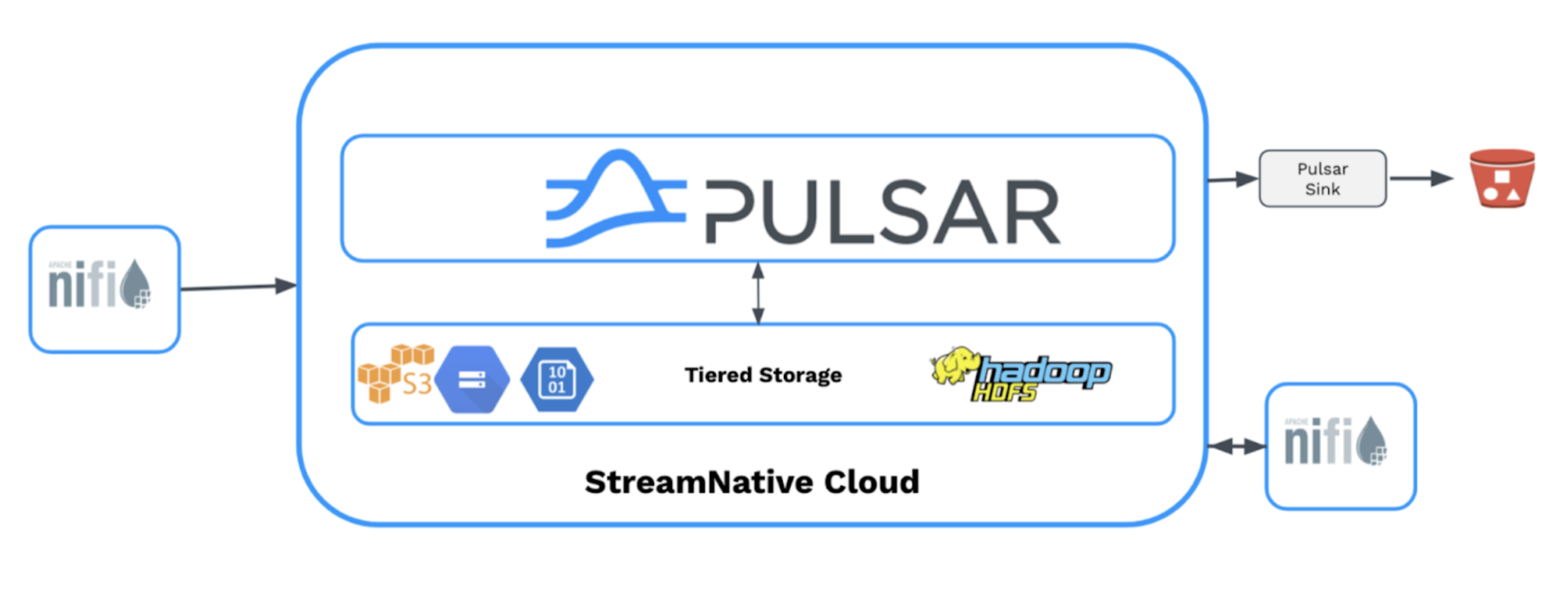
NiFi-Pulsar Integration
If you have been following our blog, you have seen the recent formal announcement of the Apache Pulsar processor for Apache NiFi release. We now have an official way to consume and produce messages from any Pulsar topic with the low code streaming tool that is Apache NiFi.
This integration allows us to build a real-time data processing and analytics platform for all types of rich data pipelines. This is the keystone connector for the democratization of streaming application development.
Read the articles below to learn more:
- Blog Cloudera and StreamNative Announce the Integration of Apache NiFi and Apache Pulsar
- Blog Producing and Consuming Pulsar messages with Apache NiFi
- Datanami Article Code for Pulsar, NiFi Tie-Up Now Open Source
An Example FLiP Stack Application
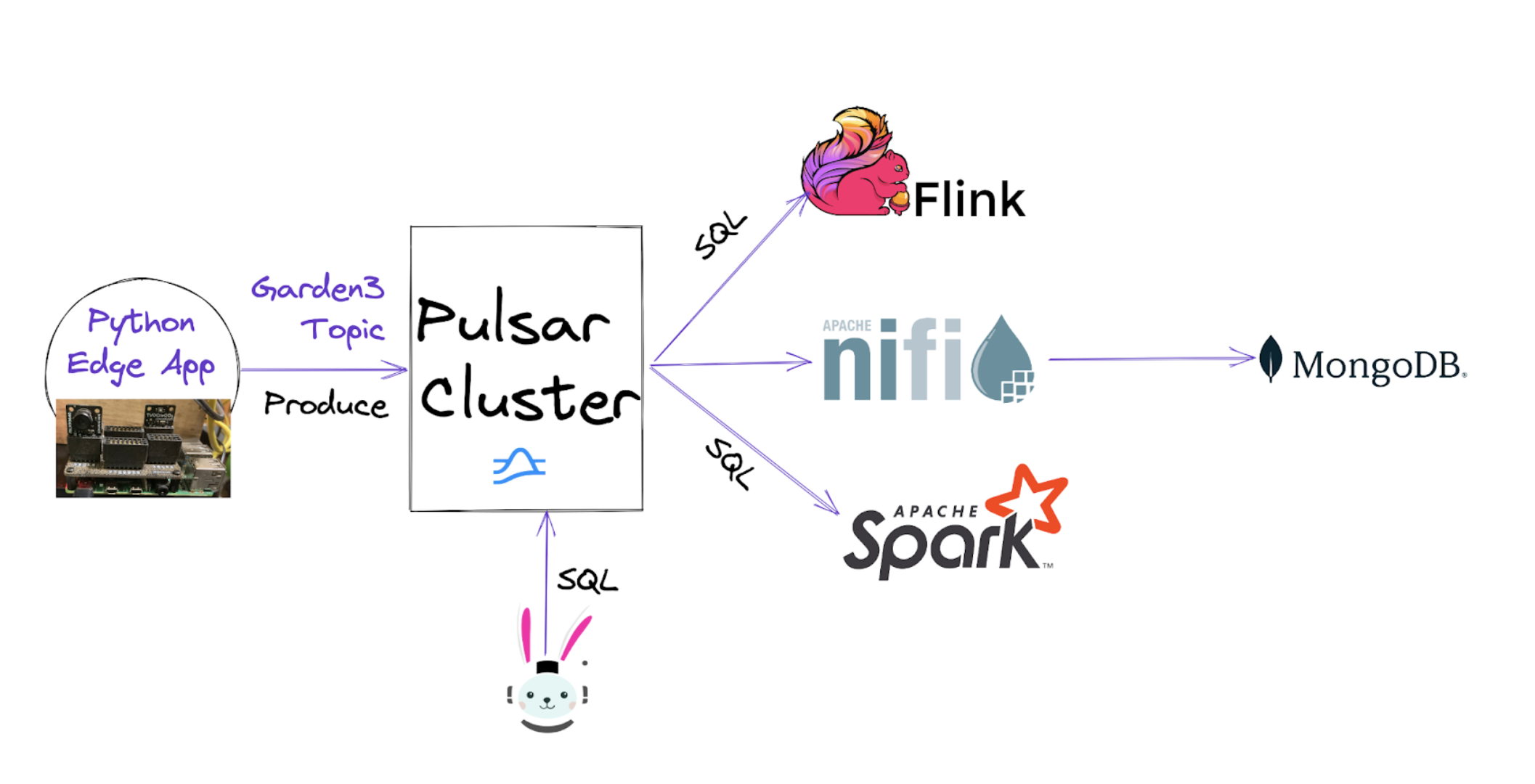
Now that you have seen the combinations, use cases, and the basic integration, we can walk through an example FLiP Stack application. In this example, we will be ingesting sensor data from a device running a Python Pulsar application.

Demo Edge Software Specification
- Apache Pulsar C++ and Python Client
- Pimoroni SGP30 Python Library
Streaming Server
- HP ProLiant DL360 G7 1U RackMount 64-bit Server
- Ubuntu 18.04.6 LTS
- 72GB PC3 RAM
- X5677 Xeon 3.46GHz CPU with 24 Cores
- 4×900GB 10K SAS SFF HDD
- Apache Pulsar 2.9.1
- Apache Spark 3.2.0
- Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_302)
- Apache Flink 1.13.2
- MongoDB
NiFi/AI Server
- NVIDIA® Jetson Xavier™ NX Developer Kit
- AI Perf: 21 TOPS
- GPU: 384-core NVIDIA Volta™ GPU with 48 Tensor Cores
- CPU: 6-core NVIDIA Carmel ARM®v8.2 64-bit CPU 6 MB L2 + 4 MB L3
- Memory: 8 GB 128-bit LPDDR4x 59.7GB/s
- Ubuntu 18.04.5 LTS (GNU/Linux 4.9.201-tegra aarch64)
- Apache NiFi 1.15.3
- Apache NiFi Registry 1.15.3
- Apache NiFi Toolkit 1.15.3
- Pulsar Processors
- OpenJDK 8 and 11
- Jetson Inference GoogleNet
- Python 3
Building the Air Quality Sensors Application with FLiPN-Py
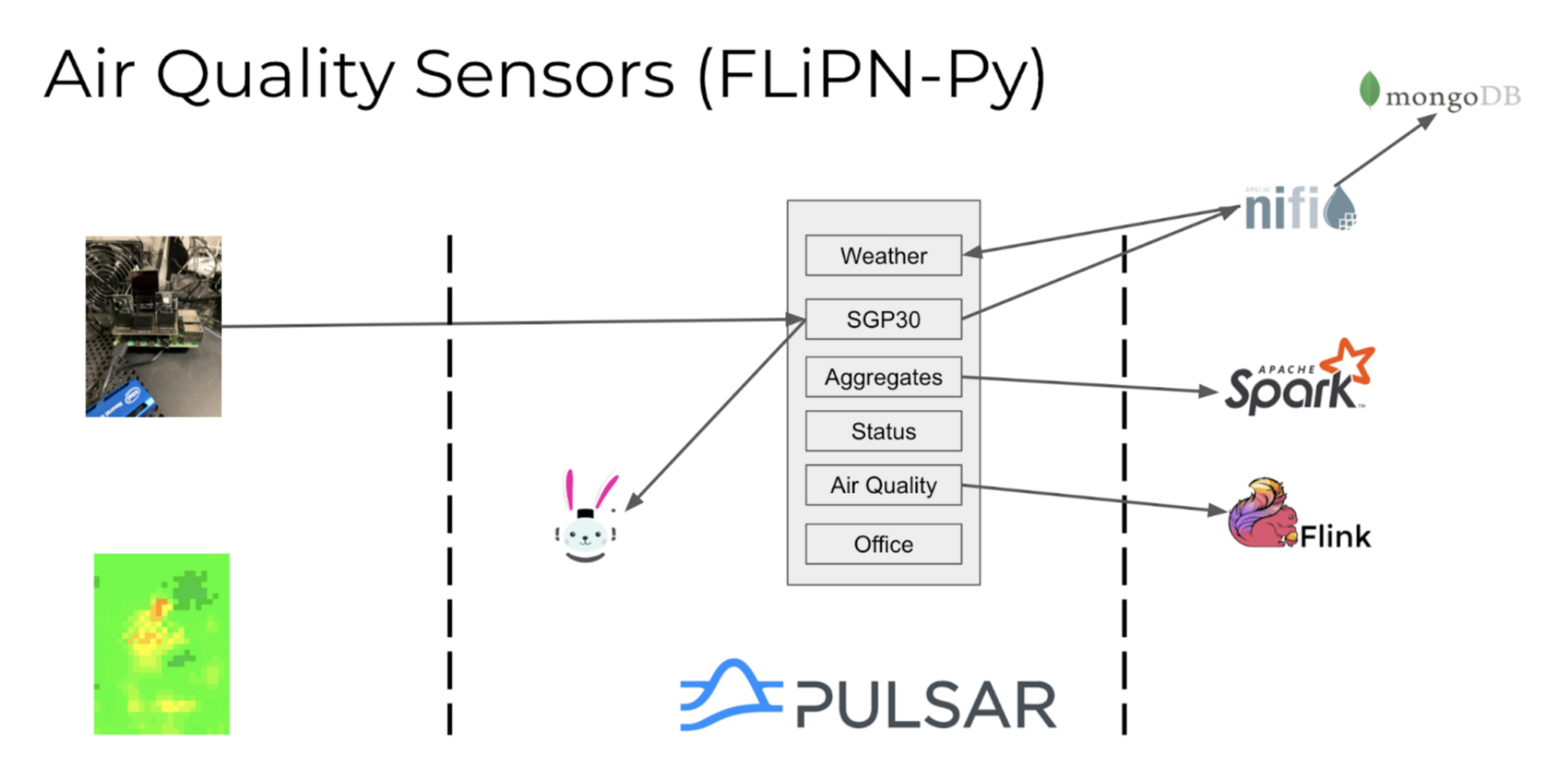
In this application, we want to monitor the air quality in an office continuously and then hand off a large amount of data to a data scientist to make predictions. Once that model is done, we will add that model to a Pulsar function for live anomaly detection to alert office occupants of the situation. We will also want dashboards to monitor trends, aggregates and advanced analytics.
Once the initial prototype proves itself, we will deploy it to all the remote offices for monitoring internal air quality. For future enhancements, we will ingest outside air quality data as well local weather conditions.
On our edge devices, we will perform the following three steps to collect the sensor readings, format the data into the desired schema, and forward the records to Pulsar.
Edge Step 1: Collect Sensor Readings
result = sgp30.get_air_quality()
Edge Step 2: Format Data According to Schema
class Garden(Record):
cpu = Float()
diskusage = String()
endtime = String()
equivalentco2ppm = String()
host = String()
hostname = String()
ipaddress = String()
macaddress = String()
memory = Float()
rowid = String()
runtime = Integer()
starttime = String()
systemtime = String()
totalvocppb = String()
ts = Integer()
uuid = String()
Edge Step 3: Produce Record to Pulsar Topic
producer.send(gardenRec,partition_key=str(uniqueid))
Now that we have built the edge-to-pulsar ingestion pipeline, let’s do something interesting with the sensor data that we have published to Pulsar.
Cloud Step 1: Spark ETL to Parquet Files
val dfPulsar =
spark.readStream.format("pulsar")
.option("service.url", "pulsar://pulsar1:6650")
.option("admin.url", "http://pulsar1:8080")
.option("topic","persistent://public/default/garden3")
.load()
val pQuery = dfPulsar.selectExpr("*")
.writeStream
.format("parquet")
.option("truncate", false)
.option("checkpointLocation", "/tmp/checkpoint")
.option("path", "/opt/demo/gasthermal").start()
Cloud Step 2: Continuous SQL Analytics with Flink SQL
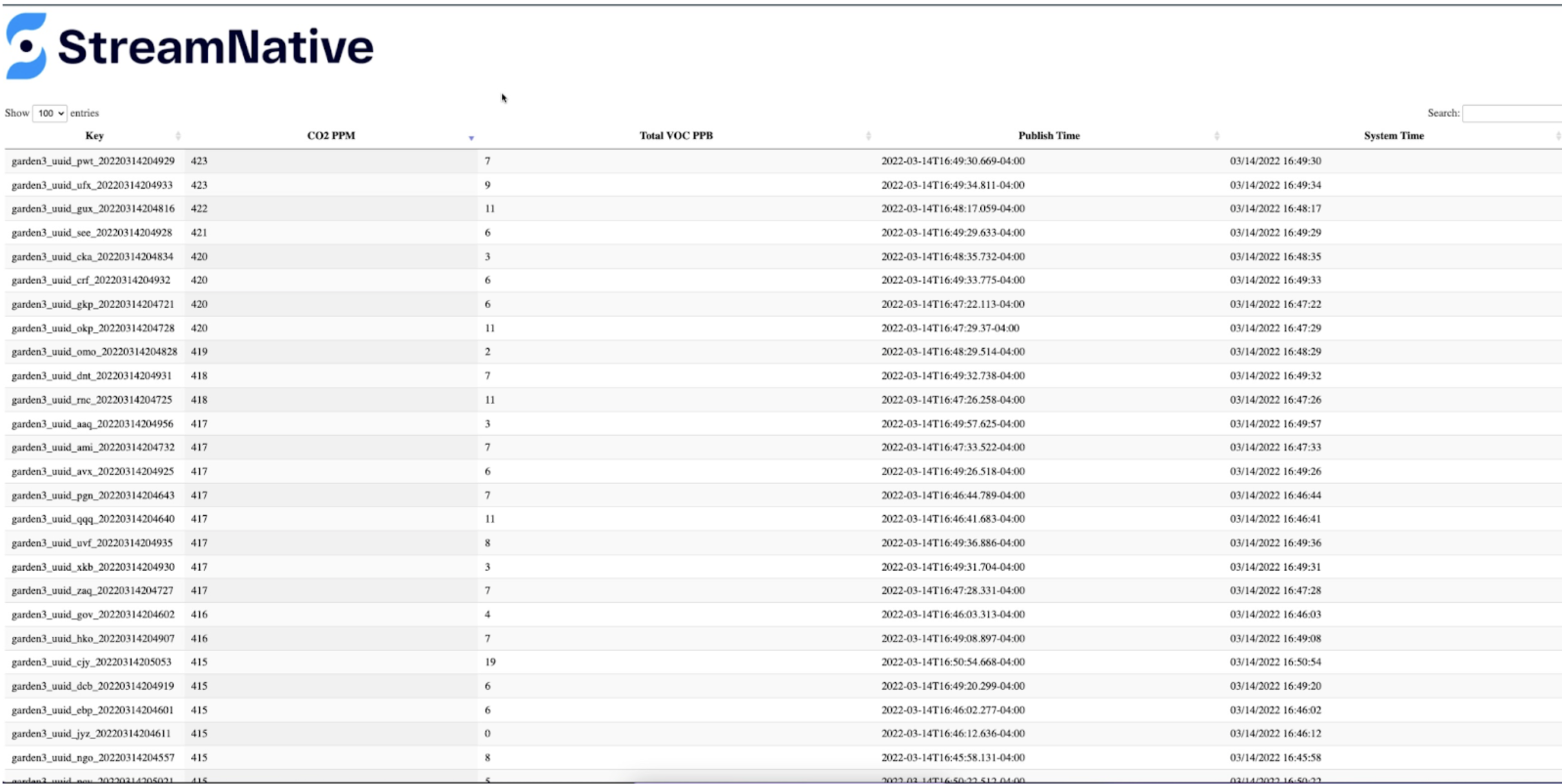
select equivalentco2ppm, totalvocppb, cpu, starttime, systemtime, ts, cpu, diskusage, endtime, memory, uuid from garden3;
select max(equivalentco2ppm) as MaxCO2, max(totalvocppb) as MaxVocPPB from garden3;
Cloud Step 3: SQL Analytics with Pulsar SQL
select * from pulsar."public/default"."garden3"
Cloud Step 4: NiFi Filter, Route, Transform and Store to MongoDB
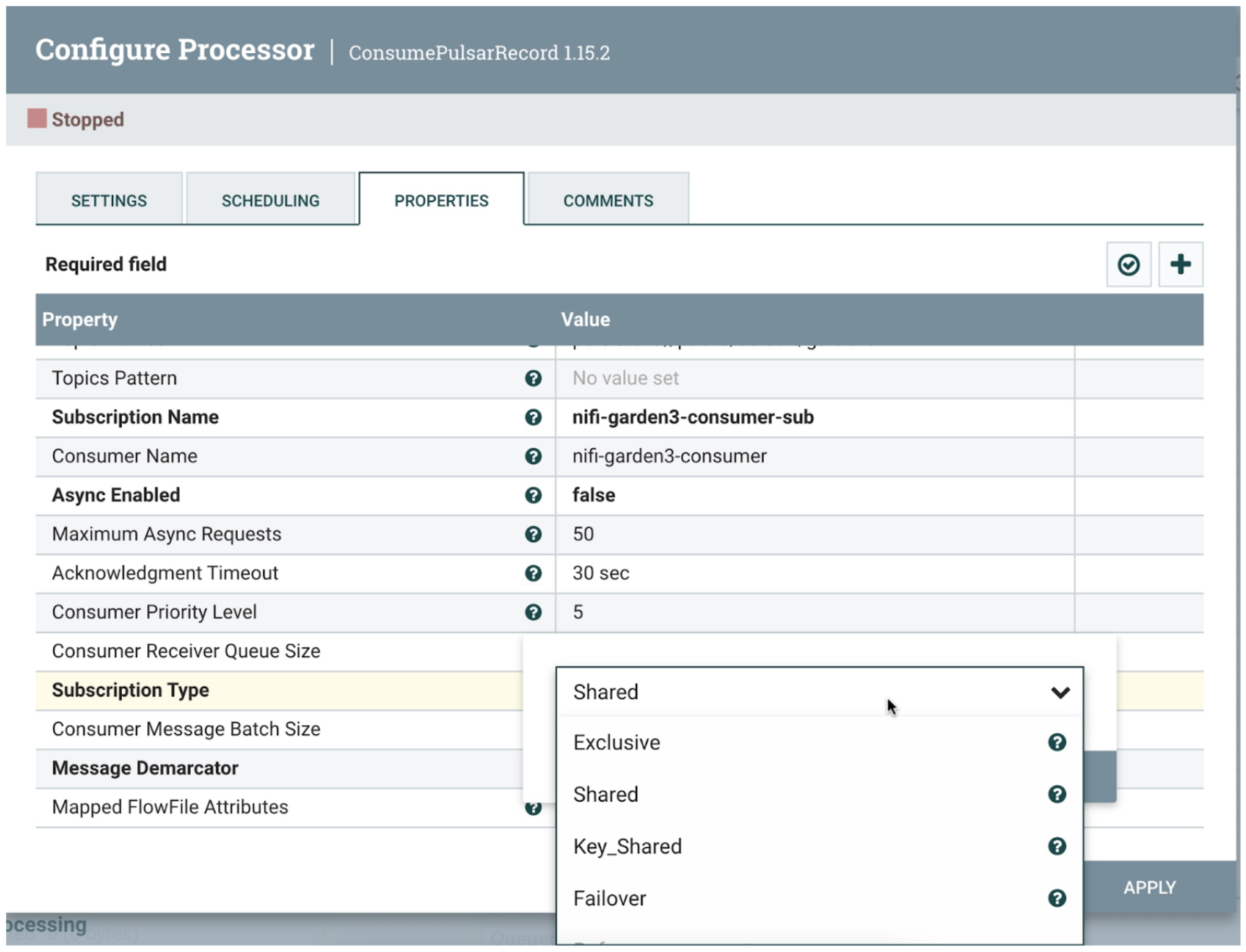
We could have used a Pulsar Function and Pulsar IO Sink for MongoDB instead, but you may want to do other data enrichment with Apache NiFi without coding.
Cloud Step 5: Validate MongoDB Data
show collections
db.garden3.find().pretty()
Watch the Demo
Conclusion
In this blog, we explained how to build real-time event driven applications utilizing the latest open source frameworks together as FLiP Stack applications. So now you know what we are talking about when we say “FLiPN Stack”. By using the latest and greatest open source Apache streaming and big data projects together, we can build applications faster, easier, and with known scalable results.
Join us in building scalable applications today with Pulsar and its awesome friends. Start with data, route it through Pulsar, transform it to meet your analytic needs, and stream it to every corner of your enterprise. Dashboards, live reports, applications, and machine learning analytics driven by fast data at scale built by citizen data engineers in hours, not months. Let’s get these FLiPN applications built now.
Resources
- Code Source code for the air quality sensors application
- Resources FLiP Stack for Apache Pulsar Developer
- Talk Using the FLiPN Stack for Edge AI (Flink, NiFi, Pulsar)
- Connector Flink-Pulsar Sink Connector
- Connector Flink-Pulsar SQL Connector
More on Pulsar
- Make an inquiry: Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Engage with the community by submitting a CFP or becoming a community sponsor (no fee required).
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.




