
Recently, I had the opportunity to immerse myself in the Kafka Summit London, a major conference on data streaming organized by Confluent. My interactions with attendees, partners, and vendors sparked deep dives into the latest trends and technologies shaping data streaming. As insights from the conference flow through various channels, including insights from colleagues like Julien Jakubowski and industry experts like Yingjun Wu of RisingWave, a recurring theme emerges: the critical consideration of cost in data streaming technologies. Amidst the buzz around Kafka, Flink, Iceberg, and more, the discourse is heavily skewed toward cost, with each vendor vying to be seen as the more cost-efficient solution.
In the current economic landscape, the focus on cost is understandable. However, this emphasis often comes without the necessary context of the trade-offs involved, leading us into a "vendor's trap" where cost discussions lack depth and utility. Noticing this gap, I was compelled to share my perspective on the intricate balance between cost, availability, and performance in the realm of data streaming platforms.
Almost twenty-five years ago, in 2000, Eric Brewer introduced the idea that there is a fundamental trade-off between consistency, availability, and partition tolerance. This trade-off, which has become known as the CAP Theorem, has been widely used to evaluate distributed system architectures ever since.
In light of the emerging proliferation of streaming platforms, a similar model for evaluating the trade-offs between cost, availability, and performance within data streaming platforms is required. Recognizing this, we propose what we term the New CAP Theorem for cloud-based data streaming systems.
Introducing the New CAP theorem
The letters in CAP refer to three desirable properties of cloud-based data streaming platforms: Cost efficiency, Availability of the system for reads and writes, and Performance tolerance.
The new CAP theorem states that it is not possible to guarantee all three of the desirable properties in a cloud-based data streaming platform at the same time.
- Cost refers to the total infrastructure cost of the platform to provide data streaming functionality. This can be quantified in terms of cost per unit of work, e.g., MB of throughput, etc.
- Availability simply means that the data streaming system can continue to serve requests even if a single availability zone experiences an outage.
- Performance Tolerance refers to the minimal acceptable latency of the platform when servicing requests. This can be quantified in terms of p99 latencies for message publication and consumption.
This theorem is based on three foundational aspects of cloud-based data streaming systems:
- To ensure high availability, data streaming systems employ a data replication algorithm. This algorithm replicates data across multiple availability zones to withstand single-zone failures, making inter-zone traffic indispensable for maintaining high availability.
- Inter-zone traffic significantly contributes to the overall cost structure of a data streaming system. Although eliminating inter-zone traffic can reduce costs, it may adversely affect availability or performance.
- The latency of low-cost cloud object storage solutions is not on par with persistent block storage or local SSDs. To meet specific performance requirements, the use of persistent block storage or local SSDs is essential.
In order to help you better understand the New CAP theorem, we will dive deeper into the cost structure of a data streaming system.
Infrastructure costs in data streaming platforms
The infrastructure costs of a data streaming infrastructure are typically comprised of 3 cost categories:
- Compute: This refers to the servers and computing resources required to run the data streaming platform.
- Storage: Essential for data retention, storage can range from local disks and persistent volumes to cost-effective cloud-based object stores.
- Network: Critical for data movement, networking costs are incurred for transferring data to and from the platform and replicating data across various availability zones to ensure the availability of the platform.
Technologies designed for data streaming leverage cloud resources in different ways, leading to varied cost structures. Comparing these costs directly is challenging because technologies are not uniform in design or efficiency. Benchmark tests, commonly used by vendors to demonstrate the cost-effectiveness of their technology, often do not account for the full spectrum of business needs and scenarios. These benchmarks, typically conducted under conditions favorable to the vendor's product, can give rise to "benchmarketing," which may not always present a realistic picture of costs.
A notable oversight in cost estimation is the heavy reliance on benchmarks to gauge the computational throughput of a system, leading to calculations based on how many units of compute are needed. This approach is fundamentally flawed as it fails to account for critical factors like storage and networking costs. The latter, in particular, can reveal hidden costs that become painfully apparent when organizations are confronted with unexpectedly high bills for network usage from their cloud service providers.
The Overlooked Cost of Networking in Data Streaming
Often underestimated in infrastructure software considerations, networking emerges as a significant (up to 90%!) expense in the realm of data streaming technologies. The voluminous data flow within and through these platforms incurs substantial costs. While these costs are often overlooked during the planning stages, they do represent a significant cost when operating at scale.
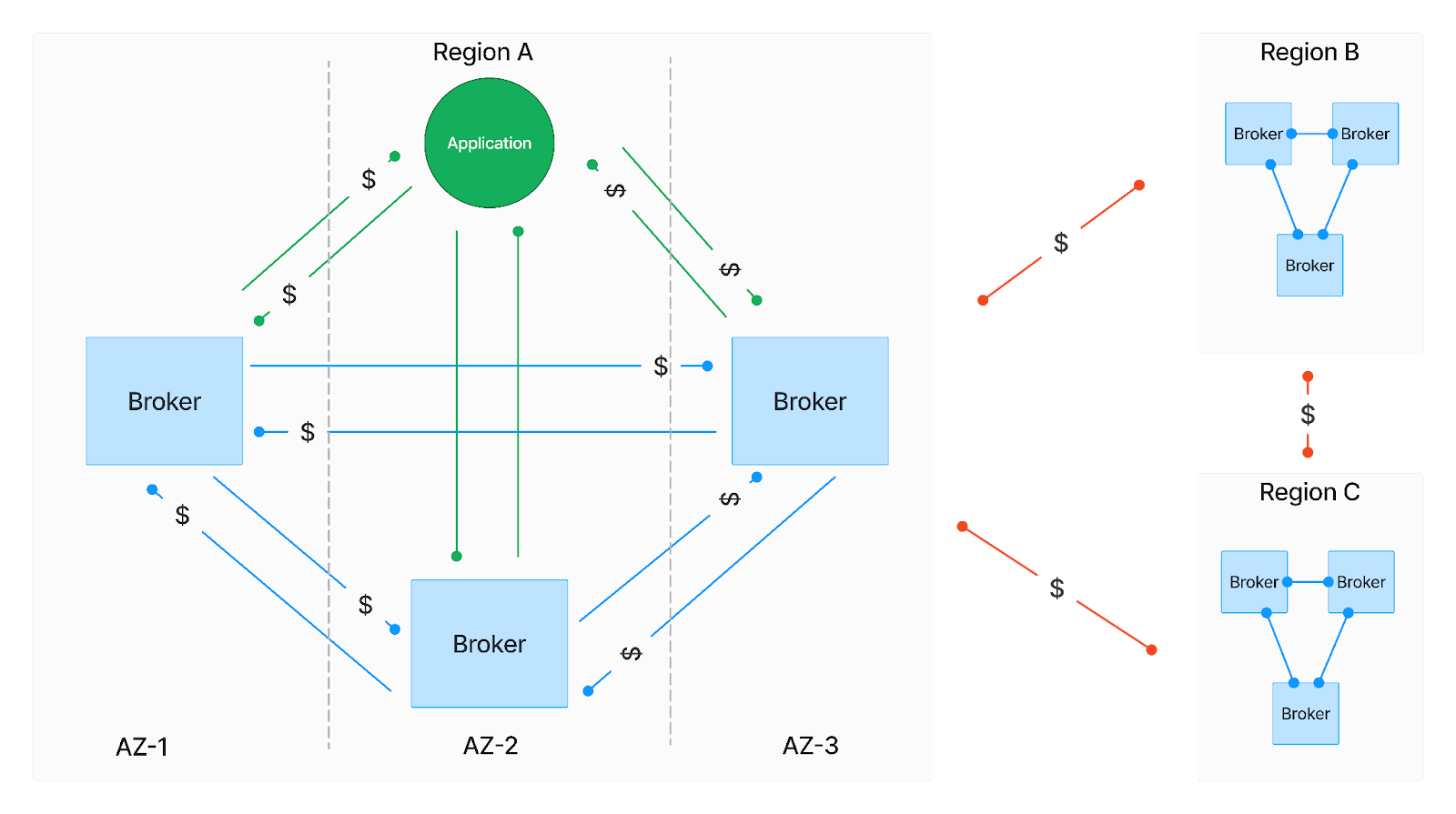
As illustrated in the diagram above, networking costs are primarily attributed to:
- Data Transmission: The ingress and egress of data to and from the data streaming system can lead to substantial fees.
- Internal Replication Traffic: Data streaming platforms replicate data across multiple instances to ensure high availability. This replication, especially across different availability zones, can significantly increase costs based on the volume of data involved.
- Inter-Cluster Replication: For purposes like geographic redundancy or disaster recovery, data streaming solutions often replicate data across regions, incurring significant expenses based on the distance and volume of data transferred.
Cloud service providers levy considerable fees for data egress and traffic between availability zones and regions. Without a deep understanding of these infrastructural nuances, organizations may face unexpectedly high charges from their cloud services, underscoring the criticality of incorporating networking cost considerations in the early planning and design phases of data streaming platforms.
Categorization
After understanding the cost structure of a data streaming system plus the foundational aspects of inter-zone traffic, we can categorize data streaming systems into three broad types:
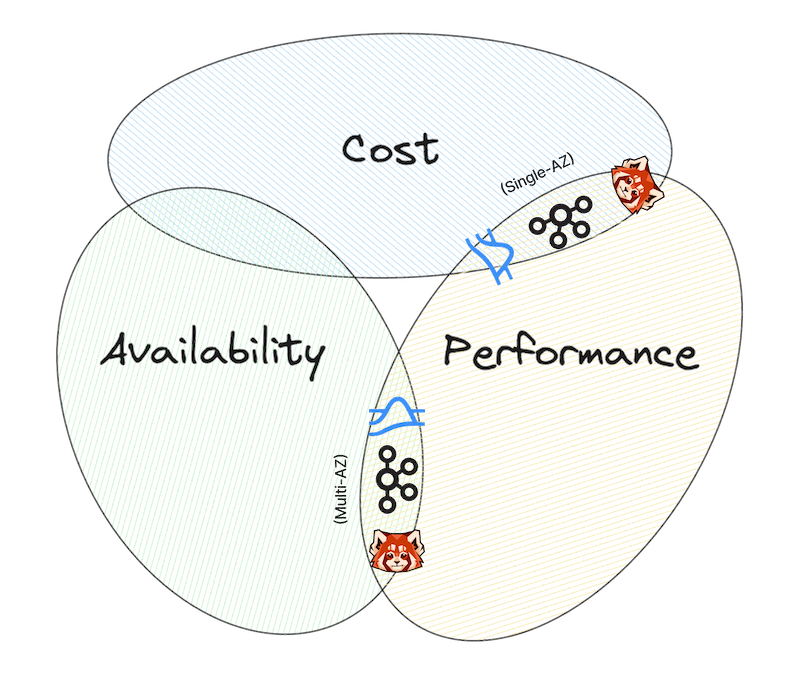
AP (Availability and Performance) Data Streaming Systems
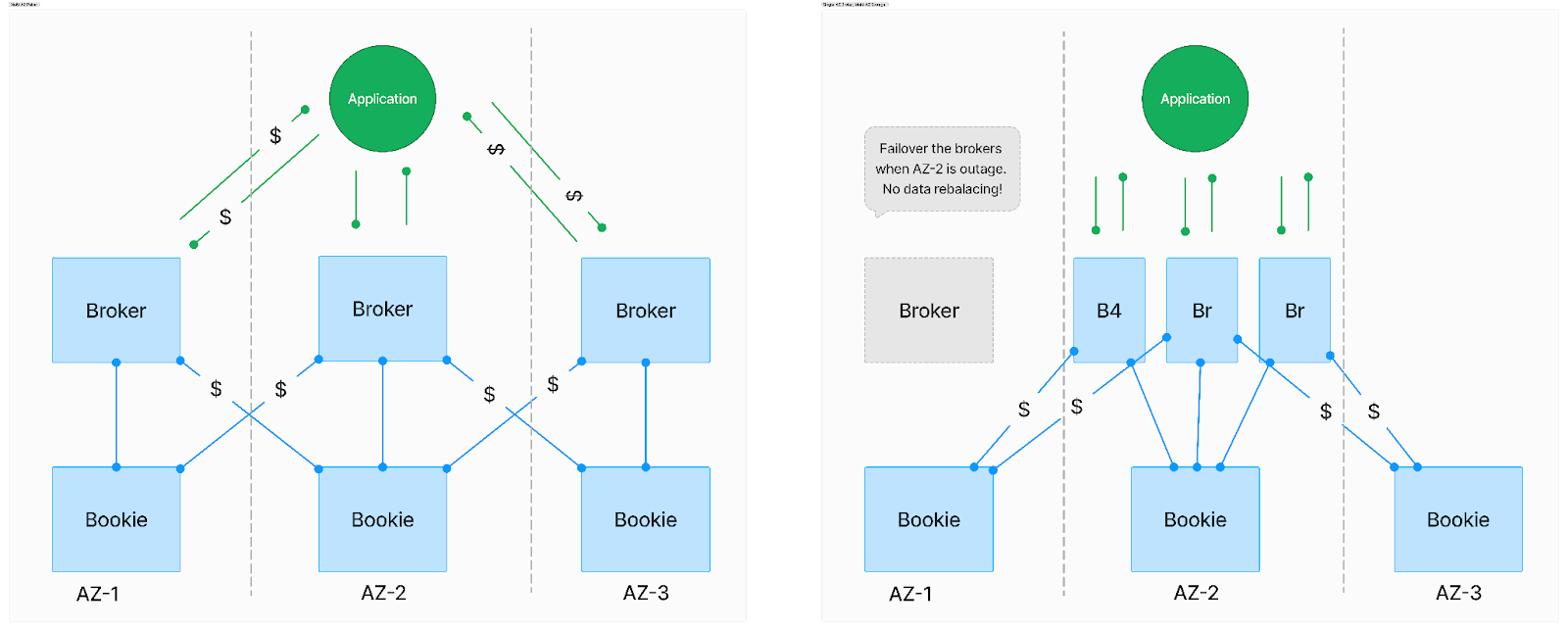
Popular systems like Apache Pulsar, Apache Kafka, and Redpanda fall into this category, adopting a multi-AZ deployment strategy to ensure high availability despite single-zone failures. These systems utilize sophisticated replication mechanisms across availability zones, inherently increasing inter-zone traffic and, by extension, infrastructure costs. However, they deliver superior availability and reduced latency, making them ideal for mission-critical applications. Noteworthy efforts to mitigate cross-zone traffic include technologies like Follower Fetching in Kafka and ReadOnly Broker in Pulsar.
Despite the inevitability of cross-AZ traffic, Apache Pulsar stands out due to its unique two-layer architecture, which separates storage nodes from broker/serving nodes. This design allows for the strategic deployment of broker/serving nodes within a single AZ, while storage nodes can be distributed across multiple AZs. Since all broker nodes are stateless, they can swiftly failover to a different AZ in case of an outage in the current zone. This compute-and-storage-separation architecture significantly reduces cross-zone traffic and ensures higher availability, demonstrating Pulsar's innovative approach to balancing the challenges of distributed data streaming infrastructure. In future blog posts, we will explain in more detail how compute-and-storage-separation architecture can help reduce cost while achieving high availability and low latency.
CP (Cost and Performance) Data Streaming Systems
In a CP system, the focus shifts towards balancing high availability with cost efficiency, a goal often achieved by restricting operations to a single availability zone. This approach eliminates inter-zone traffic, reducing costs and latency at the risk of decreased availability in the event of a zone outage. While no technology is inherently designed as CP, adaptations of AP systems for single-zone deployment are common, with vendors including Confluent and StreamNative offering specialized zonal cluster configurations.
CA (Cost and Availability) Data Streaming Systems
Addressing use cases like non-critical, high-volume data streaming (e.g., log data ingestion), CA systems prioritize low total cost and availability over performance. New innovations, which use cloud object storage for replication, exemplify efforts to minimize costs by avoiding inter-zone traffic. These systems, however, necessitate a tolerance for higher latency (> 1s).
Through the New CAP Theorem lens, we gain a structured approach to navigate the trade-offs between cost, availability, and performance tolerance, enabling informed decision-making in selecting data streaming technologies.
From Cost Saving to Balanced Cost Optimization
The New CAP Theorem doesn't serve to rank systems but to highlight the importance of making informed choices based on a balance of cost, availability, and performance. At StreamNative, we champion the principle of cost-awareness over mere cost-efficiency. Recognizing that no single technology suits every scenario, evaluating each platform's trade-offs in the context of specific use cases and business requirements is vital.
In conclusion, the data streaming technology selection journey is complex and nuanced. By adopting a cost-aware approach and understanding the inherent trade-offs, engineers and decision-makers can navigate this landscape more effectively, selecting the right technologies to meet their unique challenges and opportunities.




