
In the realm of data streaming platforms like Kafka, retaining data is often a necessity. Yet, navigating the complexities of data storage management within Kafka can pose significant challenges. This blog post explores the hurdles encountered in managing data retention in Kafka, and the comparative benefits Pulsar provides in this context.
Meet Kevin, a Kafka aficionado, and Patricia, a Pulsar professional. They are both tasked with managing a large amount of data in their clusters. What will their experiences be like?

Why store data in Kafka
Before joining the adventures of our friends Kevin and Patricia, let's briefly recall the reasons why it can be useful to store a certain volume of data on a data streaming platform like Kafka and Pulsar.
In numerous scenarios, the necessity to reprocess data arises, whether due to updates in processing logic or to rectify errors. The availability of historical data allows for this reprocessing.
Kafka, commonly utilized for event sourcing, captures every modification to the application's state as a series of events. This retention of records offers a comprehensive history of state alterations, aiding in audit, debugging, and tracing the trajectory of an entity.
Furthermore, some applications demand data processing within specific time frames, such as the most recent 24 hours. Keeping these records allows for such time-bound analyses.
Additionally, various industries face regulatory mandates that dictate the duration for which data must be preserved. Kafka's configurable retention settings accommodate these compliance needs efficiently.
Challenge #1 - reassigning partitions
Kevin’s experience
Kevin designed his cluster to accommodate up to 128TB of data, which, with a replication factor of 3, requires 384TB due to redundancy. Kevin's cluster comprises 6 nodes, each with a 64TB disk attached - 64TB is the maximum storage capacity per broker node possible for Kevin’s cloud provider.
Kevin's cluster hosts over 100 topics, totaling over 1000 partitions. Like most Kafka brokers at a non-trivial scale, the data distribution across nodes and partitions is not perfectly uniform.
This is illustrated in the diagram below. For improved readability, only three nodes and three topics are depicted, and the replicas are not displayed.
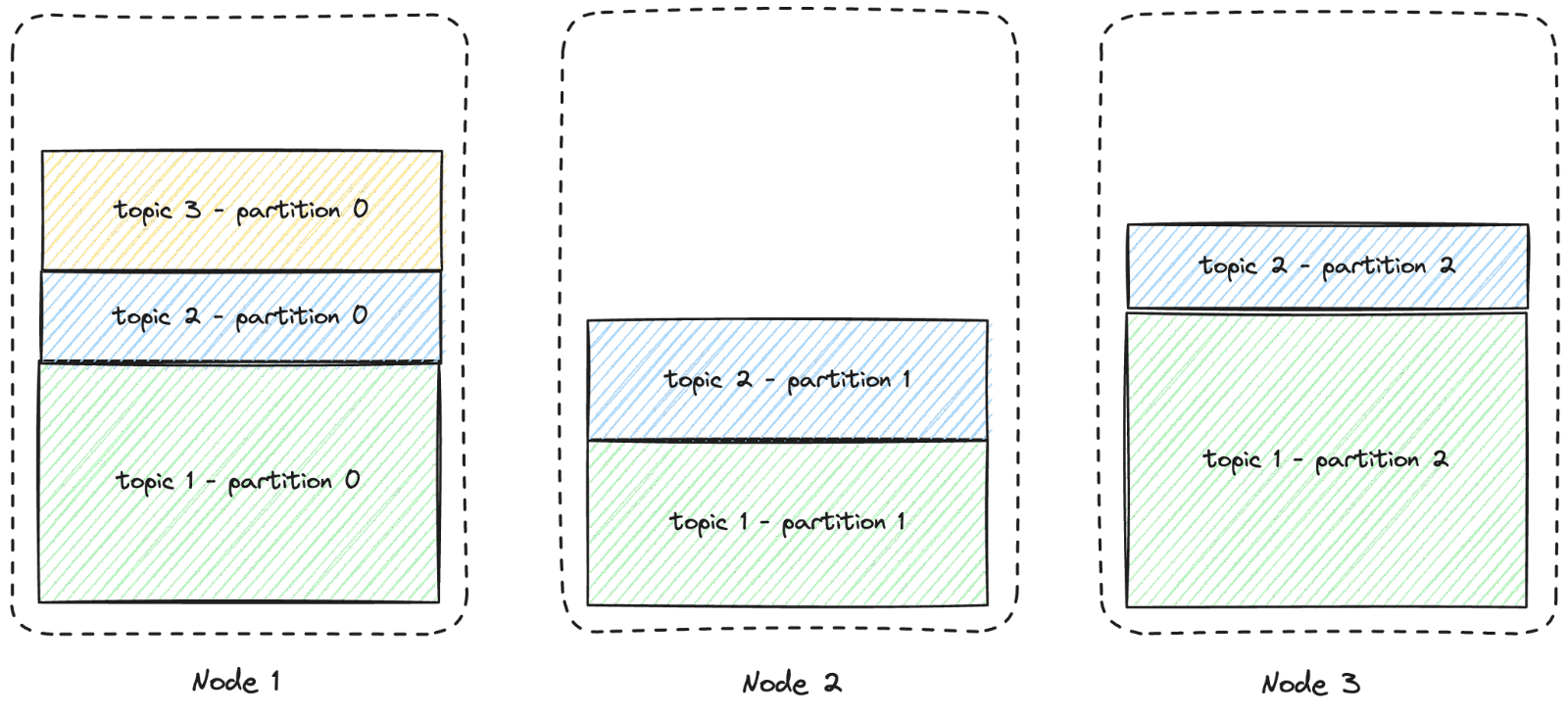
As business requirements evolve, Kevin must now accommodate an additional 20TB of data on a new existing topic divided into 3 partitions.
The total storage capacity available on the cluster is 30TB, so Kevin might believe the cluster can accommodate this.
However, one of the topics' partitions will exceed the capacity of one of the disks. Kevin faces an issue, as illustrated in the animation below:
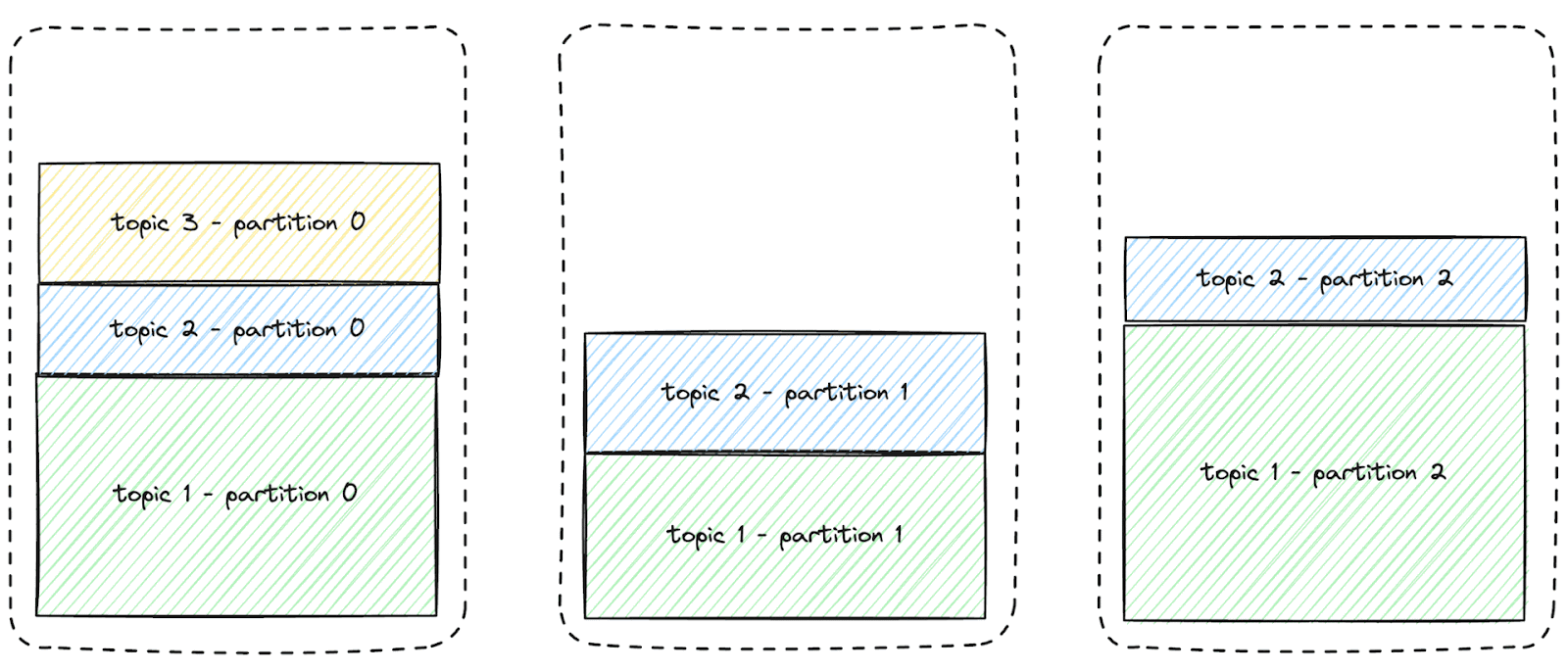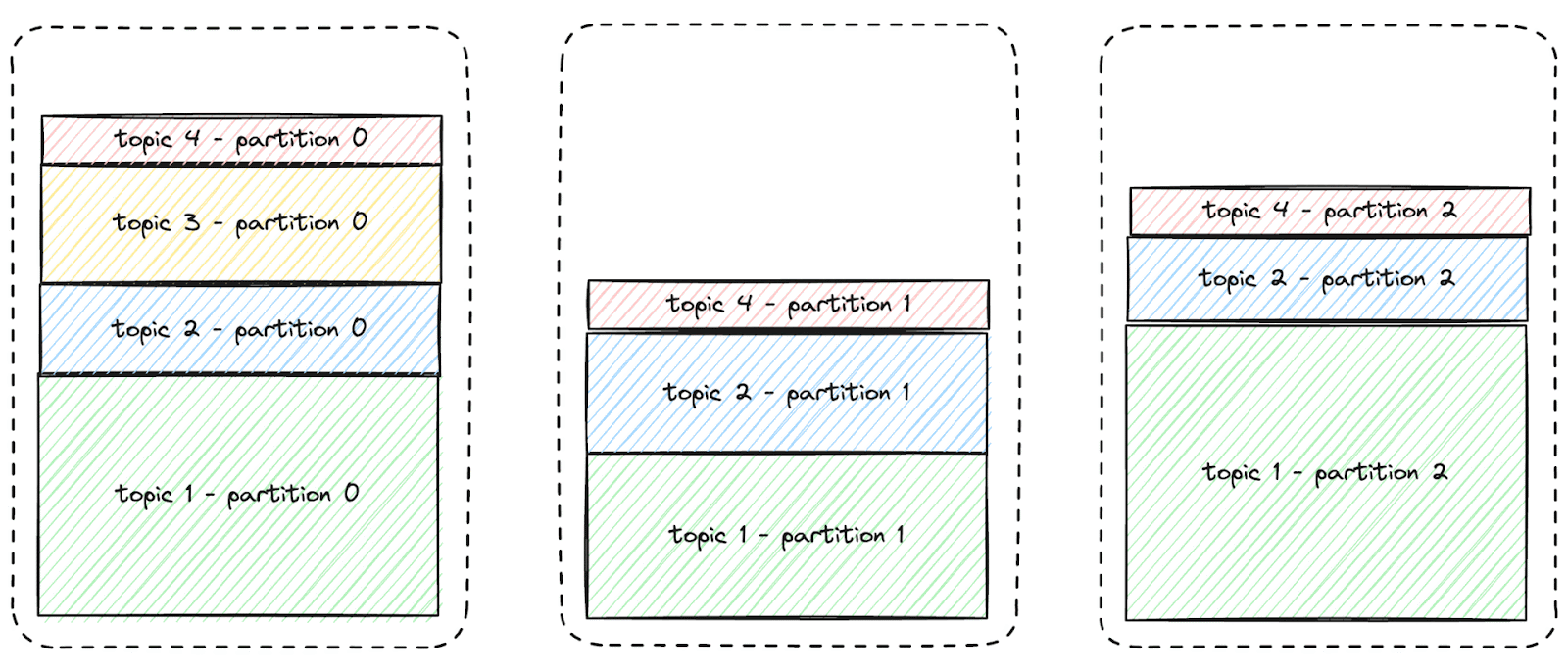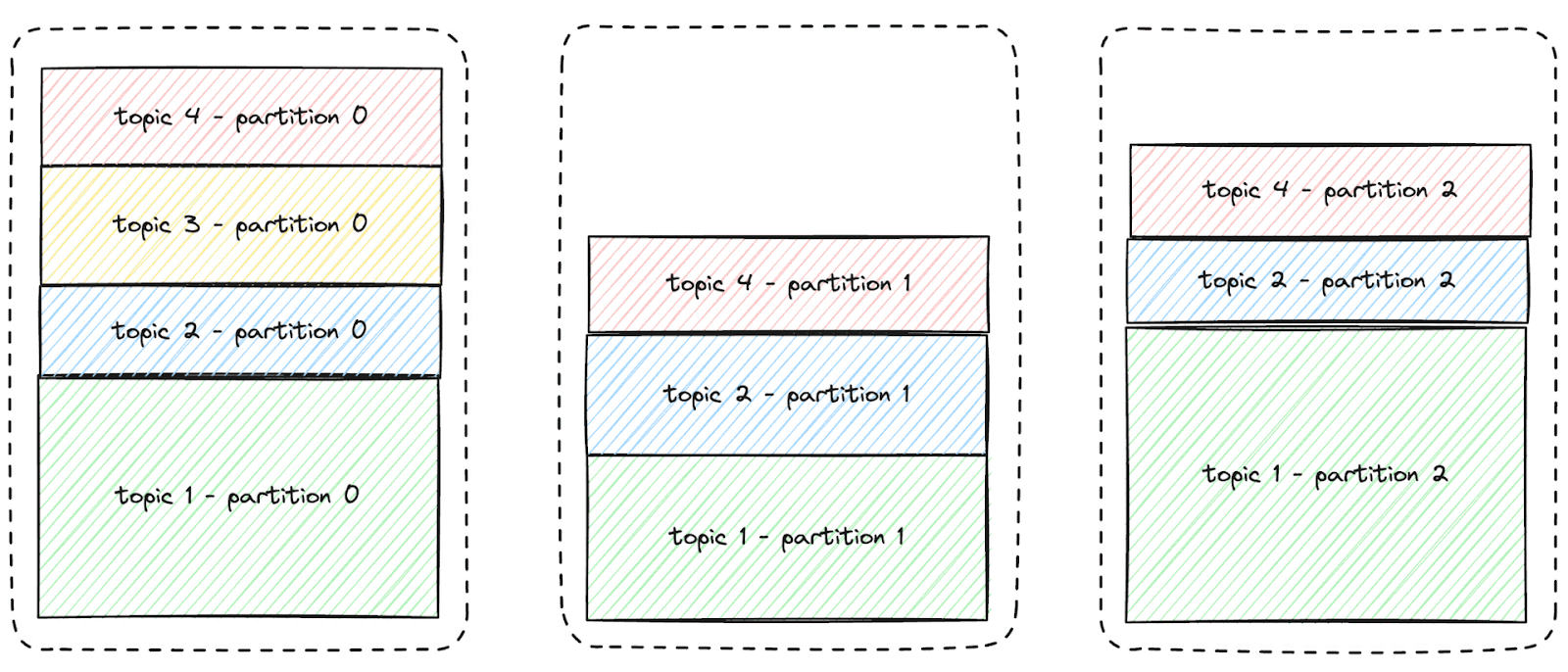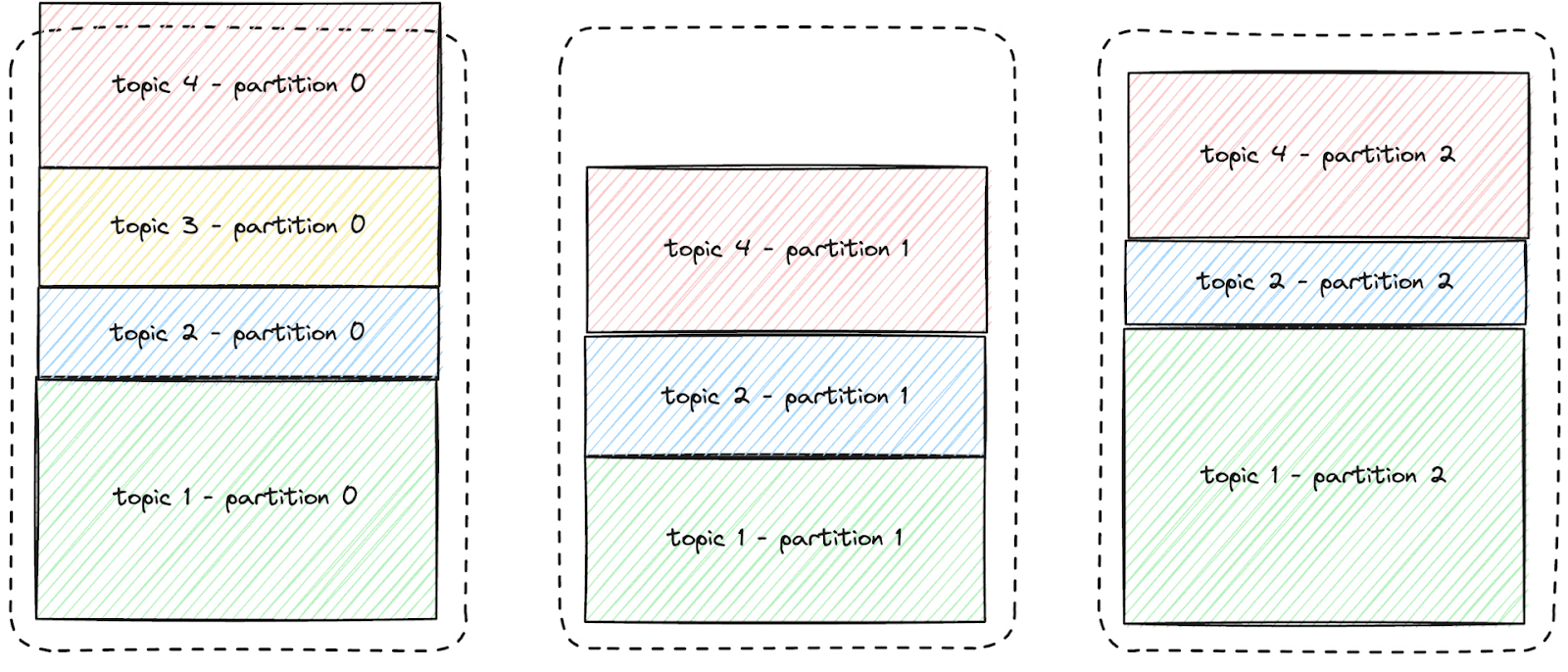
If Kevin doesn't intervene to prevent the partition from overflowing the first node's local storage, he will lose data.
Unfortunately, increasing the disk size isn't an option because it already reached the maximum size allowed by the cloud provider.
Here's the key point: in Kafka, message assignment to partitions is determined solely by message keys (for ordered delivery) or round-robin (for even distribution). The amount of free space on individual nodes does not play a role in this process.
Therefore, Kevin's only option to prevent data loss is to rebalance the partitions across nodes. The (very simplified) diagram below illustrates this concept. The yellow partition needs to be moved to another node to create space on the first node.
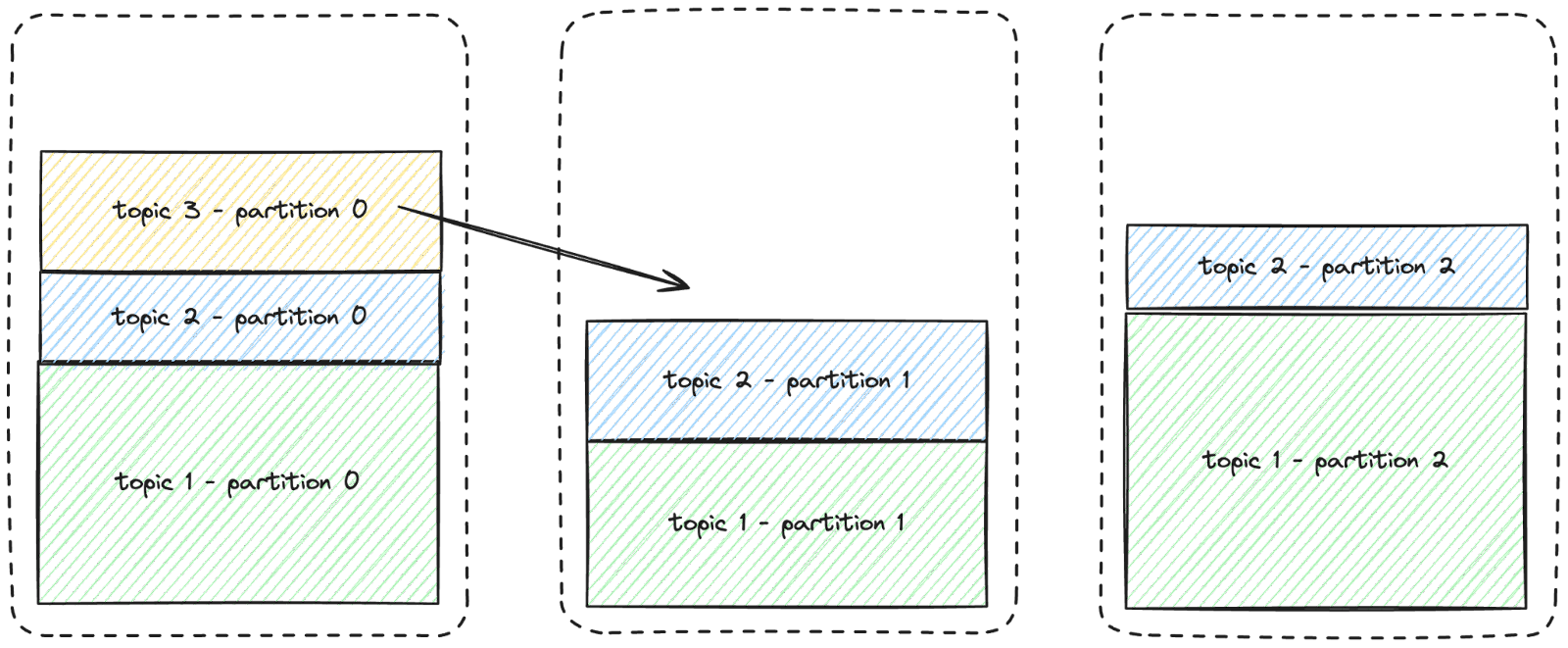
Kevin generates a partition assignment plan and executes it to move these partitions so the cluster can accommodate the new topic’s data, as illustrated below:

After the data migration, the new topic and its three partitions will fit on the nodes due to sufficient storage capacity on each node.

The reassignment of partitions presents Kevin with several challenges.
This process transfers 1 TB of data, significantly consuming bandwidth and disk IO. With a network speed of 100 MB/s, this data transfer can take several hours!
The brokers' network and disks, being shared resources, face contention between the re-partitioning process and the ongoing data ingestion/consumption by other topics. This contention affects the entire system's performance.
To minimize this impact, Kevin must enable throttling, which further increases the time required.
Unfortunately for Kevin, this operation took too long: one of the disks became full. Kevin starts losing data, and there is nothing he can do to alleviate it immediately.
While handling these issues in a small-scale Kafka cluster with limited data might be manageable, the challenges significantly increase as the volume of retained data grows.
Patricia’s experience
In this scenario, Patricia simply needs to ensure enough space is available in her Pulsar cluster for the incoming 20TB of data. She does not need to worry about the distribution of the existing data across the cluster.
The reason? Pulsar employs a segment-based storage model rather than a partition-based one. This approach enables smooth and even data distribution across all nodes, eliminating the need for large and long-running data transfers across broker nodes caused by partition reassignments.
Unlike partition-based storage models, where adding more data to a partition is capped by a single disk's available space, Pulsar's model avoids this constraint. Indeed, Pulsar stores the topic data using segments instead of partitions.
Below is a visual representation of these models:
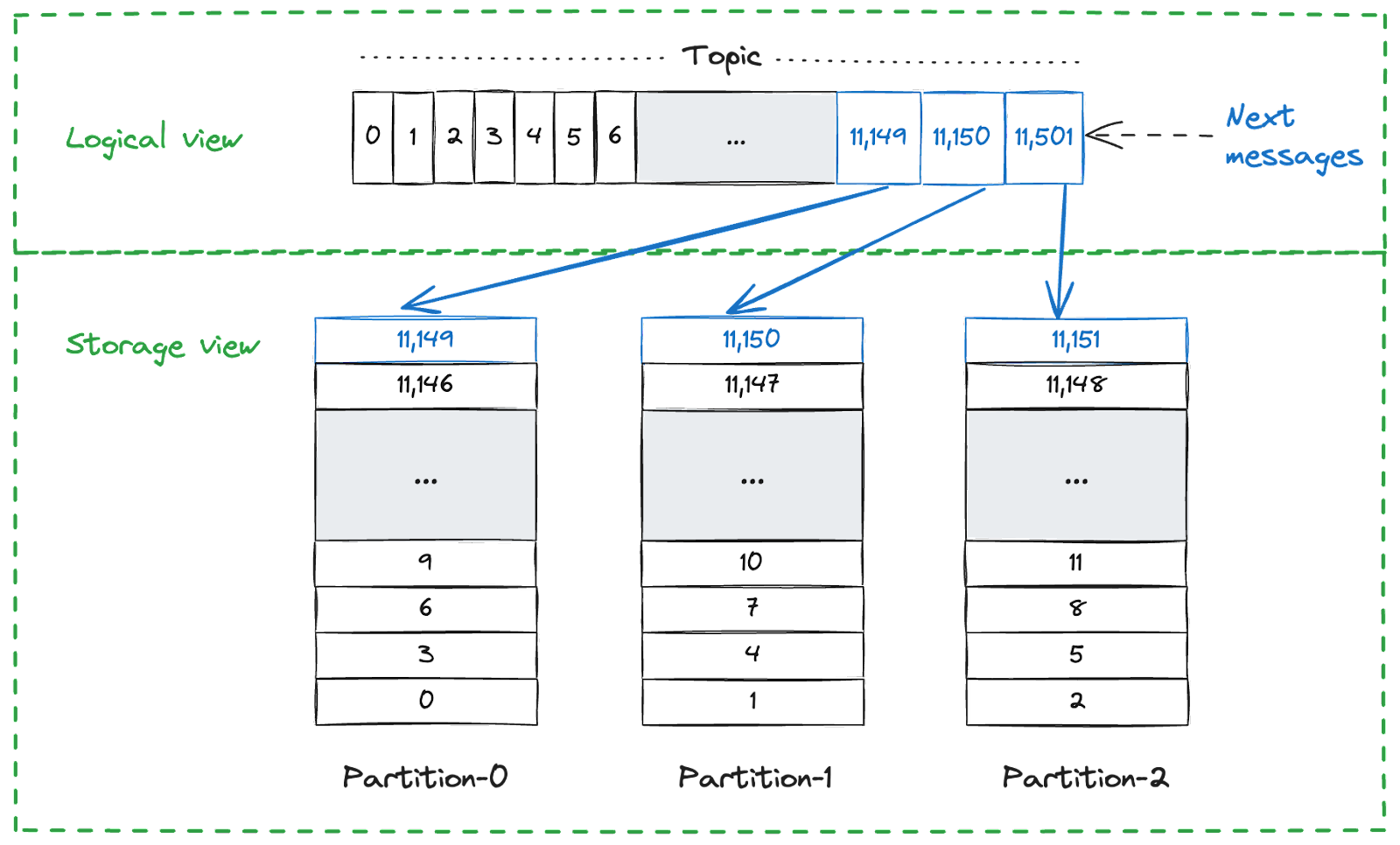
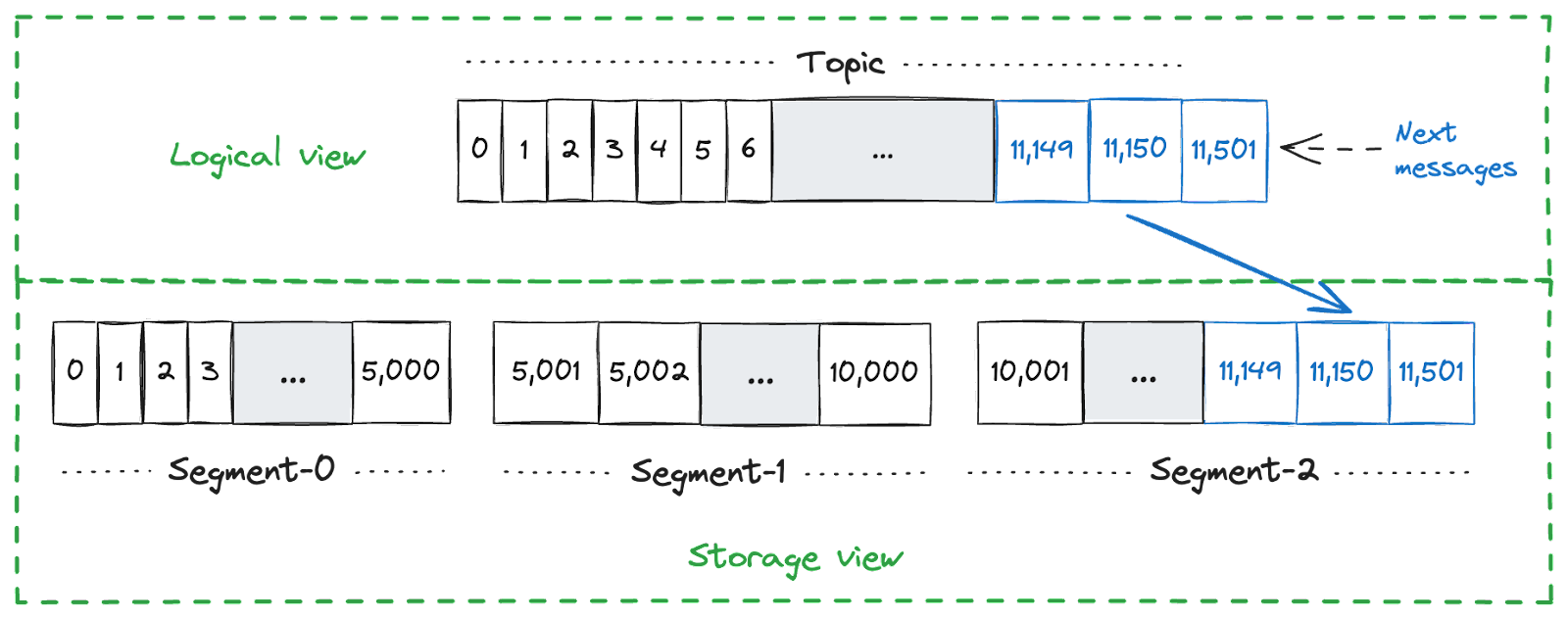
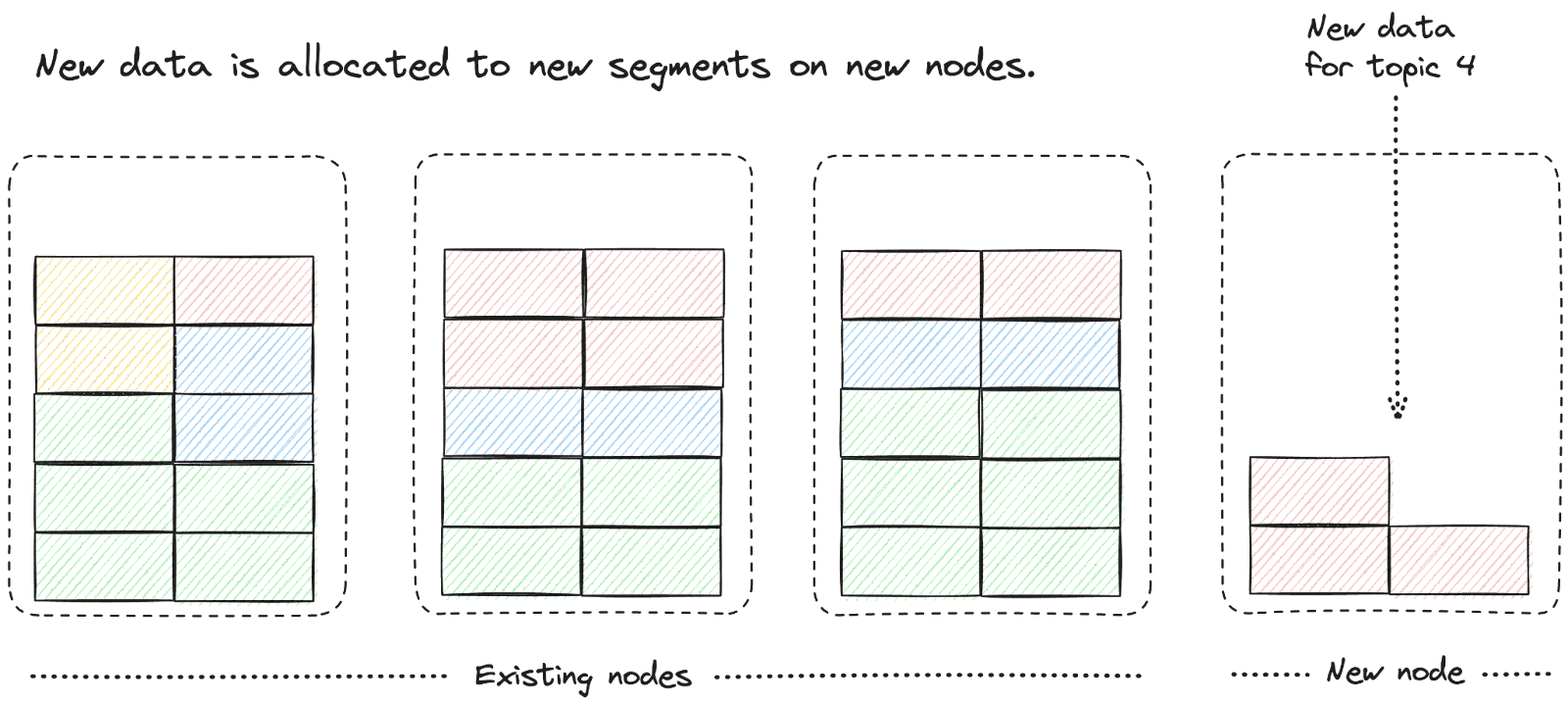
Using the segment-based storage model above, adding more data is not capped by a single disk. The data distribution across the nodes is not coupled to the distribution of message keys in the topics. This allows a single topic to efficiently use the storage available across the entire cluster, as illustrated below:
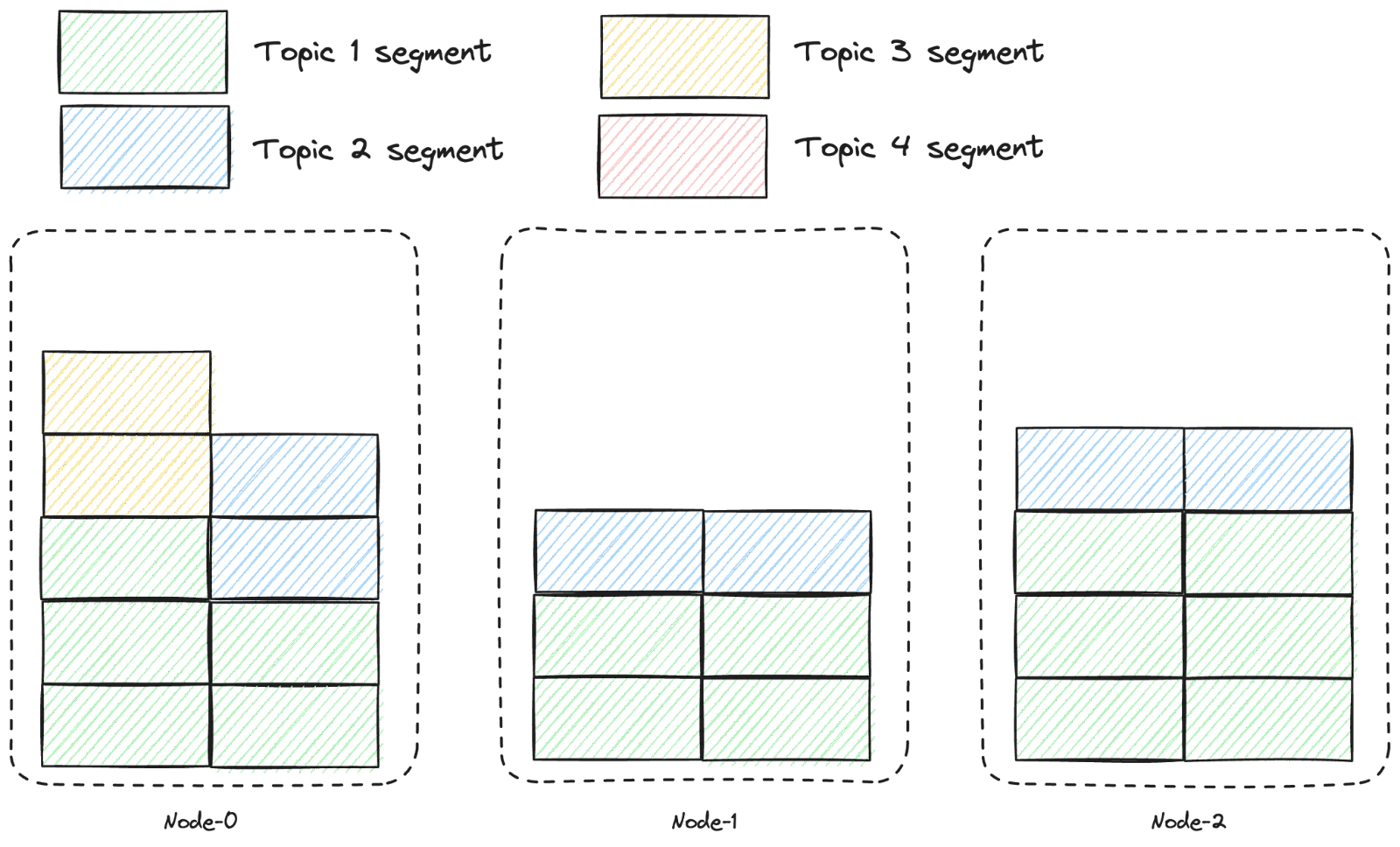
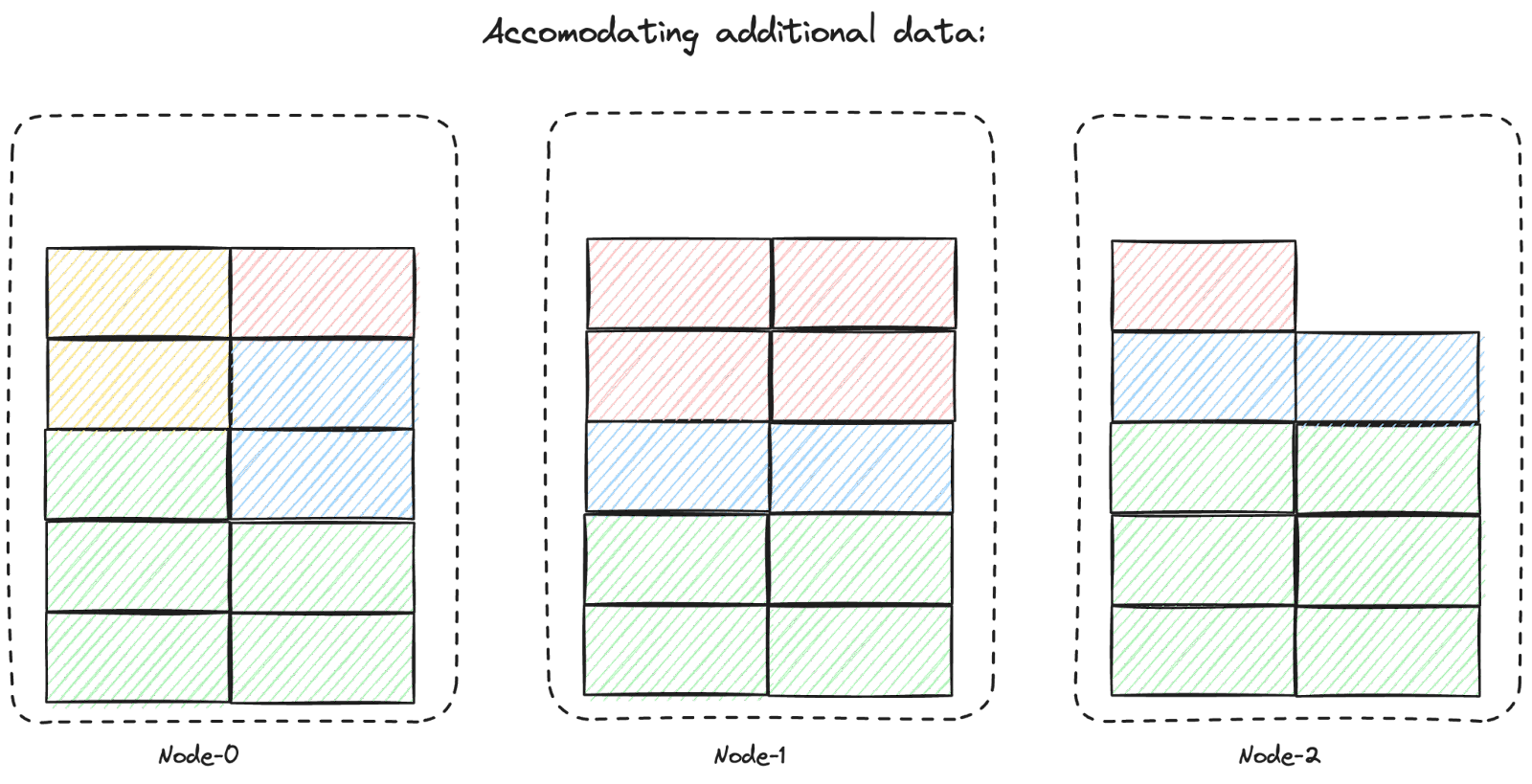
This segment-based storage model means less operational burden for Patricia, reduced risks, and a better quality of service.
For an in-depth exploration of the segment-based model and its distinctions from the partition-based model, feel free to read the Data Streaming Patterns Series blog post on Segmentation.
Challenge #2 - expanding the storage capacity
Kevin and Patricia have to prepare their respective clusters to store an additional 10TB on an existing topic. Unlike the previous scenario, their clusters do not have enough free storage space for that. They have to expand their cluster storage capacity by adding new nodes. To ensure the data is replicated at least three times, they each add three nodes.
Kevin’s experience
Kevin has added three broker nodes. However, the partitions continue to grow, leading to storage space depletion on the existing nodes. The cluster isn't ready to utilize the additional storage capacity yet. This is illustrated in the diagram below - for better clarity, the diagram shows one new node without replicas:
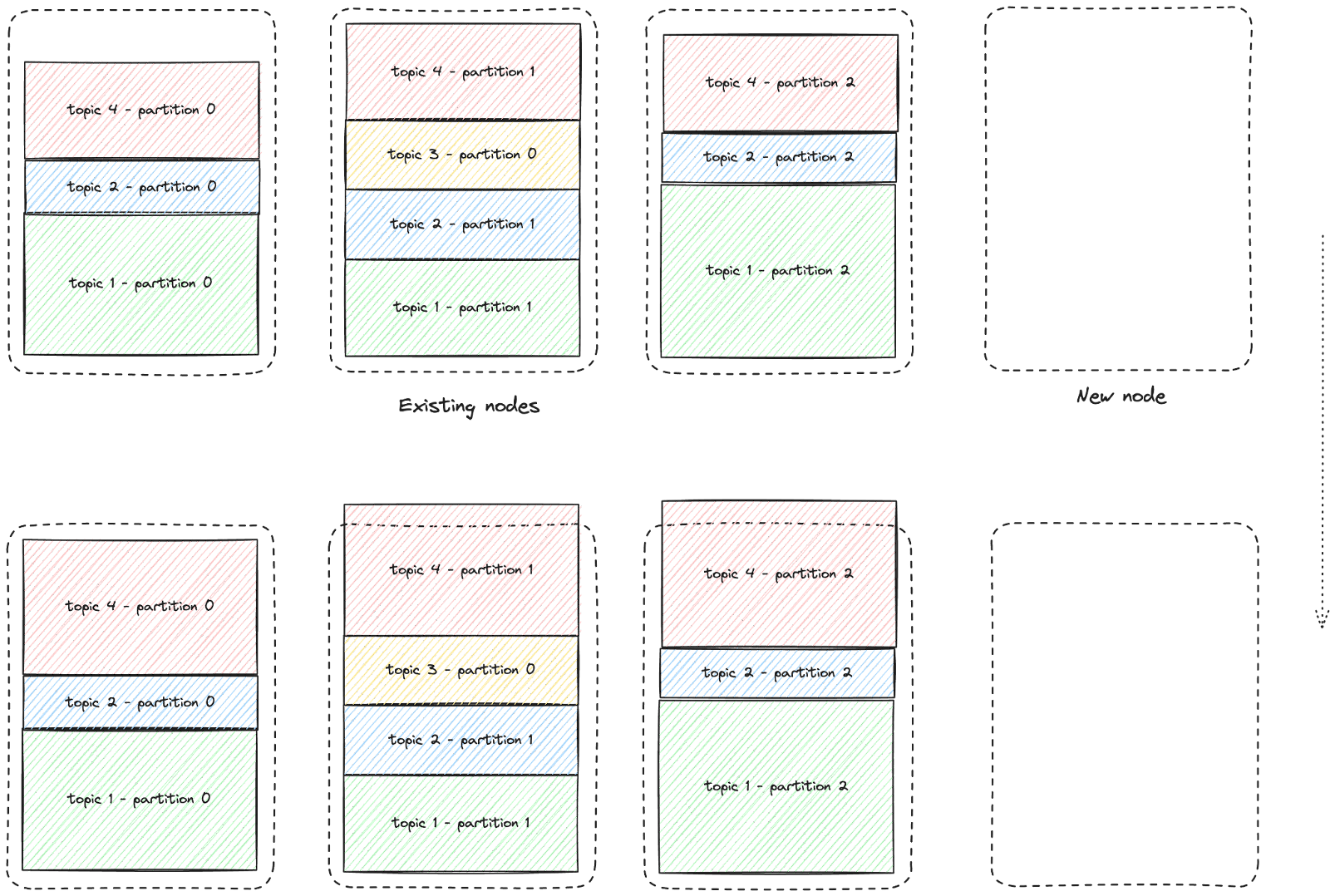
To avoid the situation described above, Kevin needs to reassign topics' partitions, ensuring that data is distributed across all nodes and that the storage space of the new nodes is effectively utilized. Therefore, Kevin has decided to rebalance the data to create more space on the nodes and achieve an even distribution of data across all nodes, preparing for future incoming messages on the topics:
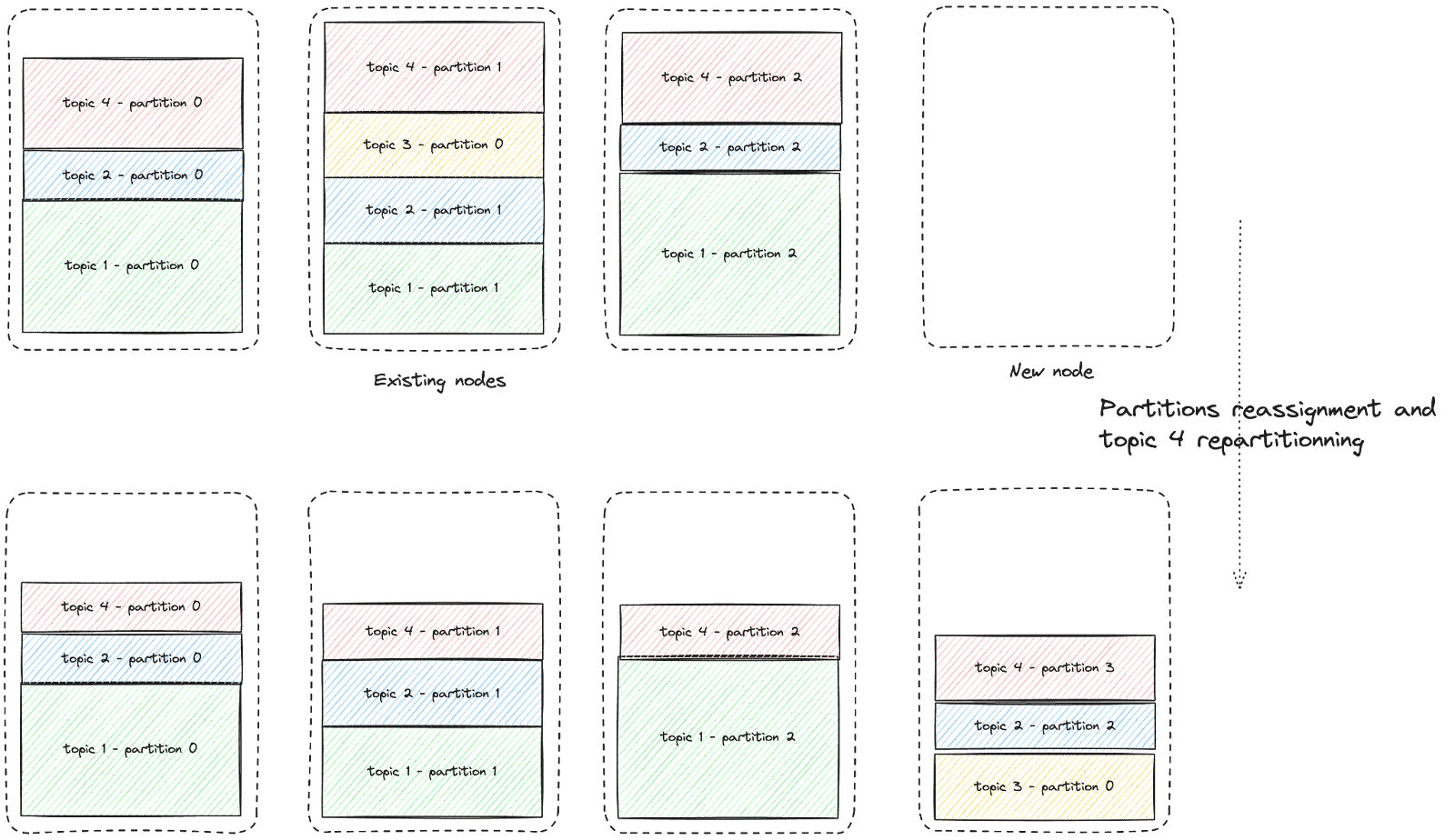
This operation requires the transfer of an enormous amount of data. Kevin finds himself dealing with the issues he faced in the previous scenario but on a larger scale.
Patricia’s experience
Patricia needed to store an extra 10 terabytes of data on her Pulsar cluster. To achieve this, she simply added new storage nodes, following a similar approach as Kevin's.
However, unlike Kevin's experience, Patricia's process was smooth sailing. She avoided the time-consuming and manual tasks Kevin had to perform, like designing, executing, and monitoring partition reassignments. There was also no noticeable decline in message consumption or production for her clients.
This efficiency is, again, all thanks to Pulsar's segment-based storage model. In this model, as new data arrives on topics, new segments are automatically created to store it. These new segments are then automatically distributed and stored on the new nodes, allowing the new nodes to store new messages right away.
Keeping costs under control

For Kevin and Patricia, managing costs in their massive clusters is crucial. However, Kevin faces a steeper challenge.
Firstly, scaling out Kevin's cluster impacted his budget significantly. The massive data movement during repeated partition reassignments caused data transfer costs to skyrocket. Indeed, cloud providers charge for transferred data, and these costs can be significant.
On the other hand, Patricia's infrastructure budget only increased due to additional nodes and disks, with no data transfer cost spikes.
Secondly, Patricia required far fewer manual, time-consuming, and risky operations in those scenarios mentioned in this blog post, saving both time and money.
To explore the broader topic of TCO for messaging and data streaming platforms, which goes beyond just data retention, check out the following blog post: Reducing Total Cost of Ownership (TCO) for Enterprise Data Streaming and Messaging
What about Tiered Storage?

Kevin has heard of Kafka's offloading feature, which allows data to be stored out of the cluster. He thinks this feature could solve all these problems. This would mean less data would be moved during partition reassignments because most of the data would not be stored on local disks. Kevin hopes this will remove performance issues, improve flexibility, and cut data transfer costs. Offloading could also lower storage costs by needing fewer nodes for data storage and leveraging a cost-effective storage solution such as Amazon S3.
However, Kevin will soon realize that Tiered Storage, despite its potential, also presents unique challenges. Keep an eye out for our next blog post, where we'll delve into Kevin's experiences with Tiered Storage.
Want to learn more?

For deeper exploration of these subjects, you're encouraged to:
- View David Kjerrumgaard’s webinar for an insightful analysis of challenges and Pulsar’s solutions: Decoding Kafka Challenges - free webinar
- Discover the nuances between partitioning and segmentation in our blog by Caito Scherr: Data Streaming Patterns: What You Didn't Know About Partitioning
If you're inclined to experience Pulsar from Patricia's perspective rather than Kevin's:
- I invite you to try out Pulsar here: Get started | Apache Pulsar
- An excellent way to quickly get started with Pulsar in production is through StreamNative: Book a demo or get started on StreamNative Hosted with a 200$ credit.
Looking to grasp Pulsar’s concepts quickly?
- Check out the video: Understanding Apache Pulsar in 10 minutes video
- Read a concise guide: Understanding Apache Pulsar in 10 Minutes: A Guide for Kafka Users | StreamNative




