
Background
As enterprises scale their data infrastructure, seamless data replication and migration become critical for operational efficiency. Organizations managing real-time data pipelines often face challenges in replicating data across clusters, migrating from legacy Kafka deployments, and ensuring business continuity during these transitions.
At StreamNative, we understand the importance of a frictionless and cost-efficient approach to data replication and migration. That's why we announced the availability of Universal Linking in Private Preview at the Data Streaming Summit in October,2024. We are now introducing StreamNative Universal Linking Public Preview, which offers a powerful experience designed to make data movement between environments effortless.
Use Cases
StreamNative Universal Linking is designed to support a wide range of use cases; however, this post will primarily highlight the following use cases.
- Seamless Kafka Migration to StreamNative Enable a zero-downtime, low-risk migration strategy for organizations moving from Apache Kafka to StreamNative (Apache Pulsar).
- Facilitate incremental migration of Kafka workloads with Universal Linking, ensuring minimal disruption during application transitions.
- Real-Time Data Lakehouse Bridge Kafka’s real-time streaming data with modern lakehouse architectures.
- Continuously replicates Kafka topics into Delta Lake or Iceberg tables to fuel AI/ML pipelines, hybrid analytics (HTAP), and real-time decision-making.
Challenges
Organizations undergoing data replication and migration typically face the following challenges.
- Offset Management – Maintaining consistent offsets across clusters is complex, especially for active consumers, to prevent duplicate processing or message loss.
- Schema Replication – Managing schema compatibility, evolution, registry sync, cross-cluster lookups,
- Operation Complexity – Maintaining, upgrading, and managing Kafka clusters may seek a managed alternative to offload operational burdens.
- High Networking Costs – High networking costs from traditional wire-protocol-based data replication methods which also suffer from protocol-specific limitations.
Introducing Universal Linking Public Preview
We are excited to introduce Universal Linking in Public Preview , a tool built to simplify and accelerate Kafka migration and build a Real-Time Data Lakehouse.
Key Capabilities:
- Full-Fidelity ReplicationPreserve topics, offsets, schemas, and ACLs for an exact Kafka replica with full offset preservation.
- Cost-Effective by Design Cut storage costs by 20x with direct-to-lakehouse streaming, eliminating bottlenecks and cross-AZ fees.
- Seamless Kafka IntegrationWorks with Confluent, AWS MSK, Redpanda, and self-hosted Kafka for seamless replication, migration, and scaling—no code changes needed.
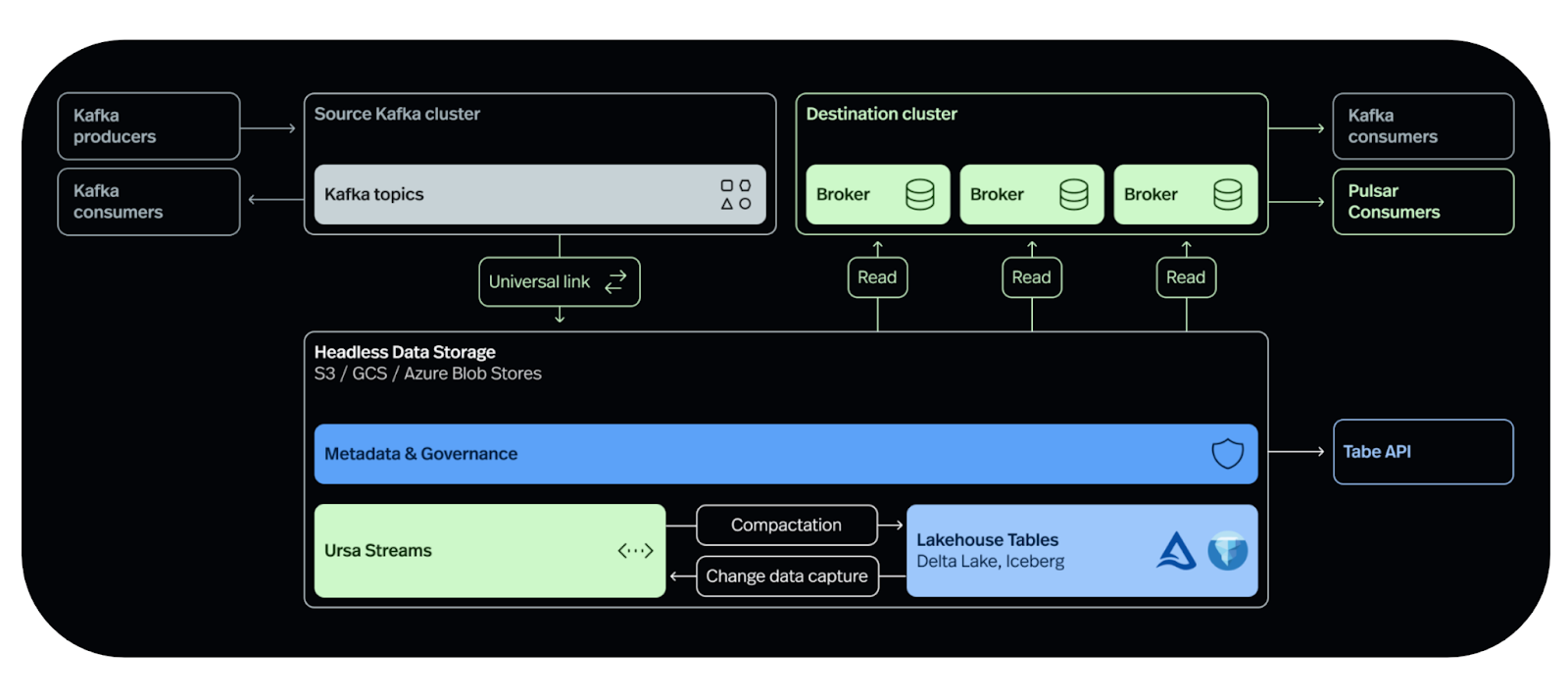
With Universal Linking, enterprises can seamlessly build a Real-Time Data Lakehouse, replicating data from a source Kafka cluster to object storage, integrating it with a data catalog, and enabling effortless querying. When ready to transition from the source Kafka cluster, organizations can seamlessly migrate their applications to the destination cluster on StreamNative Cloud.
Walkthrough
This walkthrough provides details on utilizing Universal Linking (UniLink) to build a Real-Time Data Lakehouse and facilitate Kafka migration. The process involves configuring source and destination clusters, streaming data to an S3 table bucket, and querying data from Amazon Athena. After establishing a pipeline to stream data to a Real-Time Data Lakehouse, we will explore the steps required to transition producers and consumers to a new StreamNative cluster, enabling a seamless migration from the source Kafka cluster.
While StreamNative’s platform supports multiple catalogs—including Databricks Unity Catalog, Snowflake Open Catalog, and Amazon S3 Tables—this post specifically focuses on S3 Tables Integration.
Prerequisites
- An AWS account with access to the following AWS services:
1.1 Amazon S3
1.2 AWS Identity and Access Management (IAM)
1.3 Amazon Athena
1.4 AWS Glue
1.5 AWS Lake Formation - Create a BYOC infrastructure pool by taking the following steps.
2.1 Grant StreamNative vendor access to manage clusters in your AWS account.
2.2 Create a cloud connection for StreamNative to provision your environment.
2.3 Create Cloud Environment to provision Pool Members in your designated cloud region.
2.4 Watch this video for a detailed explanation. - Create StreamNative BYOC Ursa Cluster where data will be replicated
3.1 Follow these steps to create a StreamNative Ursa cluster.
3.2 Enable S3 Tables Integration while deploying Ursa cluster
Step 1: Create UniLink to replicate data from source to StreamNative Cluster
We will be creating two UniLinks. One for Data Migration and one for Schema migration.
Data Migration
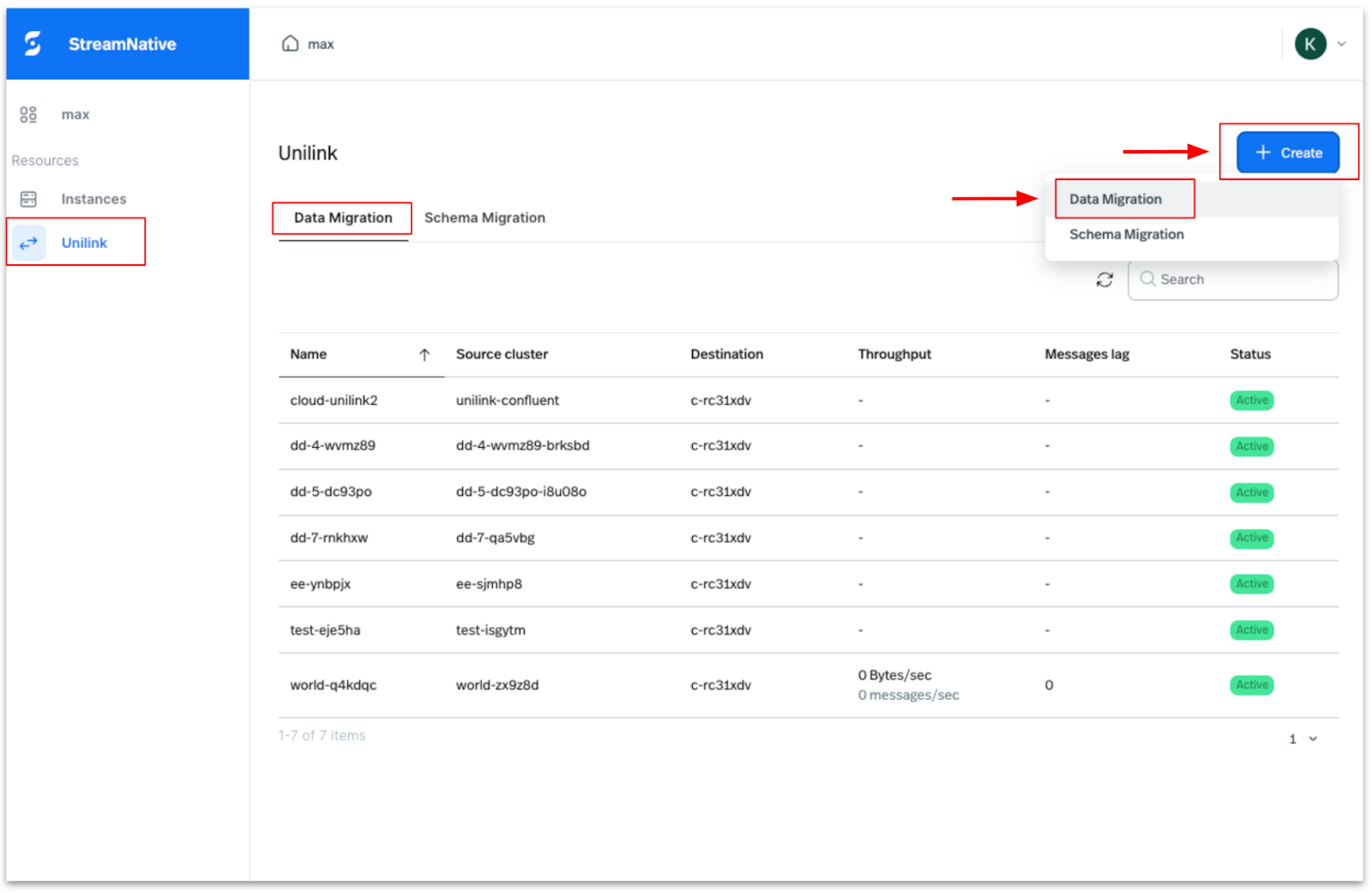
On the StreamNative Cloud homepage, navigate to the left-hand menu and select UniLink. Then, click Create and choose Data Migration, as illustrated in the image below.
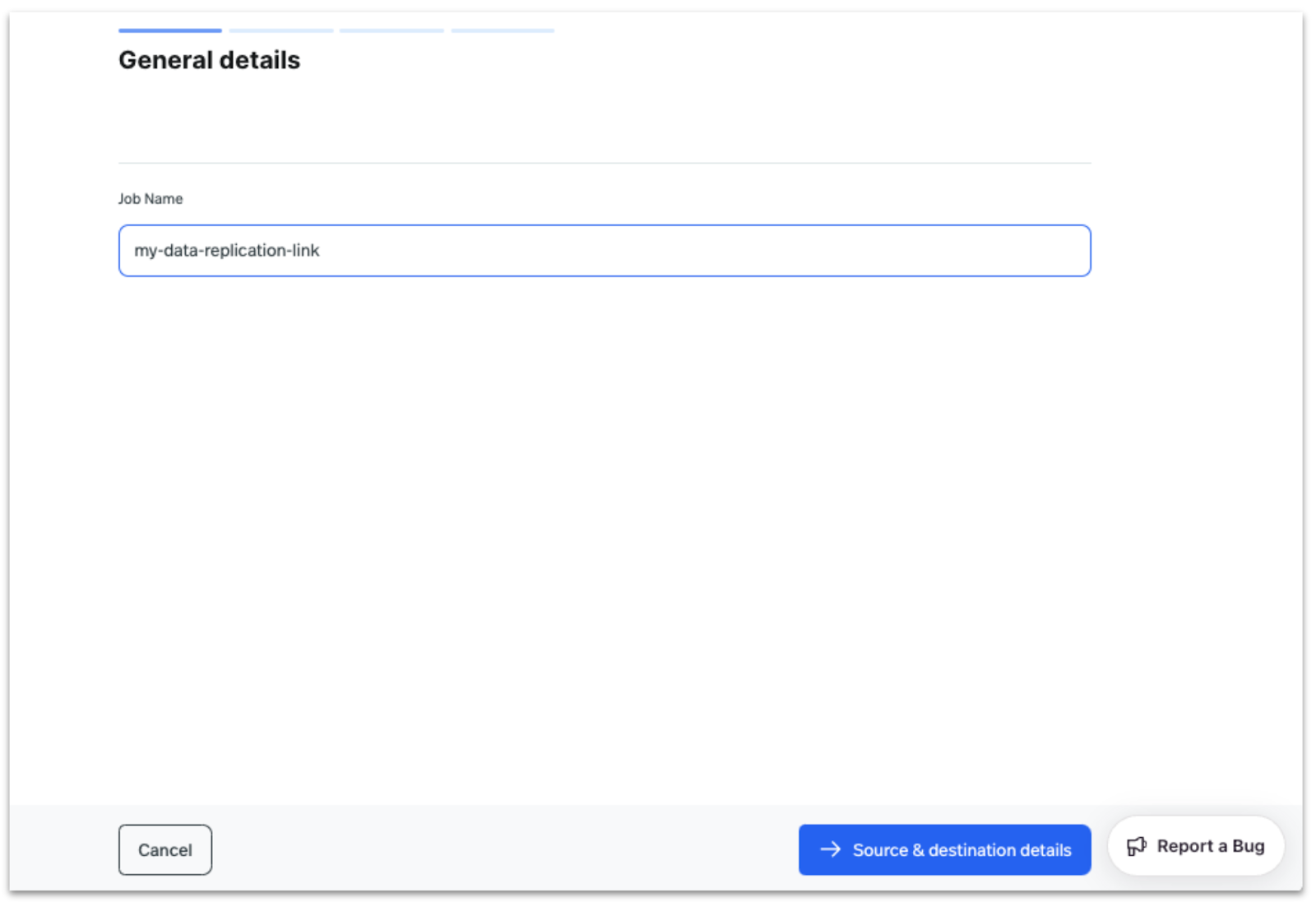
Enter a name for the Data Migration UniLink, then click on Source and Destination Details.
Enter the Source Cluster Broker URL, Destination Instance, and Ursa Cluster in StreamNative Cloud. Then, provide the Key/Secret for source Kafka cluster for authentication, and click on ‘Connect & Deploy.’
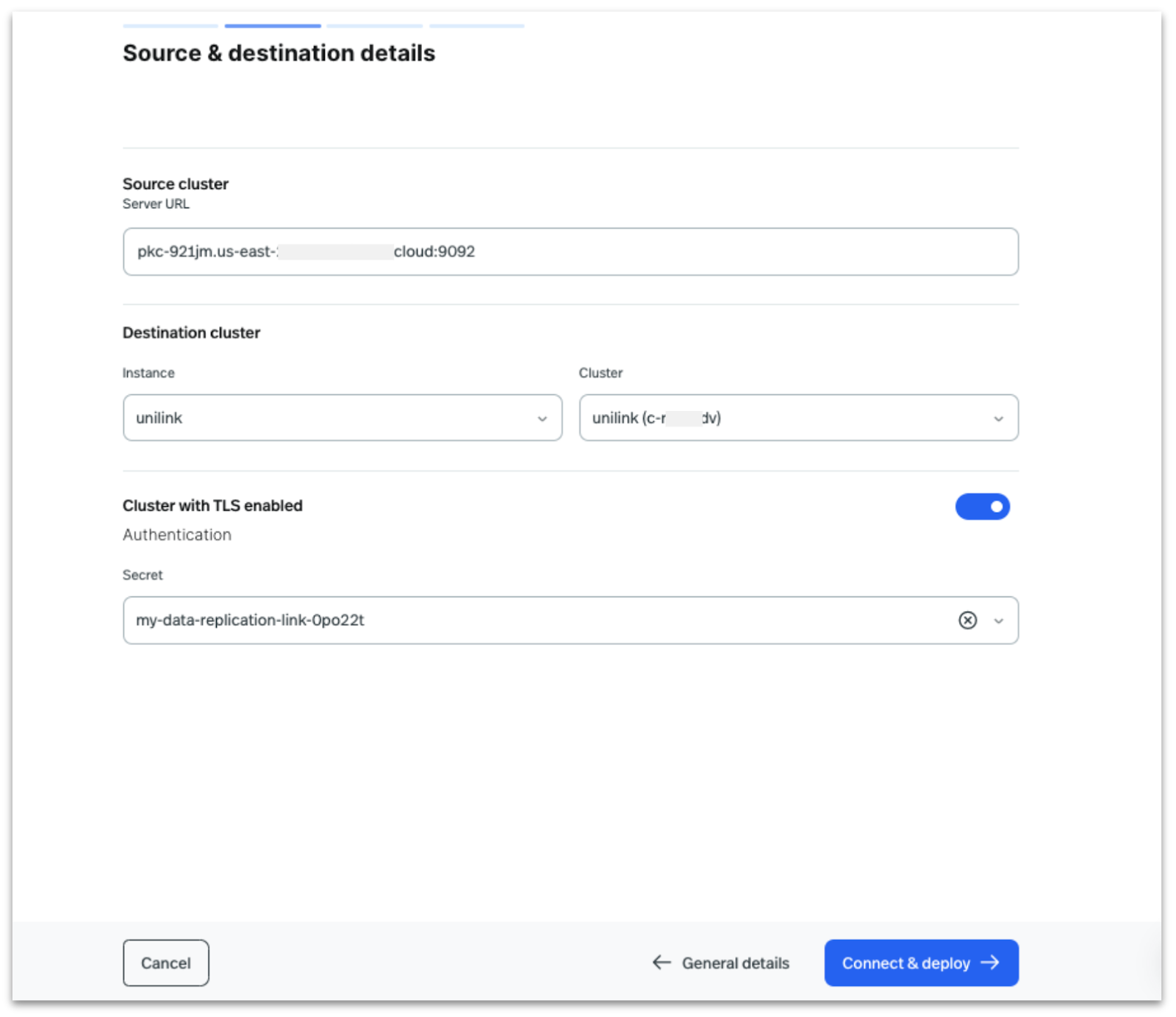
After clicking Connect and Deploy, the UniLink runtime verifies the connection and proceeds upon successful authentication. If the connection fails, the user is prompted to return to the previous step to correct the source cluster details.
In the next step, configure the topics to be migrated from the source to the destination cluster. You can either select All Topics Replication to replicate all topics or specify topics to migrate using a regex expression. In this guide, we will select All Topics Replication, as shown in the image below.
Additionally, you can specify the tenant and namespace for the destination StreamNative Ursa cluster. In this post, we will keep the default settings, allowing the Data Migration UniLink to migrate topics and data to the default tenant (public) and default namespace (default).
After entering all details, click Deploy.
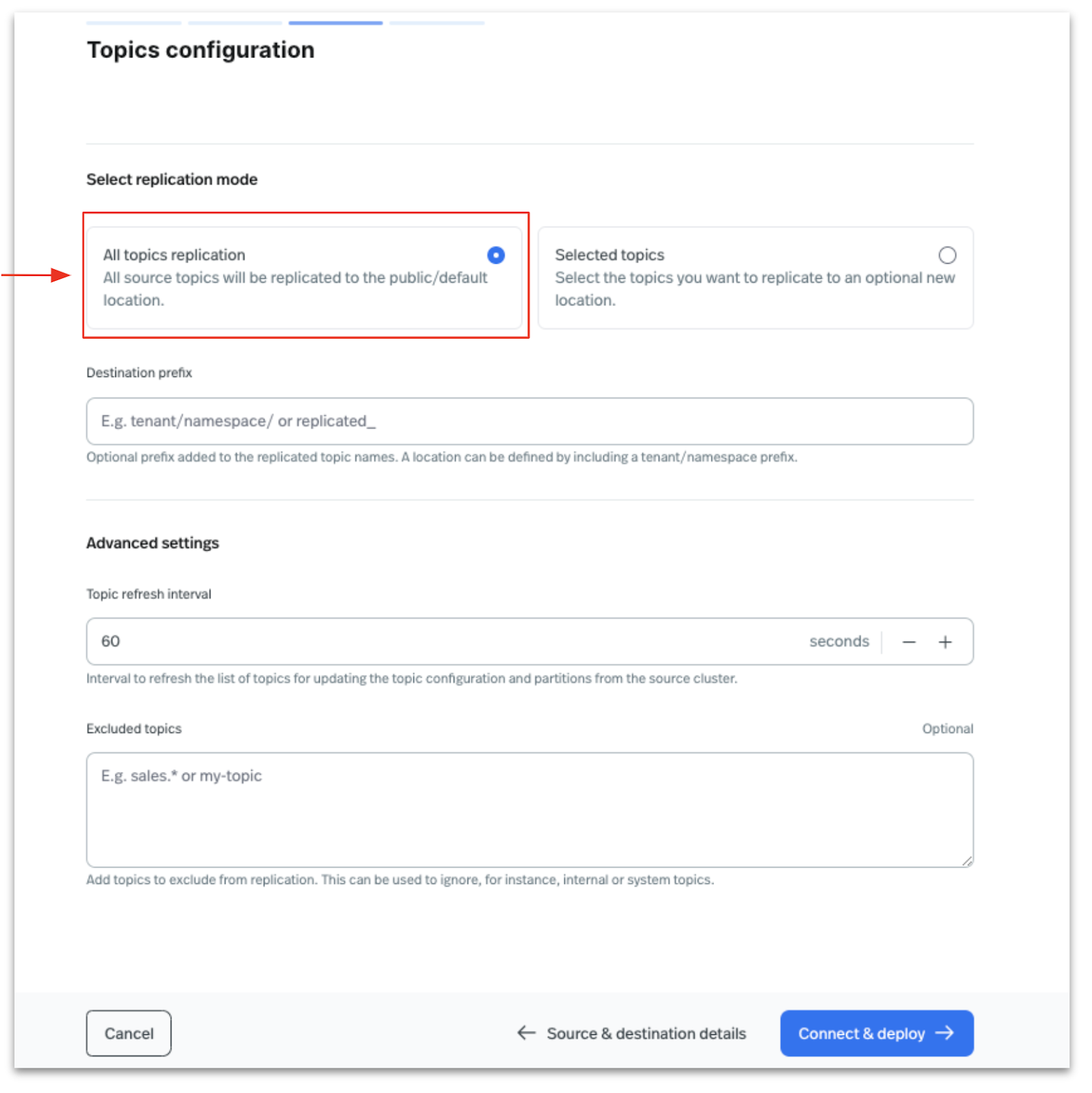
Preview the topics from your source cluster and click Continue.
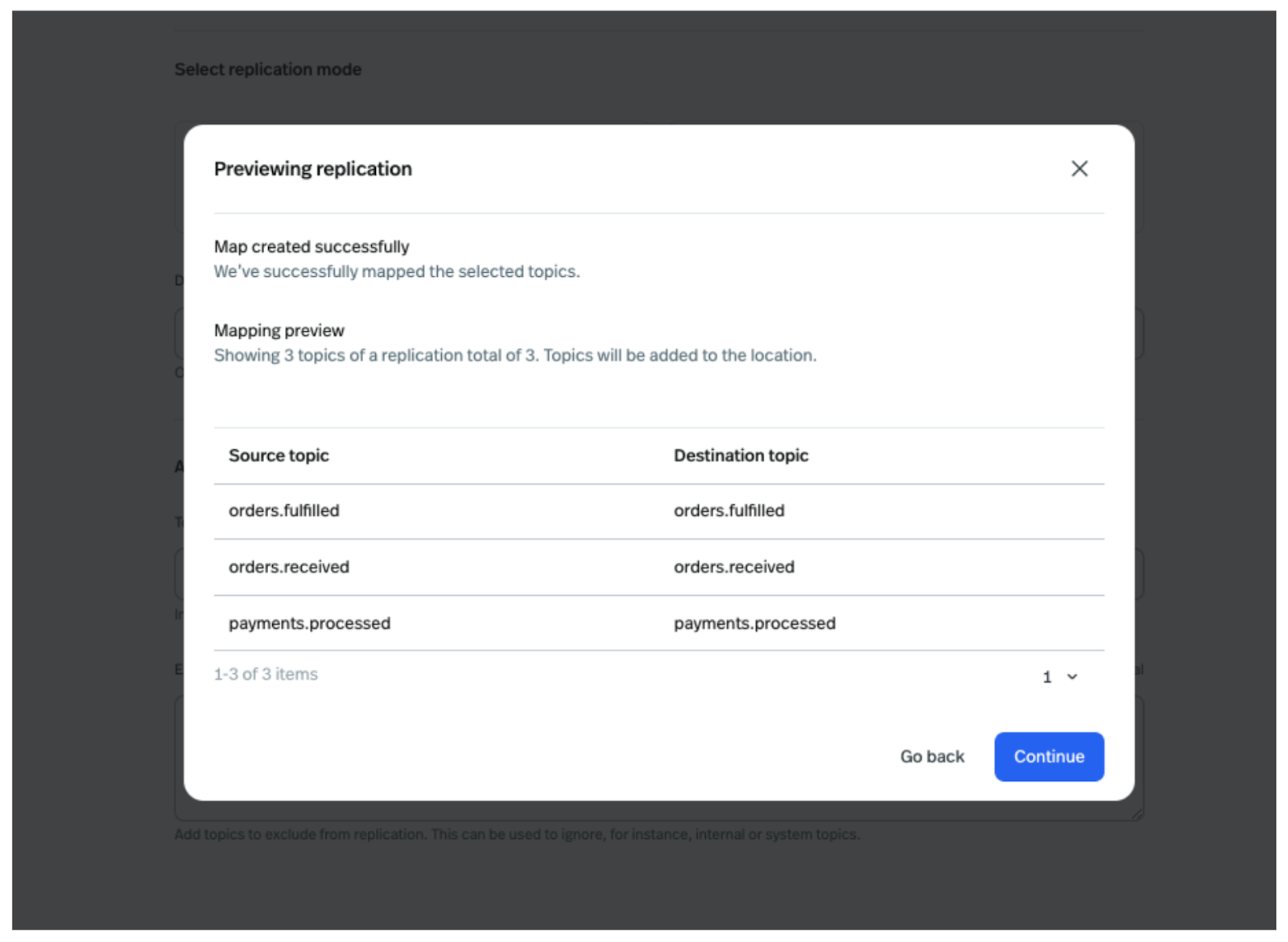
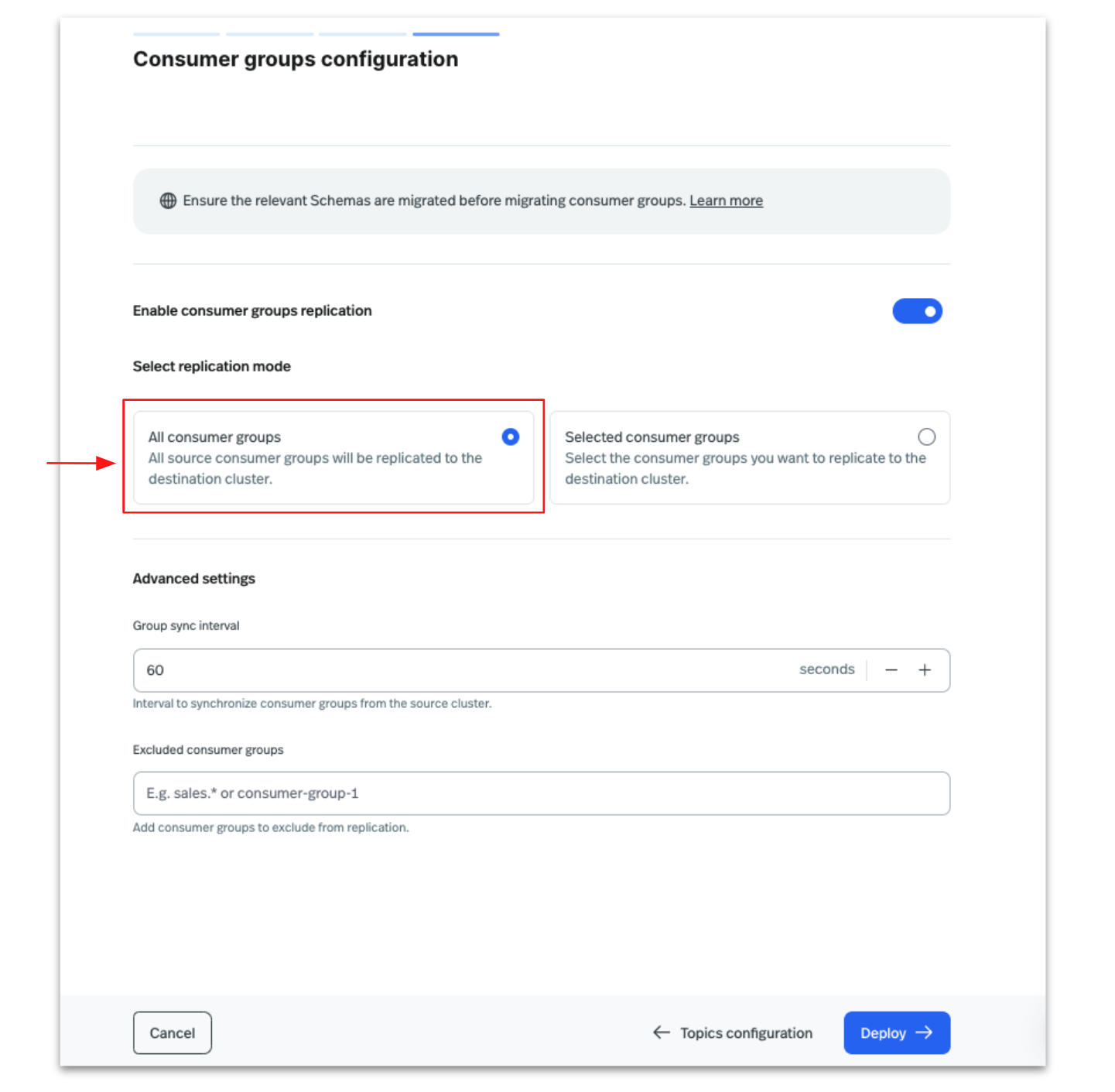
In the next optional step, configure Consumer Groups by either selecting All Consumer Groups or specifying specific consumer groups using a regex expression. In this post, we will choose All Consumer Groups and click Deploy.
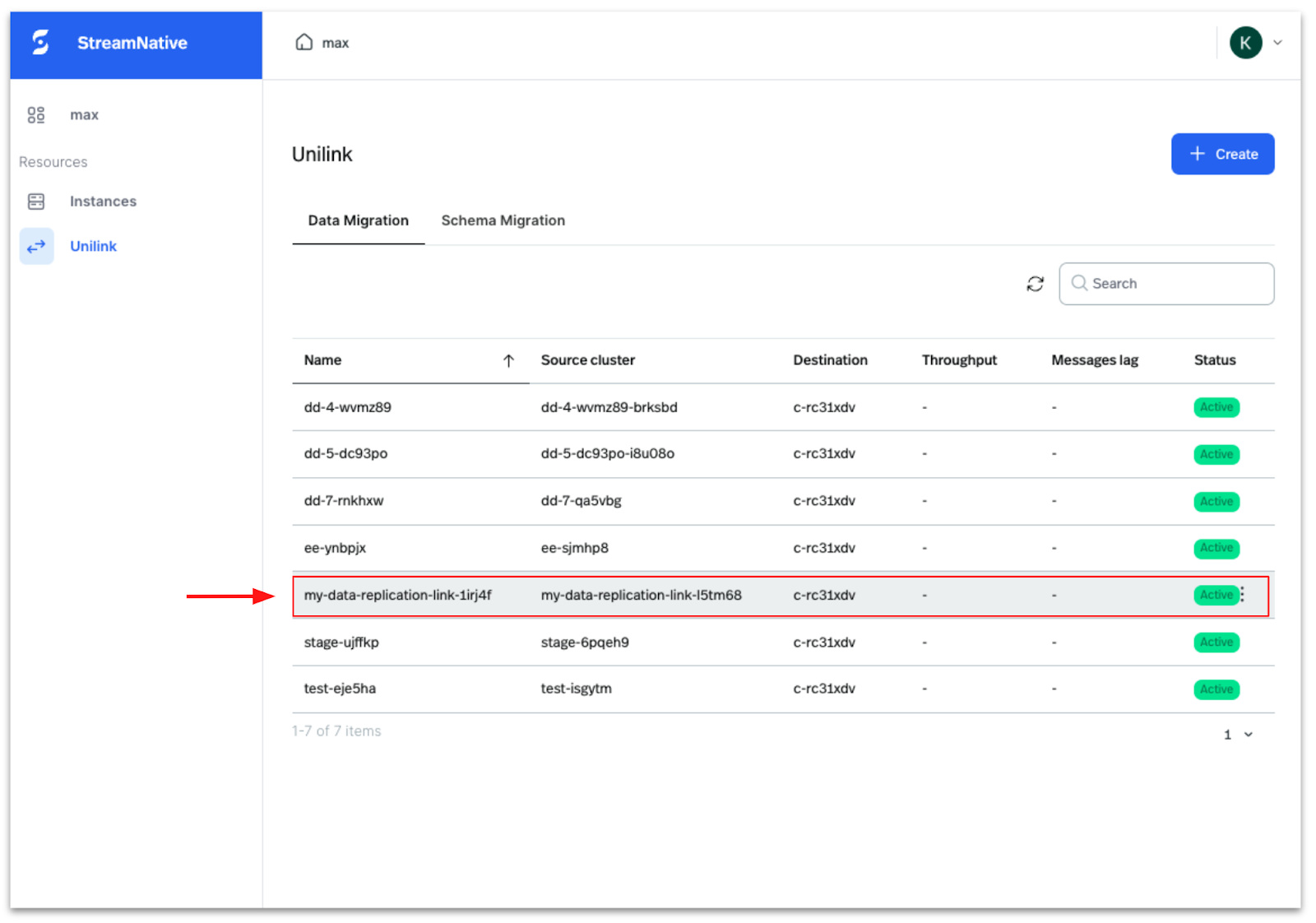
Once the Data Migration UniLink is deployed you can find it in the list view as highlighted in the picture below.
In the next section, we will review the topics and data replicated by this Data Migration link. However, before proceeding, let's create a link to replicate schemas.
Schema Migration
On the StreamNative Cloud homepage, navigate to the left-hand menu and select UniLink. Then, click Create and choose Schema Migration, as illustrated in the image below.
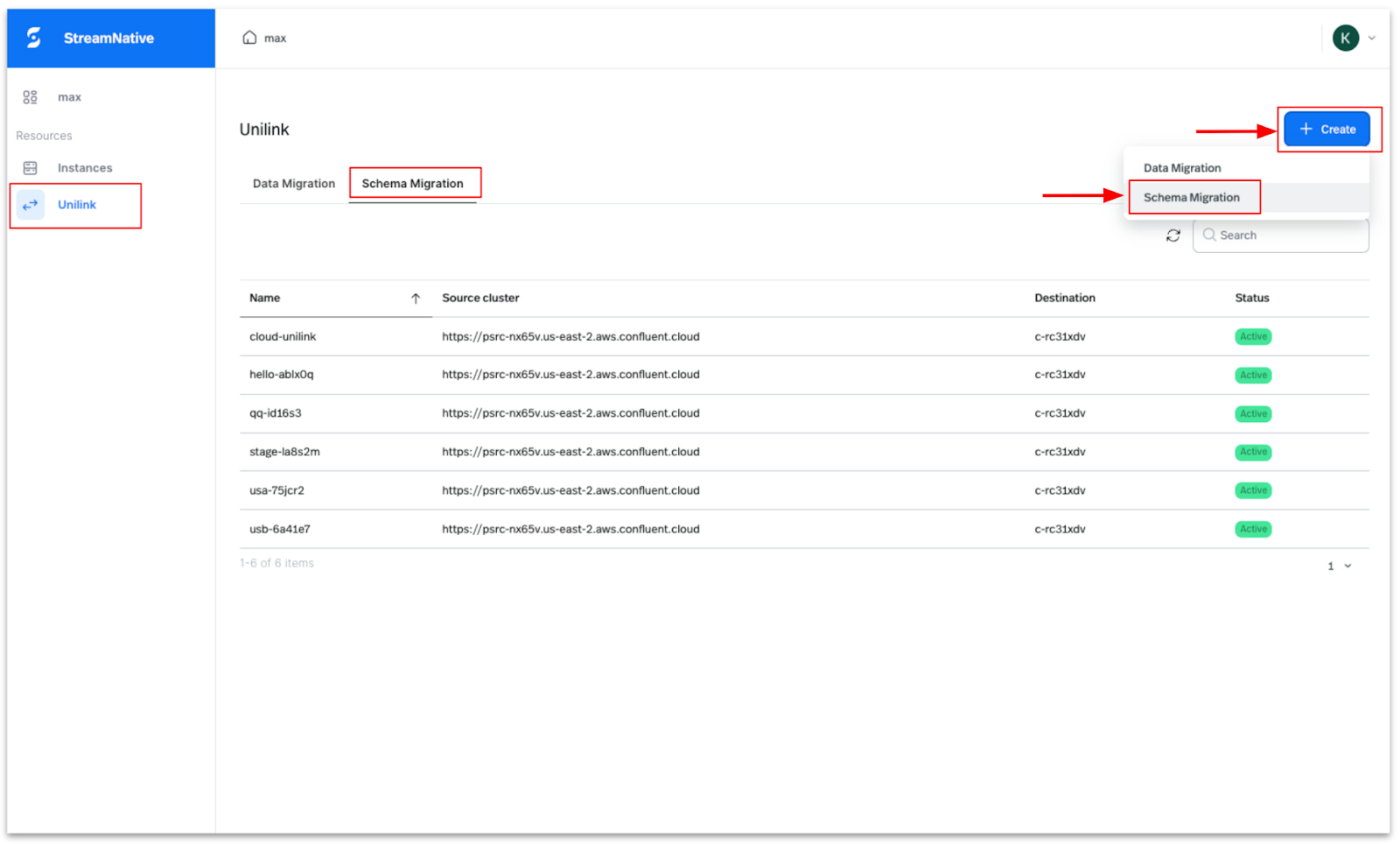
Enter a name for the Schema Migration UniLink, then click on Source and Destination Details.
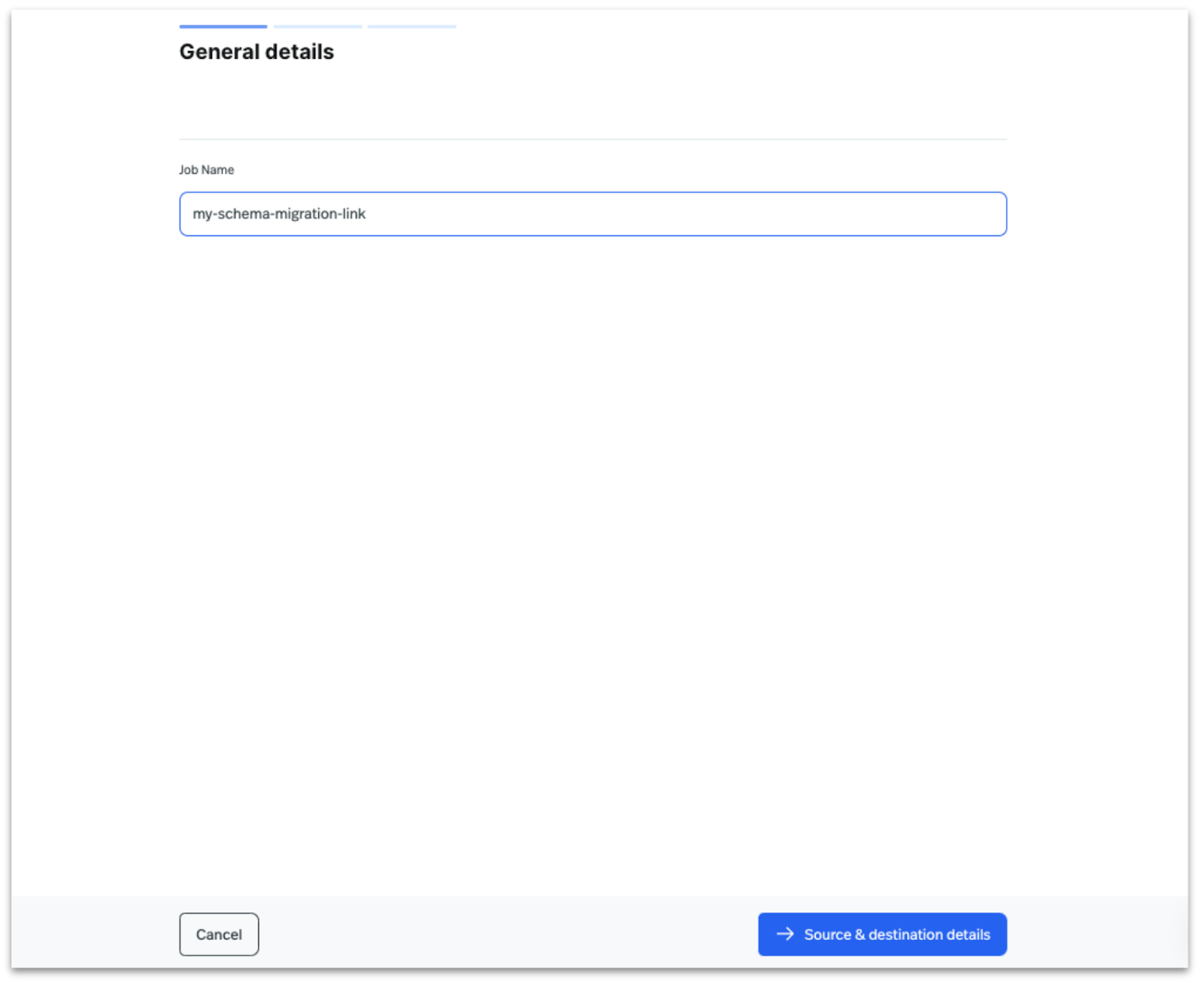
Enter the Source Cluster Broker URL, Destination Instance, and Ursa Cluster in StreamNative Cloud. Then, provide the Secret for source Schema registry cluster for authentication, and click on Subjects Configuration’
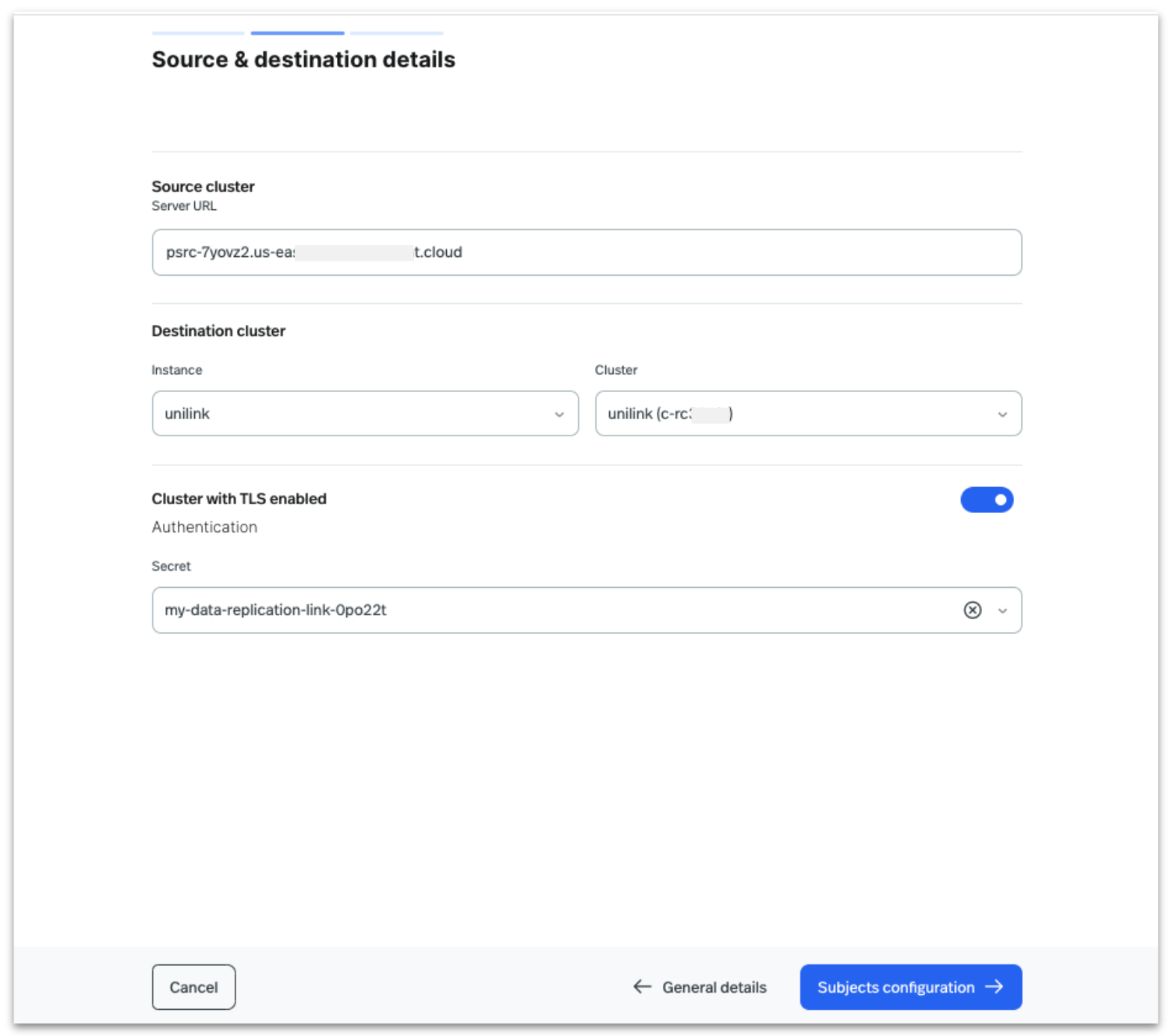
In the next step, configure the subjects to be migrated from the source to the destination cluster. You can either select All Subjects to replicate all schemas and configurations or specify subjects to migrate using a regex expression. In this post, we will select All Subjects Replication, as shown in the image below, and click Deploy.
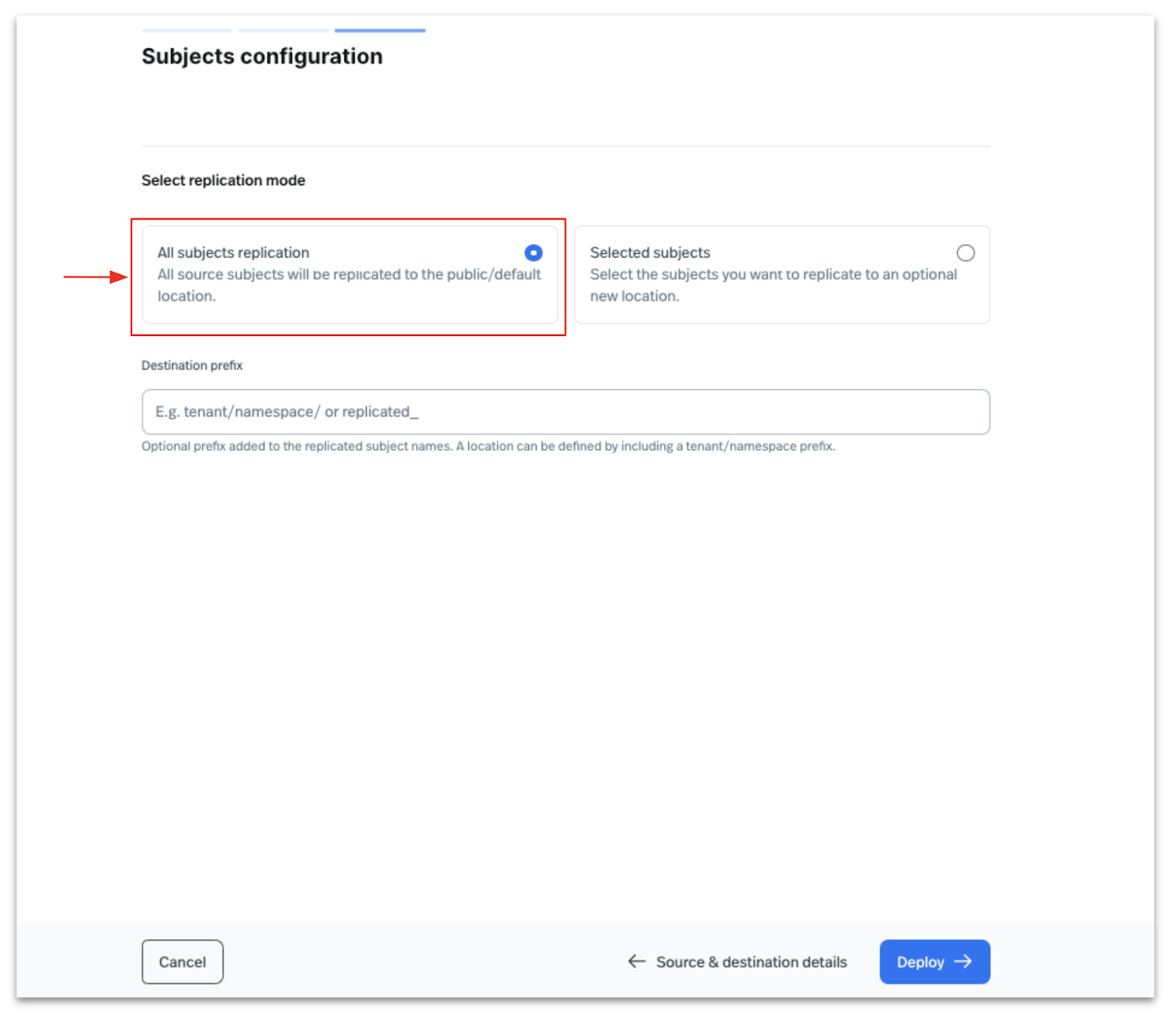
In the next step preview the schemas from source schema registry, and click on Continue.
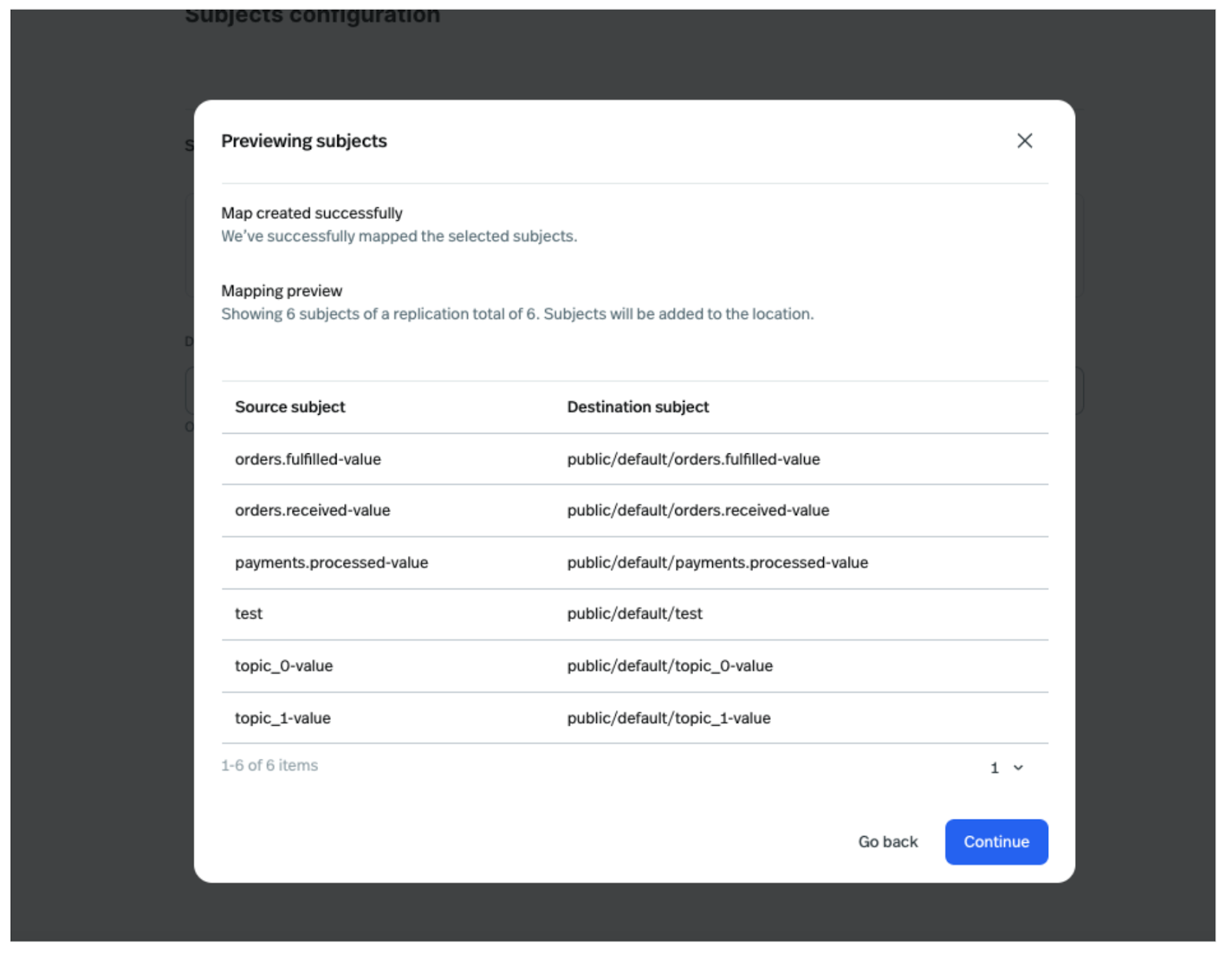
Once the Schema Migration UniLink is deployed you can find it in the list view as highlighted in the picture below.
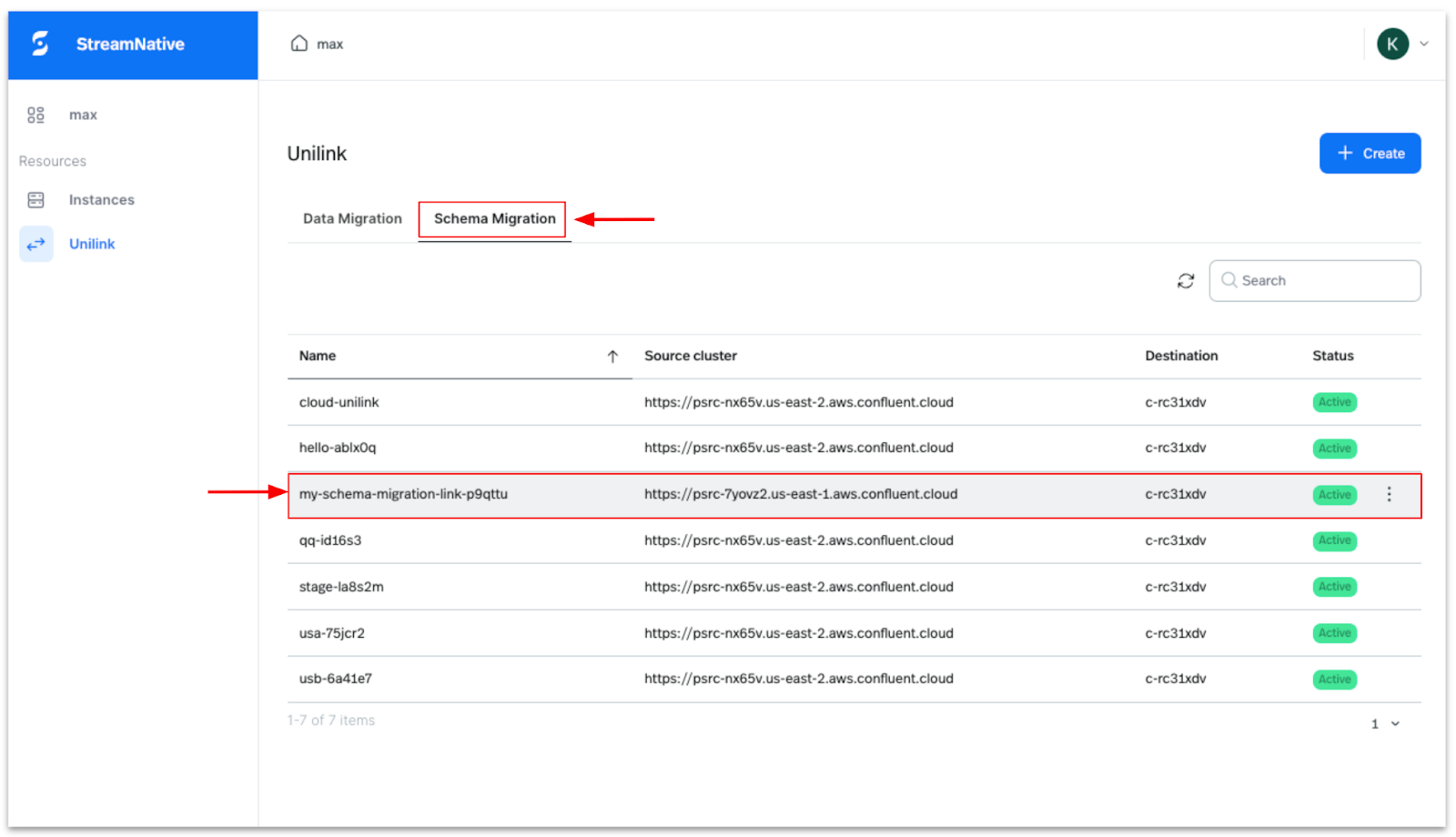
At this stage, both Data Replication and Schema Replication UniLinks are actively running, replicating topic data, schemas, and other configurations. In the next sections, we will review the migrated topics and schemas in StreamNative Cloud and the Amazon S3 Table bucket.
Step 2: Review replicated data and schema in StreamNative Ursa Cluster
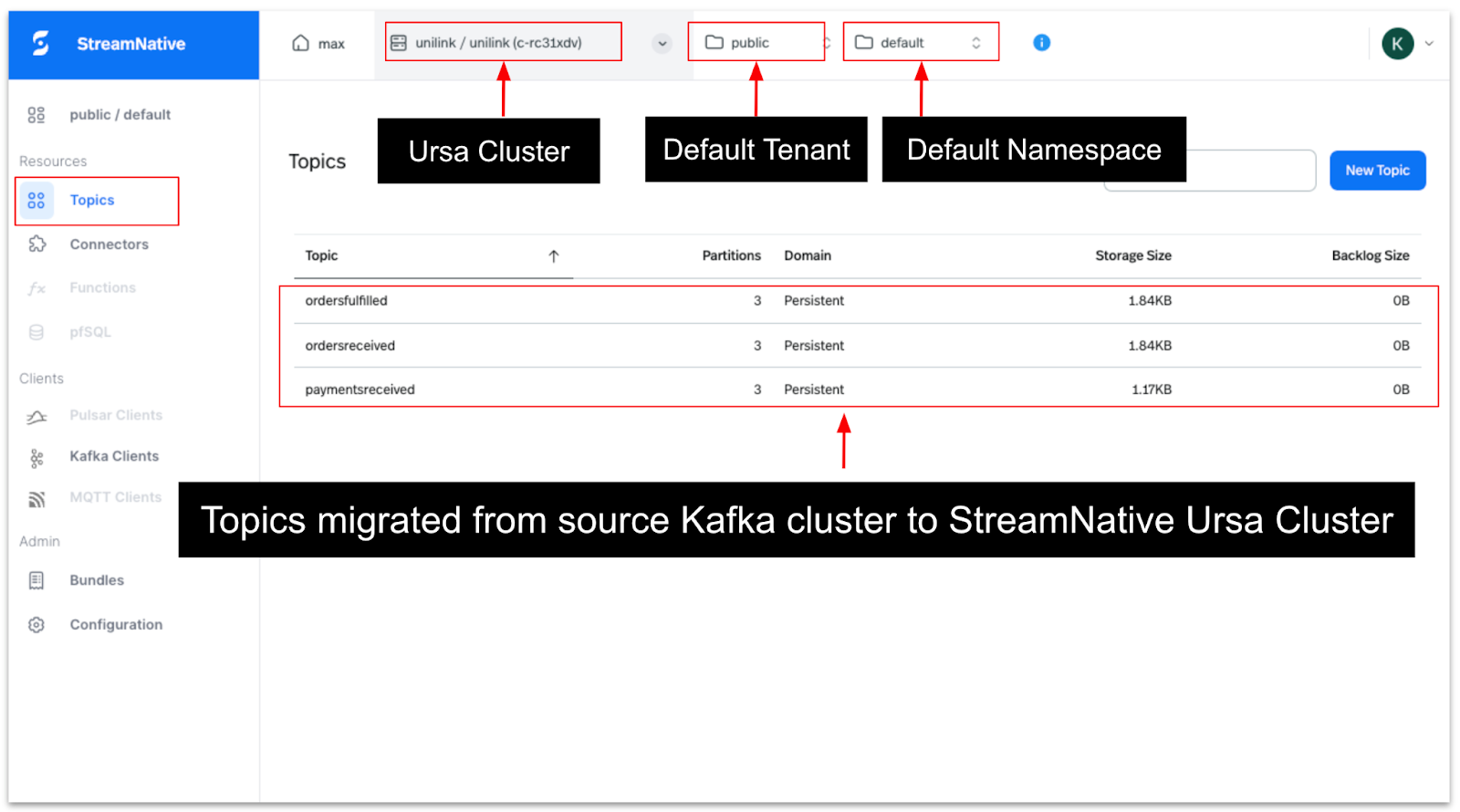
As described in the post above, the topics and data are expected to be replicated into the default tenant (public) and default namespace (default) within StreamNative Cloud.
To verify this, navigate to the StreamNative Cloud homepage, select the Ursa cluster, and choose the default tenant and namespace, and find the migrated topics as shown in the image below.
To verify the replicated schemas, invoke the Kafka Schema Registry REST APIs to view the migrated subjects. Watch this video to learn how to set up and access Kafka Schema Registry With StreamNative Cloud .Watch this video to learn more about Querying Kafka Schema Registry.
To verify the replicated consumer groups, watch this video to use Kafka CLI to Query Consumer Group Backlog.
Step 3: Review and query data published in S3 Tables Bucket
Instead of relying on direct networking over streaming protocols like Pulsar or Kafka, Universal Linking leverages object storage (such as S3) for both networking and storage. This architecture enables cost-effective, robust, flexible, and scalable replication across heterogeneous environments.
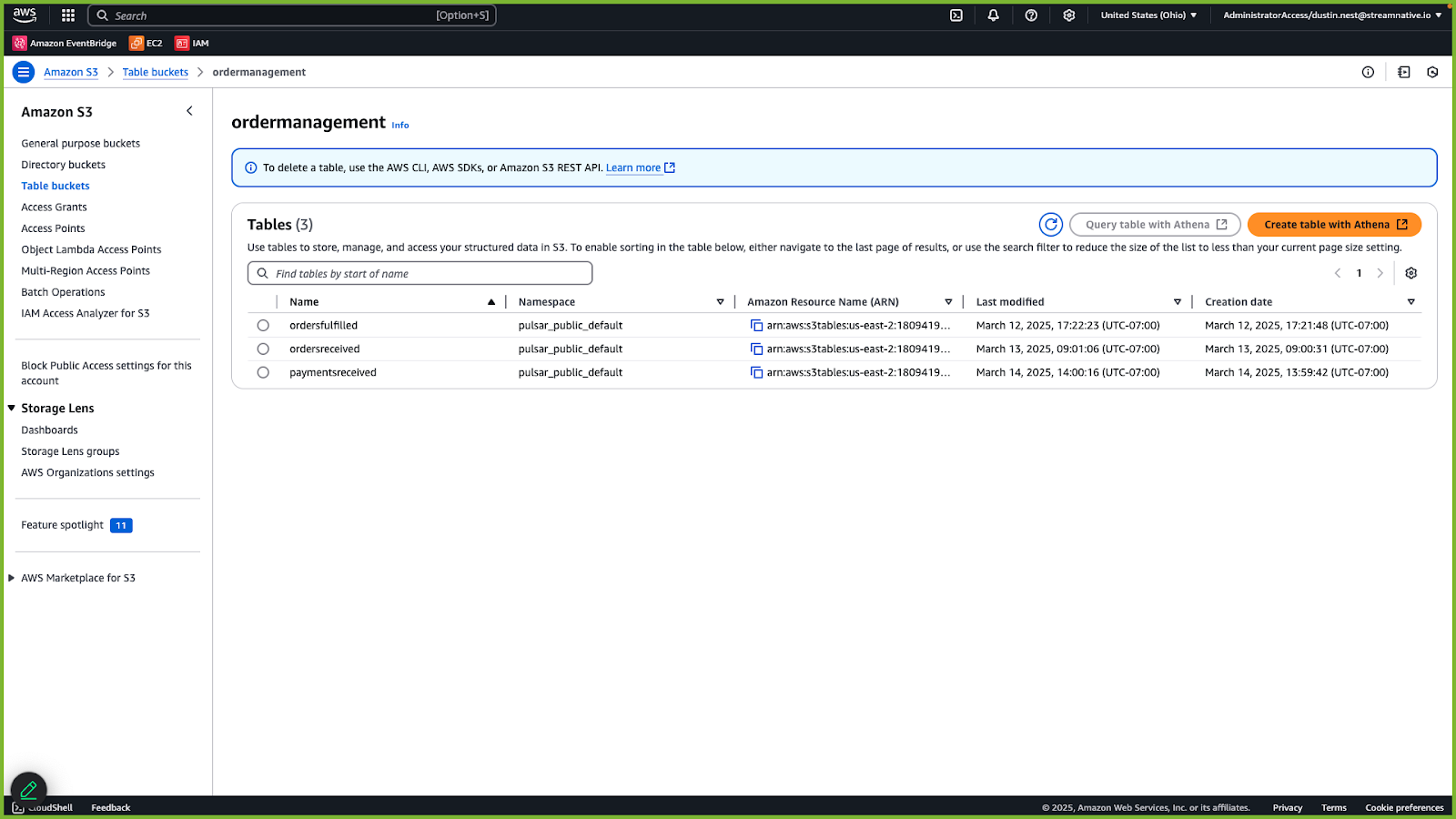
In this guide, as outlined in the Prerequisites section, we configured the destination cluster with S3 Tables Integration, enabling UniLink to replicate data directly to Amazon S3 Tables, which is an object store with built-in Apache Iceberg support and streamline storing tabular data at scale.
The three topics (orders.fulfilled, orders.received, and payments.processed) are created as Apache Iceberg tables in the S3 Table bucket, which is configured in the destination Ursa cluster as shown in the picture below.
To query the Iceberg tables in Amazon Athena, follow steps listed on this doc.
Steps 1 to 3 listed above outline the process of building a Real-Time Data Lakehouse, where UniLink facilitates live data and schema replication in an open lakehouse format, such as Apache Iceberg. This allows Data Science, Data Analytics, and other teams to seamlessly query the replicated data.
The UniLink jobs deployed for a Real-Time Data Lakehouse are long-running and always active, continuously replicating data and schemas. This setup is particularly beneficial for organizations that want to continue using their existing Kafka cluster while leveraging StreamNative Ursa’s capabilities to build a Real-Time Data Lakehouse.
For organizations ready to fully transition from their source cluster, the next step provides best practices for switching producer and consumer applications to connect directly to the StreamNative Ursa cluster.
Step 4: Switch over producers & consumers to StreamNative Ursa Cluster
This is an option step for organizations who no longer want to keep their source Kafka clusters and switch over to StreamNative Ursa clusters. Steps 1 to 3 already replicated topics data, schema and other related configurations. In this section we will look at some of the important steps an organization needs to review before switching over completely to StreamNative Ursa Cluster.
1. Validate Topic and Partition Configurations
- Verify that all topics, partitions, and replication factors match the original cluster.
- Ensure topic-level configurations (e.g., retention policies, cleanup policies, compression settings) are correctly applied.
2. Validate Data Integrity
- Compare data consistency between old and new clusters using: Running consumers on both clusters and comparing outputs.
- Checking for data loss or corruption with checksum verification.
- Do not produce anything in the destination topic until the consumer group has mitigated from source to destination.
3. Performance and Latency Benchmarking
- Measure producer and consumer performance on the new cluster.
- Test end-to-end latency and throughput to ensure the new cluster meets SLAs.
4. Validate Security & Access Controls
- Ensure ACLs, authentication mechanisms (SASL, TLS etc), and RBAC roles match between clusters.
- Verify that all users and service accounts have the correct permissions.
5. Perform a Controlled Traffic Cutover
- Gradually redirect producer and consumer traffic in a phased manner: Blue-Green Deployment: Run some applications on the old and some on the new cluster.
- Canary Testing: Route a small percentage of traffic first before full cutover.
6. Update Client Configurations
- Modify producer and consumer configs: Update bootstrap.servers to point to the new cluster.
- Adjust acks, linger.ms, and batch.size based on new cluster performance.
7. Final Validation & Decommission Old Cluster
- Run end-to-end tests before decommissioning the old cluster.
- Ensure all applications are stable and confirm there’s no data loss or consistency issues.
- Safely shut down the old cluster once all traffic has been migrated.
Conclusion
StreamNative Universal Linking streamlines Kafka migration and real-time data replication, enabling seamless transitions to a modern Data Lakehouse. With full-fidelity replication, reduced operational complexity, and cost-efficient direct-to-lakehouse streaming, it ensures minimal disruption and maximum flexibility.
Now in Public Preview, Universal Linking helps enterprises bridge streaming and analytics, unlocking real-time insights with ease. Start leveraging it today to future-proof your data infrastructure. Get started by signing up for a trial of StreamNative Cloud.


.png&w=1536&q=100)
