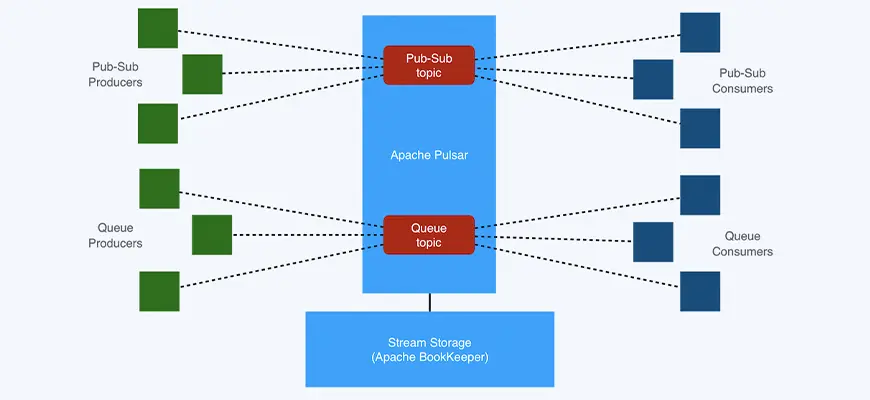
Background
As a part of Tencent Interactive Entertainment Group Global (IEG Global), Proxima Beta is committed to supporting our teams and studios to bring unique, exhilarating games to millions of players around the world. At Proxima Beta, our team is responsible for managing a wide range of risks to our business. As such, we must build an efficient real-time analytics system to consistently monitor all kinds of activities in our business domain.
In this blog, I will talk about our experience of building a real-time analytics system on top of Apache Pulsar and ScyllaDB. Before I share our practices in detail, I will introduce two major architectures for data manipulation, namely CRUD and CQRS. I will also explain our reasons for combining CQRS and Event Sourcing to implement our service architecture, as well as their advantages over CRUD-based systems. Lastly, I will dive deeper into our practices of leveraging distinguishing features of Apache Pulsar for better data governance, such as multitenancy and geo-replication.
A stereotypical CRUD system
CRUD is the acronym for Create, Read, Update and Delete. It is one of the most common data processing methods for microservices development. These four operations are essential for managing persistent data, often used for relational database applications.
This is another definition of CQRS in Amanda Bennett's blog:
The Command and Query Responsibility Segregation (CQRS) pattern separates read and write operations for a data store. Reads and writes may take entirely different paths through the application and may be applied to different data stores. CQRS relies on asynchronous replication to progressively apply writes to the read view, so that changes to the application state instigated by the writer are eventually observed by the reader.
The key idea of CQRS is to explicitly build data models that serve reads and writes respectively instead of doing them against the same data model. This pattern is not very interesting by itself. However, it becomes extremely interesting when working together with Event Sourcing from an architectural point of view.
Event Sourcing: Handling operations on data driven by events
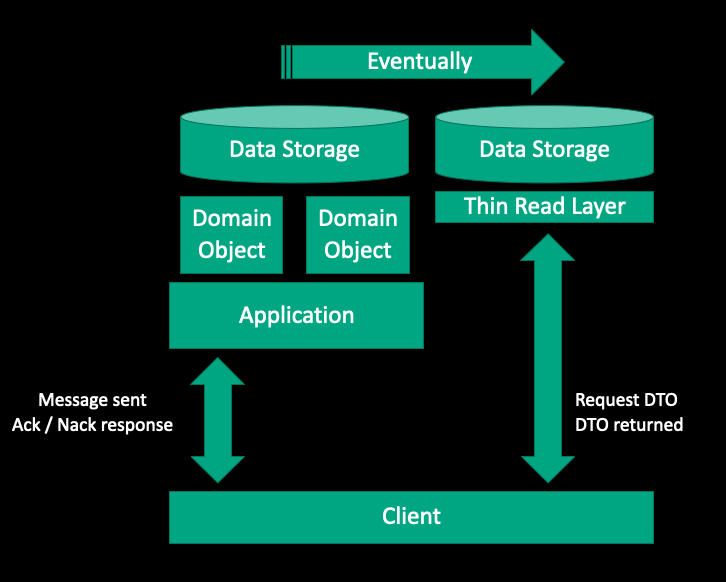
The fundamental idea of Event Sourcing is to ensure every change to the state of an application is captured in an event object. Event objects are stored in the sequence they were applied for the application state itself. For the Event Sourcing pattern, instead of storing just the current state of the data in a domain, you use an append-only store to record the full series of actions taken on that data.
This idea is simple but really powerful because the event store acts as a system of records and can be used to materialize domain objects and views. As events represent every action that has been recorded, any possible model describing the system can be built from the events.
In reality, there are many cases where Event Sourcing is applied. A good example of Event Sourcing is our bank statement as shown in the table below.
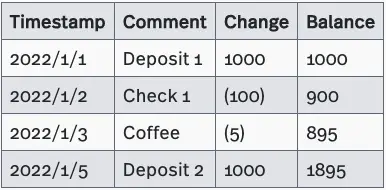
In short, Event Sourcing tracks changes by capturing the sequence of actions instead of overwriting states deconstructively, which is what a CRUD system usually does.
Why CQRS and Event Sourcing
CQRS-based implementations are often used together with the Even Sourcing pattern.
On the one hand, CQRS allows you to use Event Sourcing as a data storage mechanism, which is very important when building a non-trivial CQRS-based system. Although you can maintain relational models for reading and writing respectively, this practice requires high cost, since there is an event model required to synchronize the two. As mentioned above, CQRS fundamentally separates reads and writes into different models. This means with Event Sourcing, you can leverage the event model as the persistence model on the write side.
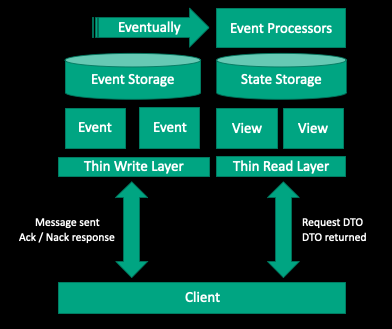
On the other hand, one of the major issues of using Event Sourcing alone is that you cannot perform a query like “Give me all users whose first names are Joe” to a system. This is impossible due to the lack of a representation of the current state. The only valid query to an Event sourcing system alone is GetEventById. The responsibility of maintaining the current state is shifted to event processors. Different processors can generate different views against the same events.
Here, I would like to share a real-world example to further explain why we selected CQRS with Event Sourcing for our service architecture.
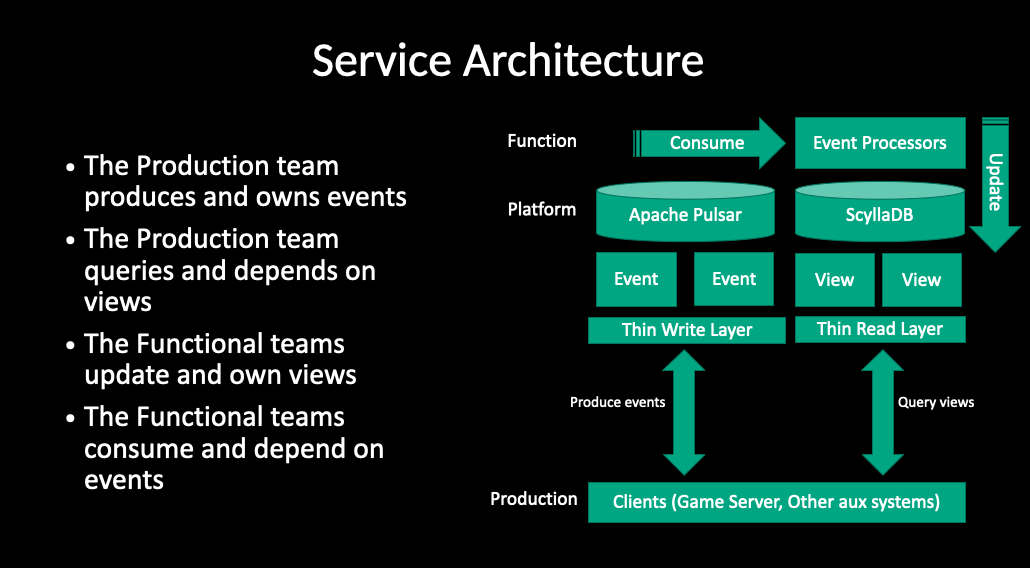
In this architecture, we use Apache Pulsar as the event storage solution because it meets the following needs:
- Multitenancy and workload isolation. This feature is critical to large organizations like us. As multiple teams are working on the same set of data (event streams) in parallel, you must have fine-grained access control and prevent workloads interference with each other.
- Scalability and elasticity. Since all activities will be captured as events and all events will be recorded for a certain amount of time, we need the ability to scale our cluster according to the volume of incoming traffic.
- Geo-replication. Running a business across the globe is a challenging task, as we need to take different factors into consideration, such as policy compliance and network latency.
I will explain how Pulsar has helped us in these aspects in more detail in the next section.
On the read side of the system, any SQL/NoSQL solutions that fit your query workload could be a good candidate. It is also possible to have more than one state store and optimize each of them for a certain kind of query. In our use case, since we are dealing with hundreds of thousands of game-playing sessions in parallel, we finally landed our solution on ScyllaDB as the state storage (An alternative implementation of Apache Cassandra, inspired by Amazon DynamoDB).
A multi-cluster solution built on Apache Pulsar
There are different reasons for building a multi-cluster system as shown below:
- Achieve the Recovery Time Objectives (RTOs) and the Recovery Point Objectives (RPOs) of your organization
- Lower network latency for better user experience
- Comply with rules and regulations
In our case, low network latency and regulation compliance are top priorities. We are trying our best to make sure data is processed and saved in the right region. Let me quickly walk you through some typical approaches to deploying a multi-cluster system.
Independent clusters in different regions
This approach runs multiple independent instances in different regions with no intercommunication. In some cases, eliminating cross-region connectivity is necessary. For example, you may need to deploy a dedicated cluster in a customer's private data center. The downside is that the maintenance cost will surge as you have more clusters. However, it does give you a high level of confidence in compliance, since there is no way you can accidentally process or save data in the wrong location.
Application-level federation
This solution pushes the complexity to the application layer. The application server coordinates with other peers to make sure data is saved to the right location. If your organization only runs one application and doesn't have a heterogeneous infrastructure, this approach probably makes more sense. This is because no matter how complex the implementation is, you only have to do it once.
In reality, however, a large organization may have hundreds of applications. We think it is not reasonable to ask every application developer to deal with a multi-cluster deployment. To make our developers less worried about complicated compliance issues, we took another approach, also known as the Global Data Ring.
Global Data Ring
This solution is a combination of policies and technologies. Every application only has access to local endpoints. Every cluster contains a Pulsar instance and a ScyllaDB instance. There is no interconnectivity between applications. This ensures that no application can accidentally access a region that it should not touch. Our Platform team can enforce this implementation without involving individual application developers.
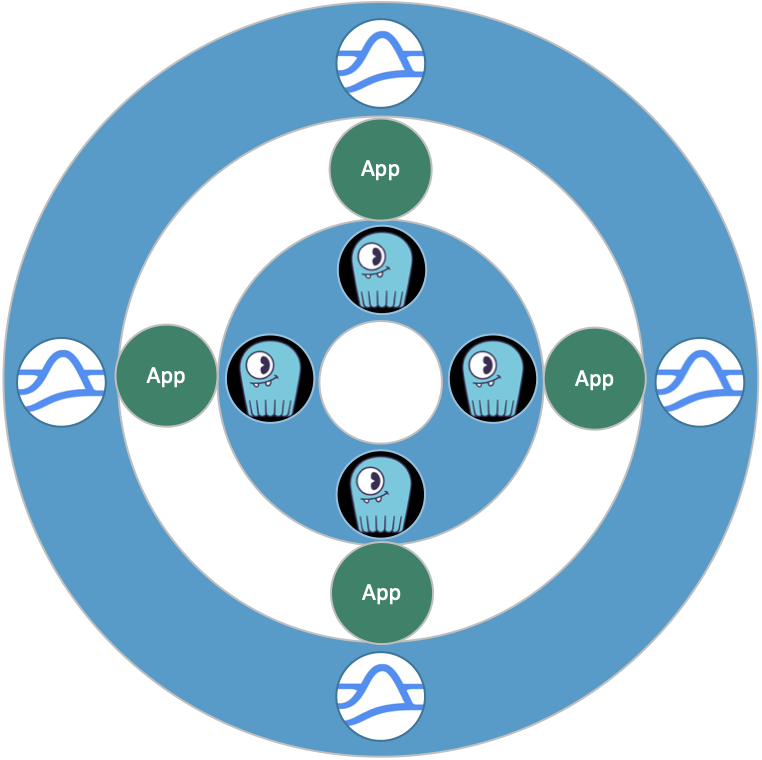
Figure 7
In this architecture, we are using Pulsar namespaces as geofencing data containers. Currently, we have three types of namespaces:
- Global. Geo-replication is enabled for the global namespace among all clusters. Applications running in different regions can share the same view of the namespace. Any data written to the global namespace is automatically replicated to the rest of the regions.
- Regional. Geo-replication is not enabled for the regional namespace (or local namespace). The data will be stored in the same region as the writer.
- Cross-region. Geo-replication is enabled for the cross-region namespace only with selected clusters. The reason is that in accordance with some local rules and regulations, we can copy the data out of a country in some cases, as long as the original copy stays within the border. This gives us great flexibility to move our workload to nearby regions, helping optimize our overall cost.
In this practice, the compliance policy can be represented by the system configuration of Pulsar and ScyllaDB, which is under the entire control of the Platform team. Those structured configurations are much easier for auditing and visualization, which eventually help us build better governance within our organization.
What’s next for your organization
In this blog, I explained CRUD and CQRS, and why we should combine CQRS and Event Sourcing together. I hope our experience of implementing CQRS and Event Sourcing on top of Pulsar and ScyllaDB can be helpful to those who want to build similar architectures. And here are my suggestions for you in terms of short- and long-term planning.
- Start by trying to build materialized views for queries.
- Figure out what domain events your system can produce with your client.
- Implement your data model based on the domain events of your client and try to establish a global data ring with your organization.
Reference
Introduction to CQRS | Amanda Bennett
CQRS pattern - Azure Architecture Center | Microsoft Learn
Event Sourcing pattern - Azure Architecture Center | Microsoft Learn
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community driving innovation and improvements to the project. Check out the following resources to learn more about Pulsar.
- Start your on-demand Pulsar training today with StreamNative Academy.
- Spin up a Pulsar cluster in minutes with StreamNative Cloud. StreamNative Cloud provides a simple, fast, and cost-effective way to run Pulsar in the public cloud.
- Rregister now for free for Pulsar Summit Asia 2022! Held on November 19th and 20th, this two-day virtual event will feature 36 sessions by developers, engineers, architects, and technologists from ByteDance, Huawei, Tencent, Nippon Telegraph and Telephone Corporation (NTT) Software Innovation Center, Yum China, Netease, vivo, WeChat, Nutanix, StreamNative, and many more.