
At the Pulsar Virtual Summit EMEA 2024, StreamNative unveiled the Ursa Engine—a transformative advancement in data streaming architecture. The launch received overwhelmingly positive feedback from customers and prospects alike. Recently, StreamNative announced the public preview of the Ursa Engine for its StreamNative AWS BYOC clusters, marking a significant milestone in its development.
With the public preview, users gain access to core Ursa Engine features, including Oxia-based metadata management and S3-backed Write-Ahead Logs (WAL). These features provide enhanced flexibility, scalability, and cost-efficiency, making it easier than ever to manage and analyze streaming data.
PuppyGraph is proud to be the first graph compute engine to integrate with StreamNative's Ursa Engine. This partnership marks a shift toward democratizing access to streaming data and graph analytics—delivering cost-effective solutions without requiring a dedicated graph database. Combined with Ursa Engine, PuppyGraph enables users to query streaming data using graph query languages like Gremlin and openCypher, along with built-in visualization tools, providing a seamless experience for graph-based analytics.
In this blog, we will introduce StreamNative's Ursa Engine and explore how combining its capabilities with PuppyGraph’s zero-ETL graph query engine unlocks the potential of real-time graph analytics. First, let’s dive deeper into the features and benefits of StreamNative's Ursa Engine.
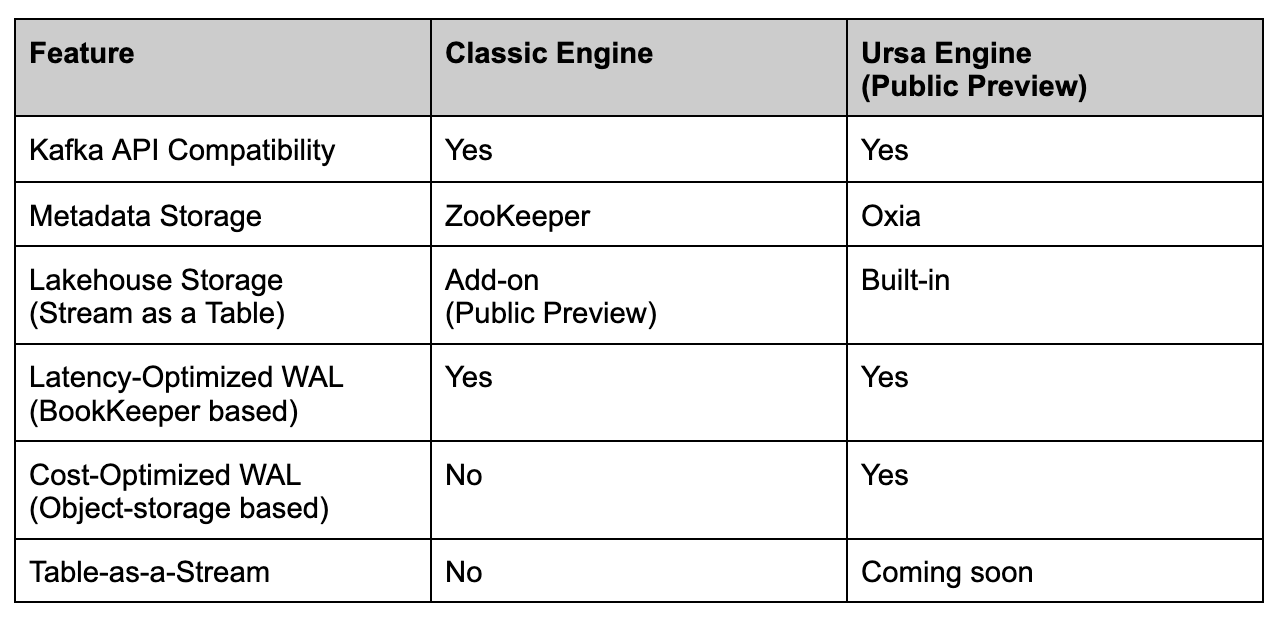
What is StreamNative's Ursa Engine
StreamNative's Ursa Engine represents a next-generation data streaming engine that builds upon and extends Apache Pulsar's capabilities. At its foundation, Ursa Engine leverages two key components: Oxia for metadata storage and Object Storage (S3, GCS, Azure Blob Storage) for data persistence. This architectural decision makes the traditional BookKeeper storage optional, reserving it exclusively for scenarios demanding ultra-low latency.
Key Features and Capabilities
The engine stands on several essential pillars that make it particularly powerful:
- Complete Kafka API Compatibility: Organizations can seamlessly migrate their existing Kafka-based applications to Pulsar, as Ursa Engine provides full compatibility with the Kafka API.
- Lakehouse Storage Integration: The engine incorporates lakehouse storage principles, ensuring long-term durability and adherence to open standards.
- Advanced Metadata Management: By utilizing Oxia, Ursa Engine achieves highly scalable and durable metadata storage.
- Flexible Storage Options: Users can choose between two storage tiers based on their specific needs:some textLatency-Optimized Storage: Powered by Apache BookKeeper, this option caters to high-throughput, latency-sensitive workloads requiring immediate message delivery.
- Cost-Optimized Storage: Built on Object Storage services, this tier offers a more economical solution for workloads that can accommodate sub-second latencies.
Lakehouse Storage
Ursa streamlines the integration of streaming data into lakehouse environments. It allows users to store their Pulsar and Kafka topics, along with associated schemas, directly into lakehouse tables. Ursa's objective is to simplify feeding streaming data into lakehouses, making data instantly available for analytics and other use cases.
Building on Apache Pulsar’s pioneering tiered storage model, which offloads sealed log segments to commodity object stores like S3, GCS, and Azure Blob Store, Lakehouse Storage takes a leap forward by enabling data to be stored directly in lakehouse-ready formats. Traditionally, Pulsar relies on Apache BookKeeper to persist data in a write-ahead log, which consolidates entries across topics using a distributed index for fast lookups. Afterward, the data is compacted into Pulsar’s proprietary format for efficient scans and storage. Lakehouse Storage enhances this process by compacting data directly into open standard formats such as Apache Iceberg, and Delta Lake. This shift eliminates the need for complex integrations between streaming platforms and lakehouses, making data immediately accessible for lakehouse analytics.
The Ursa engine leverages the schema registry during compaction, automating schema mapping, evolution, and type conversion. This ensures schema enforcement as part of the data stream contract, catching incompatible data early and maintaining high data quality. Additionally, Ursa continuously compacts small Parquet files into larger ones, optimizing read performance for analytics and query workloads.
By seamlessly integrating with lakehouse solutions like Databricks and OneHouse, Lakehouse Storage further simplifies data workflows and enhances performance. This innovative approach removes the barriers between streaming and lakehouse ecosystems, offering a unified, high-performance solution for real-time and batch data analytics. With Lakehouse Storage, Ursa sets a new standard for efficient, schema-aware, and lakehouse-compatible data streaming.
Ursa Engine + PuppyGraph Architecture
Ursa Engine specializes in Lakehouse Storage capabilities, efficiently compacting data into open standard formats like Apache Iceberg, and Delta Lake. This efficient data storage foundation is enhanced by PuppyGraph, a graph query engine that works directly with existing data, eliminating the need for time-consuming ETL processes to a separate graph database. PuppyGraph connects to various data sources to build comprehensive graph models, leveraging these same standard formats. Combining these technologies results in a high-performance, cost-optimized solution for real-time graph analysis.
The solution delivers exceptional performance in graph querying through scalable and performant zero-ETL. PuppyGraph achieves this by leveraging the column-based data file format coupled with massively parallel processing and vectorized evaluation technology built into its engine. This distributed compute engine design ensures fast query execution even without efficient indexing and caching, delivering a performant and efficient graph querying and analytics experience without the hassles of the traditional graph infrastructure.
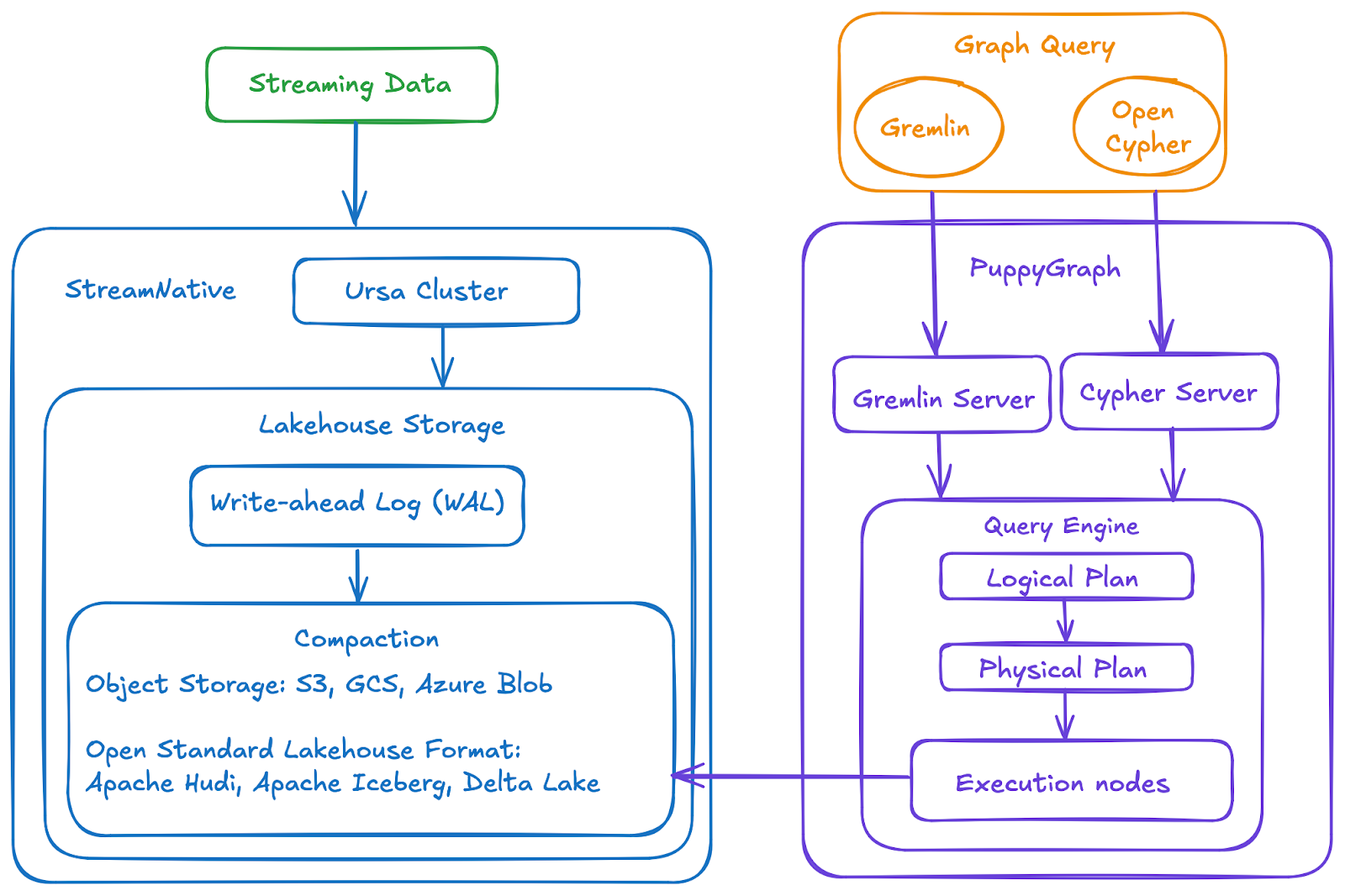
Integrate Ursa Engine with PuppyGraph
Integrating Ursa Engine with PuppyGraph is a straightforward process that involves four key steps:
- Deploy Ursa Engine: Set up and deploy the Ursa Engine.
- Deploy PuppyGraph: Set up and deploy PuppyGraph.
- Connect to Compacted Data: Establish a connection between PuppyGraph and the compacted data in Lakehouse storage generated by Ursa Engine.
- Query Your Data as a Graph: Query data with Gremlin and openCypher in PuppyGraph. Visualize results with the graph visualization tool.
Both Lakehouse storage and PuppyGraph integrate seamlessly with lakehouse solutions like Databricks. For more information, see the following document and blogs:
PuppyGraph Connecting Document(delta lake)
We also have a detailed demo to help you get started. Try it out and contact us if you have any questions!
Deploy Ursa Engine
For a quick start guide to the Ursa-Engine BYOC Cluster, refer to the quickstart document of Ursa Engine. The prerequisites in that document involve Java and Maven, but you can choose from many available Kafka clients.
To deploy your Ursa-Engine BYOC cluster, you need the following prerequisites:
- Access to StreamNative Cloud
- Internet connectivity
- Access to your AWS account for provisioning the BYOC infrastructure
Deployment involves the following steps:
- Sign up for StreamNative Cloud.
- Grant StreamNative vendor access. Before deploying a StreamNative cluster within your cloud account, you must grant StreamNative vendor access.
- Create a cloud connection. This establishes a connection to your AWS account.
- Create a cloud environment. After creating a cloud connection, you can create a cloud environment and provision a BYOC instance.
- Create a StreamNative instance and cluster. Your cluster will be deployed in AWS.
- Create a service account. To interact with your cluster (by producing and consuming messages), you need to set up authentication and authorization. A service account serves as an identity for this purpose. It provides the necessary credentials for your applications to securely connect and operate on the Pulsar cluster.
- Create a tenant and namespace, and authorize the service account. After creating the service account and obtaining the API key, authorize it to grant the necessary permissions to interact with your StreamNative Cloud cluster.
- Grant permission to access the Kafka Schema Registry. You need to grant the service account access to the Kafka Schema Registry.
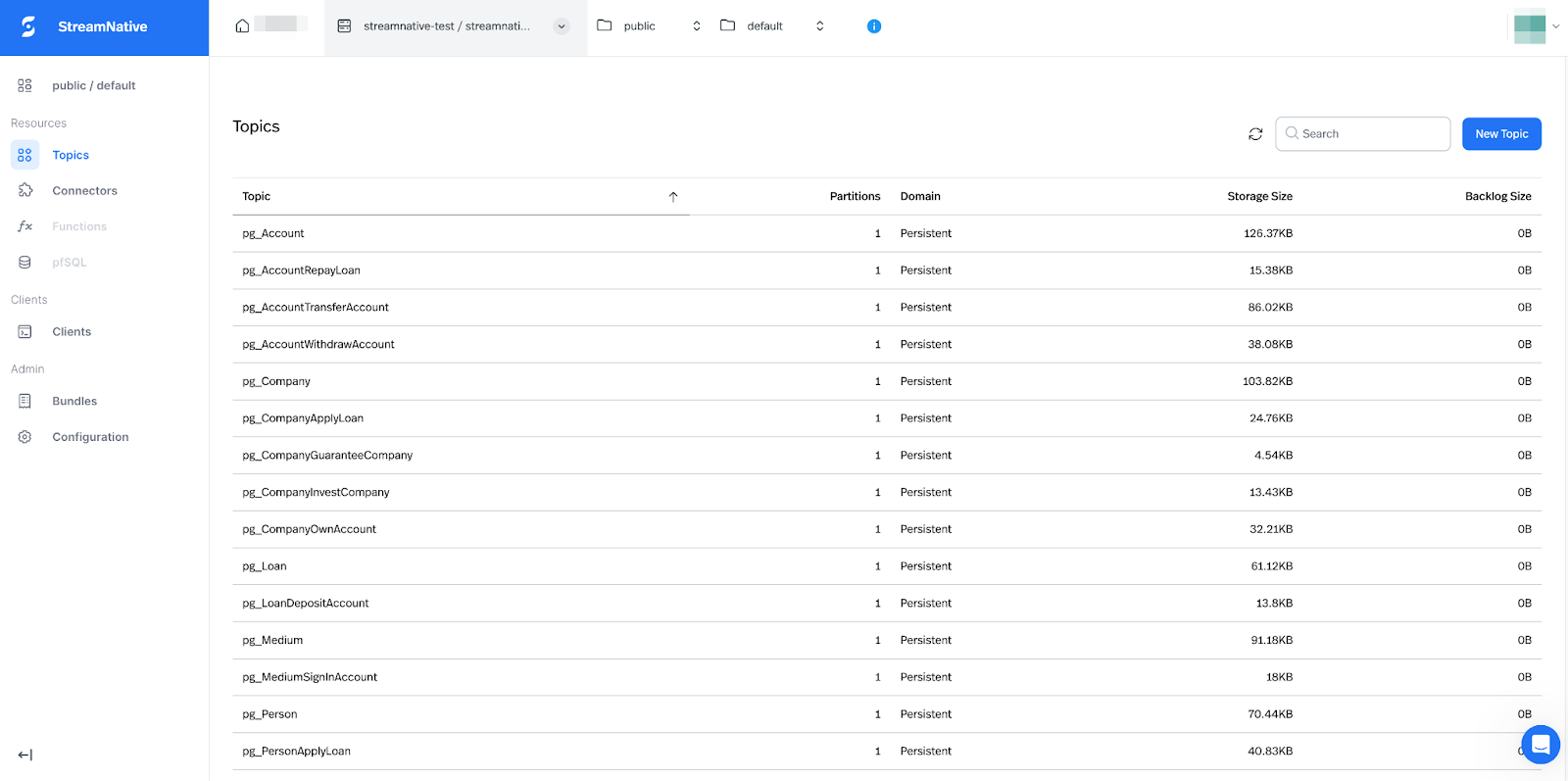
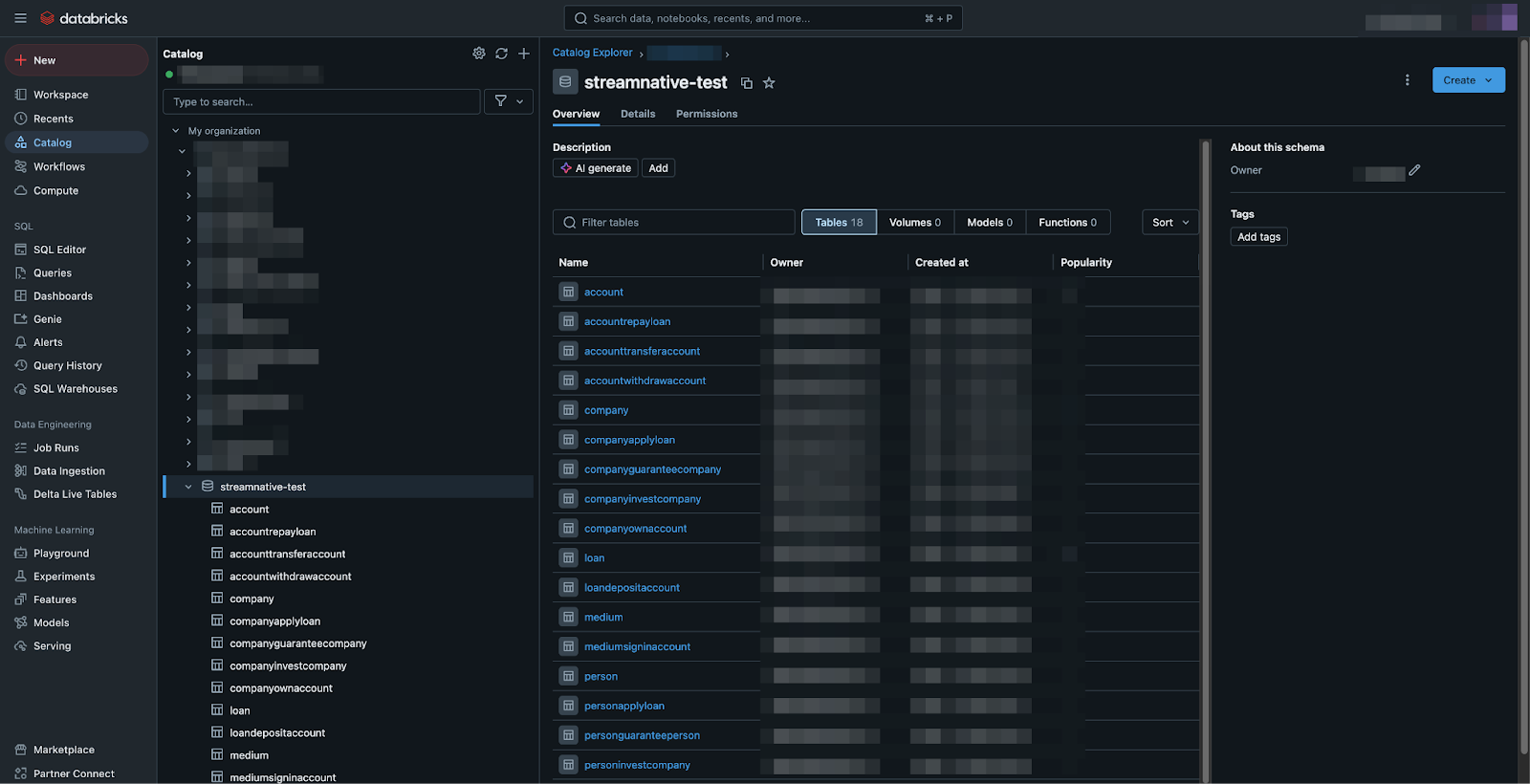
Now you can produce data to your topics via Kafka clients. Depending on the compaction configuration, after some time, you will see the compaction in your S3 storage according to your cloud environment. Compaction uses the Delta Lake format by default. You can read and manipulate your compaction data with Databricks. In the Databricks console, you can add a catalog for your data and then use the SQL Editor to create tables from the compacted data.
Deploy PuppyGraph
It is easy to deploy PuppyGraph, and can currently be done through Docker, an AWS AMI through AWS Marketplace, or GCP Marketplace. The AMI approach deploys your instance on your chosen infrastructure with just a few clicks. Below, we will focus on what it takes to launch a PuppyGraph instance on Docker.
With Docker installed, you can run the following command to launch the container in your terminal. Note that the environment variable DATAACCESS_DATA_CACHE_STRATEGY is set as adaptive.
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -e DATAACCESS_DATA_CACHE_STRATEGY=adaptive -d --name puppy --rm --pull=always puppygraph/puppygraph:stable
Launch a PuppyGraph instance locally, in the cloud, or on a server with the command above. Then, open your browser and navigate to localhost:8081 (or your instance's URL) to access the PuppyGraph login screen.
After logging in with the default credentials (username: “puppygraph” and default password: “puppygraph123”) you’ll enter the application itself. At this point, our instance is ready to go and we can proceed with connecting to the compacted data.
Connect to the Compacted Data
To connect PuppyGraph to the compacted data, you need to define the graph schema. You can add the vertices and edges manually through the interface, or compose the JSON schema file and upload it. You need to configure the data source and specify the vertices and edges. In the demo, we provide a JSON schema file template for you and you just need to fill the configuration of the data source there. You can refer to the connecting document for the details of those fields.
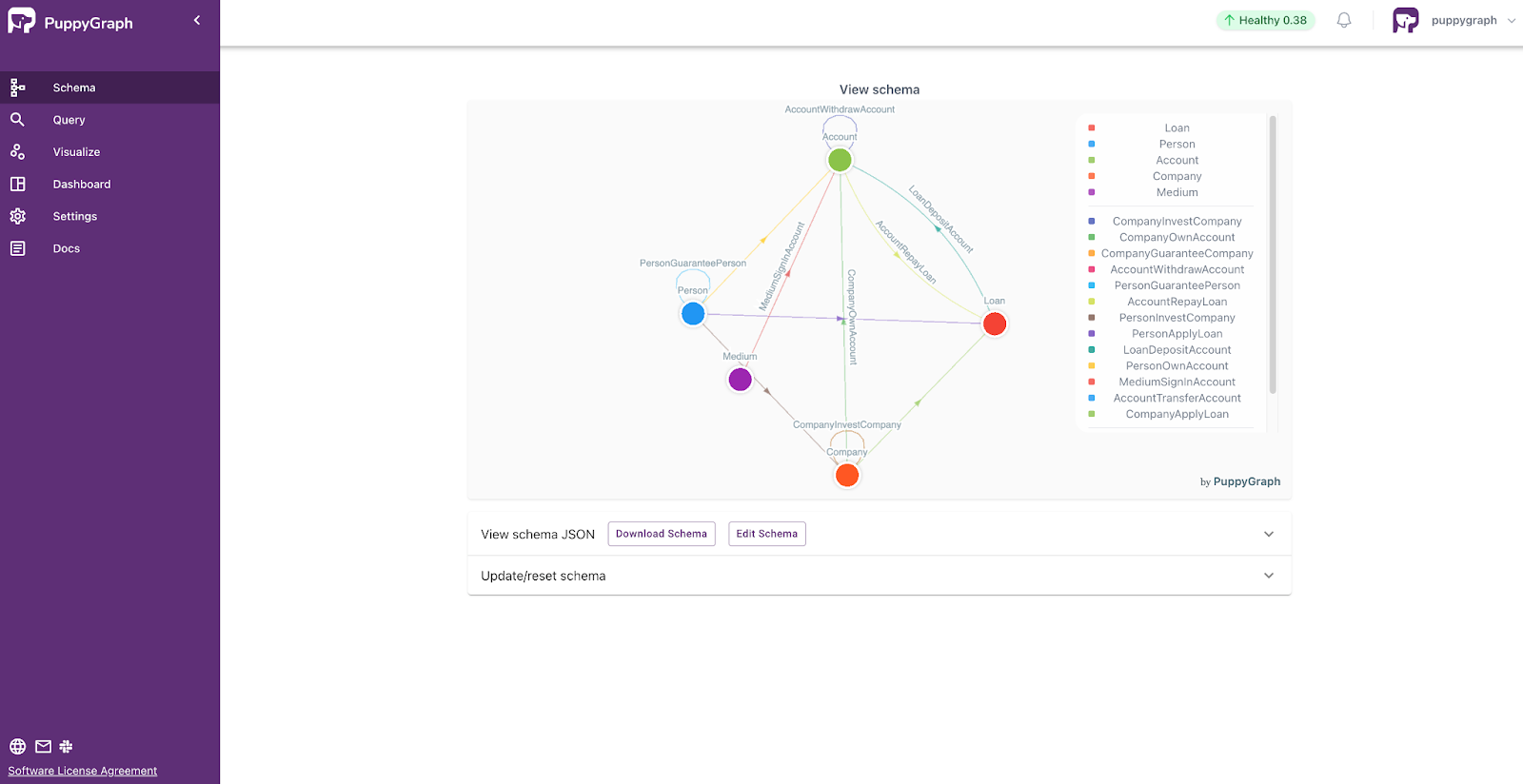
After submitting the schema, you will see the schema graph.
Query Your Graph via PuppyGraph
Now you can query the graph using Gremlin or openCypher and visualize the results with the built-in graph visualization tool.
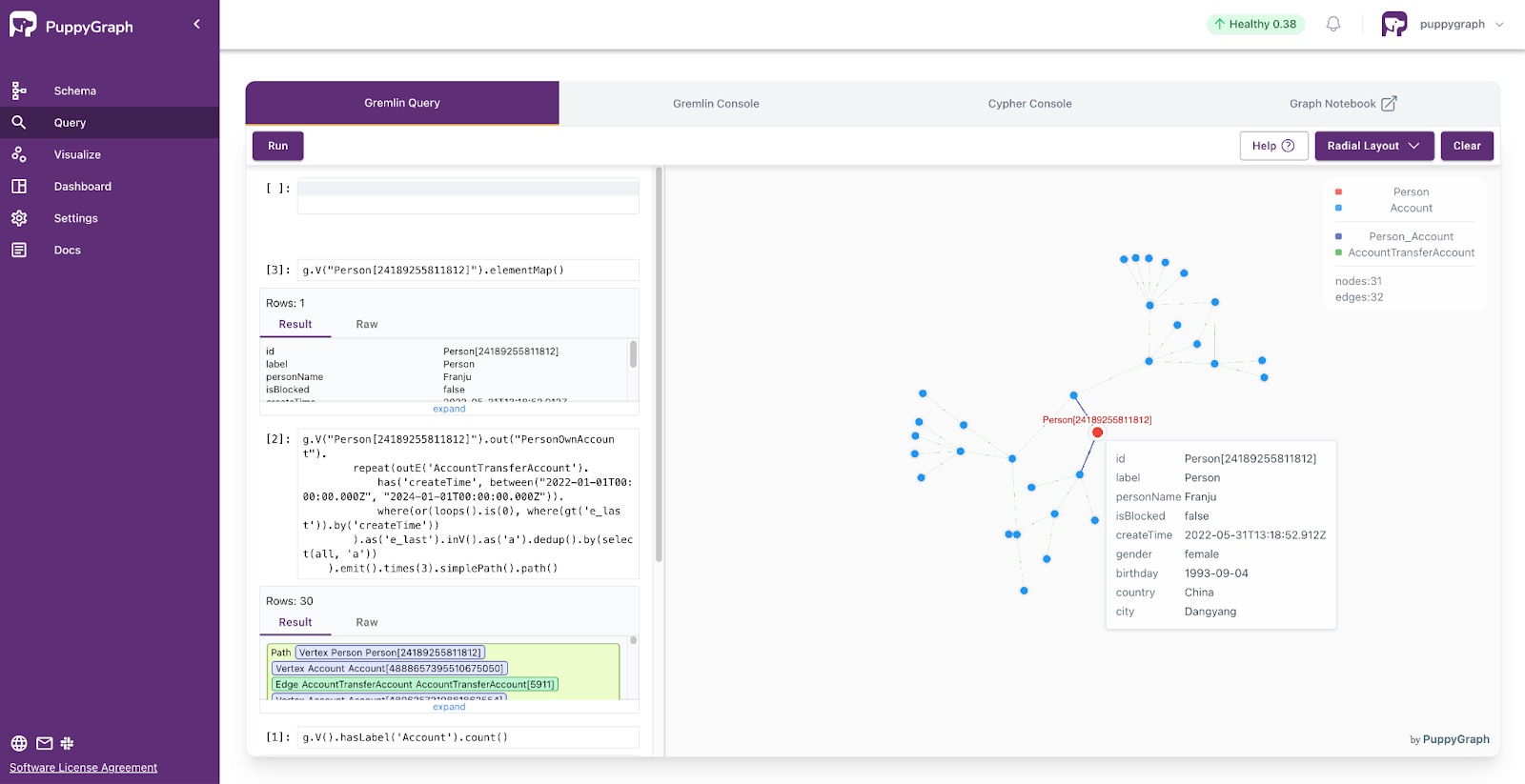
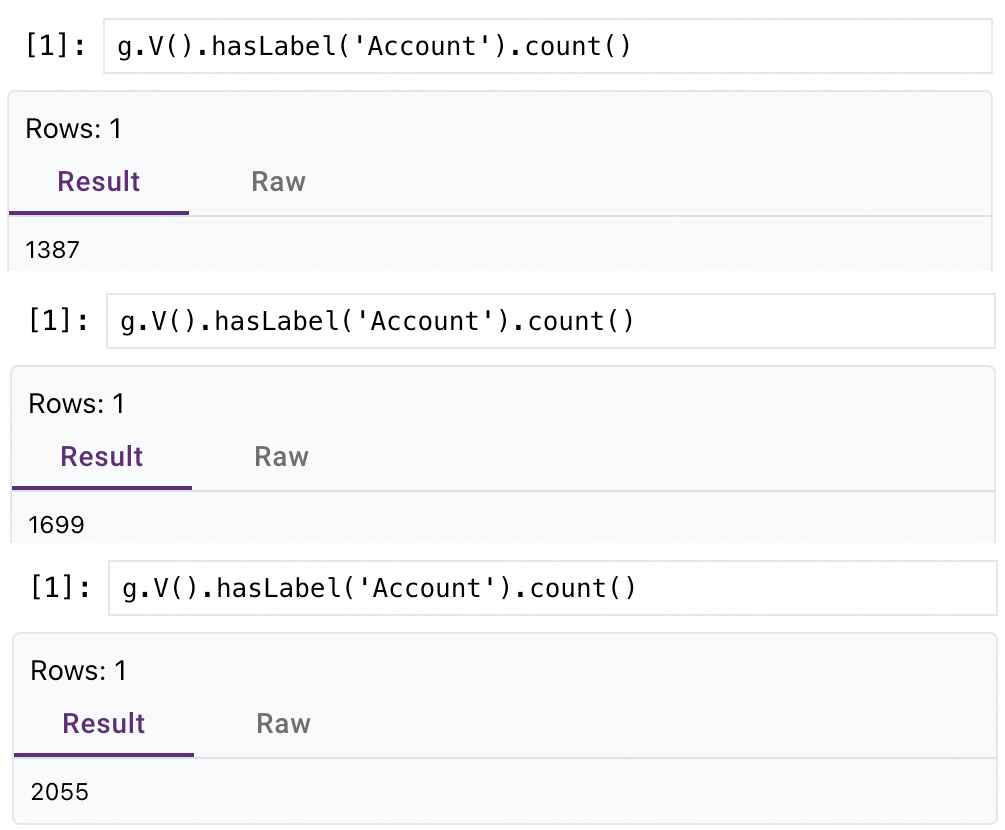
As new data is produced and added to the Ursa Cluster, your query results in PuppyGraph will update regularly.
Conclusion
In this blog, we delved into integrating StreamNative's Ursa Engine Lakehouse Storage with PuppyGraph's zero-ETL graph query engine to achieve real-time graph analysis. This seamless process simplifies workflows and delivers high-speed graph queries, eliminating the complexities associated with traditional graph technologies.
Ready to take control and build a future-proof, graph-enabled real-time system? Try PuppyGraph and StreamNative today. Visit PuppyGraph (forever free developer edition) and StreamNative to get started!





