
At the Pulsar Virtual Summit EMEA 2024, we introduced the Ursa Engine—a groundbreaking leap forward in data streaming architecture. The feedback has been overwhelmingly positive from both customers and prospects. Today, we are excited to announce the Ursa Engine Public Preview for StreamNative AWS BYOC clusters, unlocking new possibilities with No Keepers architecture (Phase 3 of Ursa), leveraging Oxia for scalable metadata storage and S3 for Write-Ahead Log storage. With this release, Phase 3 of the Ursa rollout enters Public Preview, advancing the engine into the next stage—providing users with greater flexibility, scalability, and cost-efficiency.
In this blog post, we’ll explore what the Ursa Engine offers, how it differs from the Classic Engine based on open-source Pulsar, and what the Public Preview unlocks for BYOC customers.
What is the Ursa Engine?
The Ursa Engine is a next-generation data streaming engine, designed to address the need for cost-effective, future-proof streaming platforms. Building upon Pulsar’s cloud-native architecture, it introduces innovations to reduce costs while maintaining flexibility.
Key pillars of the Ursa Engine include:
- Fully Kafka API-compatible
- Lakehouse storage for long-term durability and open standards
- Oxia as a scalable metadata store
- Support for both BookKeeper-based and S3-based WAL (Write-Ahead Log)
The engine supports two WAL implementations:
- Latency-Optimized WAL (BookKeeper-based) for transactional, low-latency workloads
- Cost-Optimized WAL (Object storage-based) for workloads with relaxed latency requirements
How is the Ursa Engine Different from the Classic Engine?
Ursa targets cost-sensitive, latency-relaxed workloads. Ursa shifts from the ZooKeeper-based Classic Engine toward a headless stream storage architecture, using Oxia as a metadata store, making BookKeeper optional and relying on S3 object storage for durability. Below is a feature comparison between the Classic and Ursa Engines:
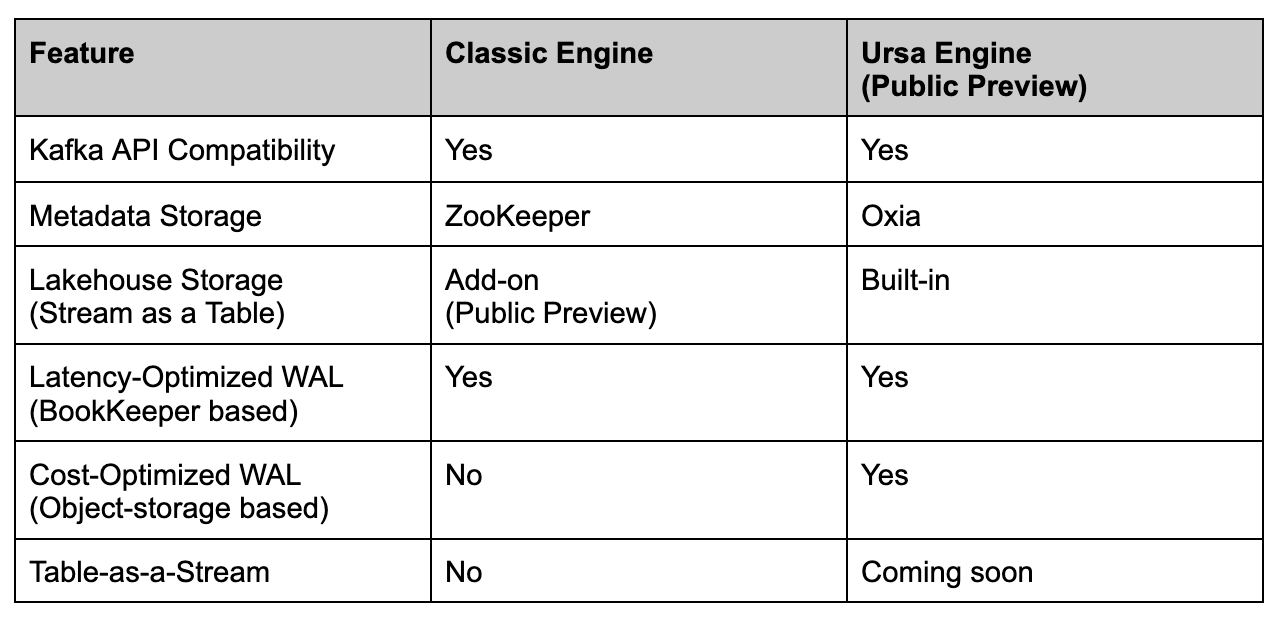
The Kafka API compatibility and Lakehouse Storage are available as add-ons for Classic Engine users. However, Oxia and S3-based WAL are integral to the Ursa Engine and cannot be retrofitted onto existing clusters.
What is included in the Public Preview?
With the Public Preview, users can access core Ursa Engine Features such as Oxia-based metadata management and S3-based WAL,.
In order to to focus on gathering feedback and optimizing the experience for broader production use, we are limiting the feature set of this Public Preview::
- Only Kafka protocol is enabled during Public Preview
- Transactions and topic compaction are not yet supported.
- Only S3-based WAL is available, making it ideal for latency-relaxed use cases.
- For ultra-low-latency applications, we recommend continuing with the Classic Engine until the Ursa Engine reaches full GA.
Shaping Ursa’s Stream Storage
As part of the Public Preview for the Ursa Engine, we are defining its storage architecture with Oxia as the metadata store, S3 as a primary storage option, and Lakehouse table formats as the open standard for long-term storage. Together, we refer to this architecture as Ursa Stream Storage—a headless, multi-modal data storage system built on lakehouse formats. We will publish a follow-up blog post exploring the details of Ursa Stream Storage and its format, which we believe extends and enhances existing open table standards.
In the meantime, here’s a quick sneak peek at the core of Ursa Stream Storage.
At the heart of Ursa Stream Storage is a WAL (Write-Ahead Log) implementation based on S3. This design writes records directly to object storage services like S3, bypassing BookKeeper and eliminating the need for replication between brokers. As a result, Ursa Engine-powered clusters replace expensive inter-AZ replication with cost-efficient, direct-to-object-storage writes. This trade-off introduces a slight increase in latency (from 200ms to 500ms) but results in significantly lower network costs—on average 10x cheaper.
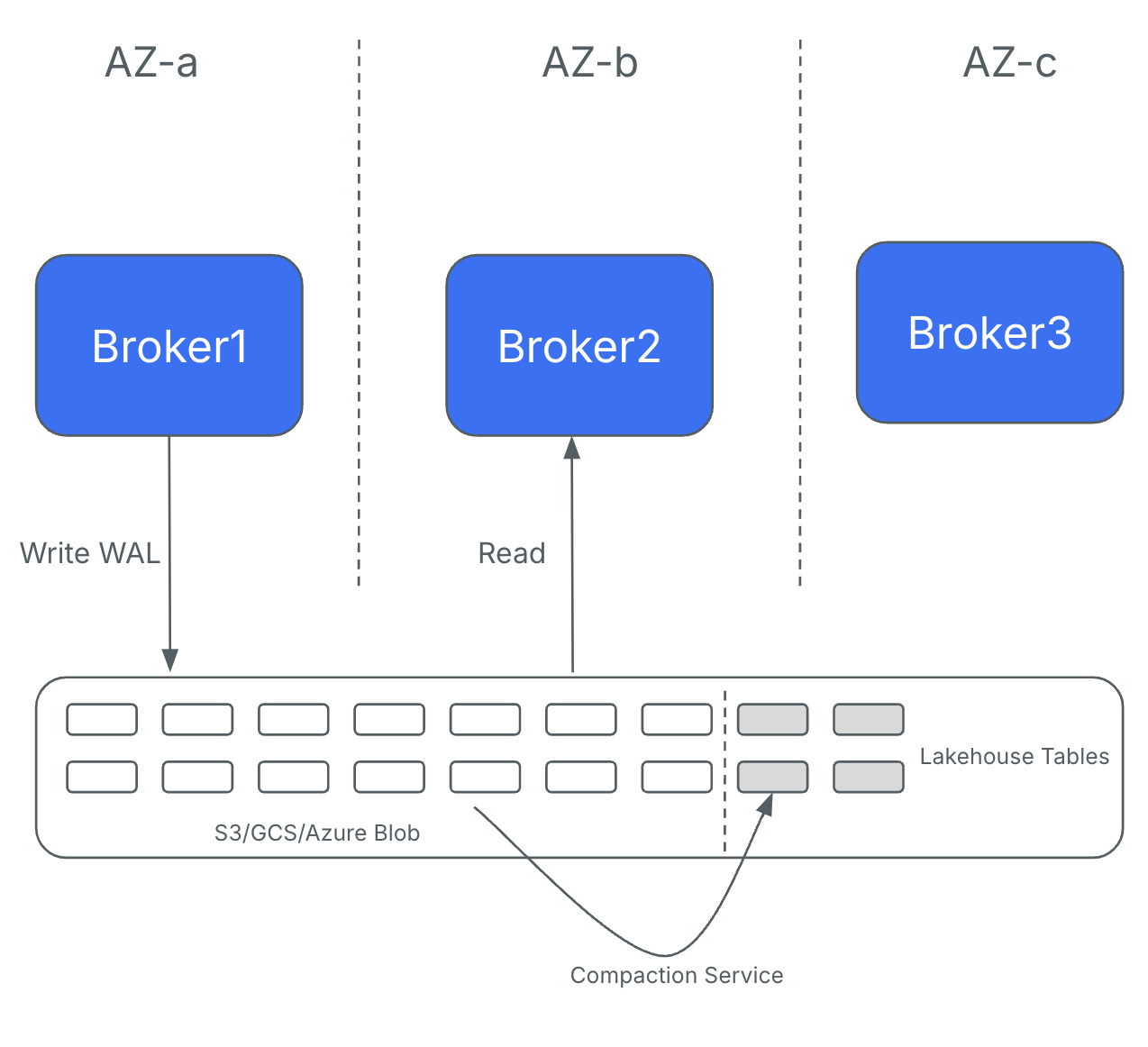
Figure 1. Object-storage based WAL eliminates inter-AZ replication traffic
How Does the Ursa Stream Storage Achieve These Savings?
In the S3-based WAL implementation, brokers create batches of produce requests and write them directly to object storage before acknowledging the client. These brokers are stateless and leaderless, meaning any broker can handle produce or fetch requests for any partition. For improved batch and fetch performance, however, specific partitions may still be routed to designated brokers.
This architecture eliminates inter-AZ replication traffic between brokers, while maintaining—and even improving—the durability and availability that customers expect from StreamNative.
As with any engineering trade-off, these savings come at a cost: Produce requests must now wait for acknowledgments from object storage, introducing some additional latency. However, this trade-off can result in up to 90% cost savings, making it a compelling choice for cost-sensitive workloads.
There’s much more to explore about the technology behind Ursa Stream Storage—stay tuned for a more detailed technical blog post coming soon!
Auto-scaling clusters offer even more cost savings
Sizing and capacity planning are among the most challenging (and expensive) aspects of running and managing data streaming platforms like Apache Kafka. To handle peak workloads, users often have to over-provision resources, which results in paying for underutilized capacity most of the time. Optimizing utilization independently can also introduce significant operational overhead and complexity.
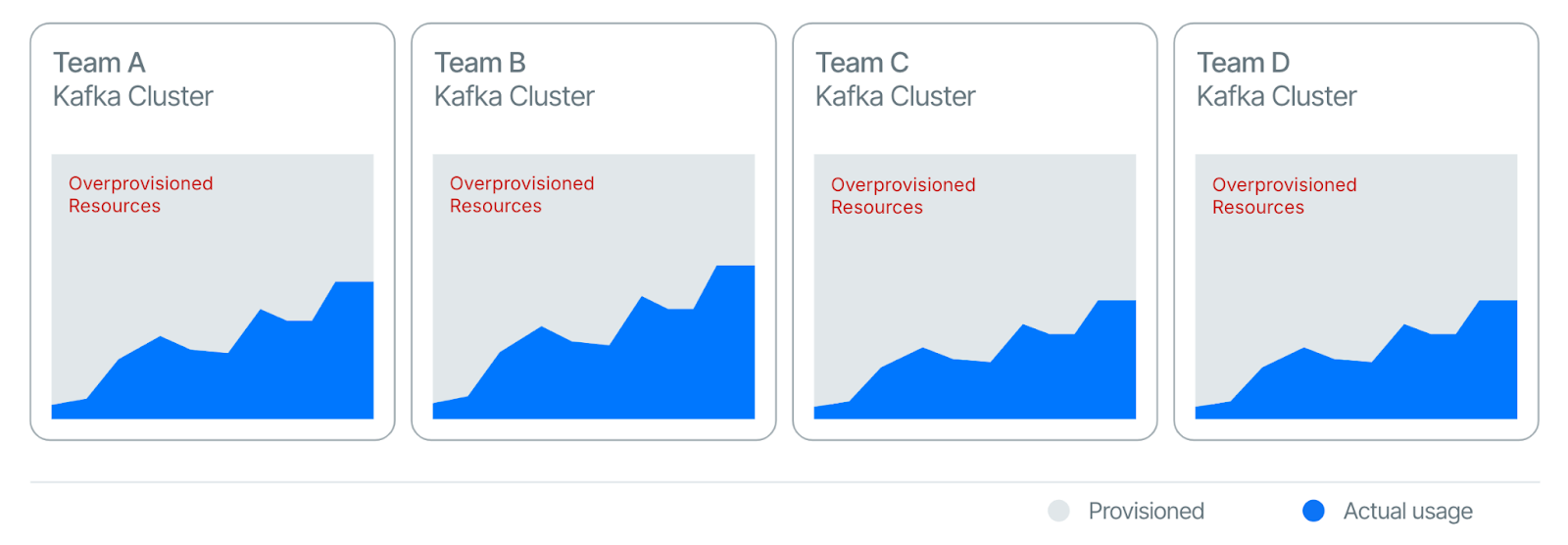
Figure 2. Overprovisioned resources result in excessive spending on underutilized resources
Ursa Engine-powered clusters utilize the same Elastic Throughput Unit (ETU) model as Serverless clusters, decoupling billing from the underlying resources in use to provide more value-based pricing. This means you only pay for the capacity you actually consume, avoiding the costs associated with over-provisioning. With broker auto-scaling, Ursa clusters automatically adjust to match your workload—without user intervention—helping you save on infrastructure costs. BYOC customers pay StreamNative based on actual throughput and pay their cloud provider only for the underlying resources when they are needed.
How to Get Started with Ursa Engine
Getting started with the Ursa Engine is simple:
- Create a BYOC instance through the StreamNative portal.
- Select Ursa as the engine when creating the Instance.
For a step-by-step tutorial, refer to our documentation and instructional video.
One More Thing: How to Migrate to Ursa Engine
So, Ursa is great—but how do you migrate to it? Since the Ursa Engine uses Oxia for metadata storage, whereas the Classic Engine relies on ZooKeeper, there is no direct upgrade path from the Classic Engine to the Ursa Engine. However, we are introducing a new data replication tool called Universal Linking (UniLink) to streamline the migration process from both Kafka and Pulsar clusters to an Ursa Engine-powered cluster. Please checkout our announcement blog post for more details.
Migration from Classic Engine
- Offload data from your Classic Engine cluster to Lakehouse Storage.
- Spin up a new Ursa Engine instance.
- Connect both clusters via UniLink and allow data replication.
- Redirect consumers to the Ursa Engine instance, finalize data offloading, and switch producers.
Migration from Kafka
- Create an Ursa Engine cluster.
- Configure UniLink to replicate data from your Kafka cluster.
- Migrate consumers first, then switch producers.
- Complete the migration with minimal downtime.
Up to 90% Savings with Ursa Engine
In summary, the Ursa Engine leverages Ursa Stream Storage to deliver significant cost savings and performance benefits:
- Leaderless brokers: Any broker can serve produce or consume requests for any partition.
- Object storage based writes: Produce requests are batched at the broker and sent directly to object storage before acknowledgment, eliminating the need for broker replication and avoiding inter-AZ network charges.
- Elastic Throughput Units (ETUs): Ursa clusters auto-scale based on workload demands, ensuring you only pay for the throughput and resources you need, when you need them.
These innovations are designed for high-throughput use cases with relaxed latency requirements, delivering up to 90% cost savings compared to other data streaming platforms that rely on disk-based replication mechanisms.
Sign Up for the Public Preview Today
We are excited for you to experience the power of Ursa Engine-powered clusters. Sign up today and give it a try!




