
In November 2023, StreamNative unveiled a vision poised to transform Lakehouse data storage solutions for businesses globally: Streaming Lakehouse: Introducing Pulsar’s Lakehouse Tiered Storage. The Lakehouse Storage vision explains how Apache Pulsar uses a tiered storage system to organize data into hot, warm, and cold categories based on its lifecycle, which helps reduce storage costs. It also introduces Lakehouse Storage, which meets the ideal standards for tiered storage by embracing open standards, allowing for changes in data schema, supporting data streaming and transactions, and managing metadata effectively.
In this post, we'll explore how StreamNative's Lakehouse Storage offloads and stores data in the open Lakehouse file formats, like Delta Lake. This format is particularly beneficial for applications that handle large amounts of data and need strong data management and complex processing pipelines. We'll also discuss how StreamNative's Lakehouse Storage works with Lakehouse Storage providers like Databricks, the creators of the Delta Lake standards.
The Core Vision of StreamNative's Lakehouse Storage
StreamNative's Lakehouse Storage is designed to facilitate a seamless transition of data from the StreamNative cloud to various low-cost storage services. This model allows organizations to store data for extended periods without incurring the high costs traditionally associated with high-frequency data access and storage solutions. The essence of this vision lies in providing flexibility and reducing operational costs for businesses.
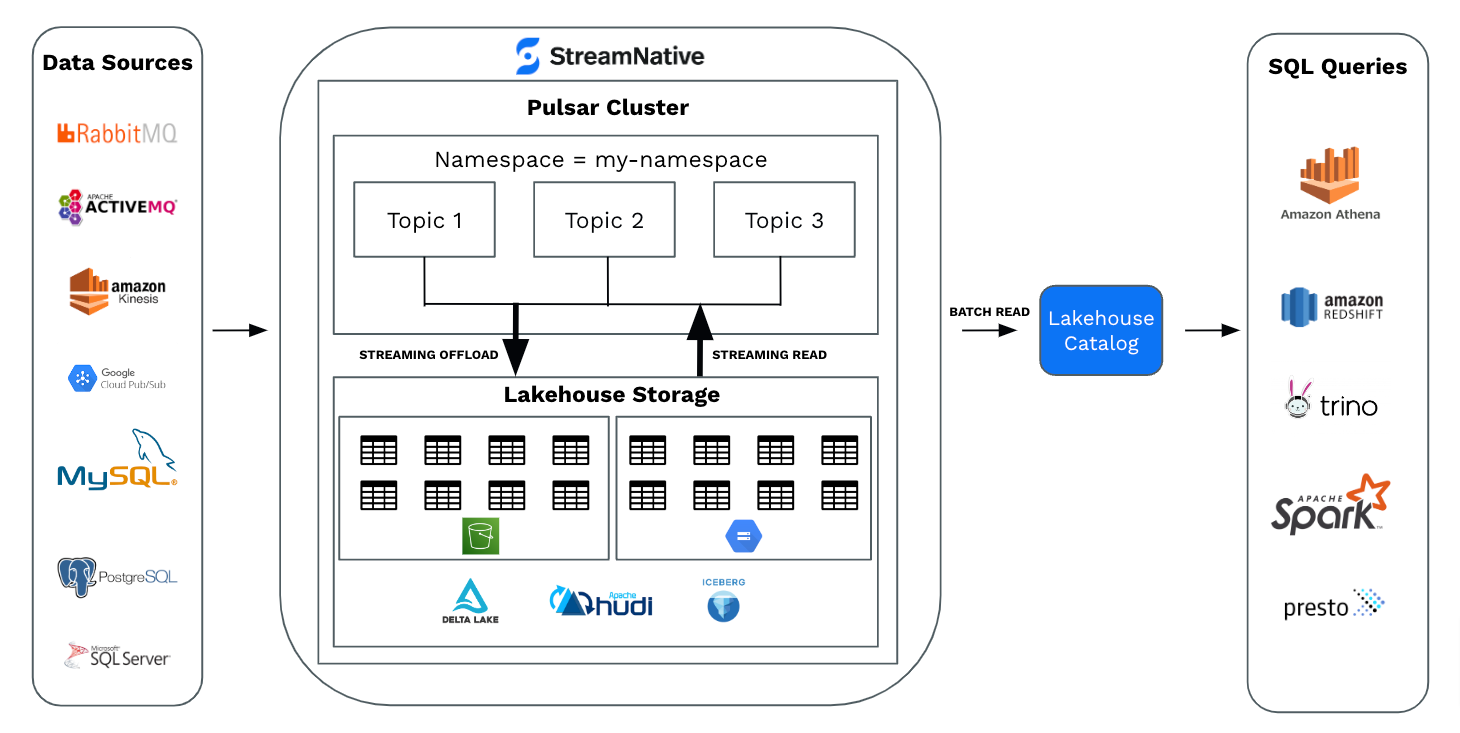
Lakehouse Storage offers the following capabilities.
- Data Offloading to Lakehouse: Easily transfer data from Pulsar topics to top Lakehouse formats like Delta Lake and Apache Iceberg instantly, and keep it in widely used data formats.
- Streaming Read Capabilities: Enable streaming read operations from Lakehouse tables using Pulsar clients, ensuring timely access to real-time data streams for various use cases such AI/ML.
- Batch Read Functionality: Facilitate batch read operations from Lakehouse products through popular query engines like Spark SQL, Flink SQL, and Trino, enhancing data analytics and processing capabilities.
StreamNative’s Lakehouse Storage improves upon the Apache Pulsar Tiered Storage by offering specific advantages.
- Long-Term Data Retention: Define offload policies to store data in BookKeeper for real-time processing and in Lakehouse products for batch processing, ensuring comprehensive data retention strategies.
- Cost-Effective Storage: Utilize Lakehouse products for storing cold data with open formats and compression, offering a cost-effective storage solution.
- Unified Data Platform: Pulsar serves as a unified data storage and processing platform for real-time and batch data processing needs, enhancing operational efficiency.
- Schema Evolution Management: Lakehouse Storage seamlessly handles schema evolution, ensuring synchronization between Pulsar topics and Lakehouse tables.
- Data Query and Analysis: Enable data querying in Lakehouse products and utilize Pulsar consumers/readers to access data from BookKeeper and Lakehouse products.
- Advanced Data Management Features: Benefit from data versioning, auditing, indexing, caching, and query optimization capabilities, merging the advantages of data lakes and data warehouses.
Offloading Data with Flexibility and Efficiency
A standout feature of the Lakehouse Storage is the ability to offload data in preferred Lakehouse formats such as Delta Lake, Apache Iceberg, and Apache Hudi. This flexibility ensures that organizations can choose the format that best fits their operational needs and technological preferences. Moreover, once the data is offloaded, it can be queried using popular third-party tools like Amazon Athena, Apache Spark, and Trino, for batch processing use cases.
Lakehouse Storage In Ursa Engine
Ursa is a data streaming engine that offers compatibility with Apache Kafka and can operate on low cost storage services like AWS S3, GCP GCS, and Azure Blob Storage. It saves data streams in formats compatible with lakehouse tables such as Hudi, Iceberg, and Delta Lake. This approach allows data to be readily available in the lakehouse and streamlines management by removing the need for ZooKeeper and soon, BookKeeper, which also cuts down on bandwidth costs between availability zones. Users can opt in or opt out to use or skip Apache BookKeeper on StreamNative cloud and stream data directly to a Lakehouse.
Spotlight on Delta Lake:
StreamNative Lakehouse Storage supports the Delta Lake format, pioneered by Databricks. Delta Lake is an open format to store data in lakehouse and it offers numerous capabilities for data management like ACID transactions, Schema enforcement and evolution, Time Travel, and more. Delta Lake support is currently in Private Preview within StreamNative Private Cloud and Bring Your Own Cloud (BYOC) offerings.
With Delta Lake support, the data offloaded by StreamNative cloud stores a rich transaction history for tables as JSON files in a metadata folder, which includes transaction logs of operational and maintenance actions. The table data itself is stored in Parquet format. Delta Lake even supports reads in Hudi and Iceberg formats through a feature called UniForm to enable complex data ecosystems.
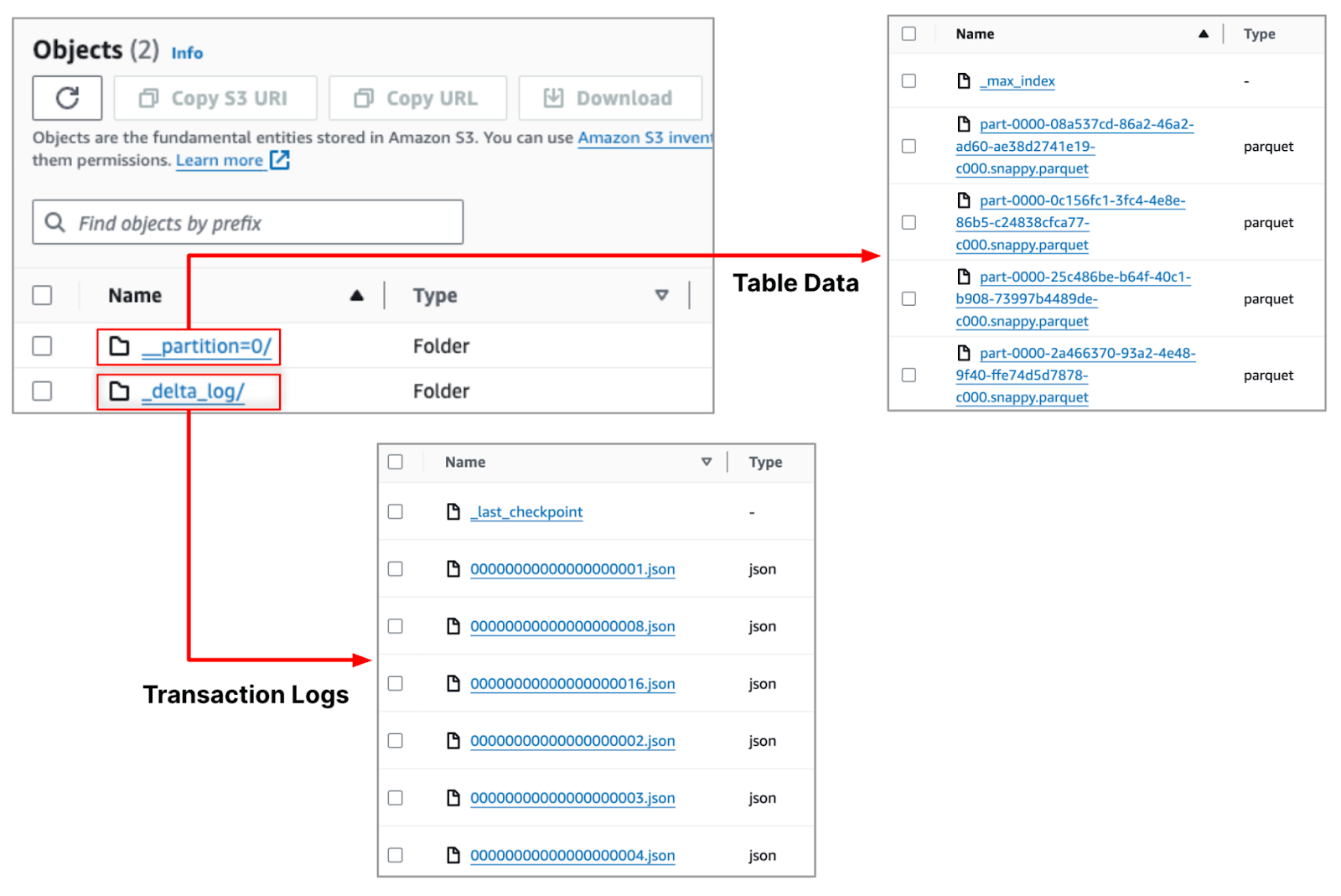
The integration of Delta Lake in StreamNative’s Lakehouse Storage provides major advantages for businesses, as outlined below
- Helps teams work together on accurate data, speeding up decision-making.
- Lowers infrastructure and maintenance costs with best price performance.
- Provides a secure, multi-cloud analytics platform based on an open format.
Lakehouse Storage Integration With Databricks
Looking towards the future, StreamNative aims to integrate more closely with various Lakehouse storage vendors like Databricks who created the Delta Lake format. These partnerships will likely standardize specific Lakehouse formats, facilitating a smoother data management process across different platforms. Such integration will also enhance compatibility and interoperability between different data systems, fostering a more cohesive data management ecosystem.
Users must undertake only a few manual steps to configure Databricks with StreamNative Lakehouse Storage.
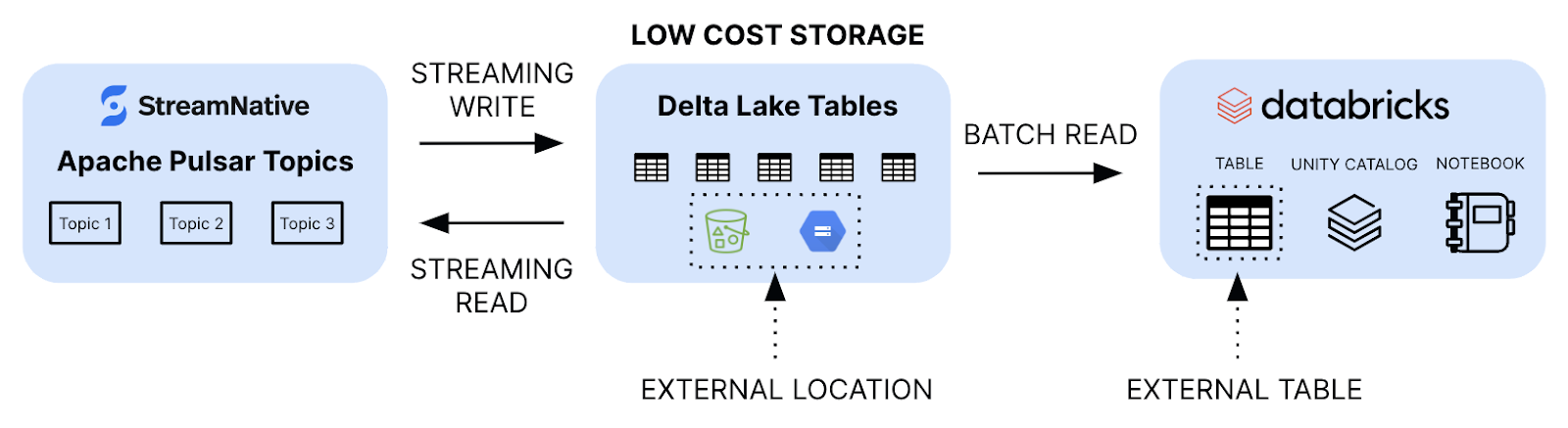
Let's talk about a scenario where an enterprise is using StreamNative cloud in a Bring Your Own Cloud (BYOC) environment and wants to set up Databricks with it. In such a scenario users can perform the following three steps to successfully mount, discover, and query the offloaded data within Databricks workspace.
- Add an external storage location
Within the Databricks Unity Catalog, add an external location which points to the storage bucket where StreamNative Cloud is streaming data. The external location can be set up by setting up the right access permissions. You can configure the access policy to be read only.
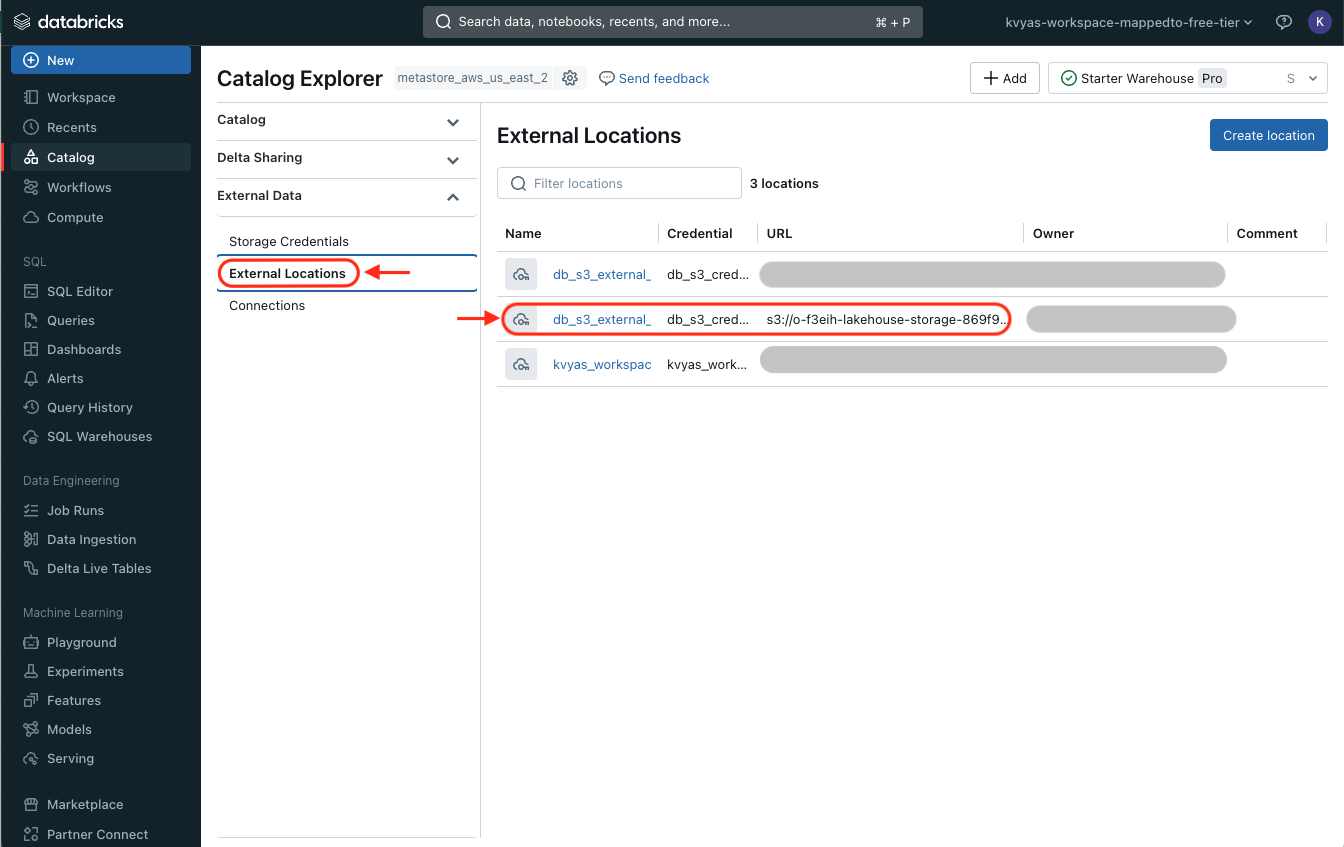
- Create external table
Within the Databricks SQL Editor create an external table which points to the external storage location.
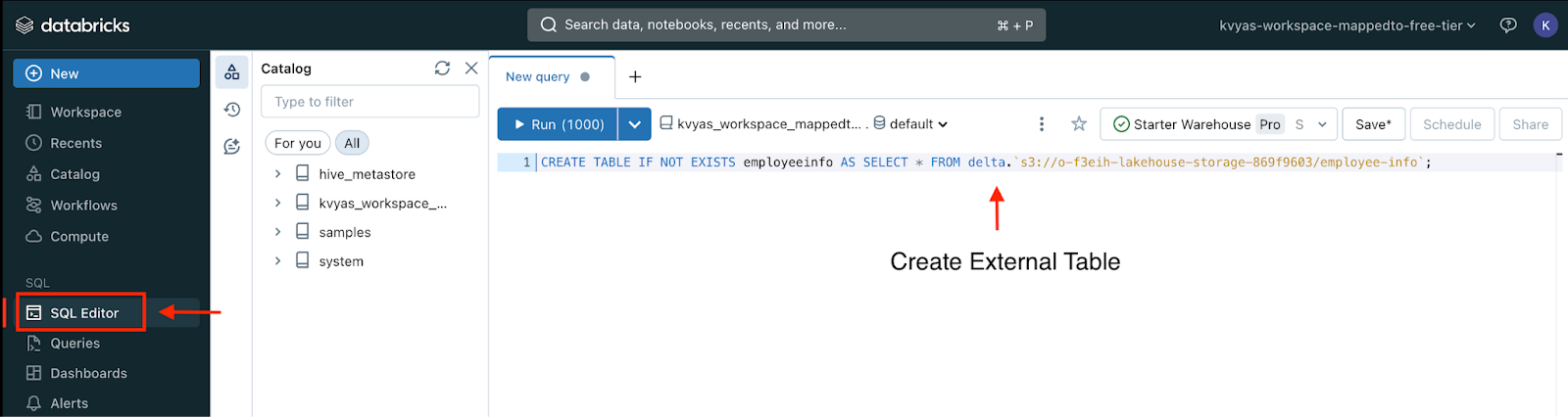
Here is an example query which creates an external table called employeeinfo pointing to an external location path of an S3 bucket.
CREATE TABLE IF NOT EXISTS employeeinfo AS SELECT * FROM delta.s3://o-f3eih-lakehouse-storage-869f9603/employee-info;
Once the table is created, you can view and explore the table and its schema within the Unity Catalog.
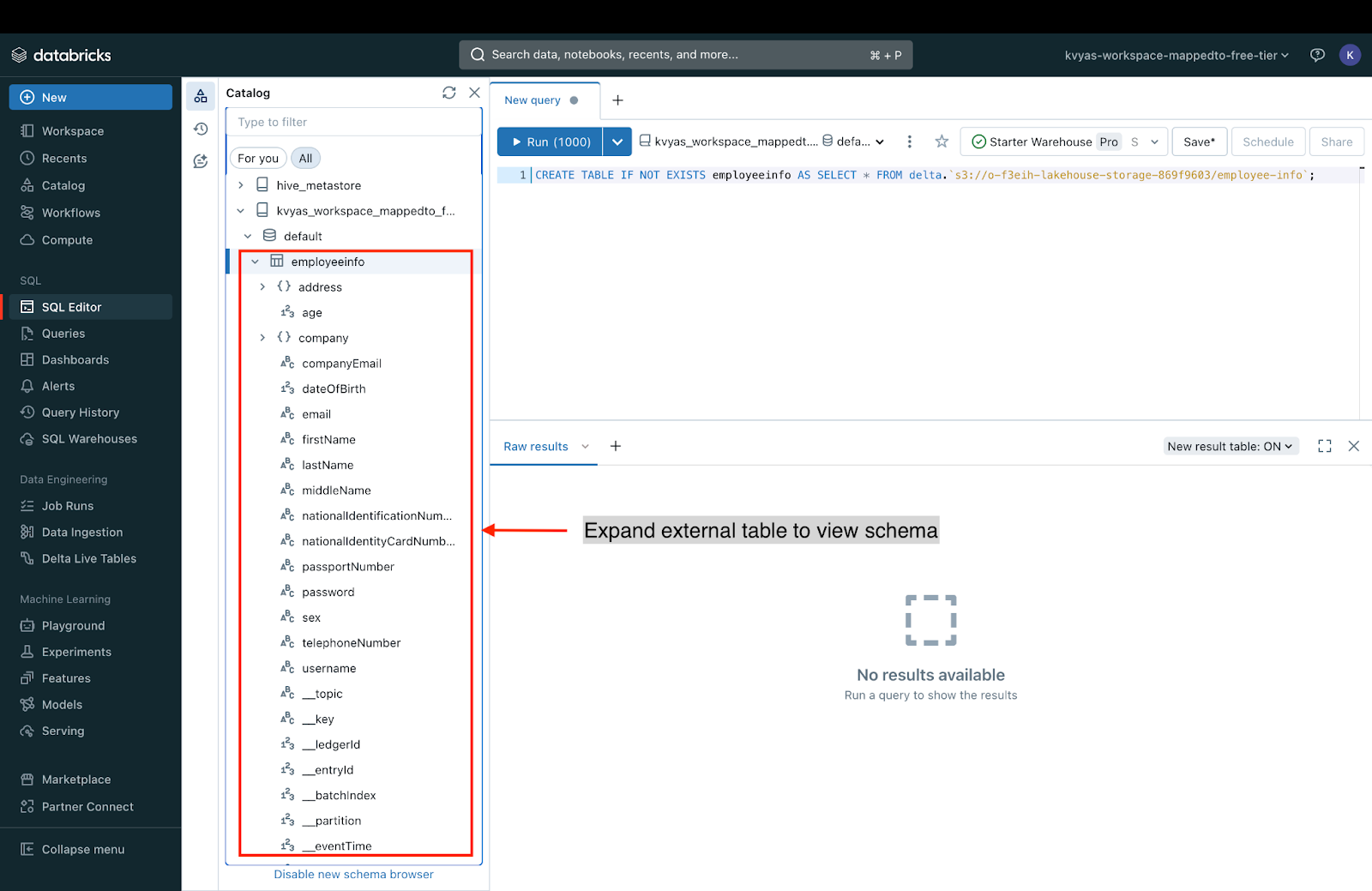
- Query data
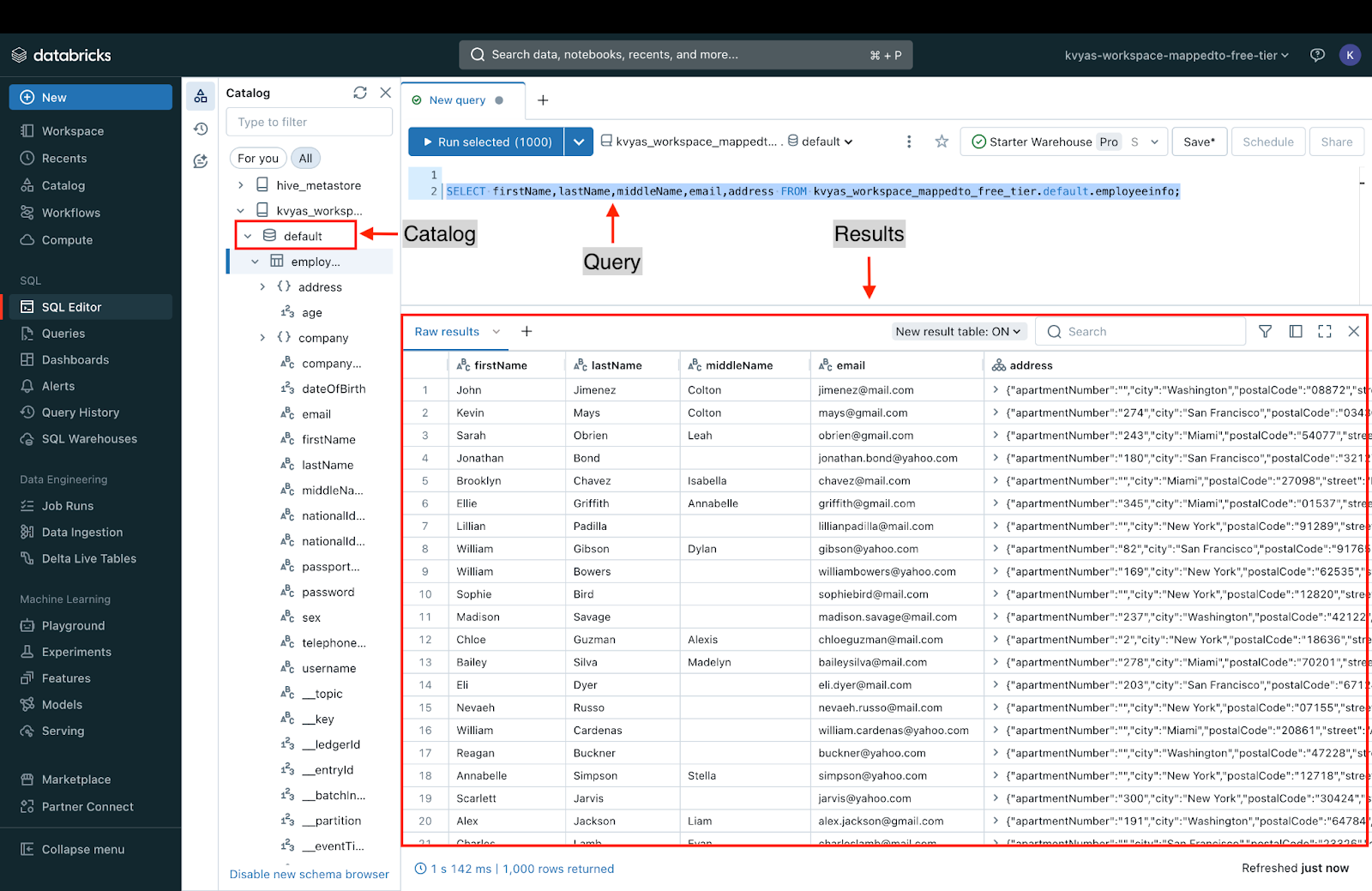
Once the external table is created in the Unity Catalog, users can perform queries to list, filter, and aggregate data.
Here is an example of a query fetching a few specific columns from the employee info table:
SELECT firstName,lastName,middleName,email,address FROM kvyas_workspace_mappedto_free_tier.default.employeeinfo;
StreamNative's long-term strategy includes direct integration with Databricks' Unity Catalog. This integration will streamline processes, significantly reducing the manual effort required to discover and manage data.By directly publishing data to a unified catalog, StreamNative will enable users to leverage a centralized repository for managing and securing data across various environments. This evolution in data handling and storage exemplifies StreamNative's commitment to innovation and customer-centric solutions in the data lakehouse domain.
Summary
Here's a quick summary of the key content covered in the blog:
- Lakehouse Storage Part of Ursa Engine: Ursa engine within StreamNative cloud natively supports Lakehouse Storage so users can opt in or out of using Apache BookKeeper for storage and directly write data to a Lakehouse.
- Private Preview - The Lakehouse Storage is currently in Private Preview. Customers can file a ticket to enable Lakehouse Storage in their cloud environment.
- Setting Industry Standards: StreamNative's Lakehouse Storage is defining the future of data management with its flexible, cost-effective solutions.
- Leading Integration Efforts: By aligning with popular open lakehouse formats and tools, StreamNative is at the forefront of creating an efficient and interconnected data management landscape.
- Cost Efficiency and Enhanced Accessibility: This initiative promises significant cost savings while improving data accessibility and analytics capabilities.
- Empowering Businesses: It paves the way for businesses to fully leverage the potential of their data assets.
- Streamlining Decision-Making: The partnership with Databricks simplifies and accelerates decision-making processes for customers.
- Enhanced Collaboration: The collaboration with Databricks ensures that customers benefit from seamless integration and optimized data workflows, reducing complexities in data handling and analysis.




