
Two weeks ago, I had the pleasure of attending Current 2024, a data-streaming conference hosted by Confluent. It was a valuable opportunity to connect with industry peers. While the event may not have featured product announcements from Confluent as notable as those at Kafka Summit London in March, it still offered insightful discussions and networking opportunities. The event focused heavily on the Shift-Left architecture, with Jay Kreps, CEO of Confluent, stating that a data streaming platform is the natural foundation for AI and calling out lakehouse as unsuitable.
While I agree that Shift-Left is an important data strategy for moving toward real-time streaming architectures and we respect Jay’s perspective on Lakehouses, we have a different viewpoint on it. There are additional factors to consider that provide a more comprehensive understanding of the situation. Data streaming is indeed critical for real-time generative AI, but the true data foundation for real-time Gen AI applications must combine data streaming and lakehouses. This synergy is what I call Streaming-Augmented Lakehouse (SAL), similar to Retrieval-Augmented Generation (RAG) in AI. Just as RAG enhances large language models (LLMs), SAL augments traditional lakehouses with real-time data streaming capabilities.
Unlike Shift-Left, which aims to move entirely from batch and lakehouse architectures to real-time streaming, SAL acknowledges that lakehouses serve as the foundation where all data lands but emphasizes augmenting lakehouses with real-time data streams for greater flexibility, low-latency insights, and adaptability.
The Shift-Left Principle
1. What is Shift-Left?
Shift-Left is a modern data strategy that accelerates data processing by shifting from batch processing to real-time streaming architectures. Traditional data pipelines in lakehouses are batch-oriented, where data is ingested in bulk at scheduled intervals, transformed, and stored for downstream consumption. This approach works well for historical data analytics, machine learning model training, and big data processing, but it doesn’t meet the needs of applications requiring real-time insights or low-latency responses.
Shift-Left focuses on continuously processing data as it arrives, enabling businesses to build real-time data products such as recommendation engines, fraud detection systems, and dynamic AI-driven applications that respond to user interactions and changes in real-time.
2. The Problem with Batch-Oriented Lakehouses in a Shift-Left World
Lakehouses excel at managing large datasets and AI assets, with strengths in efficient querying, long-term storage, and batch processing. However, they struggle to meet the demands of real-time applications that require immediate processing and rapid decision-making. The key limitation is data latency (not query latency; in fact, many lakehouse systems excel at reduced query latency). Batch processing often occurs hours or days after data is generated, which is unacceptable for real-time Gen AI applications, where the freshness of data directly impacts decision-making quality. This becomes especially critical as Gen AI applications evolve from conversational chatbots to actionable agents.
This latency becomes a bottleneck in a Shift-Left architecture, and that’s where data streaming plays a crucial role. Lakehouses must adopt record-level ingestion to make them more suitable for real-time Gen AI applications.
You Can’t Only Shift Left
While Shift-Left is undoubtedly a valuable strategy, it’s important to consider it as part of a broader data strategy rather than the only valid solution. A balanced approach that incorporates both Shift-Left strategy and Lakehouses together often yields the most comprehensive results. Here are some factors that prevent the full implementation of shift-left practices:
- Cost Efficiency: Data streaming platforms are not as cost-effective as lakehouses for batch processing and managing historical data. Most of the world's data (90%) is processed in batches, and replacing batch workloads with streaming jobs doesn’t make economic sense. While systems like StreamNative’s Ursa Engine and Confluent’s Tableflow try to make streaming platforms cost-effective by persisting historical data in lakehouse formats, the core of this approach is still the lakehouse. Streaming serves as an augmentation layer rather than a replacement.
- Multi-Hop Pipelines: Streaming platforms often require multi-stage pipelines, which can become complex, introducing challenges with intermediate result persistence, correctness, and robustness. The idea that lakehouses require multi-hops while streaming doesn’t is misleading—streaming jobs with too many stages can be more complex than chaining multiple batch jobs.
- Not All Jobs Require Low Latency: While technologies like Flink and RisingWave deliver low-latency computation, not all jobs require real-time processing. Systems like Spark are still better suited for many use cases. Especially with Project Lightspeed, Spark is now equipped for real-time data streaming as well. There is no one-size-fits-all solution, and businesses need to strike a balance between cost and performance (latency).
SAL: Augmenting Lakehouses with Data Streaming
Instead of solely focusing on Shift-Left, let’s introduce Streaming-Augmented Lakehouse (SAL). SAL combines the strengths of data lakehouses and real-time data streaming, addressing the shortcomings of traditional batch-oriented architectures and avoiding completely shifting-left towards a streaming-only architecture. It builds on the concept of Stream-Table Duality, treating a table as a stream and a stream as a table. At its core:
1. Data Lakehouses: The Foundation for Managing Data Assets
Data lakehouses provide a strong foundation for managing both structured and unstructured data, offering both scalable storage and transactional capabilities. In Generative AI, lakehouses are crucial for storing and managing large datasets used for training, validation, and tuning models.
For example, training large-scale machine learning models like LLMs requires extensive datasets. Lakehouses ensure these datasets are organized, queryable, and accessible, while their transactional capabilities allow for accurate versioning and governance, ensuring that models can be retrained against historical data.
2. Data Streaming: The Real-Time Layer Augmenting Lakehouses
While lakehouses manage historical data, data streaming provides the real-time layer needed to continuously feed up-to-the-second information into AI systems. As I discussed in my previous blog post, "Data Streaming for Generative AI", streaming enables AI models to adapt dynamically based on the latest inputs.
Streaming ensures that lakehouses are continuously updated with new data points, enabling real-time AI applications to respond to current events, user interactions, or sensor readings, making AI systems reactive and proactive.
Why SAL is Different from Lambda Architecture
You might wonder whether SAL resembles Lambda Architecture. While they share similarities, the core difference lies in how data is managed. Lambda Architecture uses two separate systems (streaming and batch), leading to challenges like data inconsistency, dual storage costs, and complex governance.
SAL, on the other hand, stores one copy of data, presenting it as either a stream or a table depending on the use case. It shifts ingestion & computation left to achieve low latency while ensuring data quality and governance. SAL emphasizes storing one copy of data and allowing it to be consumed via multiple modalities (stream or table), protocols (Kafka or Pulsar), and semantics (competing queues vs. sequential streams) tailored to specific business needs. The benefits of SAL include:
- Cost and Time Efficiency: You no longer need to move data between systems, saving both time and money. For example, users can access their data as tables and seamlessly integrate it with Athena, Databricks, Snowflake, or Redshift without relocating it.
- Data Consistency: By eliminating the need for multiple copies of data, SAL reduces the occurrence of similar-yet-different datasets, leading to fewer data pipelines and simpler data management.
- Bring Your Own Compute: With SAL, you can choose the best processing engine for each task—using Flink for one job and DuckDB for another. Since data is abstracted from the processing engines, you're not locked into any specific technology because of decisions made years ago.
- Governance and Security: SAL ensures governance through data catalogs and centralized access control. This allows for fine-grained control over sensitive data, ensuring that private and financial information remains secure.
Ursa Engine: Augmenting Lakehouses with Data Streaming
Many streaming platforms have already started integrating with lakehouses, including StreamNative’s Ursa Engine and Confluent’s Tableflow. However, not all integrations are created equal. Confluent’s Tableflow follows a Lambda-like architecture, storing two copies of data—one for streaming and one for the lakehouse.
In contrast, Ursa Engine implements SAL with a headless stream storage engine that augments lakehouse tables with streaming updates. At the core of the Ursa Engine is the Ursa Stream storage, a stream storage implementation over object storage that incorporates row-based WAL files for fast appends and columnar Parquet files for efficient scans and queries. Data streamed into Ursa is stored in Ursa Stream, compacted into Parquet files, and organized as lakehouse tables—eliminating the need for separate copies of the data. Changes made to the lakehouse tables can be indexed as streams and consumed via either Kafka or Pulsar protocols.
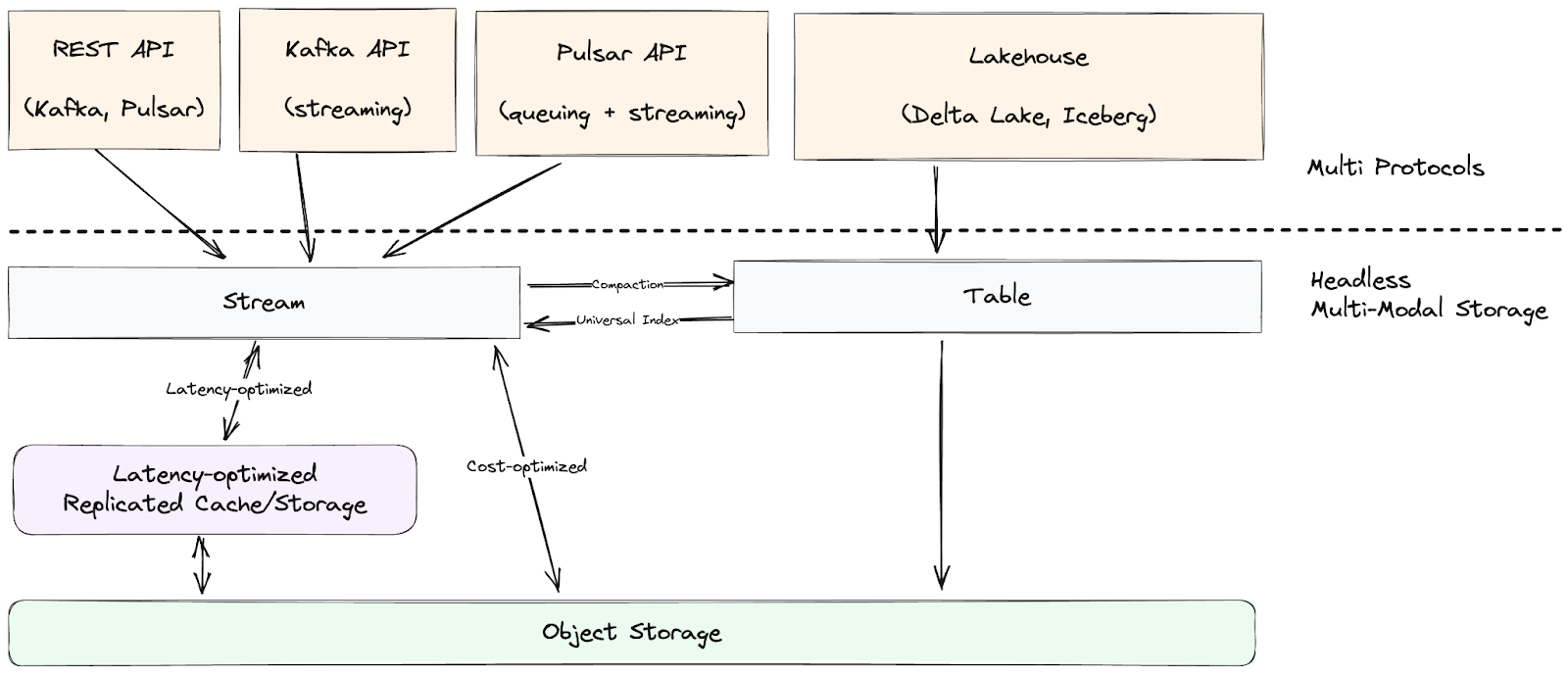
By building multiple modalities over the same data, Ursa enables different semantics. You can process the data as continuous streams using a stream processing engine like Flink or RisingWave, or as cost-effective tables with a batch query engine like Databricks or Trino. Ursa’s design allows for seamless integration between real-time streams and historical data, empowering AI models to operate in a Shift-Left manner. For more details about Ursa Engine, we invite you to attend the upcoming Data Streaming Summit at Grand Hyatt SFO on October 28-29, 2024.
SAL: The Shift-Left Foundation for Real-Time Gen AI
In the age of AI, businesses need a new data foundation that combines the real-time power of streaming with the robustness of lakehouses. Streaming-Augmented Lakehouse (SAL) is that foundation. It allows enterprises to build AI systems continuously fed with real-time data while also managing the vast historical datasets needed for training and improving models.
By embracing SAL, organizations can integrate real-time insights into their lakehouse architectures, ensuring they act on data as it arrives while maintaining governance, scalability, and analytical depth. SAL represents the future of the data foundation for real-time Gen AI, enabling businesses to continuously evolve and respond to real-time changes.




.png&w=1536&q=100)