One of the ways in which the tech industry has become so competitive is the expectation that software should be able to intake mass amounts of data, process it rapidly, and with incredible precision. In the past, this standard was typically saved for areas like medical technology or FinTech, but it is now becoming the norm across the industry. Stream processing is the most reliable method for successfully meeting this expectation, although each streaming technology has its own strengths and weaknesses.
The benefit of stream processing is how well it can handle incredibly complex situations. Unfortunately, that also means it can be a challenge to learn. Even for those already working with streaming, that world is constantly changing, and it can be hard to keep up without up-to-date refreshers.
This post is part of a series that offers a full introduction to modern stream processing, including the newest innovations and debunking misconceptions. In the following posts, we’ll cover the challenges of stream processing and how to avoid them, as well as the streaming ecosystem like real time analytics and storage.
Use Case: Fraud Detection
In this post, we’ll be using fraud detection as a use case. On the simplest level, fraud detection covers anything where it is important to verify that a user is who they claim to be, or that the user behavior is consistent with the user’s intentions. In terms of what makes for successful fraud detection, the focus is usually on security - how hard is it to access the data, are there opportunities for data to be exposed accidentally, etc.
Cyber attacks are becoming increasingly sophisticated, so we can’t rely only on security to prevent 100% of attacks. In the talk on Cyber Security Breaches at the Future of Data’s 2020 Cyber Summer Data Slam, speaker Carolyn Duby (Field CTO and Data at Cloudera) mentions that state sponsored hackers could compromise an entire network in less than 18 minutes. She also emphasized this need for access to real time AND correlative data in order to have any chance at responding to an anomaly accurately in a time that’s meaningful to the customer.
This means that you need a system that can ingest large amounts of live data. However, you also need a way to analyze and aggregate that data, and correlate it with other data. This data or metadata is likely being ingested from external systems, since current user data and historic user behavior patterns (and things like subscription or account information) would not be stored or coming in from the same source.
This is where stream processing really shines. Not only that, this is where stream processing becomes necessary. With the most powerful stream processing engines, you can achieve real-time data transfer and processing for large amounts of data, as well as support precision accuracy of the data. This also makes fraud detection a prime example to showcase what each of the core elements of streaming architecture is built for.
Stream Processing Basics & Architecture
As the name implies, stream processing involves a continuous stream of data and is often referred to as “data in motion.” Another way of describing this has been as an “unbounded” stream of data. With an unbounded, continuous stream of data, there are a lot of benefits- most data is already naturally in this form, whether it’s input from a video game, weather sensor readings, or customer usage patterns. And, without breaks and waiting for a new batch of incoming records, it naturally has more potential for faster data transfer and processing.
Data stream processing is used as a distinction from batch processing, where data is published to a system or application in batches, or bounded units of data.
The most prevalent streaming use cases, and the ones we’ll be referring to here, are event streaming cases, where “event-driven” architecture is used. On the simplest level, event-driven architecture is a system where actions are triggered by an event. They are highly decoupled, asynchronous, and most importantly, allow for the possibility of real-time data processing. By contrast, a traditional transactional application depends on request to elicit a response, and on receiving acknowledgment to proceed.
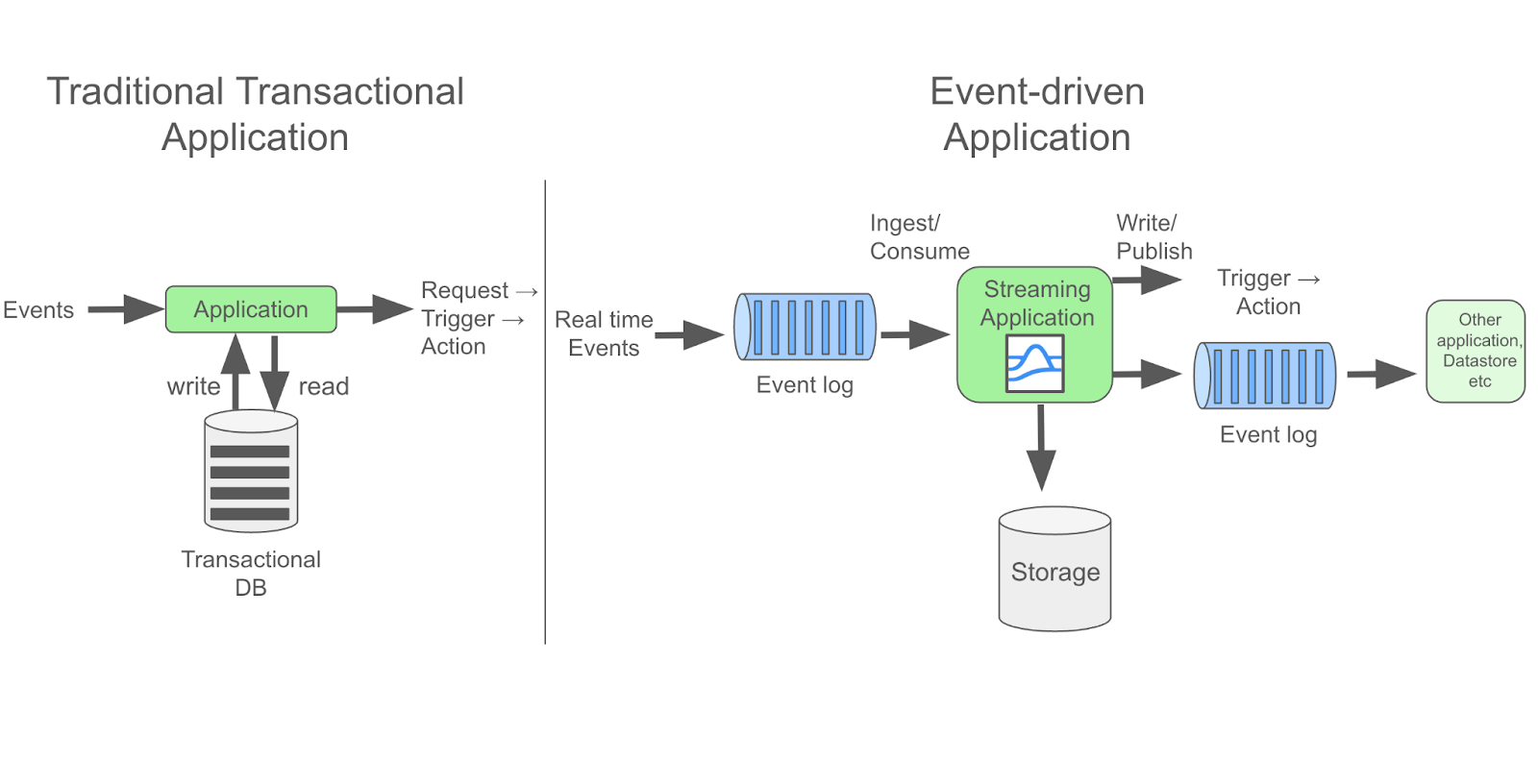
Stream processing architecture can come in many different “shapes.” However, the most common is a data pipeline, which is also a great way to showcase how streaming works.
The pipeline can consume data from a variety of “sources”, such as from another app, or, with some of the more advanced data streaming frameworks and platforms, directly from where the data is collected, which could be hardware like a weather sensor system, or it could be the original application where a fraudulent credit card purchase occurs.
In reality, the bulk of this pipeline is actually one or more stream processing applications, powered by a streaming framework or platform. Many of these technologies are open source, including some of the most powerful ones like Apache Pulsar and Apache Flink. Flink is a stateful processing engine (meaning that state can be persisted within a Flink application). Pulsar is a distributed messaging and streaming platform which is now also cloud-native!
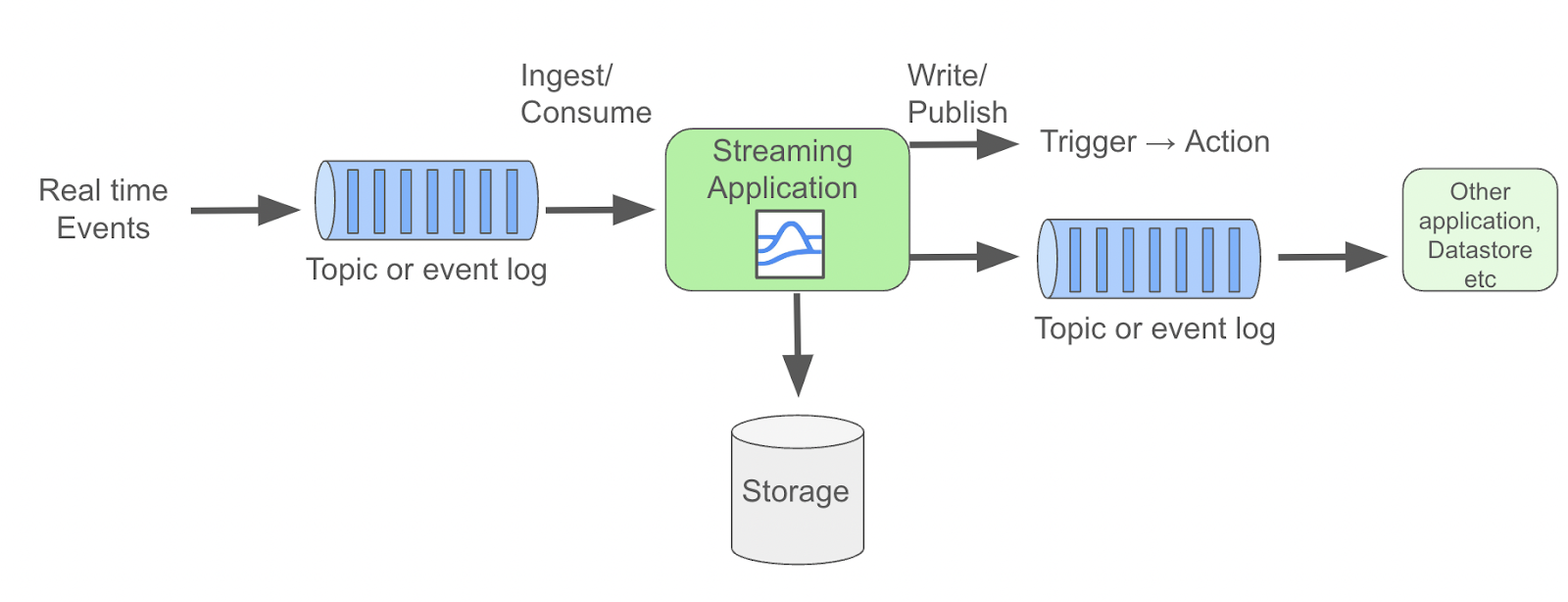
In a complex use case like fraud detection, there would likely be several stream processing applications making up the whole system. Let’s say we have an example where a large tech company sells multiple different types of software products, and most of their users use at least two different products, ranging from hobbyists to enterprise customers. This company wants to use a stream processing system to ensure that there is no credit card fraud. This initial pipeline would likely need to aggregate the different accounts and subscriptions into values that can be compared to each other. Meanwhile, this system would likely be storing metadata and possibly other information like the user account status, in separate topics, logs or queues.
Queues and logs are such a core part of stream processing, that streaming platforms are often classified by whether they are queue or log-based. Both are used to route data from one system to another, but also to group related data together. Queues are first-in, first out, which can be beneficial to ensure that the order of messages is retained. With queues, the data is stored only until it is read by a consumer. Logs, on the other hand, can persist data and can also be shared among multiple different applications- they are a one-to-many routing system. Topics are more sophisticated and high-level than logs, but logs are still the underlying data structure. Logs (and, therefore, topics) also support publish-subscribe (or pub-sub) applications.
With pub-sub, consumers can “subscribe” to a topic, and messages that are published to that topic can be broadcast to all subscribed parties. At the same time, topics can also provide message filtering, so that subscribers only receive messages that match the set filters. Being able to broadcast and filter messages in this way allows this to be a highly efficient option, which is why topics are used for event-driven applications and real time stream processing. That being said, a true pub-sub system is not guaranteed just by using topics over queues. Making sure your application has an advanced pub-sub structure like Apache Pulsar’s is particularly useful for scalability.
In our fraud detection scenario, the topics become the “sinks” for this initial streaming system. A stream processing application will allow you to write to or, in this case, publish data to different varieties of sinks, like a datastore, logs, various types of storage, or even to another data stream.
At this point, the aggregated data topic, which is this pipeline’s sink, is now the source for another data pipeline. In a real world scenario, this could be even more complicated, with even more data streams. Incoming data could be joined and merged as it’s being consumed, or there could be more topics being ingested that originated from other applications with varying different data types that need to be aggregated upon ingest.
However, in this example, we’ll say there’s just the two streaming applications. In this second one, this is where the heavy lifting occurs. The best fraud detection will combine a machine learning model that has been trained on their use case with a high power stream processing engine.
If an anomalous action occurs - let's say a long time hobbyist purchases a large subscription to an enterprise level product, the machine learning model should pick this up quickly. However, the work isn’t done once the anomaly is detected. In a highly sensitive case, the anomalous transaction may require additional analysis, and either way, it would need to be sorted and alerted on in as near real-time as possible. There are several ways this anomaly could be alerted on. The simplest way would be that the fraudulent transaction would be sent to a topic designated just for anomalies, where each event in that topic is alerted on, meanwhile all other non-fraudulent transactions would continue on to a datastore or other sink.
At this point, a non-streaming application could likely handle the alerts, although it is just as likely that a company would want an additional streaming pipeline to rapidly sort the alerts, particularly if there are different algorithms for different combinations of thresholds: maybe there are alerts for anyone purchasing something over a certain amount, and separate alerts for any hobbyist attempting to buy enterprise software and the system needs to ensure the user is not being notified twice, etc. This could get progressively more complicated the more products and types of users and subscriptions that the company has, which would necessitate an additional need for rapid, large-scale data processing.
This brings us to throughput and latency. In this case, we’ve mentioned several times the importance of being able to quickly process large amounts of data. The “throughput” relates to how much data a streaming system can consume (and/or process). Ideally, a system would be capable of as high throughput as possible.
“Latency” refers to how much lateness there is in the data getting from one point to another. This means that the ideal scenario would be to have as low latency as possible - the least amount of delay in a message moving through the stream.
The importance of benchmarking
This combination has historically been very tricky to produce. The relationship between throughput and latency is often how scalability of a stream processing platform is measured. For instance, if you’re testing the performance of two different stream processing platforms, and you are only sending a small amount of data through, you’ll likely have the same amount of latency for both applications.
However, if you start adding drastically higher amounts of data into your system, you will likely notice that suddenly the latency goes up for the less performant software. This means that, unfortunately, when building out a proof of concept and selecting a streaming system to use, many people often select a less performant stream processing option if they aren’t testing with large amounts of data. In this case, these users often won’t find out that their software is insufficient for scaling with their company’s growth until they have already launched and are committed to ingesting increasingly larger amounts of user data. This is why checking out benchmarks and testing with as high throughput as possible is so important.
Data Accuracy and “Exactly Once”
In our fraud detection use case, we’ve discussed the requirement for high throughput of data and speed of processing and transferring that data. However, there’s another essential component. When ingesting large amounts of data, there is a risk that messages could get dropped or duplicated. The best machine learning models and algorithms won’t do much if the event is dropped and never makes it into the application. Duplicated events can be equally problematic, and particularly for this use case, could trigger a false positive as being an anomaly. This is where a concept called “exactly once guarantees” comes in. Conceptually, it is basically what it sounds like - a guarantee from the stream processing platform that messages will neither be dropped nor duplicated, but that each message will arrive successfully and only once. In practice though, this can be difficult to implement, particularly at scale.
Conclusion
Stream processing is the necessary choice for any use case that requires data to be truly real-time accessible, particularly when there are large amounts of data, or could be large amounts of data in the future (always good to think ahead for scalability requirements!). However, not all stream processing platforms will have the right features or performance capabilities for every use case. It’s important to understand whether your application should be log- or queue-based, and if it can scale up with your project’s projected growth.
If you would like to learn more, stay tuned for our next blog in the intro series! Or if you’re ready for best practices and data patterns, check out our Data Streaming Patterns series.
Want to Learn More About Apache Pulsar and StreamNative?
- Learn more about how leading organizations are using Pulsar by checking out the latest Pulsar success stories.
- Use StreamNative Cloud to spin up a Pulsar cluster in minutes. Get started today.
- Engage with the Pulsar community by joining the Pulsar Slack channel.
- Expand your Pulsar knowledge today with free, on-demand courses and live training from StreamNative Academy.