Apache Kafka and event streaming are practically synonymous today. Event streaming is a core part of our platform, and we recently swapped Kafka out for Pulsar. We’ve spoken about it in-person with our clients and at conferences. Recently, a friend in the Apache Pulsar community recommended that I write a post to share our experience and our reasons for switching.
We built our platform on Kafka and found ourselves writing tons of code to make the system behave as we wanted. We decided that Kafka was not the right tool for the job. Obviously, this won’t be true for many, many use cases and, even when it is, it may make sense to use it anyway instead of Pulsar. Through the rest of the post, I’ll describe the solution we built with Kafka, and why we decided to move to Pulsar.
Our Problem Statement
What is StreamSQL?
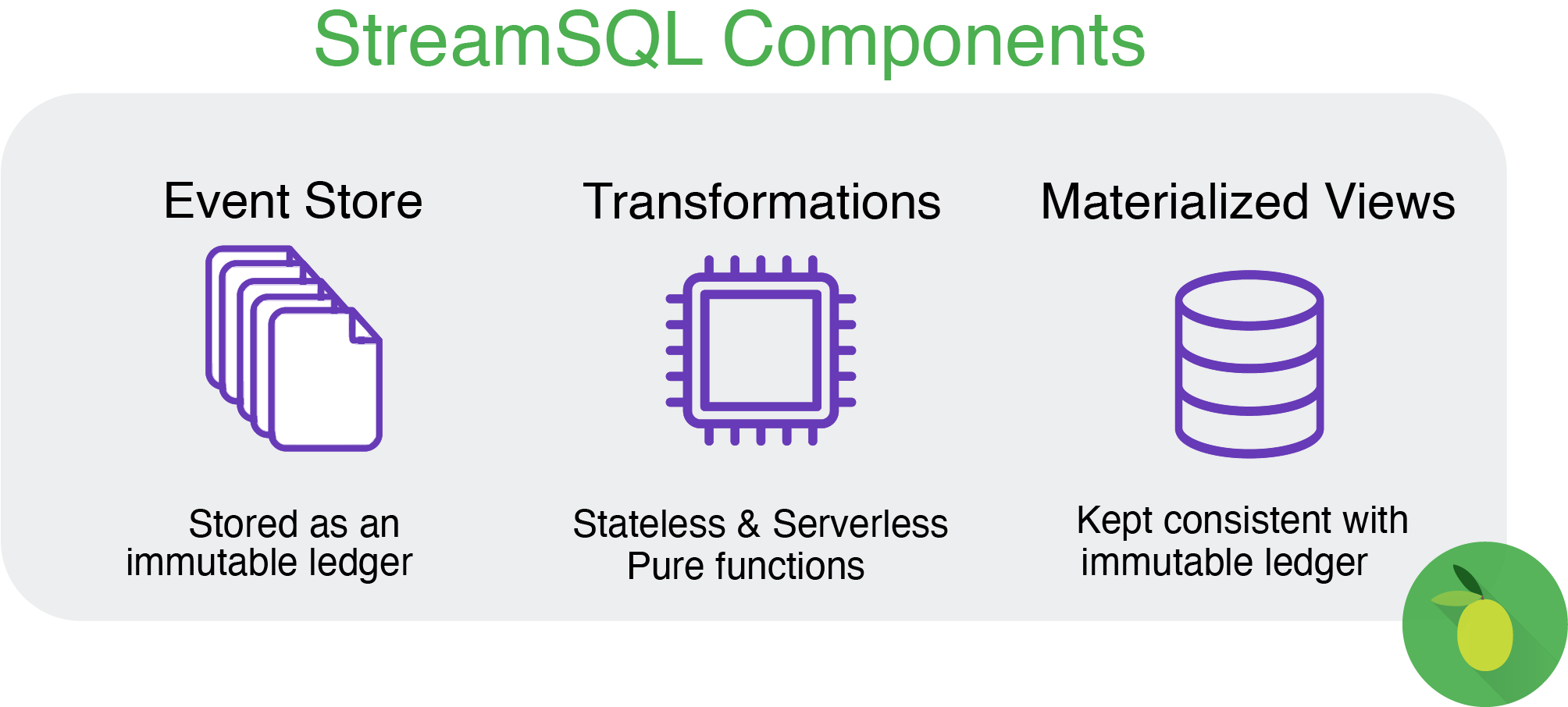
StreamSQL is a data storage system built around event-sourcing. Three components make up StreamSQL: Event Storage, Transformations, and Materialized State. The event storage is an immutable ledger of every domain event sent to our system. We serve the materialized state with similar APIs to Cassandra, Redis, and CockroachDB. Transformations are pure functions that map the events into the state. Every event that we receive is processed and applied to the materialized state, according to the transformation.
StreamSQL runs new transformations retroactively across all data. The end state is a true materialized of the entire event stream. Furthermore, you can generate a "virtual" state by rollbacking back and replaying events. The virtual state can be used to train and validate machine learning models, and for debugging purposes (like Redux for frontend development).
Requirements
The system needs to be able to do the following:
- Store every domain event in a system forever.
- Keep materialized state consistent by guaranteeing exactly-once processing of each incoming event.
- Be able to run transformations on all historical events in the same order that we received them.
- Rollback and replay the event ledger and materialize the views at that point.
The Original Kafka-Based Solution
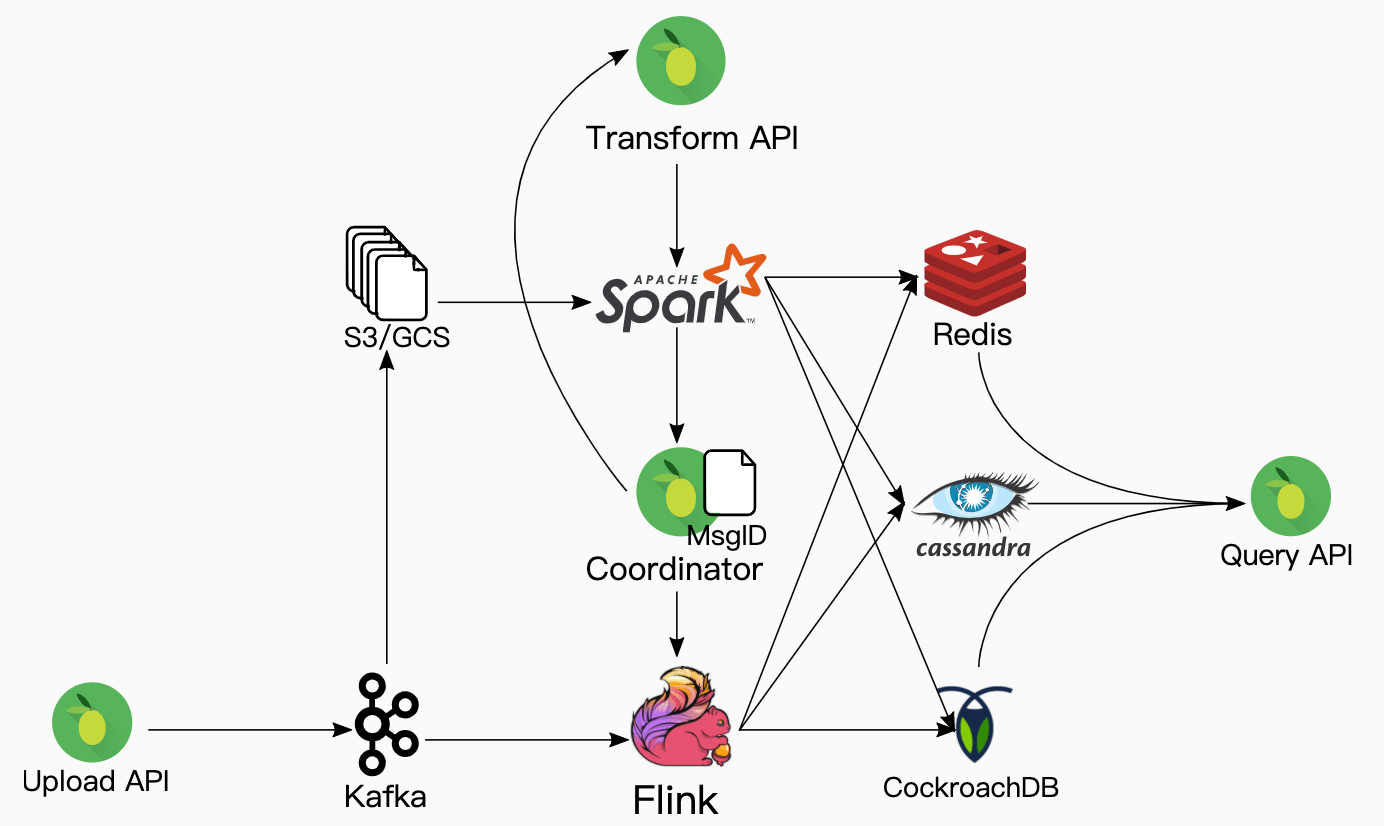
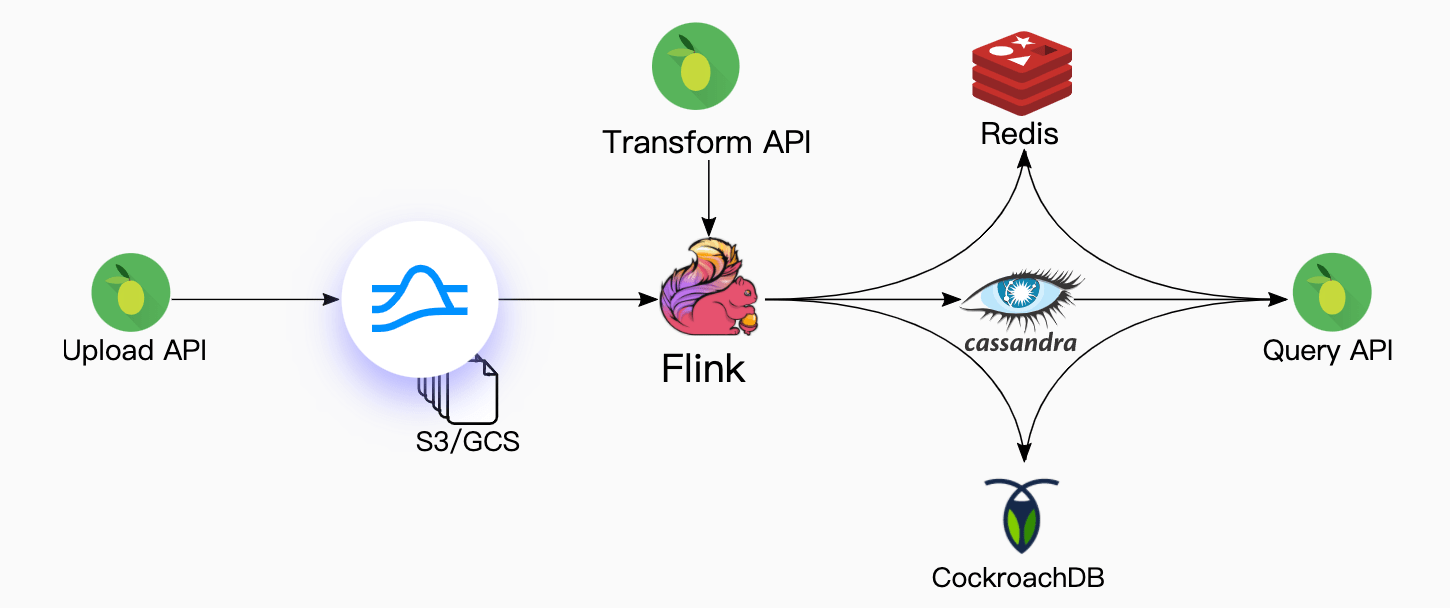
The original Kafka-Based solution consisted of a stitched-together set of big data tools. The system stored past events in S3 and processed them with Spark. For streaming data, it used Kafka and Flink. Keeping events and the materialized views consistent required complex coordination between each system.
Storing Every Domain Event Indefinitely
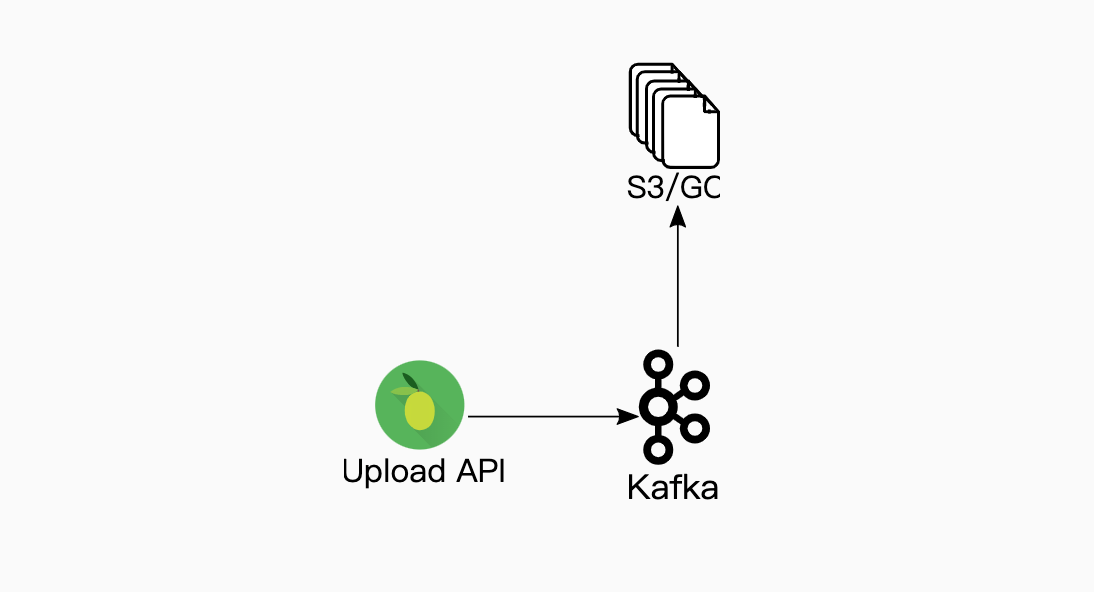
Every domain event would enter the system through Kafka which would then save it into S3. This allowed us to store large amounts of seldom used data with high durability and low cost.
We attempted to use Kafka’s infinite retention on streams but found it expensive and unmaintainable. We started to see performance degradation and volatile latencies on our larger topics. We did not investigate further since we were almost entirely moved onto to Pulsar.
Bootstrapping a Materialized View from Batch Data
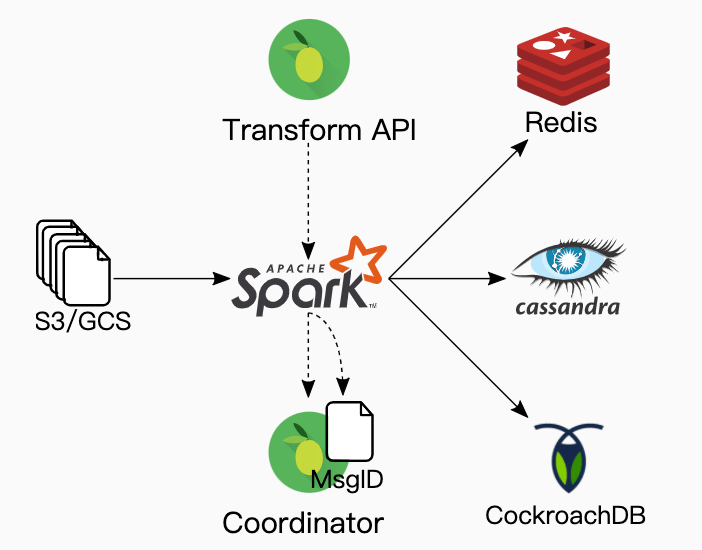
We materialize a view by processing every event in order. We use Spark to crunch through the majority of the historical data that's stored in S3. If we could pause events while this was happening, it would simplify things. In that situation, we could read all S3 data, then switch to processing Kafka at the head of the topic. In reality, there is a delay between events persisting into S3 from Kafka, and another one between swapping the large batch processing cluster to the smaller stream processing one. We can't afford to miss processing any events, so we use Spark to process as many events as possible in S3 and then have it return the last event's ID. Since we've configured Kafka to retain the last couple weeks of data, we can backfill the rest of the events off of Kafka.
Backfilling from Kafka
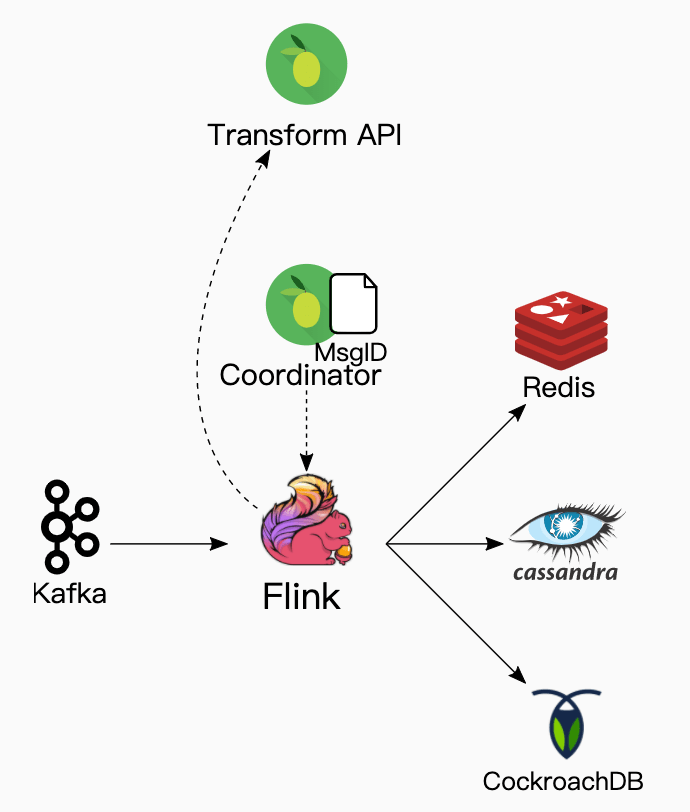
Spark was able to crunch through the majority of past events, but it does not get us to the latest state. To process the final set of past events, we've configured our Kafka cluster to retain the last two weeks of acknowledged events. We run a Flink job to continue the SQL transformation that Spark started. We point Flink at the first event in Kafka and have it read through, doing nothing until it reaches the messageID where Spark left off. From that point on, it continues to update the materialized view until it reaches the head of the stream. Finally, it notifies the Transformation API that the materialized view is up to date and ready to serve.
Updating on Incoming Events
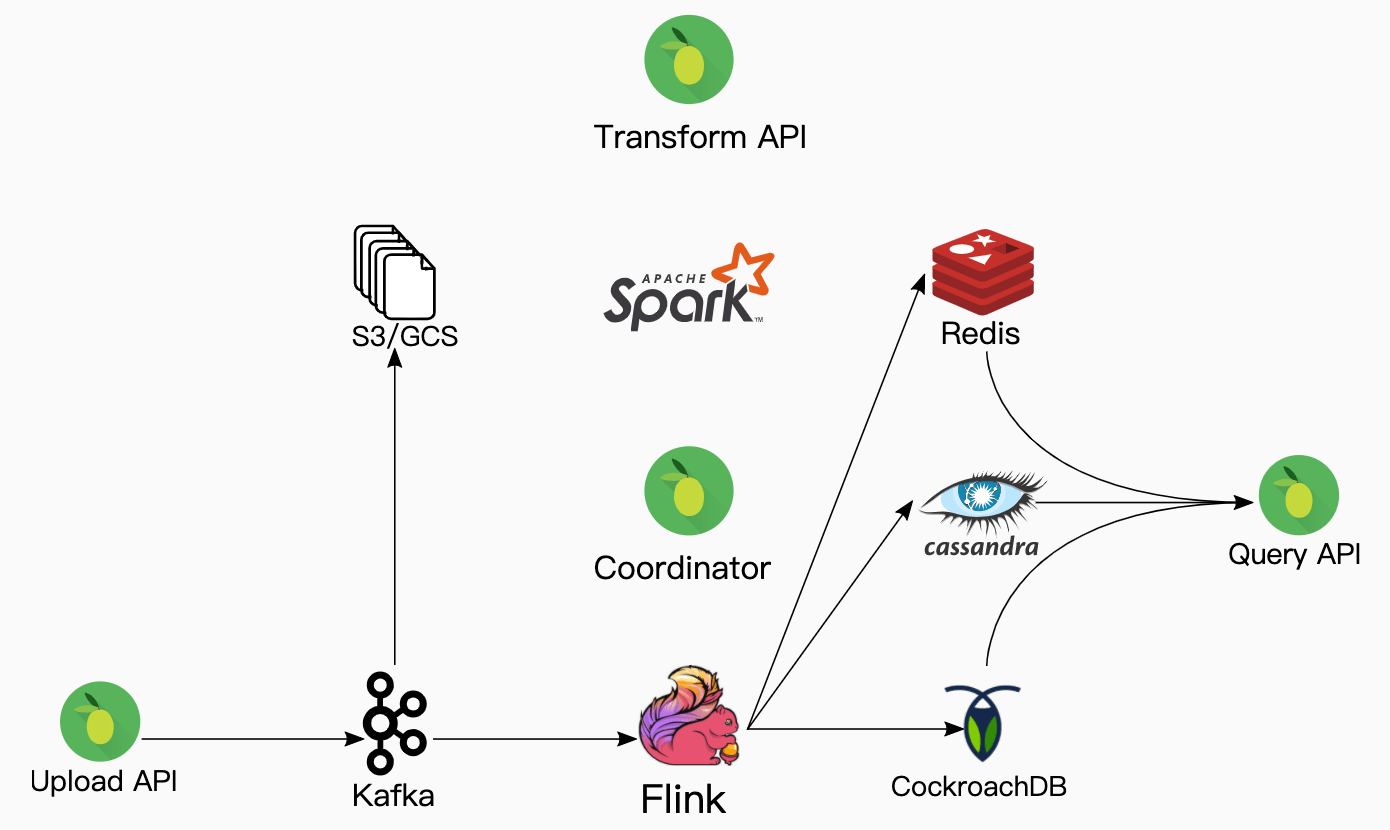
StreamSQL must keep the materialized views up to date once they are bootstrapped. At this point, the problem is trivial. Kafka passes each incoming event directly to Flink which then performs the necessary updates. The Transformation API and Spark are idle at this point. However, we still persist each incoming event into S3 in case a user updates or creates a transformation.
Multi-Tenancy, Rollback & Replay, Error Handling, etc.
We coordinate Flink and Kafka to work together in keeping snapshots of materialized views. With proper coordination, we can allow seamless rollback and replay functionality. Describing this process would require a blog post to itself (which we expect to write in the near future).
In this blog post, we also won't cover how we scaled our Flink and Kafka clusters, how we handled service failures, or how we were able to have secure multi-tenancy across all these different services (hint: each solution has a different answer). If you have a pressing need to know any of the above, feel free to reach out. We're happy to share.
Why Pulsar?
Pulsar was built to store events forever, rather than streaming them between systems. Furthermore, Pulsar was built at Yahoo! for teams building a wide variety of products across the globe. It natively supports geo-distribution and multi-tenancy. Performing complex deployments, such as keeping dedicated servers for certain tenants, becomes easy. We leverage these features wherever we can. This allowed us to hand off a significant portion of our custom logic into Pulsar.
Tiered Storage into S3
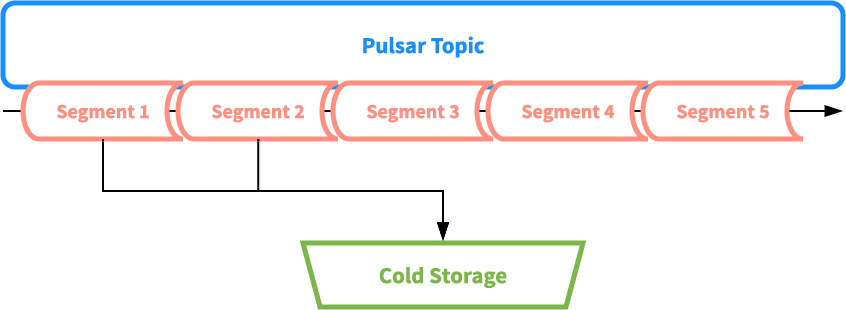
StreamSQL users can create a new materialized view at any time. These views must be a projection of all events, so every transformation processes each historical event in-order. In our Kafka-based solution, we streamed all acknowledged events into S3 or GCS. Then, a batch pipeline in Spark processed those events. The system as a whole required us to coordinate an event stream, batch storage, batch compute, stream compute, and stateful storage. In the real world, coordinating these systems is error-prone, expensive, and hard to automate.
If we could configure our event storage to keep events forever, it would allow us to merge together our batch and streaming pipelines. Both Pulsar and Kafka allow this; however, Kafka does not have tiered storage. This means all events would have to be kept on the Kafka nodes’ disks. The event ledger monotonically increases, so we would have to constantly add storage. Most historical events aren’t read very often, so the majority of our expensive disk storage sits dormant.
On the other hand, Apache Pulsar has built-in tiered storage. Pulsar breaks down every event log into segments, and offloads inactive segments to S3. This means that we get infinite, cheap storage with a simple configuration change to Kafka. We don’t have to constantly increase the size of our cluster, and we can merge our batch and stream pipelines.
We can configure Pulsar to offload events when a topic hits a specific size or we can run it manually. This gives us flexibility to set the right offload policy to balance cost and speed. We’re building machine learning models to fit our offload policy to each individual topic's specific needs.
Separate Compute and Storage Scaling
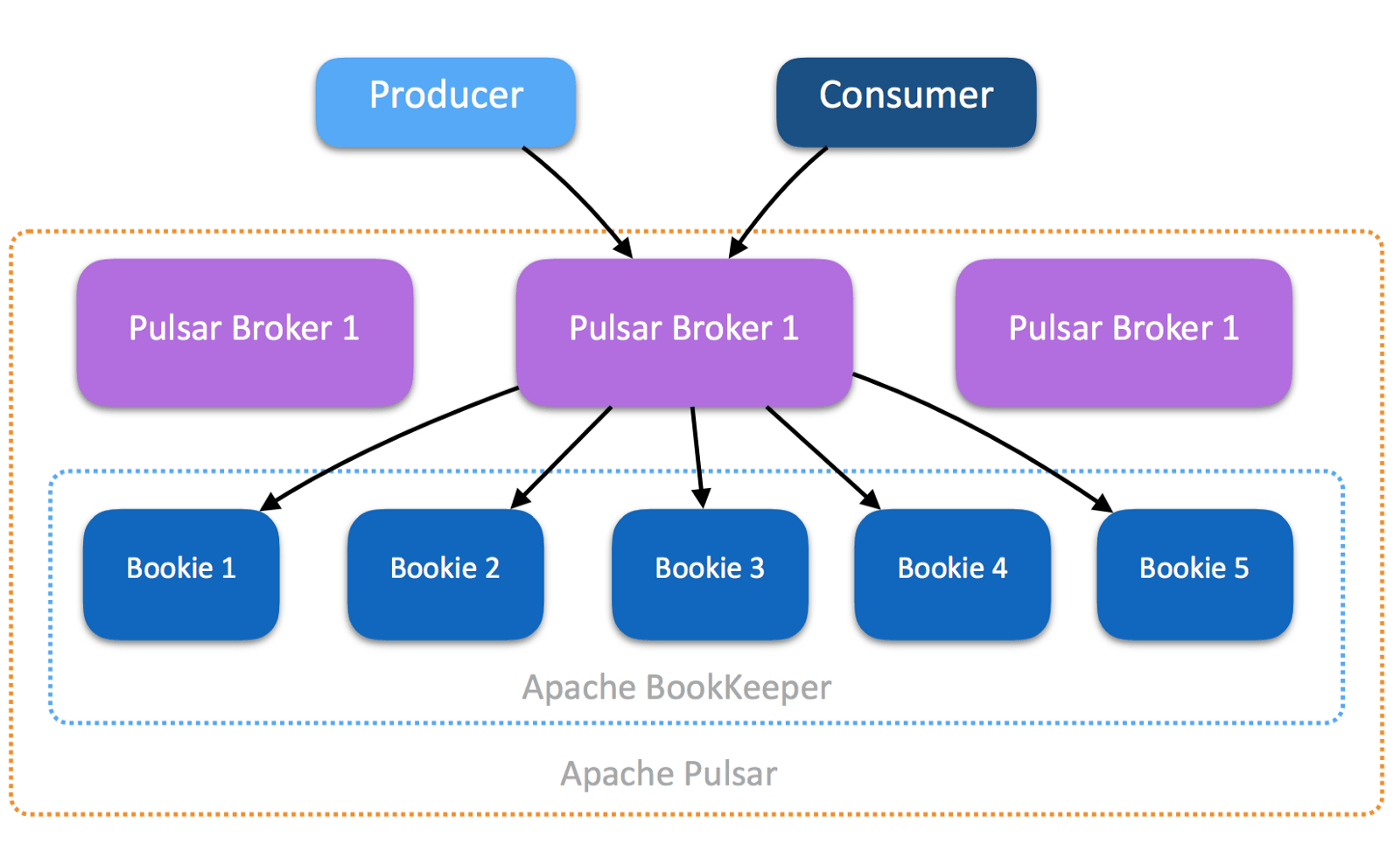
Our event volume and usage patterns vary widely throughout the day and across users. Each user's different usage patterns result in either heavier storage or compute usage. Luckily, Pulsar separates its brokers from its storage layer.
There are three different operations that Pulsar can perform: tail writes, tail reads, and historical reads. Pulsar writes, like Kafka’s, always go to the end of the stream. For Pulsar there are three steps in a write. First, the broker receives the request, then the broker writes it to Bookkeeper, and finally, it caches it for subsequent tail reads. That means that tail reads are very fast and don’t touch the storage layer at all. In comparison, historical reads are very heavy on the storage layer.
Adding storage nodes is relatively easy for both Kafka and Pulsar, but it is a very expensive operation. Data must be shuffled around and copied to properly balance the storage nodes. In Kafka’s case, brokers and storage exist on the same nodes, so any scaling operation is expensive. Contrastly, in Pulsar, brokers are stateless and are easy and cheap to scale. That means that tail reads do not pose a significant scale issue. we can fit our cluster to the current usage pattern of historical reads and tail reads.
Builtin Multi-tenancy
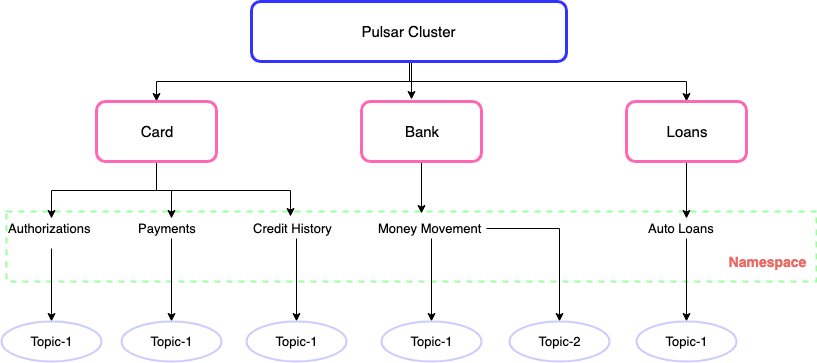
Pulsar was built with multi-tenancy baked in. At Yahoo!, many geographically distributed teams working on different products shared the same Pulsar cluster. The system had to handle keeping track of different budgets and various SLAs. It has a feature set that allows us to run all users on the same Pulsar cluster while maintaining performance, reliability, and security.
Every Pulsar topic belongs to a namespace, and each namespace belongs to a tenant. Every StreamSQL account maps to a tenant. Tenants are securely isolated from eachother. There is no way for one user to ever touch a different user’s streams.
The namespaces provide other interesting dynamics around isolation from a performance standpoint. We can isolate a user’s namespace to a specific set of brokers and storage nodes. This limits the effect a single user can have on a whole system. At the same time, we can set up automatic load shedding on the brokers so that a spike in a single client can be absorbed by the larger system.
Active and Responsive Community
The Pulsar community slack channel has been amazing. I receive answers to most of my questions almost immediately, and I’m always learning new things by keeping an eye on it. There are a handful of meetups and a Pulsar Summit as well for in-person learning and networking. We knew, in the worst case, we could reach out to relevant people and get help with even our most niche questions. The community gave us the confidence to move forward with Pulsar.
The Pulsar-Based Solution
Storing Every Domain Event Indefinitely
Pulsar allows us to store the entire immutable ledger in a Pulsar topic. We treat it as if it's all in Pulsar, but, under the hood, Pulsar offloads events into S3. We get the simplicity benefit of working with an event ledger, with the cost and maintenance benefit of putting events in S3. It all behaves better than our Kafka system without us having to maintain any of the complexity.
Bootstrapping a Materialized View from Batch Data
The Pulsar architecture merges our streaming and batch capabilities. This allows us to remove Spark and all the coordination code between Spark and Flink. The Pulsar -> Flink connector seamlessly swaps between batch and stream processing modes. The architecture's simplicity eliminates tons of edge cases, error handling, and maintenance costs that were present in the Kafka-based version.
Updating on Incoming Events
We write one job to handle both batch and streaming data. Without any coordination from us, Flink maintains exactly-once processing and swaps between its batch and streaming modes.
Drawbacks of Pulsar
Integrations
Pulsar has been around for almost as long as Kafka and was proven in production at Yahoo. We view Pulsar’s core as stable and reliable. Integrations are a different problem. There are a never-ending list of integrations to write. In most cases, the Pulsar community builds and maintains its integrations. For example, we wanted to set S3 as a sink and learned that no open-source connector existed. We built our own are open-sourcing our solution to push the community forward, but we expect to find into missing integrations in the future.
Given that Pulsar is nowhere near as popular as Kafka to date, a majority of the Pulsar integrations are built and maintained in the Pulsar repo. For example, the Flink connector that we use is in the Pulsar repo, but there is also an open Apache Flink ticket to build an one on their side as well. Until Pulsar becomes mainstream enough, there will continue to be missing integrations.
Lack of Public Case Studies
Almost all Pulsar content is published by hosted Pulsar providers like Streamlio (acq. by Splunk), Stream Native, and Kafkaesque. It’s quite uncommon to see a Pulsar case study by a company that’s using it in production at scale with no commercial ties to Pulsar. There are many large companies using it in production with it, but they seldom publish their experiences to the public. StreamNative posted a list of them here. Public case studies allow us to pick up tricks and gotchas without having to reinvent the wheel.
In comparison, there are plenty of case studies on Kafka. Kafka is the most prominent event streaming platform and continuing to gain popularity, so most companies that write about their data platform will go in-depth about how they use Kafka.
Infrastructure Liability
Our Pulsar deployment requires a Zookeeper cluster for metadata, a Bookkeeper cluster for storage, a broker cluster, and a proxy cluster. Even with AWS and Google Cloud services, this is a lot of maintenance liability. There are a huge number of configuration possibilities for Pulsar alone, but, when you look at the lower layers, it can call for multiple specialized engineers to maintain and optimize.
What’s Next?
Pulsar Functions
Currently, we use Flink to process streaming events and update our materialized views. Flink doesn't allow new nodes to be appended to a cluster. Instead, we have to save a checkpoint and restart the cluster with a larger size. Conversely, Pulsar functions are run in a separate compute cluster that we can be dynamically resized.
Flink's processing engine is much more expressive and powerful, but is far more complex to scale. Pulsar's is easy to scale, but far more limited. We will soon be able to categorize transformations and decide where to run them with a tendency towards Pulsar functions.
Streaming DAG
StreamSQL doesn't currently allow transformations to use materialized views as state. We are working on modeling the system as a DAG (Directed Acyclic Graph), as Airflow does. Unlike Airflow, the dependencies cannot be be performed in steps, every event would have to go through the entire DAG. Pulsar will make it much easier to maintain this guarantee as each event goes through the DAG.




