
Introduction
Tencent Angel PowerFL is a distributed federated learning platform which can support trillions of concurrent training. Angel PowerFL has been widely used in Tencent Financial Cloud, Advertising Joint Modeling, and other businesses. The platform requires a stable and reliable messaging system with guaranteed high performance and data privacy. After investigating different solutions and comparing several messaging queues, Angel PowerFL adopted Apache Pulsar as the data synchronization solution in Federated Learning (FL).
In this blog, the Tencent Angel PowerFL team shares how they built federated communication based on Pulsar, the challenges they encountered with Pulsar, and how they solved those problems and contributed to the Pulsar community. Tencent’s use of Pulsar in production has demonstrated it provides the stability, reliability, and scalability that the machine learning platform requires.
CONTENT
- About Tencent Angel PowerFL
- Requirements for Communication Services
- Stable and reliable
- High throughput and low latency
- Data privacy
- Why Apache Pulsar
- Layered and Segment-Centric Architecture
- Geo-replication
- Scalability
- Federated Communication Solution Based on Apache Pulsar
- Remove dependency on Global ZooKeeper
- Add token authentication for client
- Enable topic automatic recycle in multi-cluster
- Enable topic throttling
- Configure topic unloading
- Pulsar on Kubernetes
- Future Plans
- Conclusion
- Special Thanks
About Tencent Angel PowerFL
Federated learning (FL) is a machine-learning technique that trains statistical models across multiple decentralized edge devices, servers, or siloed data centers while keeping data localized. These decentralized devices collaboratively learn a shared prediction model while keeping the training data on the device instead of requiring the data to be uploaded and stored on a central server. As a result, organizations like the financial industry and hospitals that are required to operate under strict privacy constraints can also participate in model training.
Angel is a distributed machine-learning platform based on the philosophy of Parameter Servers (similar to a database, this is a core part of machine learning applications that is used to store the parameters of a machine learning model and to serve them to clients). Angel is tuned for performance with big data from Tencent and has gained a wide range of applicability and stability, demonstrating increasing advantages in handling higher-dimension models.
Tencent Angel PowerFL is built based on the Angel machine learning platform. Angel Parameter Server (Angel-PS) can support trillions of models that are training concurrently, so Angel PowerFL migrates computing from Worker (a logic component that processes a received task on a different thread, and gives you feedback via a call back method) to the Parameter Server (PS). Angel PowerFL provides basic operation interfaces such as computing, encryption, storage, and state synchronization for the federated learning algorithm, and it coordinates participants with process scheduler models. Angel PowerFL has been widely used in Tencent Financial Cloud, Tencent Advertising Joint Modeling, and other businesses.
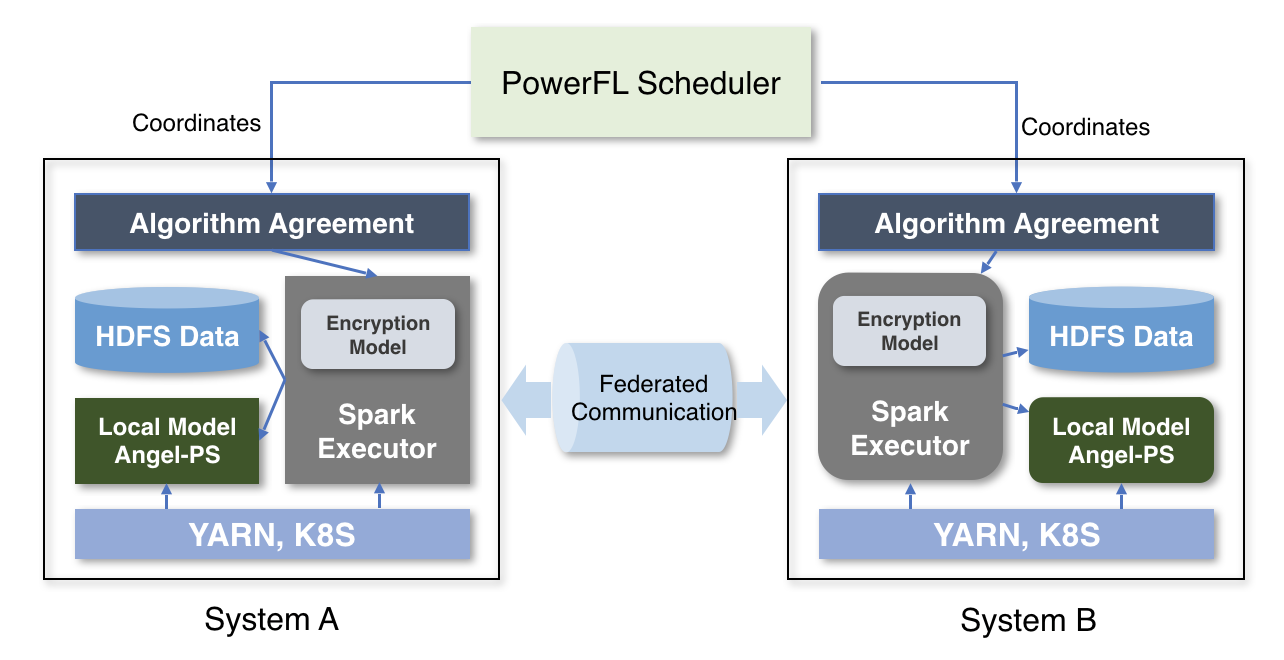
Requirements for Communication Services
During the federated training sessions, participants transfer a large amount of encrypted data via the communication model. Consequently, the Angel PowerFL platform requires a stable and reliable messaging system that provides high performance and ensures data privacy.
Stable and reliable
The federated learning tasks last from minutes to hours. The learning algorithms require accurate data, and the peak of data transmission varies for different algorithms. So we need stable and robust communication model services in order to avoid data loss.
High throughput and low latency
Angel PowerFL processes computing with Spark. The concurrent execution of Executors, which are processes that run computations and store data for your application, generates a lot of intermediate data. To transmit the encrypted data to other parties efficiently, the communication model must support low latency and high throughput.
Data privacy
Our participants in federated learning are distributed in different companies. Although all data is encrypted with the encryption model, transmitting them on a public network poses risks. As a result, we need a secure and robust communication model to protect data from being attacked in the public network.
Why Apache Pulsar
When we were researching solutions for federated communication services, we considered an RPC (Remote Procedure Call) direct connection, HDFS (Hadoop Distributed File System) synchronization, and MQ (messaging queue) synchronization. Since we have high requirements for security and performance, we decided to adopt the MQ synchronization solution. Several MQ options such as Apache Pulsar, Kafka, RabbitMQ, and TubeMQ were available. We consulted the MQ team from the Tencent Data Platform Department, who recommended Pulsar. Then, we conducted further research on Pulsar and found that the built-in features of Pulsar perfectly met our requirements for the messaging system.
Below, we summarize the points as to why Pulsar is the best fit for our federated communication.
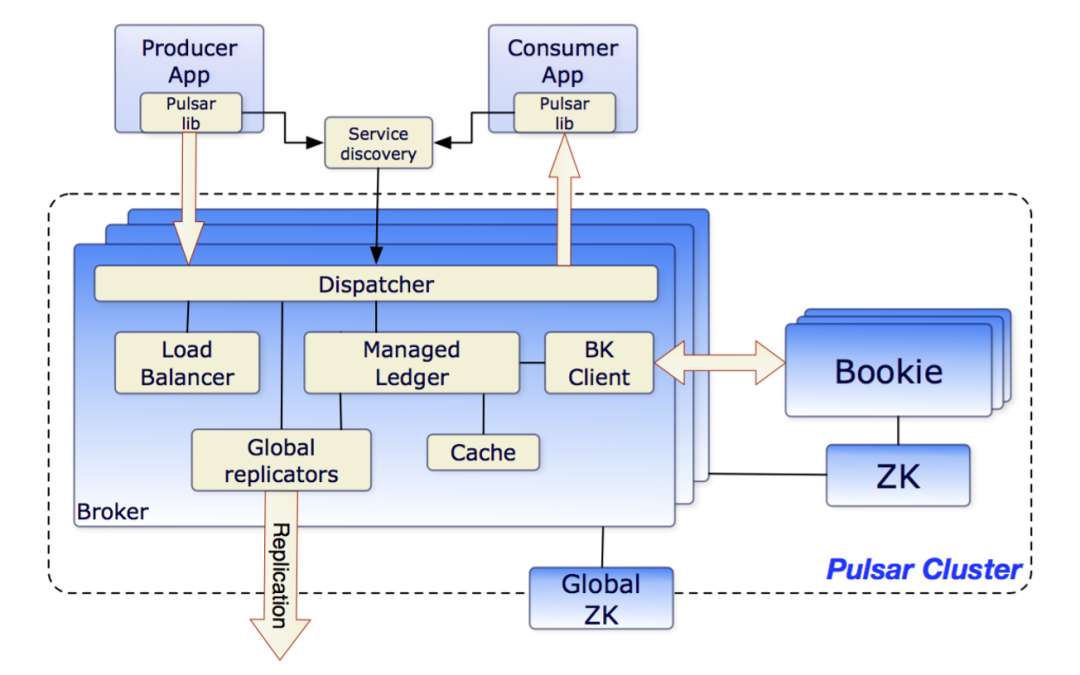
Layered and Segment-Centric Architecture
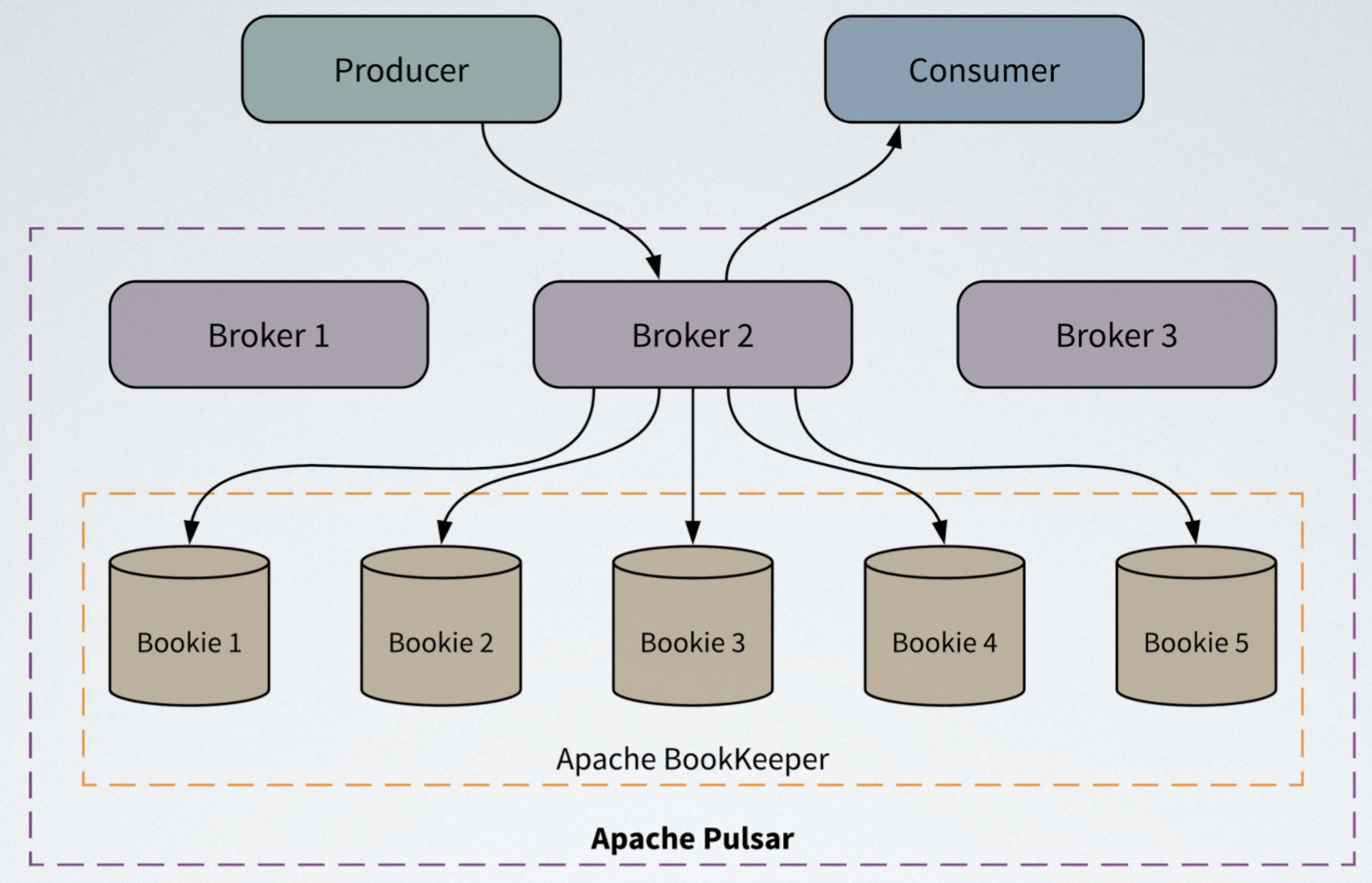
Apache Pulsar is a cloud-native distributed messaging and event-streaming platform that adopts layered architecture and decouples computing from storage. An Apache Pulsar cluster is composed of two layers: a stateless serving layer and a stateful storage layer. The serving layer consists of a set of brokers that receive and deliver messages, and the storage layer consists of a set of Apache BookKeeper storage nodes called bookies that store messages durably.
Compared to traditional messaging systems such as RabbitMQ and Kafka, Pulsar has a unique and differentiated architecture. Some unique aspects of Pulsar’s architecture include:
- Separate brokers from bookies and allow for independent scalability and fault tolerance, thus improving system availability.
- With segment-based storage architecture and tiered storage, data is evenly distributed and balanced across all bookies and the capacity is not limited by a single bookie node.
- BookKeeper is secure and reliable, ensuring no data loss. In addition, BookKeeper supports batch flashing and higher throughput.
Geo-replication
Pulsar provides built-in geo-replication for replicating data synchronously or asynchronously among multiple data centers, permitting us to restrict replication selectively. By default, messages are replicated to all clusters configured for the namespace. If we want to replicate messages to some specified clusters, we can specify a replication list.
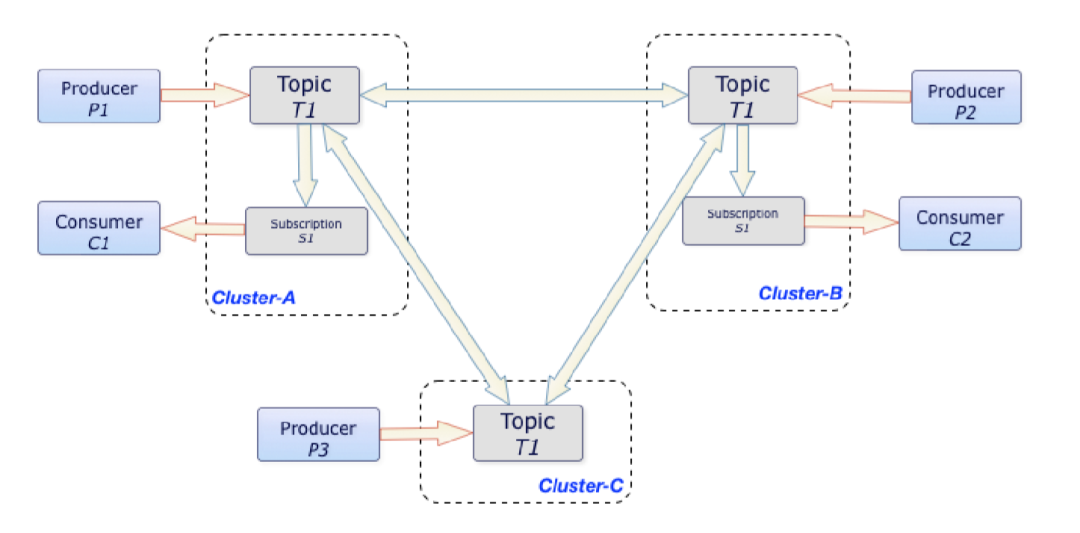
In the above figure, whenever P1, P2, and P3 producers publish messages to the T1 topic in Cluster-A, Cluster-B, and Cluster-C clusters respectively, those messages are instantly replicated across clusters. Once Pulsar replicates the messages, C1 and C2 consumers can consume those messages from their respective clusters.
Scalability
With the segment-based storage architecture, Pulsar divides the topic partition into smaller blocks called fragments. Each segment stores data as an Apache BookKeeper ledger, and the set of segments constituting the partition is distributed in the Apache BookKeeper cluster. This design makes it easier to manage capacity and scalability, and it meets our demand for high throughput. Let’s take a closer look at these elements:
- Easy to manage capacity: The capacity of the topic partition can be scaled to the entire BookKeeper cluster without being limited by the capacity of a single node.
- Easy to scale out: We do not need to rebalance or replicate data for scaling. When a new bookie node is added, it is used only for the new segment or its replica. Moreover, Pulsar rebalances the segment distribution and the traffic in the cluster.
- High throughput: The write traffic is distributed in the storage layer, so no partition write competes for the resources of a single node. Apache Pulsar’s multi-layer architecture and decoupling of the computing and storage layers provides stability, reliability, scalability, and high performance. Additionally, its built-in geo-replication enables us to synchronize messaging queues among parties across different companies. Finally, Pulsar’s authentication and authorization help ensure data privacy in transmission. These are all required features for Angel PowerFL and are why we decided to adopt Apache Pulsar in the Angel PowerFL platform.
Federated Communication Solution Based on Apache Pulsar
In Angel PowerFL, we identify each business as a Party, and each Party has a unique ID, such as 10000/20000. Those Parties are distributed in different departments of the same company (without network isolation) or in different companies (across public networks). Data from each Party is synchronized via Pulsar geo-replication. The following is our communication services design based on Apache Pulsar.
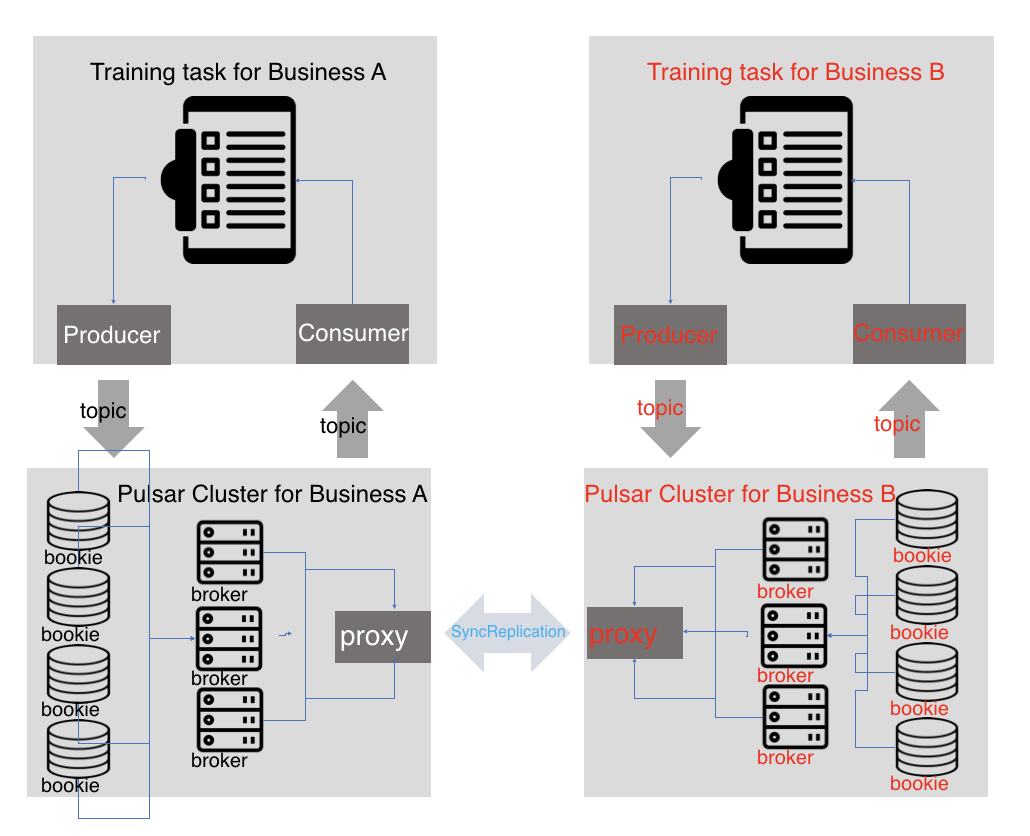
The FL training tasks are connected to the Pulsar cluster of the Party by the producer and consumer of the message. The cluster name follows the fl-pulsar-partyID pattern. After the training task generates intermediate data, the producer sends the data to the local Pulsar cluster, and then the Pulsar cluster sends data to the consuming Party via the Pulsar proxy synchronous replication network. The consumer of the consuming Party monitors the training topic, consumes data, and processes it.
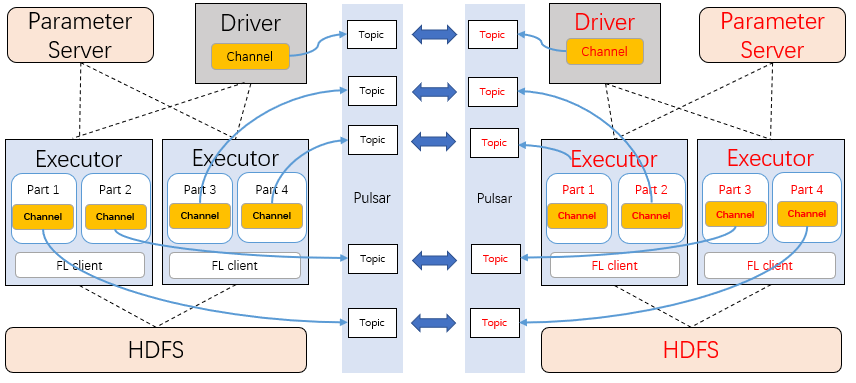
Figure 5: Angel PowerFL Federated Communication Data Streaming
During training, the driver and each partition create a channel variable, which maps a specific topic in Pulsar. The producer sends all exchange data to the topic.
Angel PowerFL supports multi-party federation, so data will be replicated synchronously in more than two clusters. Each FL task specifies participants in the task parameter, and the producer ensures data only transmits between participating Parties by calling the setReplicationClusters interface.
We make full use of Pulsar geo-replication, topic throttling, and token authentication in Angel PowerFL communication model. Next, I’ll introduce how we adopt Pulsar in Angle PowerFL in detail.
Remove dependency on Global ZooKeeper
In Angel PowerFL platform, we rely on Local ZooKeeper and Global ZooKeeper to deploy a Pulsar cluster. Local ZooKeeper is used to store metadata, similar to the method used in Kafka. Global ZooKeeper shares configuration information among multiple Pulsar clusters.
Every time we add a new Party to Angel PowerFL, we have to deploy a sub-node for Global ZooKeeper or share the public ZooKeeper among different companies or regions. Consequently, adding a new Party makes it more difficult to deploy a cluster and protect data from being attacked.
The metadata stored in Global ZooKeeper include cluster name, service address, namespace permissions, and so on. Pulsar supports creating and adding new clusters. We register the federated Pulsar clusters to the local ZooKeeper in the following steps, thereby removing dependency on Global ZooKeeper.
- Step 1: Register the Pulsar cluster for the newly added Party
# OTHER_CLUSTER_NAME is the Pulsar cluster name of the Party to be registered
# OTHER_CLUSTER_BROKER_URL is the broker address of the Pulsar cluster
./bin/pulsar-admin clusters create ${OTHER_CLUSTER_NAME} \
--url http://${OTHER_CLUSTER_HTTP_URL} \
--broker-url pulsar://${OTHER_CLUSTER_BROKER_URL}
- Step 2: Authorize the namespace used for training to access the cluster
./bin/pulsar-admin namespaces set-clusters fl-tenant/${namespace} \
-clusters ${LOCAL_CLUSTR_NAME},${OTHER_CLUSTER_NAME}
We register the newly added Party with its Pulsar cluster name/service address, and replicate data synchronously with the registration information through geo-replication.
Add token authentication for client
As the communication model of Angel PowerFL, Pulsar has no permission control on the user level. To ensure the client produces and consumes data securely, we add token authentication according to Pulsar Client authentication using tokens based on JSON Web Tokens. Then, we need to configure the service address of the current Party and admin token for training tasks. Since Angel PowerFL is deployed on Kubernetes, we generate the Public/Private keys required by the Pulsar cluster in the container and then register them to K8S secret.
# generate fl-private.key and fl-public.key
docker run --rm -v "$(pwd)":/tmp \
apachepulsar/pulsar-all:2.5.2 \
/pulsar/bin/pulsar tokens create-key-pair --output-private-key \
/tmp/fl-private.key --output-public-key /tmp/fl-public.key
# generate `admin-token.txt token` file
echo -n `docker run --rm -v \
"$(pwd)":/tmp apachepulsar/pulsar-all:2.5.2 \
/pulsar/bin/pulsar tokens create --private-key \
file:///tmp/fl-private.key --subject admin`
# register authentication to K8S
kubectl create secret generic token-symmetric-key \
--from-file=TOKEN=admin-token.txt \
--from-file=PUBLICKEY=fl-public.key -n ${PARTY_NAME}
Enable topic automatic recycle in multi-cluster
When geo-replication is enabled for the Pulsar cluster, we cannot delete topics that are used with commands directly. Angel PowerFL training tasks are disposable, so we need to recycle those topics after usage and free space in time. So, we configure the brokerDeleteInactivetopicsEnabled parameter to recycle topics replicated through geo-replication and make sure that:
- The topic is not connected to any producer or consumer.
- The topic is not subscribed.
- The topic has no message retention. We recycle topics automatically in Pulsar clusters every three hours by configuring the brokerDeleteInactivetopicsEnabled and brokerDeleteInactivetopicsFrequencySeconds parameters.
Enable topic throttling
During federated training, the data traffic peaks vary for different data sets, algorithms, and execution. The largest data volume of a task in the production environment is over 200G/h. If Pulsar is disconnected or an exception occurs in the production or consumption process, we have to restart the whole training process.
To reduce this risk, we adopted Pulsar throttling. Pulsar supports message-rate and byte-rate throttling policies on the producer side. Message-rate throttling limits the number of messages produced per second, and byte-rate throttling limits the size of messages produced per second. In Angel PowerFL, we set message size as 4M and limit the number of messages to 30 for namespace through message-rate throttling (under 30*4 = 120 M/s).
./bin/pulsar-admin namespaces set-publish-rate fl-tenant/${namespace} -m 30
When we tested on message-rate throttling initially, it did not work well. After debugging with the MQ team from Tencent Data Platform Department, we found that the throttling did not take effect if we configured the topicPublisherThrottlingTickTimeMillis parameter. Then, we enabled the precise topic publishing rate throttling on the broker side and contributed this improvement to the Pulsar community. For details, refer to PR-7078: introduce precise topic publish rate limiting.
Configure topic unloading
Pulsar assigns topics to brokers dynamically based on the load of the brokers in the cluster. If the broker owning the topic crashes or is overloaded, the topic is reassigned to another broker immediately; this process is termed topic unloading. Topic unloading means to close the topic, release the ownership, and reassign the topic to a less-loaded broker. Topic unloading is adjusted by load balance, and the client will encounter slight jitter, which usually lasts for about 10 ms. However, when we started training at the early stage, a lot of connection exceptions occurred due to topic unloading. The following is a part of the log information.
[sub] Could not get connection to broker: topic is temporarily unavailable -- Will try again in 0.1 s
To resolve the issue, we further explored broker, namespace, bundle, and topic. Bundle is a fragmentation mechanism of the Pulsar namespace. The namespace is fragmented into a list of bundles, and each bundle contains a part of the hush of the namespace. Topics are not directly assigned to the broker. Instead, each topic is assigned to a specific bundle by the hush of the topic. The bundles are independent of each other and are assigned to different brokers.
We did not reuse the training topics at an early stage. To train an LR algorithm, 2,000+ topics were created, and the data load produced by each topic varied. We suspected that creating and using many topics in a short period would lead to an unbalanced load and frequent topic unloading. To reduce topic unloading, we adjusted the following parameters for the Pulsar bundle.
# increase the maximum number of topics that can be distributed by the broker
loadBalancerBrokerMaxTopics=500000
# enable automatic namespace bundle split
loadBalancerAutoBundleSplitEnabled=true
# increase the maximum number of topics that triggers bundle split
loadBalancerNamespaceBundleMaxTopics=10000
# increase the maximum number of messages that triggers bundle split
loadBalancerNamespaceBundleMaxMsgRate=10000
Meanwhile, we set the default number of bundles to 64 when creating a namespace.
./bin/pulsar-admin namespaces create fl-tenant/${namespace} --bundles 64
After adjusting the configuration, we solved the frequent topic unloading issue perfectly.
Pulsar on Kubernetes
All services of Angel PowerFL are deployed on Kubernetes through Helm. As one of the charts, Pulsar leverages K8S resource isolation, scalability, and other advantages. When deploying Pulsar with Helm, we use Local Persistent Volume as storage, use NodeSelector in geo-replication, and configure useHostNameAsBookieID in bookies.
Use Local Persistent Volume as storage
Pulsar is sensitive to IO, especially the bookies. It is recommended to use SSD or separate disks in production environments. When we ran tasks with big data sets in Angel PowerFL, “No Bookies Available” exceptions occurred frequently due to high IO utility. With Local Persistent Volume, we mounted bookie, ZooKeeper, and other components to a separate disk and reduced IO competition. We tried to replace Pulsar PV storage with Ceph and NFS, and we found that the performance was best when using Local Persistent Volume.
Use NodeSelector
The broker needs to access the Pulsar proxy container of the other party while replicating data synchronically with geo-replication. In Angel PowerFL, we label the gateway machine separately and install the broker on the gateway machine that has access to the external network through NodeSelector.
Configure useHostNameAsBookieID
Bookie is stateful. We configure useHostNameAsBookieID after rebuilding the bookie pod, ensuring the ID registered on ZooKeeper is the hostname of the pod.
Future Plans
We’ve been using Apache Pulsar in Angel PowerFL for a year, and we’ve run Pulsar clusters in our production environment for over 8 months. It’s stable and reliable, and we’d like to upgrade our Pulsar cluster and improve Pulsar on K8S.
Upgrade Pulsar to 2.6.x
Currently, we are using Pulsar 2.5.2 and would like to backup Angel-PS failover recovery with Pulsar Key_Shared subscription mode. The Key_Shared subscription mode is enhanced in Pulsar 2.6.0 (https://github.com/apache/pulsar/pull/5928), so we hope to upgrade Pulsar to 2.6.x.
Support multi-disk mounting for Pulsar on K8S
All Angel PowerFL services are running on Kubernetes—except the YARN computing resources. As one of the charts, Pulsar is deployed with other services and uses Local Persistent Volume as storage. Currently, only one disk (directory) can be mounted on the bookie, so we could not make full use of machines with multiple disks. To address this need, we have a plan to mount multiple disks on the bookie.
Conclusion
I’ve introduced how we adopted Pulsar in the Angel PowerFL platform. We leverage Pulsar features and improve Pulsar functionalities and performance based on our demands.
As a cloud-native distributed messaging and event-streaming platform, Pulsar has many outstanding features and has been widely used in live broadcast and short video platforms, retail and e-commerce businesses, media, finance, and other industries. We believe that Pulsar’s adoption and community will continue to expand.
Special Thanks
Thanks to the MQ team at the Tencent Data Platform Department for their support and guidance. The MQ team is experienced in Apache Pulsar and TubeMQ and has made great contributions to the Apache Pulsar community. Apache Pulsar is a young, active community that enjoys rapid growth. We’d like to work with the Pulsar community, make contributions, and build a more thriving community.




