
Apache Pulsar has been a pioneer in introducing the concept of tiered storage. This feature, which has also been adopted by competitors like Kafka, Confluent, and Redpanda, has become a cornerstone for many companies, including tech giants like Tencent, in their pursuit of cost-effective long-term data storage. However, while tiered storage has been a game-changer, it was initially implemented using Pulsar's proprietary storage format. This approach comes with inherent limitations that restrict the full potential of Apache Pulsar. In response, we've taken a bold step by adopting open industry-standard storage formats, a move we believe will greatly benefit Apache Pulsar users.
We are thrilled to introduce Pulsar's Lakehouse Tiered Storage as a Private Preview feature on StreamNative Cloud. With this feature, well-known lakehouse storage solutions like Delta Lake, Apache Hudi, and Apache Iceberg become the tiered storage layer for Apache Pulsar. This development effectively transforms Apache Pulsar into a Streaming Lakehouse, allowing you to ingest data directly into your lakehouse using popular messaging and streaming APIs and protocols such as Pulsar, Kafka, AMQP, and more.
This series of blog posts will delve deep into the details of Pulsar’s Lakehouse Tiered Storage. In this first post, we will explore the origins of Pulsar’s tiered storage and how we’ve evolved it into a Lakehouse tiered storage solution. The second blog post will provide a comprehensive look at the implementation details of Lakehouse Tiered Storage, and we will conclude this series with a discussion on how data query engines can leverage the power of Lakehouse Tiered Storage to achieve unified stream and batch processing.
Let’s dive right into it.
Tiered Storage: Optimizing Data Storage Costs for Streaming Infrastructure
Apache Pulsar has always stood out for its ability to decouple storage from computing, allowing for independent scaling between stateless serving and stateful storage. The architecture's multi-layer structure is illustrated below.
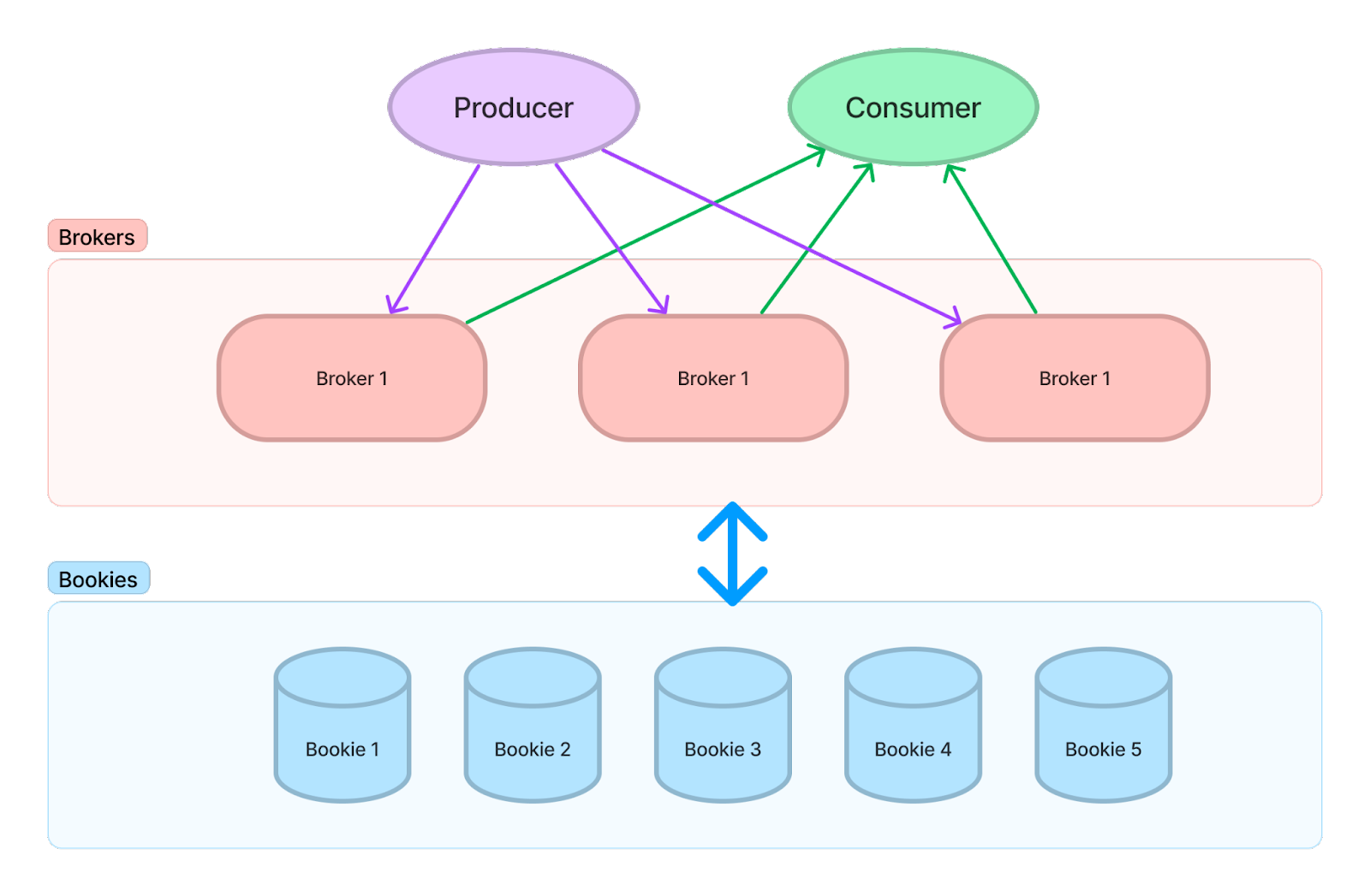
Pulsar's storage layer is built on Apache BookKeeper, known for its robust, scalable log storage capabilities. It employs a quorum-based parallel replication mechanism, ensuring high data persistence, repeatable consistent reads, and high availability for both reading and writing. BookKeeper is particularly effective when used with high-performance disks like SSDs, providing low-latency streaming reads without compromising write latency.
However, as organizations seek to retain data for extended periods, the volume of data stored in BookKeeper can result in higher storage costs. Take WeChat, for example; only 1% of WeChat's use cases demand real-time data processing, characterized by message lifecycles of less than 10 minutes. In contrast, 9% of use cases necessitate catch-up reads and batch processing, relying on data freshness within a 2-hour window. The remaining 90% of use cases revolve around data replay and data backup, spanning data older than 2 hours.
This pattern is common across enterprises. If we were to keep all the data of varying lifecycle requirements in the same storage layer, it would pose a large cost challenge. A natural approach to get around this is to move this 90% of data into a cold storage tier backed by much cheaper storage options such as object storage (S3, GCS, Azure Blob storage) or on-premise HDFS. Thus, we introduced Tiered Storage to Apache Pulsar in 2018, creating an additional storage layer.
With the introduction of the Tiered Storage layer, Pulsar could separate data based on its lifecycle:
- Hot Data (~1% of data): Cached in Brokers' memory for low-latency streaming.
- Warm Data (~9% of data): Stored in BookKeeper with replication for high availability . This data eventually gets moved to cold storage.
- Cold Data (~90% of data): Tiered and stored in cost-efficient object storage .
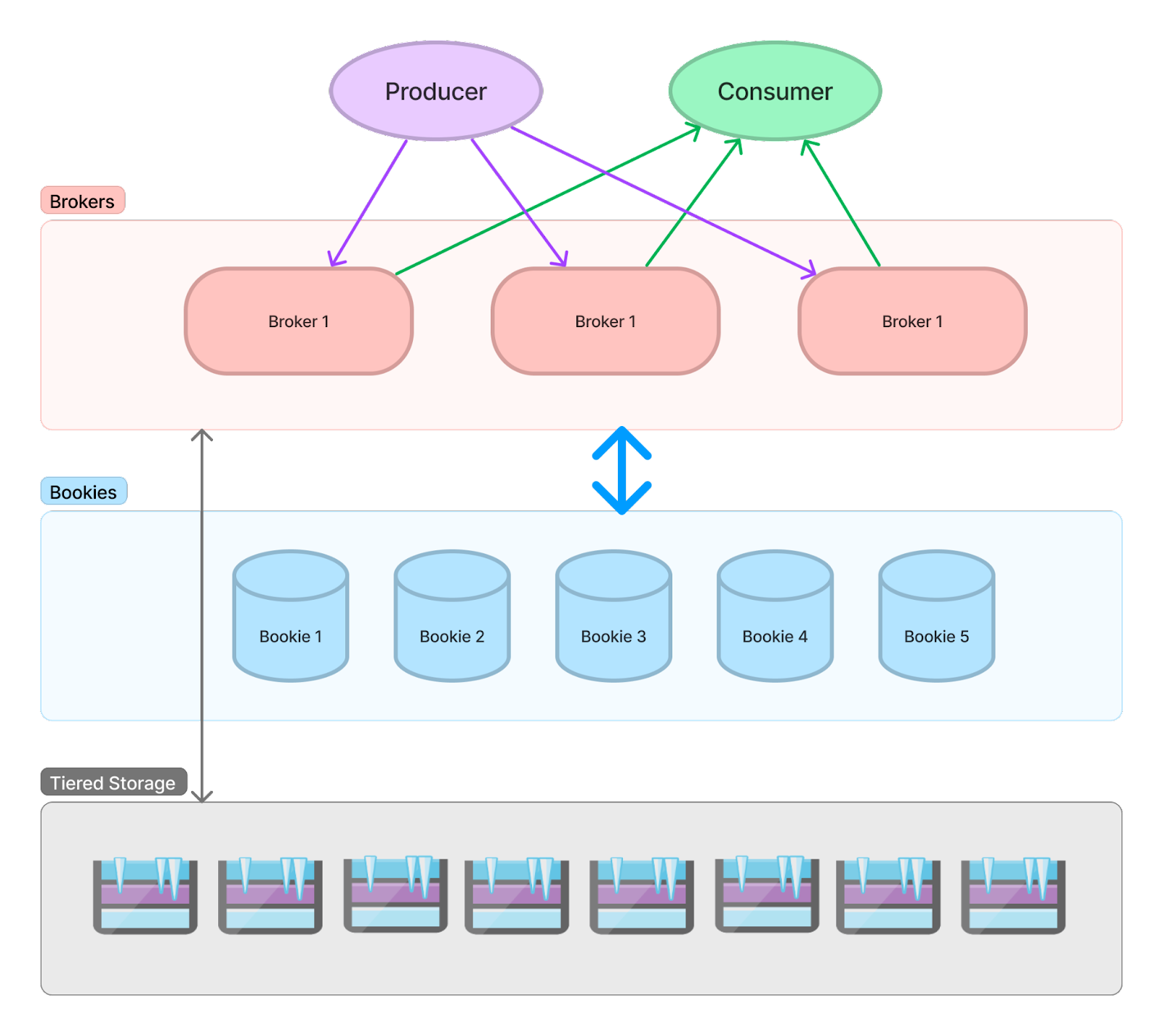
Pulsar's tiered storage was introduced with Pulsar 2.2.0, using a segmented stream model. When a segment in Pulsar is sealed, it's offloaded to tiered storage based on configured policies. Data is stored in Pulsar's format with additional indices for efficient reading. Unlike some other tiered storage solutions, Pulsar's approach allows brokers to read directly from tiered storage, saving memory, bandwidth, and cross-zone traffic.
However, while Pulsar's tiered storage is cost-effective and enhances stability, it has certain limitations:
- Proprietary Format: Data is stored in a proprietary format, making integration with broader data processing ecosystems challenging.
- Lakehouse Integration: Ingesting data into a lakehouse system requires additional effort and typically relies on tools like the Pulsar Lakehouse IO connector.
- Performance Tuning: Substantial tuning efforts are needed for optimizing read performance across various workloads due to the proprietary format.
- Lack of Schema Information: Offloaded data lacks schema information, necessitating schema retrieval via reading data from Pulsar brokers, increasing costs and limiting integration possibilities.
What is the Ideal Tiered Storage?
So, what is the ideal tiered storage for Pulsar and data streaming? In our opinion, in addition to high performance and cost savings, the ideal tiered storage solution for Pulsar and data streaming should offer:
- Schema Enforcement and Governance: The ability to reason about data schema and integrity without involving Pulsar brokers, with robust governance and auditing features.
- Openness: An open, standardized storage format with APIs that allow various tools and engines to access data effectively.
- Cost Efficiency: Reduced data size for storage and transfer, resulting in cost savings in storage and data transfer.
Does such an ideal tiered storage solution exist? The answer is yes. Lakehouse is the solution.
Introducing Lakehouse
Lakehouse represents a transformative approach to data management, merging the best attributes of data lakes and traditional data warehouses. Lakehouse combines data lake scalability and cost-effectiveness with data warehouse reliability, structure, and performance. Three key technologies—Delta Lake, Apache Hudi, and Apache Iceberg—play pivotal roles in the Lakehouse ecosystem.
Delta Lake ensures data integrity and ACID compliance within data lakes, enabling reliable transactions and simplified data management. Apache Hudi offers upsert capabilities, making it efficient to handle changing data in large-scale datasets. Apache Iceberg provides a table format abstraction that improves data discoverability, schema evolution, and query performance. Together, these technologies form the core of the Lakehouse ecosystem, facilitating a harmonious balance between data storage, reliability, and analytical capabilities within a single, unified platform.
The Lakehouse aligns with the criteria for an ideal tiered storage solution:
- Schema and Schema Evolution: They offer tools for managing schema and schema evolution.
- Stream Ingest and Transaction Support: They support streaming data ingestion with transactional capabilities and change streams.
- Metadata Management: These solutions excel in managing metadata for vast datasets.
- Open Standards: Lakehouse technologies are open standards, enabling seamless integration with various data processing systems.
Introducing Pulsar’s Lakehouse Tiered Storage
Pulsar's Lakehouse Tiered Storage takes the form of a streaming tiered storage offloader. This offloader can operate within the Pulsar broker or as a separate service in Kubernetes. It streams messages received by the broker to the Lakehouse immediately upon reception. Data offloaded to the tiered storage can be read by the broker in a streaming manner or accessed directly by external systems such as Trino, Spark, Flink, and others.
The lifecycle management of offloaded data can be handled either by Pulsar in Managed mode or by external Lakehouse systems in External mode. With Lakehouse tiered storage, you can store data for extended periods in a cost-efficient manner.
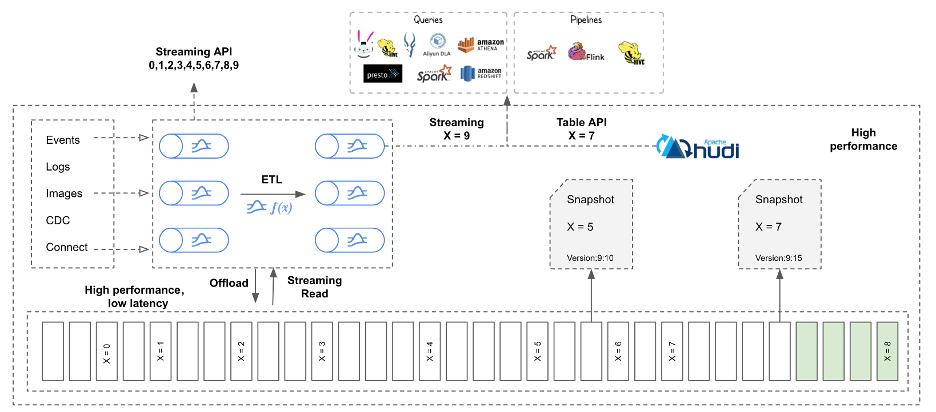
Pulsar's Lakehouse Tiered Storage has effectively transformed Apache Pulsar into an infinite streaming lakehouse. In this streaming lakehouse, you can retain infinite streams and access them through two distinct APIs:
- Streaming API: Continue using popular streaming protocols like Pulsar and Kafka APIs to ingest and consume data in real time.
- Table/Batch API: Query the data that has been offloaded into your Lakehouse using external query engines such as Spark, Flink, and Trino, or managed cloud query engines like Snowflake, BigQuery, and Athena.
This approach not only accommodates existing streaming and batch applications but also enables query engines to combine both streaming and batch data for unified batch and stream processing—a concept that offers endless possibilities for data analytics and insights. At the upcoming Pulsar Summit North America 2023, Yingjun Wu, Founder and CEO of Risingwave, will demonstrate how Risingwave leverages this combination to unlock new capabilities in querying both streaming and historical data together.
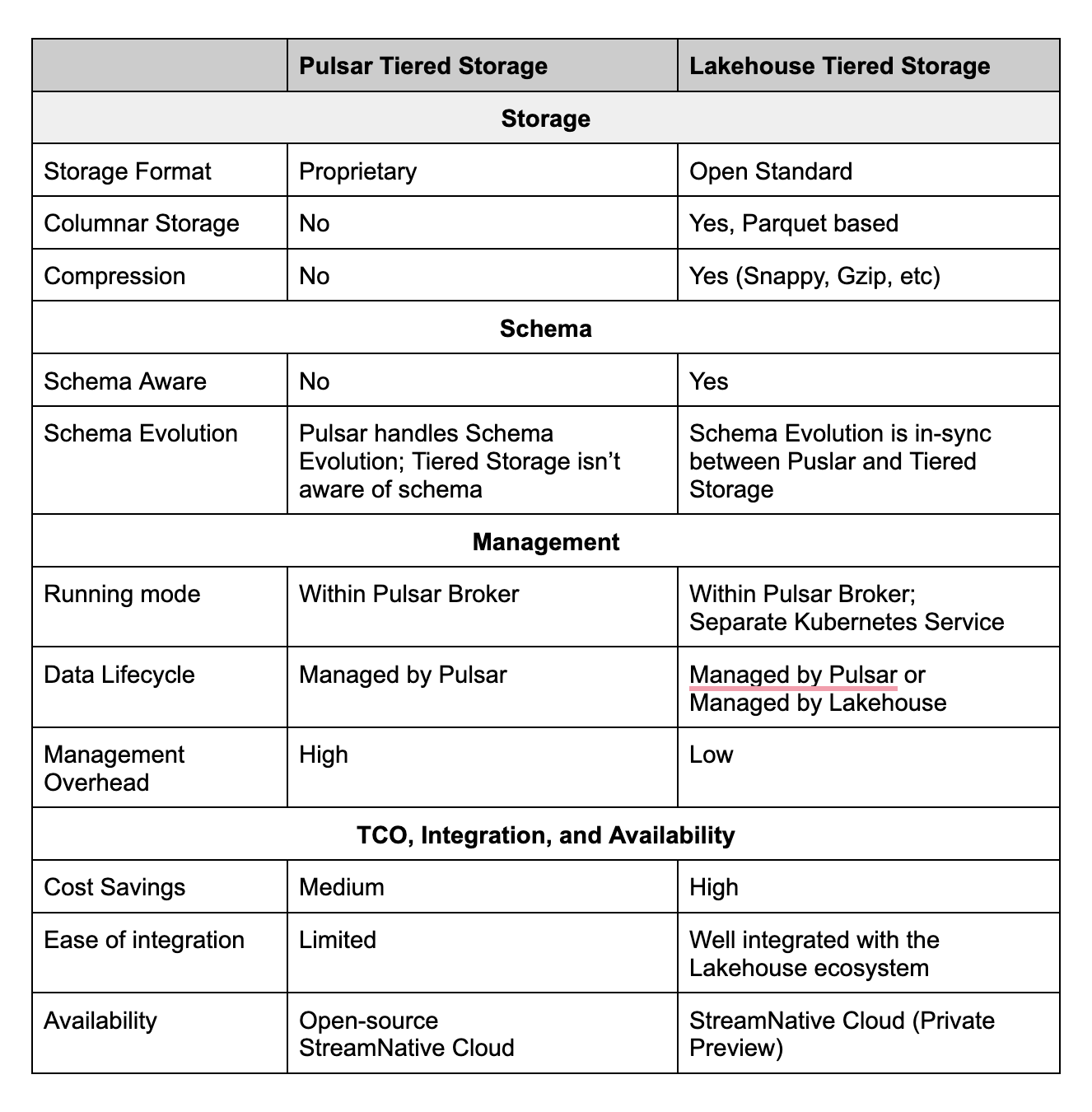
Pulsar Tiered Storage vs. Lakehouse Tiered Storage
Besides using an open storage format standard, Lakehouse Tiered Storage has many differentiators compared to the existing Pulsar tiered storage. Those differentiators are highlighted in the following table:
Additional Benefits of Lakehouse Tiered Storage
With the Lakehouse tiered storage, you can enjoy additional benefits compared to the existing tiered storage implementations.
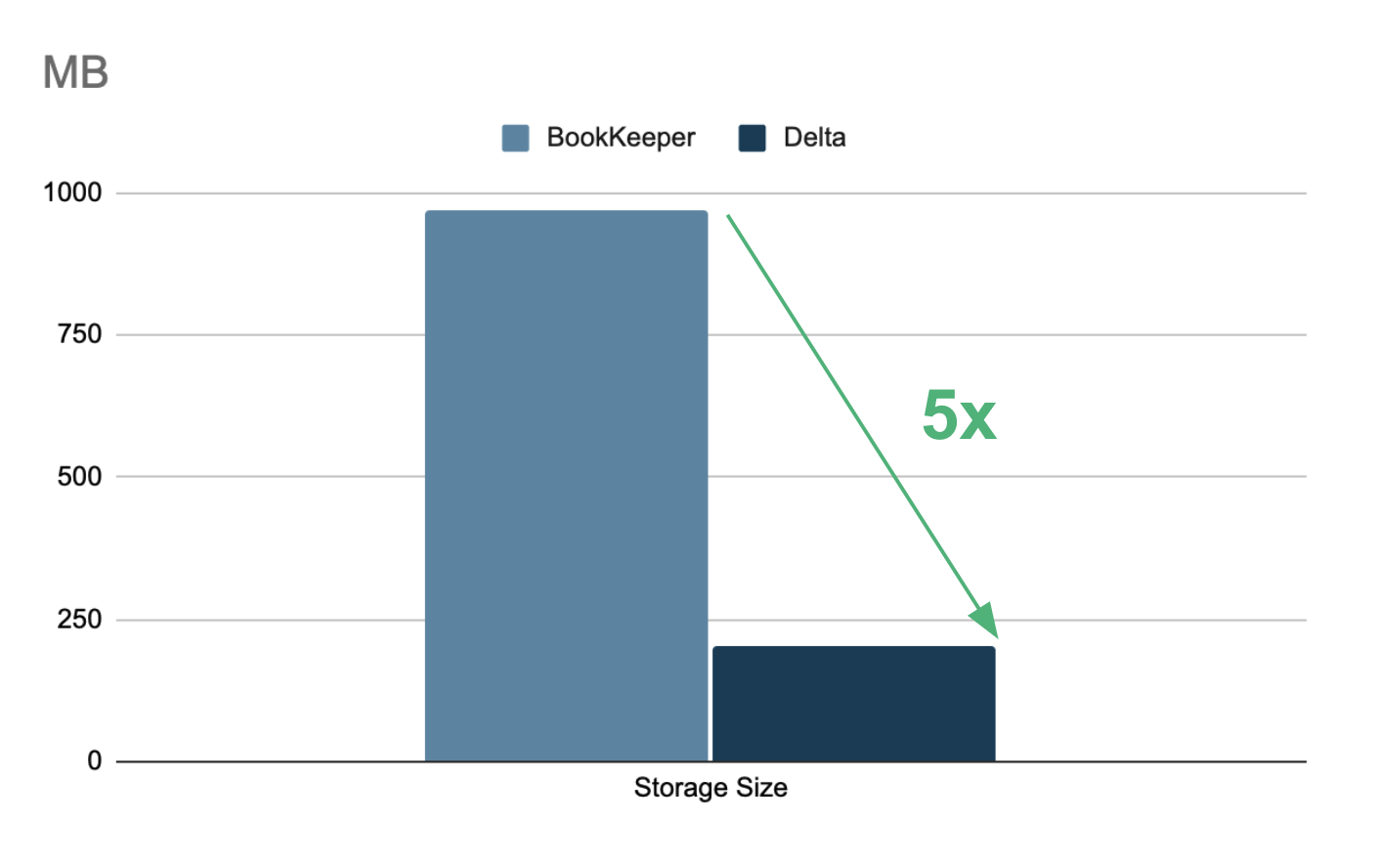
Cost Reduction: By leveraging schema information to convert row-based message data into columnar formats stored in Parquet within the Lakehouse, storage sizes are drastically reduced, resulting in significant cost savings. In tests, we achieved a 5x reduction in storage size compared to retaining data in BookKeeper or tiered storage using Pulsar's format.
Bandwidth Savings: Reduced data retrieval from tiered storage results in lower network bandwidth usage. External processing engines can directly access data from Lakehouse storage, further reducing networking costs.
Extended Data Retention: Lakehouse Tiered Storage enables cost-effective long-term data retention, opening up numerous use cases previously hindered by data retention limitations in Pulsar. It facilitates effective batch access through Lakehouse storage formats, allowing seamless data processing with real-time streaming and historical batch data.
Lakehouse Tiered Storage: Private Preview on StreamNative Cloud
Lakehouse Tiered Storage is now available for Private Preview on StreamNative Cloud, specifically for BYOC clusters. If you're interested in trying it out, please contact us. Your feedback will be invaluable as we continue to refine and enhance the tiered storage solution. Whether you're a Lakehouse vendor, a data processing or streaming SQL vendor, or an Apache Pulsar user, we welcome collaboration to define and iterate APIs for processing and querying data in this exciting realm of the "Streaming Lakehouse".
Summary
Tiered storage is the linchpin for cost-efficient data streaming in the cloud. However, most vendors tend to develop their proprietary storage formats for offloading data to cloud-native object stores, limiting integration possibilities. The introduction of Lakehouse Tiered Storage breaks down these silos, connecting the data streaming and data lakehouse ecosystems seamlessly. It streamlines integration for users and customers and marks a transformative shift in how we perceive end-to-end data streaming. In the upcoming blog posts, we will delve deeper into the implementation details of Lakehouse Tiered Storage and how query engines can leverage both streaming and historical data within a unified abstraction.
Excited about the new features from StreamNative? Request a trial license for our new Private Cloud to experience self-management capabilities, or sign up for StreamNative Cloud to explore the latest features. Feel free to reach out to us for Proof of Concept (POC) opportunities with cloud credits as well.





