
We’re excited to share that StreamNative is a launch partner for the Private Preview of Managed Apache Iceberg tables and the Iceberg REST Catalog in Databricks Unity Catalog!
This milestone marks the next step in simplifying the real-time data pipeline from Apache Pulsar and Apache Kafka to Lakehouse Storage, powered by StreamNative’s Ursa engine and Iceberg’s open table format—now fully integrated with Unity Catalog for unified governance and optimized performance. StreamNative already natively integrates with Unity Catalog through Delta Lake support, and we’re excited to add native support for Apache Iceberg as well.
Streaming into Unity Catalog with Ursa and Iceberg REST
At the heart of this integration is StreamNative’s Ursa engine, purpose-built to transform streaming data into optimized open table formats. With the recent preview launch of native Iceberg support in Unity Catalog, Ursa can now stream data directly into Iceberg tables using the Iceberg REST Catalog interface.
This RESTful interface acts as the bridge between Ursa’s real-time streaming output and Unity Catalog’s metadata governance layer. As Ursa writes new data files, it coordinates with the REST Catalog to register those files into the appropriate Iceberg table versions, maintaining full compliance with Iceberg’s transactional semantics.
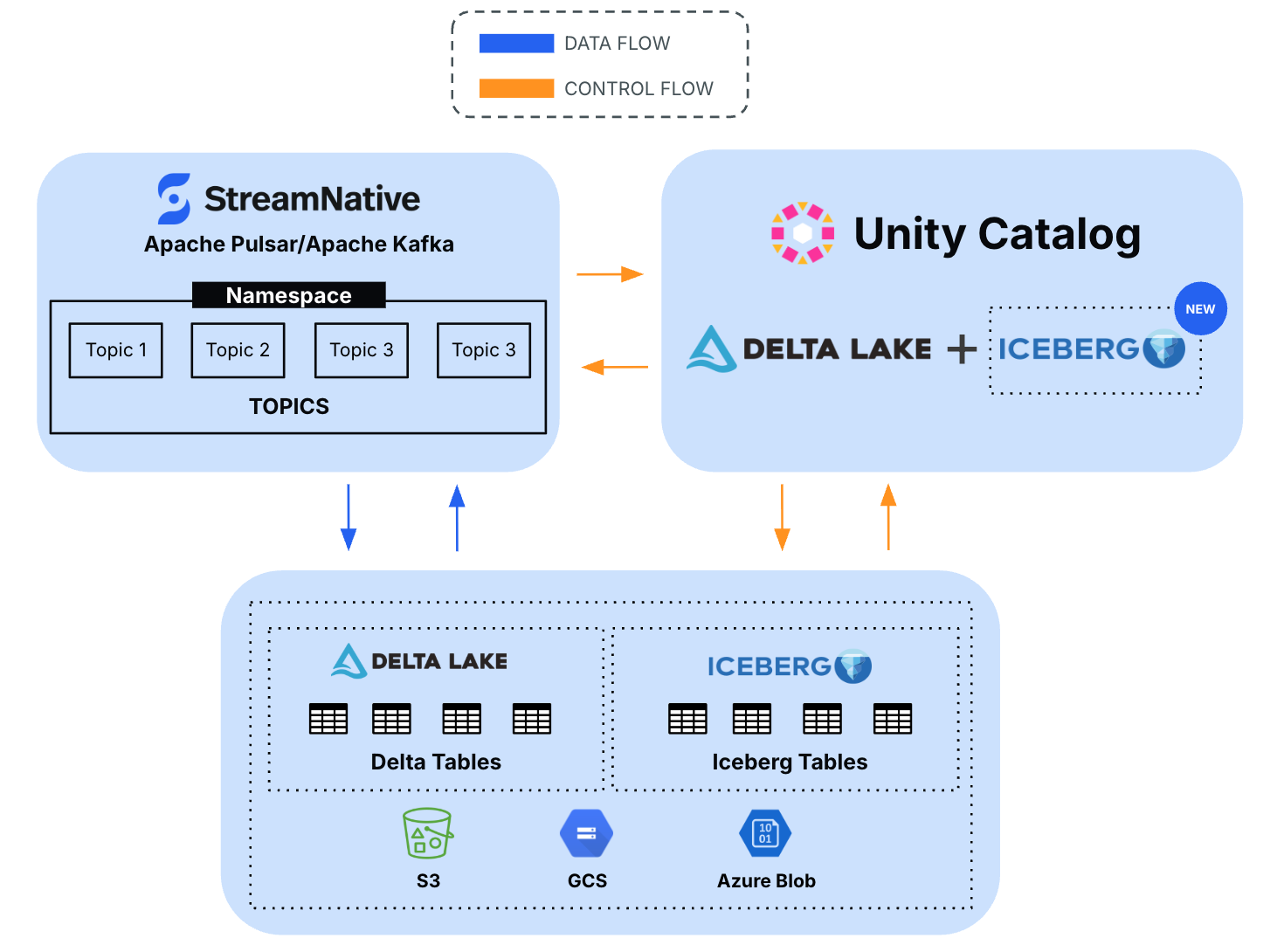
StreamNative now offers native integration with Unity Catalog, enabling seamless streaming of topic data as Iceberg tables to object storage, with direct publication into Unity Catalog for unified governance.
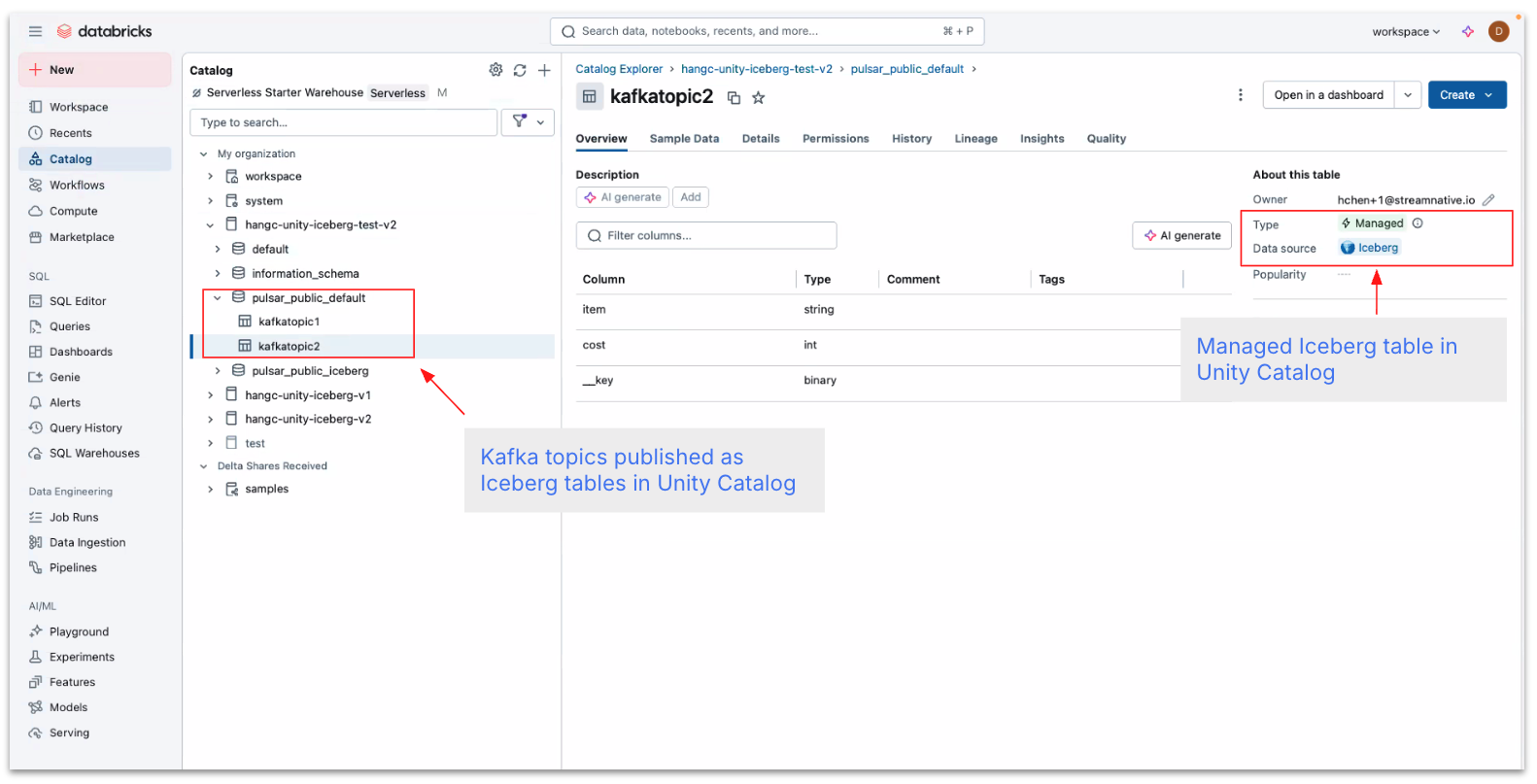
StreamNative’s Ursa engine compacts streaming topic data and stores it as optimized Parquet files in object storage. Alongside the data files, Iceberg maintains a metadata folder that captures table state using versioned snapshots, enabling efficient query planning, time travel, and schema evolution.
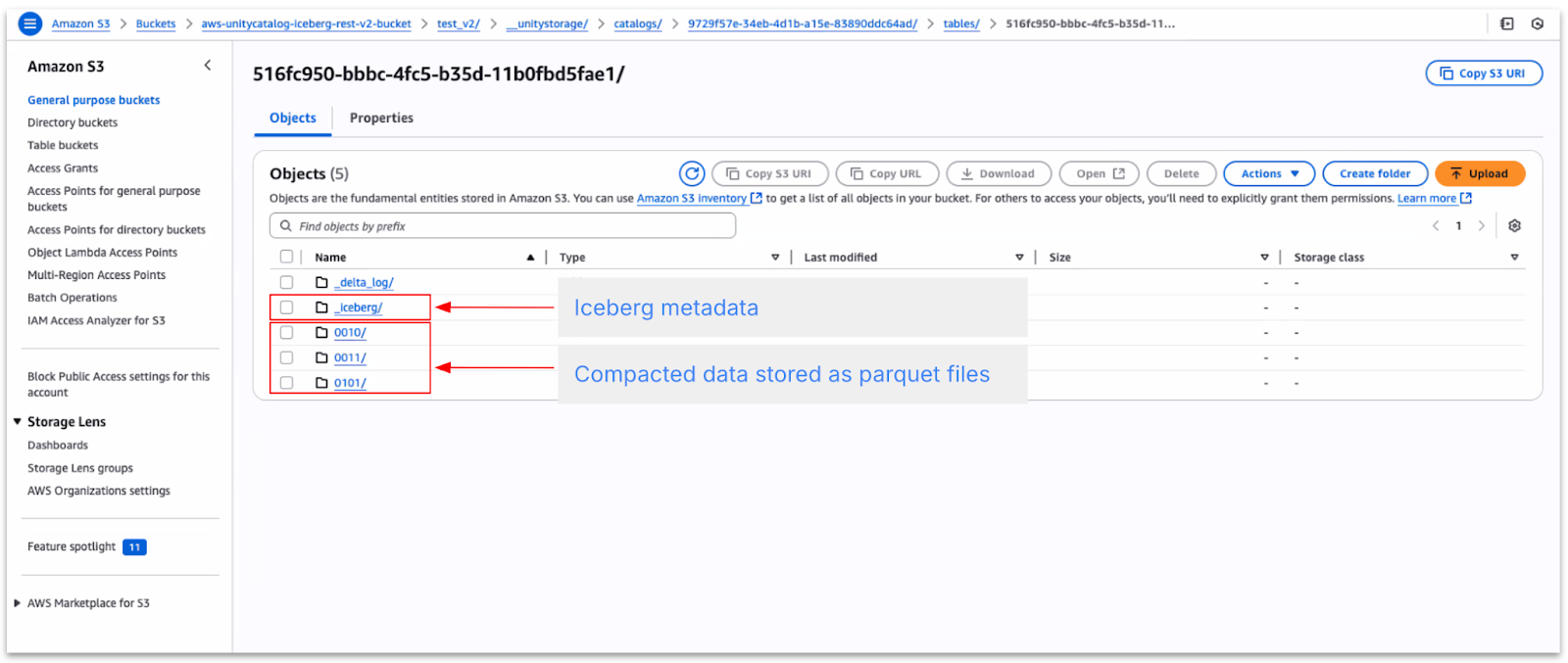
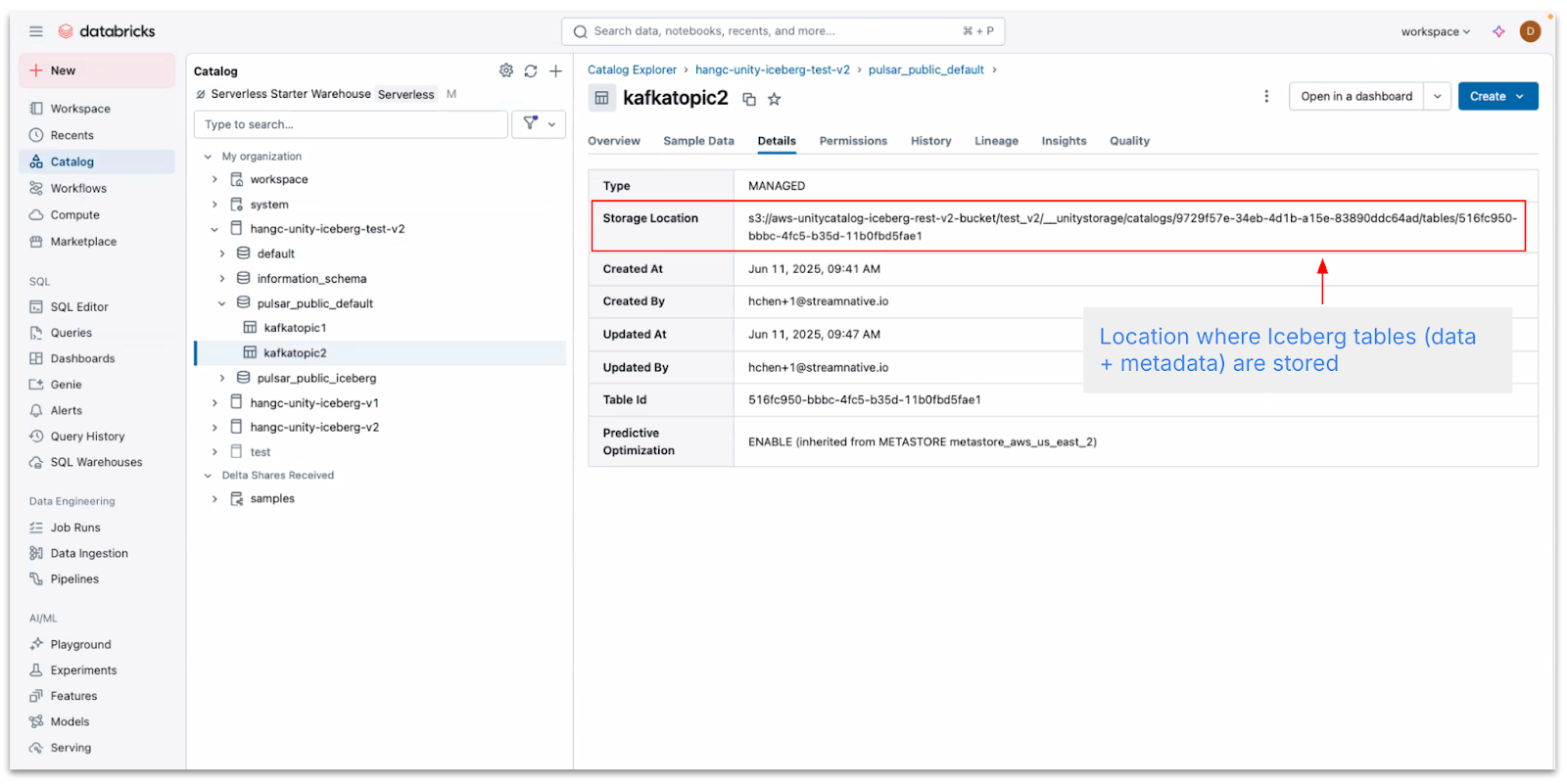
The Iceberg tables, comprising data stored in Parquet files along with metadata such as snapshots and supporting files, are located in the directory highlighted below.
Query Iceberg tables from Unity Catalog
Once topic data is ingested as Iceberg tables and published to Unity Catalog, it becomes accessible for querying through a variety of external tools. The example below demonstrates how users can query these Iceberg tables using Spark SQL.
From Streaming Chunks to Iceberg Snapshots
As messages stream into Ursa, they are initially stored in a write-optimized internal format. Ursa periodically compacts this data into columnar Apache Parquet files, which are then committed to cloud object storage (e.g., AWS S3, GCS, or Azure Blob Storage).
With each compaction cycle, Ursa creates a new Iceberg snapshot—a consistent version of the table at a point in time—by publishing a new manifest and metadata file through the Iceberg REST Catalog. These snapshots enable:
- Time travel and rollback to any prior version of the table
- Incremental reads by downstream engines
- Optimized compaction via Iceberg’s rewrite and maintenance APIs
This design ensures that real-time streaming data ingested via Pulsar is immediately queryable, governed, and fully versioned within the Unity Catalog-managed Iceberg table.
Unity Catalog's Iceberg Support Brings the Following Features:
- Automated Table Optimization Predictive compaction and file management for long-term efficiency.
- Smart Liquid Clustering Dynamically tunes table layouts for faster query performance.
- Unified Read/Write Access from External Engines Enables broad analytics access—from BI to ML—on real-time data.
Why It Matters
This integration streamlines the path from real-time event streams to AI/ML-ready analytics using open standards and governed lakehouse infrastructure. Enterprises can now:
- Ingest data with low-latency streaming from Pulsar.
- Transform it into open-format Apache Iceberg tables.
- Govern and optimize those tables with Unity Catalog.
- Access the data with any external engine using Delta, Iceberg, or Spark-compatible tooling.
What’s Next?
StreamNative and Databricks are working together to deliver seamless real-time data pipelines that power the next generation of lakehouse analytics. With support for the Iceberg REST Catalog, you can now build streaming data applications with robust schema evolution, time travel, and unified governance—out of the box.
Stay tuned for technical walkthroughs, architecture deep dives, and joint use case spotlights.
Happy streaming!
Resources



