WeChat is a WhatsApp-like social media application developed by the Chinese tech giant Tencent. According to a recent report, WeChat provided services to 1.26 billion users in Q1 2022, with 3.5 million mini programs on its platform.
As shown in Figure 1, WeChat has multiple business scenarios, including recommendations, risk control, monitoring, and AI platform. In our service architecture, we ingest data through Software Development Kits (SDKs) or data collection tools, and then distribute them to messaging platforms such as Kafka and Pulsar. Ultimately, they are processed and stored by different downstream systems. For computing, we use Hadoop, Spark, ClickHouse, Flink, and Tensorflow; for storage, we use HDFS, HBase, Redis and self-developed key-value databases.
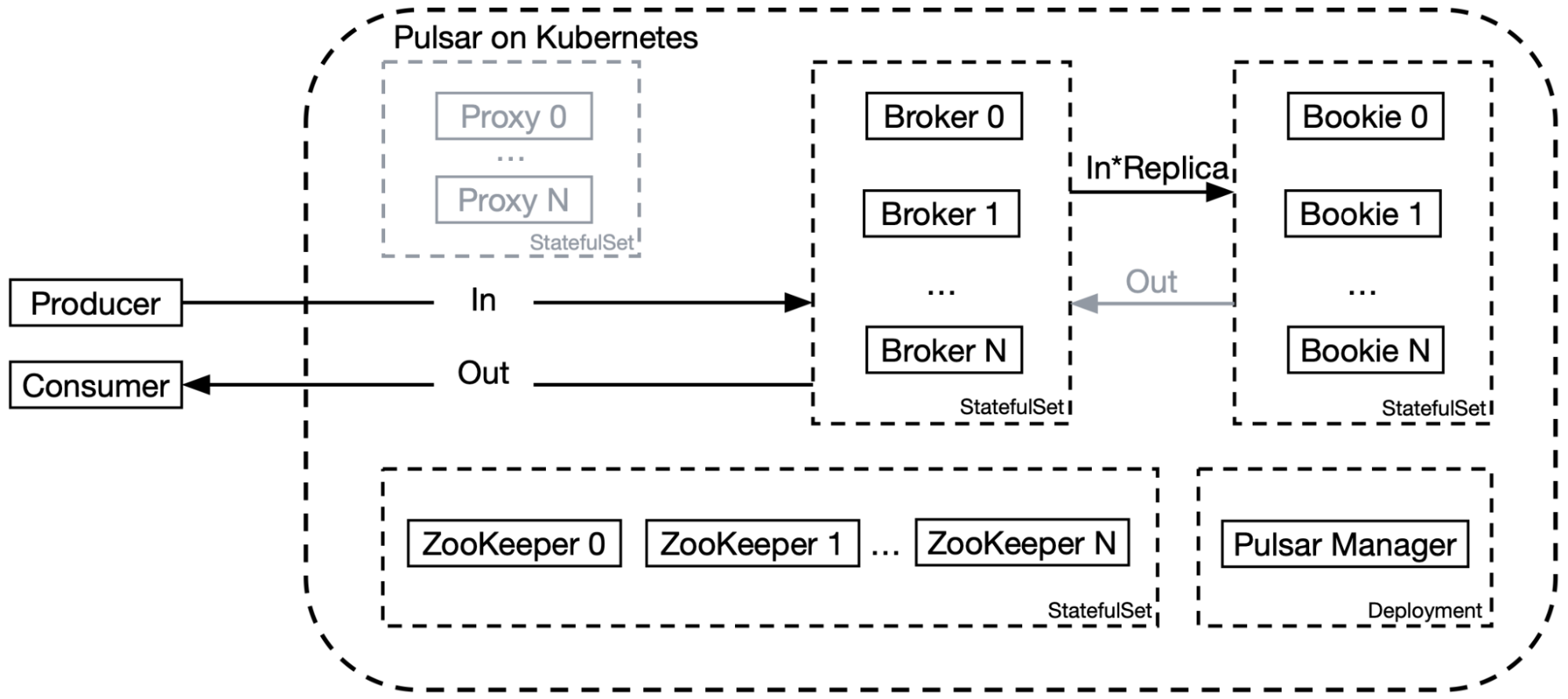
Apart from our efforts to remove the proxy layer for better bandwidth utilization, we also optimized our Pulsar deployment on Kubernetes in the following ways.
- Improved bookies’ performance by using a multi-disk and multi-directory solution with local SSDs. We contributed this enhancement to the Pulsar community. See PR-113 for details.
- Integrated the Tencent Cloud Log Service (CLS) as a unified logging mechanism to simplify log collection and query operations, as well as the use and maintenance of the whole system.
- Combined Grafana, Kvass, and Thanos with a distributed Prometheus deployment for metric collection to improve performance and support horizontal scaling. Note that for the default Pulsar deployment, Prometheus is used as a standalone service but it is not applicable to our case given the high traffic volume.
Practice 2: Using non-persistent topics
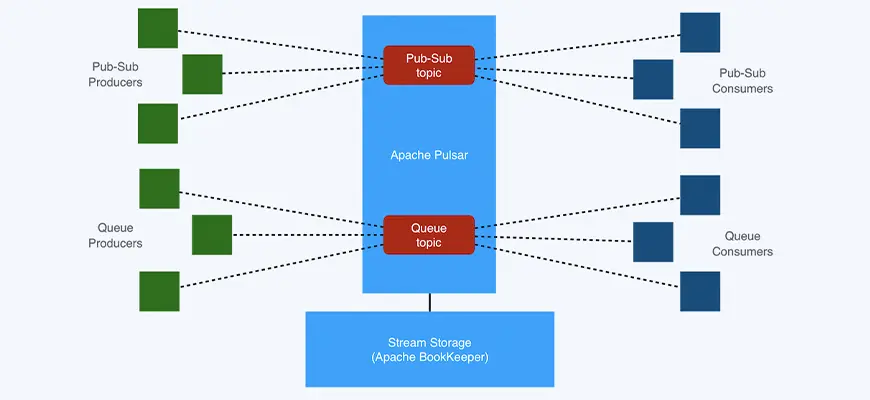
Apache Pulsar supports two types of topics: persistent topics and non-persistent topics. The former persists messages to disks whereas the latter only stores messages temporarily. Figure 4 compares how these two types of topics work in Pulsar. For persistent topics, producers publish messages to the dispatcher on the broker. These messages are sent to the managed ledger and then replicated across bookies via the bookie client. By contrast, producers and consumers working on non-persistent topics interact with the dispatcher on the broker directly, without any persistence in BookKeeper. Such straight communication has lower requirements for the bandwidth within the cluster.
Practice 4: Increasing the cache hit ratio
In Pulsar, brokers cache data to memory to improve reading performance, as consumers can retrieve data from these caches directly without going further into BookKeeper. Pulsar also allows you to set a data eviction strategy for these caches with the following configurations, among others:
- managedLedgerCacheSizeMB: The amount of memory used to cache data.
- managedLedgerCursorBackloggedThreshold: The number of entries from the position where a cursor should be considered as inactive.
- managedLedgerCacheEvictionTimeThresholdMillis: The time threshold of evicting all cached entries.
The following code snippet shows the original logic of cache eviction:
void doCacheEviction(long maxTimestamp) {
if (entryCache.getsize()
According to this implementation, all cached entries before the inactive cursor would be evicted (managedLedgerCursorBackloggedThreshold controls whether the cursor should be considered inactive). This data eviction strategy was not applicable to our use case: we had a large number of consumers with different consumption rates and they needed to restart frequently. After caches were evicted, those consuming messages at lower rates had to go deeper to bookies, thus increasing the bandwidth pressure within the cluster.
An engineer from Tencent also found this issue and proposed the following solution:
void doCacheEviction(long maxTimestamp) { if (entryCache.getSize() This implementation tweaked the logic by caching any backlogged message according to markDeletePosition. However, the cache space would be filled up with cached messages, especially when consumers restarted. Therefore, we made the following changes:
void doCacheEviction(long maxTimestamp) {
if (entryCache.getSize()
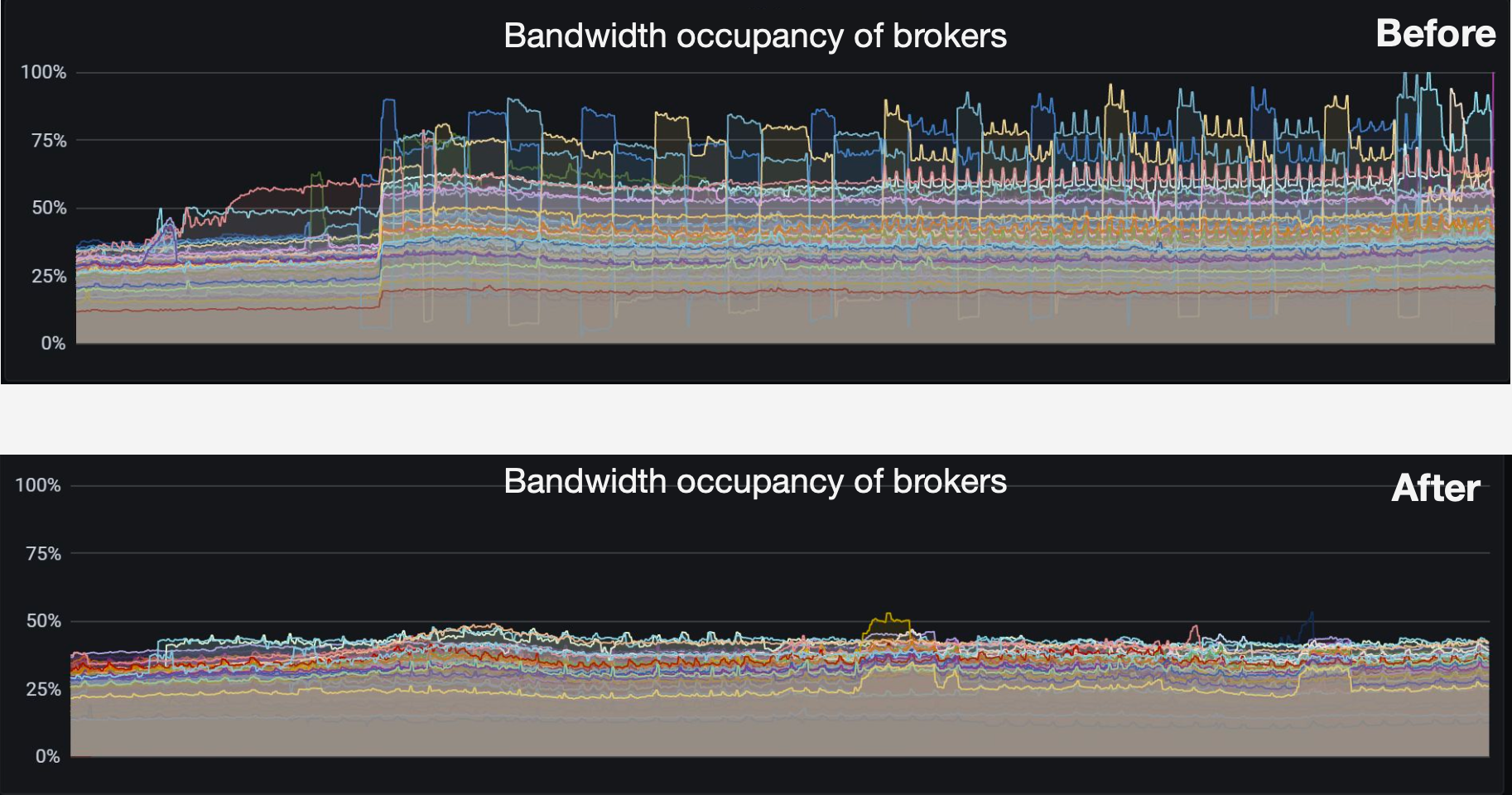
Our strategy is to exclusively cache messages within a specified period to the broker. This method has improved cache hits remarkably in our scenario, as evidenced by Figure 8. The cache hit percentage of most brokers increased from around 80% to over 95%.
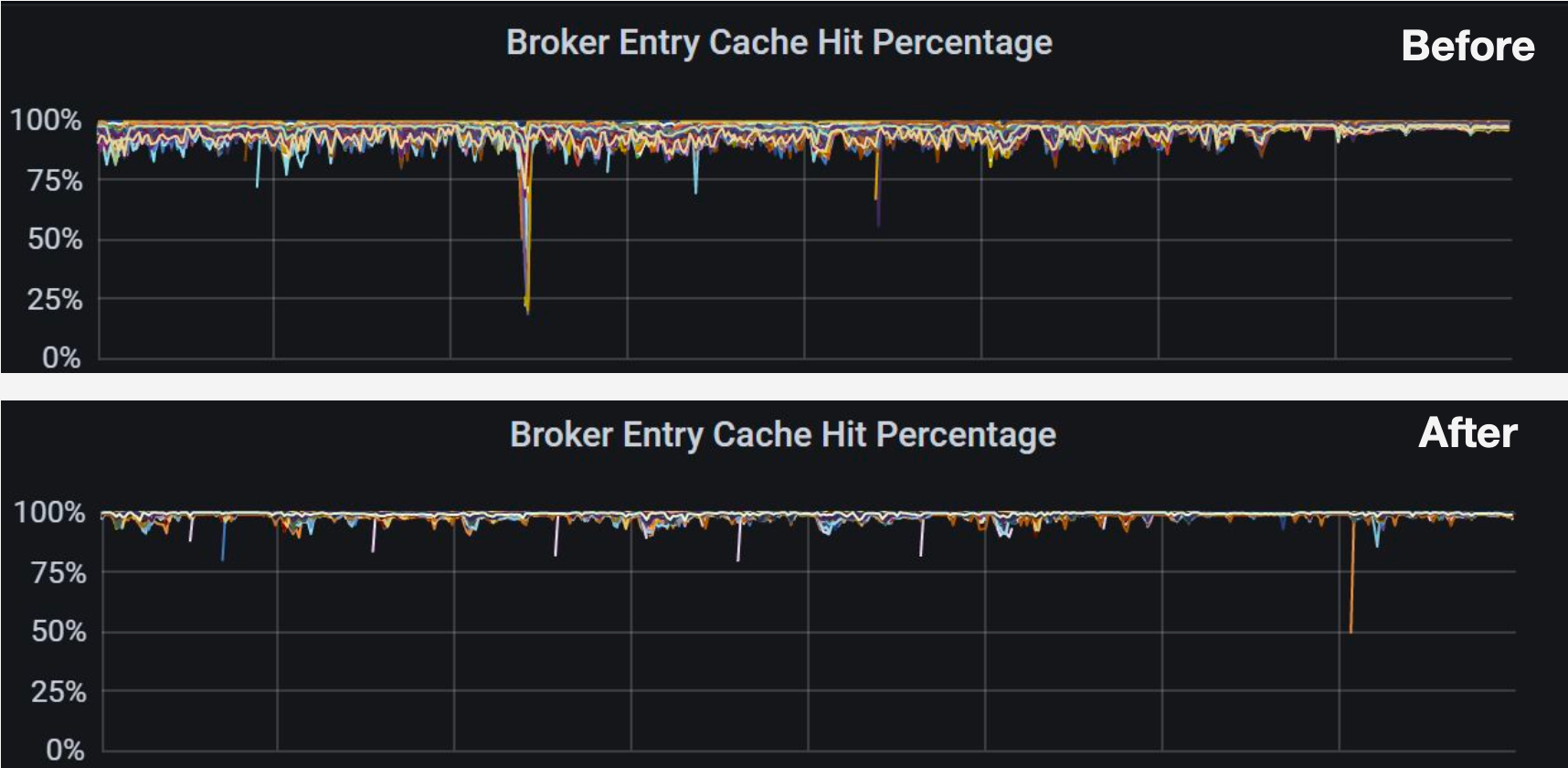Figure 8. Broker entry cache hit percentage before and after optimization
## Practice 5: Creating a COS offloader using tiered storage
Pulsar supports tiered storage, which allows you to migrate cold data from BookKeeper to cheaper storage systems. More importantly, such a movement of data does not impact the client when retrieving the messages. Currently, the supported storage systems include Amazon S3, Google Cloud Storage (GCS), Azure BlobStore, and Aliyun Object Storage Service (OSS).
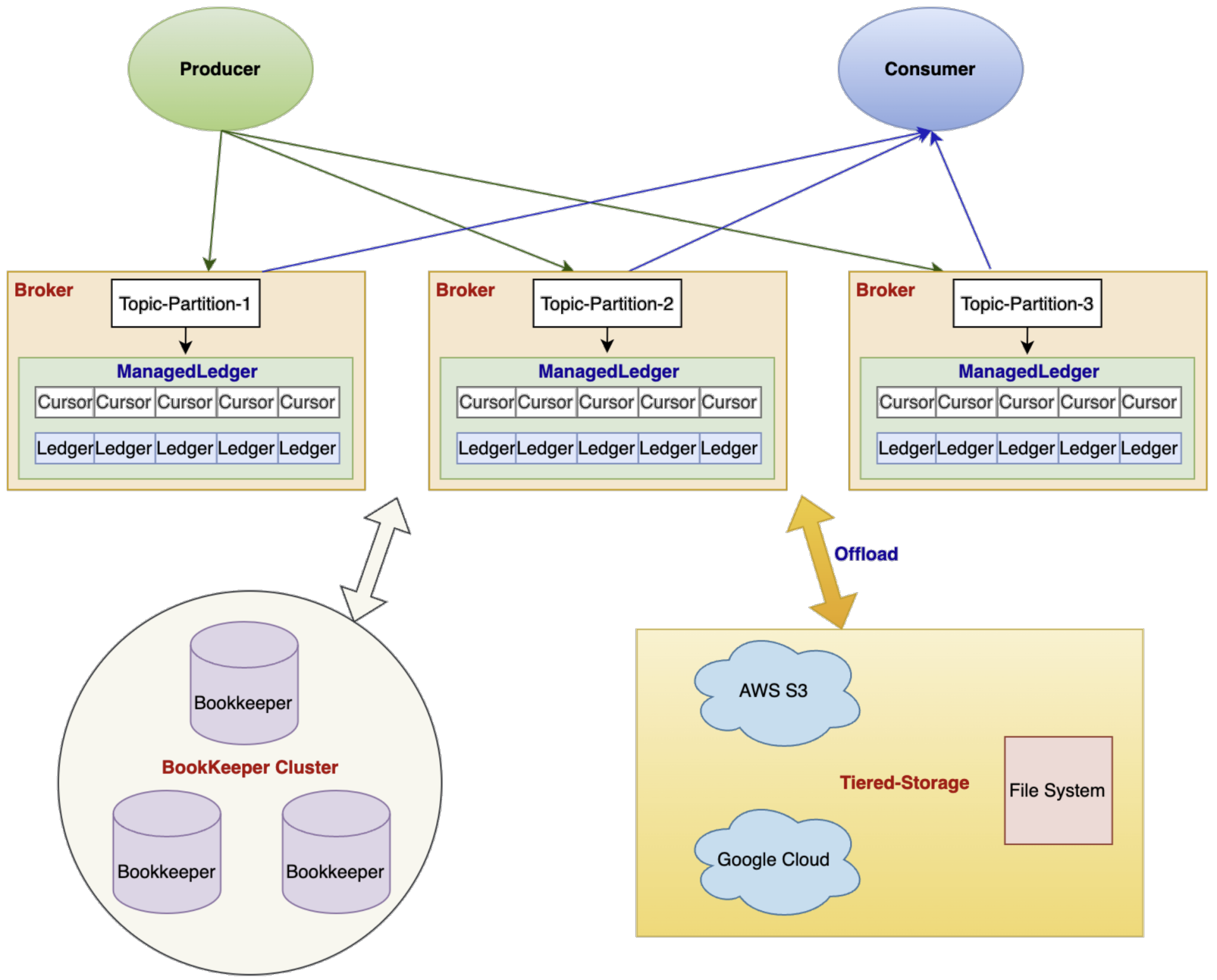Figure 9. Tiered storage in Apache Pulsar
Our main reasons for adopting tiered storage include the following:
- Cost considerations. As mentioned above, we are using SSDs for journal and ledger storage on bookies. Hence, it is a natural choice for us to use a storage solution with less hardware overhead.
- Disaster recovery. Some of our business scenarios require large amounts of data to be stored for a long period of time. If our BookKeeper cluster failed, our data would not be lost given the redundancy stored on the external system.
- Data replay needs. We need to run offline tests for some of the business modules, such as the recommendations service. In these cases, the ideal way is to replay topics with the original data.
As the Pulsar community does not provide a [Tencent Cloud Object Storage](https://www.tencentcloud.com/products/cos) (COS) offloader, we created a purpose-built one to move ledgers from bookies to remote storage devices. This migration has decreased our storage costs significantly, so we can store a larger amount of data with longer duration for different scenarios.
## Future plans
We are pleased to make contributions to Apache Pulsar, and we would like to thank the Pulsar community for their knowledge and support. This open-source project has helped us build a fully-featured message queuing system that meets our needs for scalability, resource isolation, and high throughput. Going forward, we’d like to continue our journey with Pulsar mainly in the following directions:
- Get more involved in feature improvements, such as new load balancer implementation (see [PIP 192](https://github.com/apache/pulsar/issues/16691)), and shadow topics to support read-only topic ownership (see [PIP 180](https://github.com/apache/pulsar/issues/16153)).
- Integrate Pulsar with data lake solutions.