
Today, we are really excited to unveil the next-generation data streaming engine - Ursa, which powers the entire StreamNative Cloud. Ursa is a data streaming engine that speaks the native Kafka protocol and is built directly on top of Lakehouse storage. Developed atop Apache Pulsar, Ursa removes the need for BookKeeper and ZooKeeper, pushing the architectural tenets of Pulsar to new heights, specifically tailored for the cost-conscious economy.
Both Kafka and Pulsar are robust open-source platforms. Our development of the Ursa engine leverages the extensive knowledge and operational insights we've gained from our years working with both Pulsar and Kafka. Throughout this post, I will explore the reasons behind Ursa's creation, highlight its benefits, and provide insight into its underlying mechanisms.
Understand the origin of Apache Kafka
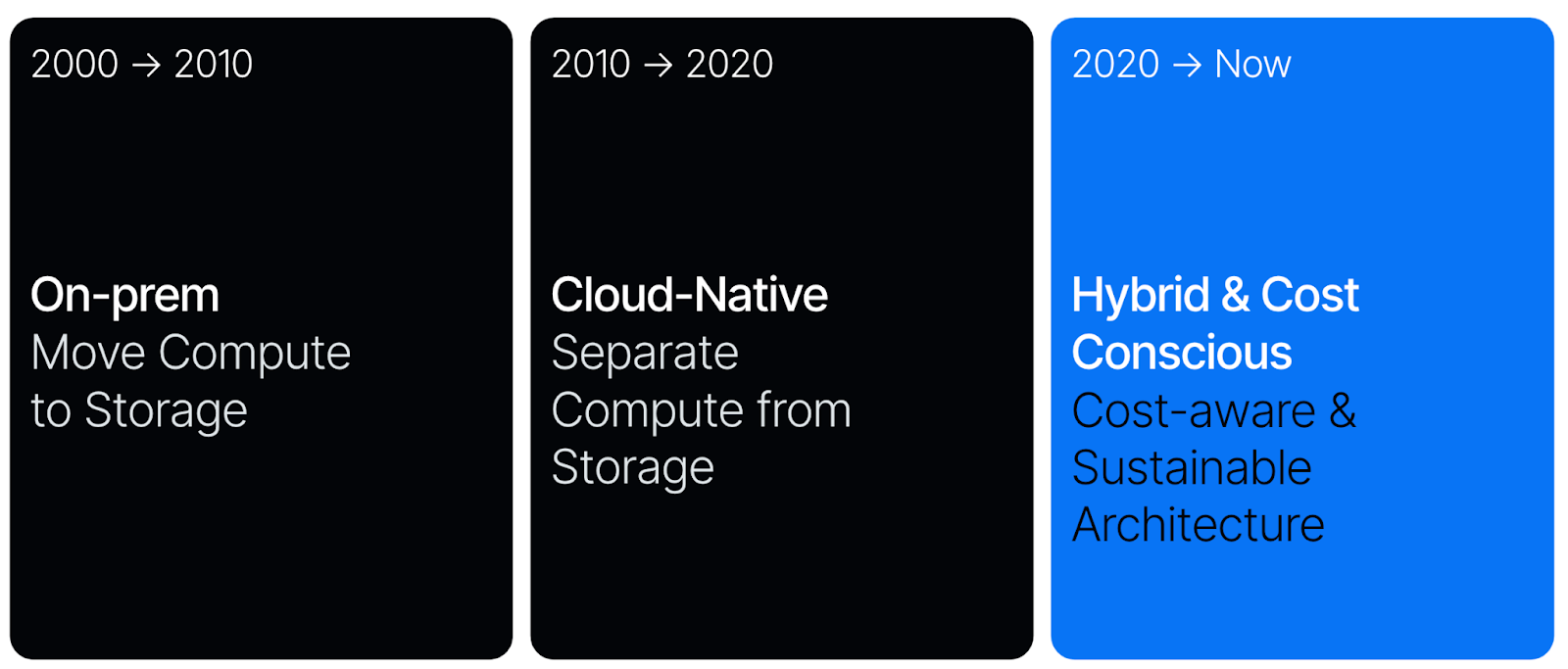
Before diving into Ursa, it’s important to grasp the significance of Kafka. Originally developed at LinkedIn, Kafka was open-sourced in 2011 and quickly became the go-to framework for building data streaming platforms. It emerged during the On-prem / Hadoop Era (2000 to 2010), a time characterized by on-premises deployments with slow network speeds. Infrastructure software from this period was optimized for rack awareness to compensate for these limitations. Kafka, designed under these conditions, coupled data serving and storage on the same physical units—an approach that matched the technological constraints of the time.
Fast forward to 2015, and the landscape has drastically shifted, particularly with the move towards cloud-native environments. Despite these changes, Kafka's core architecture has remained largely unchanged. Organizations have attempted to transition Kafka to the cloud, but the reality is that Kafka is cumbersome and costly to operate at scale in modern settings. The problem lies not with Kafka's API but with its implementation, which was conceived for on-prem data centers. This tightly coupled architecture is ill-suited for the cloud, leading to significant data rebalancing challenges when adjusting cluster topologies, resulting in high inter-AZ bandwidth costs and potential service disruptions. Managing a Kafka cluster in such environments requires extensive, specialized tooling and a dedicated support team.
Pulsar: Reimagine Kafka with a Rebalance-Free Architecture
In contrast to Kafka, Pulsar emerged during the cloud-native era (2010 to 2020), a time marked by the rise of containerized deployments and significantly faster network speeds. As organizations transitioned from on-premises to cloud environments, system designs increasingly prioritized elasticity over cost. This shift led to the widespread adoption of architectures that separate compute from storage, a strategy exemplified by platforms like Snowflake and Databricks.

Pulsar embraced this modern design by decoupling data serving capabilities from the storage layer. With this architecture, it became the pioneer in the market, making it 1000x more elastic than Apache Kafka. This architectural innovation has made Pulsar extremely attractive to those dealing with the challenges of data rebalancing when operating Kafka clusters.
Pulsar's architecture is rebalance-free and supports a unified messaging model that accommodates data streaming and message queuing. Its features, like built-in multi-tenancy and geo-replication, are key reasons many prefer Pulsar over other data streaming technologies.
Can we further reduce costs in this complex, cost-conscious economy?
Today, there is a heightened focus on operational efficiency and cost reduction, which has slowed the migration to cloud solutions and, in some cases, even reversed it. We navigate a complex landscape that straddles both on-premises and cloud environments, where cost and network efficiency are critical considerations. This scenario underscores the need to shift towards more cost-aware and sustainable architectural approaches in data streaming services.
To meet the evolving demands in the current environment and further reduce the costs of running a data streaming platform, we need to revisit and possibly redesign the architecture we have built on with Apache Pulsar. We have identified the following main areas:
Infrastructure Cost: As mentioned in our guide on evaluating the infrastructure costs of Apache Pulsar and Apache Kafka, networking often represents the most significant expense for a data streaming platform. Because Pulsar operates as an AP (Availability and Performance) system, cross-AZ traffic incurs substantial costs due to the necessity for cross-AZ replication to ensure high availability and reliability. This availability, unfortunately, comes at a high cost. The cost of inter-AZ data transfer from replication can balloon for high-throughput workloads, accounting for up to 90% of infrastructure costs when self-managing Apache Kafka. Is it possible to completely eliminate cross-AZ traffic from Pulsar?
Operational Cost: Pulsar’s modular design, which includes components like ZooKeeper for metadata management and BookKeeper for ultra-low latency log storage, leverages the elasticity of Kubernetes but can be challenging for beginners. What if we could replace these Keeper services to simplify operations?
Migration Cost: Although Pulsar provides a unified messaging and streaming API, some applications are still written using the Kafka API. Could making Pulsar compatible with the Kafka API eliminate the need for costly application rewrites?
Integration Cost: Pulsar could instantly tap into the vast Kafka ecosystem by supporting the Kafka API, blending robust architectural design with an established user base.
These considerations mark the beginning of our new journey to reimagine Kafka and Pulsar, aiming for a more cost-effective data-streaming architecture that aligns with our industry's evolving needs.
Object Storage & Lakehouse are All You Need
Beyond the cost considerations already discussed, streaming data ultimately finds its home in a data lakehouse, which serves as the foundation for all subsequent analytical processing. However, connecting data streams to these lakehouses typically requires additional integrations to transfer data from the streaming system to the designated lakehouse, incurring significant costs for networking and compute resources.
Given these expenses, we pondered whether developing a Kafka-compatible data streaming system that runs directly atop a data lakehouse would be feasible. This approach could address several of the major challenges we face with current systems:
- Cost Reduction: Operating directly on a lakehouse would significantly cut costs, as no major cloud provider charges for data transfer between VMs and object storage. For example, AWS has dedicated countless engineering resources to ensure the reliability and scalability of S3, thereby reducing the operational burden on users.
- Simplified Management: Such a system would be easier to manage without needing local disk storage.
- Immediate Data Availability: Data would be instantly available in ready-to-use lakehouse formats, allowing for more efficient and cost-effective real-time ETL processes and bypassing the costs of complex networking and bespoke integrations.
Implementing this concept is no small feat. Building a low-latency streaming infrastructure on top of the inherently high-latency lakehouse storage while maintaining full compatibility with the Kafka protocol and adhering to strict data agreements between streaming and lakehouse platforms poses a significant challenge.
So we asked ourselves: “What would Kafka or Pulsar look like if it was redesigned from the ground up today to run in the modern cloud data stack, directly on top of a lakehouse (which is the destination for most of the data streams) over commodity object storage, with no ZooKeeper and BookKeeper to manage, but still had to support the existing Kafka and Pulsar protocols?”
Ursa is our answer to that question.
Introducing Ursa
Ursa is an Apache Kafka API-compatible data streaming engine that runs directly on top of commodity object stores like AWS S3, GCP GCS, and Azure Blob Storage and stores streams in lakehouse table formats (such as Hudi, Iceberg, Delta Lake). This setup makes data immediately available in the lakehouse and simplifies management by eliminating the need for ZooKeeper and, soon, BookKeeper—thereby reducing inter-AZ bandwidth costs.
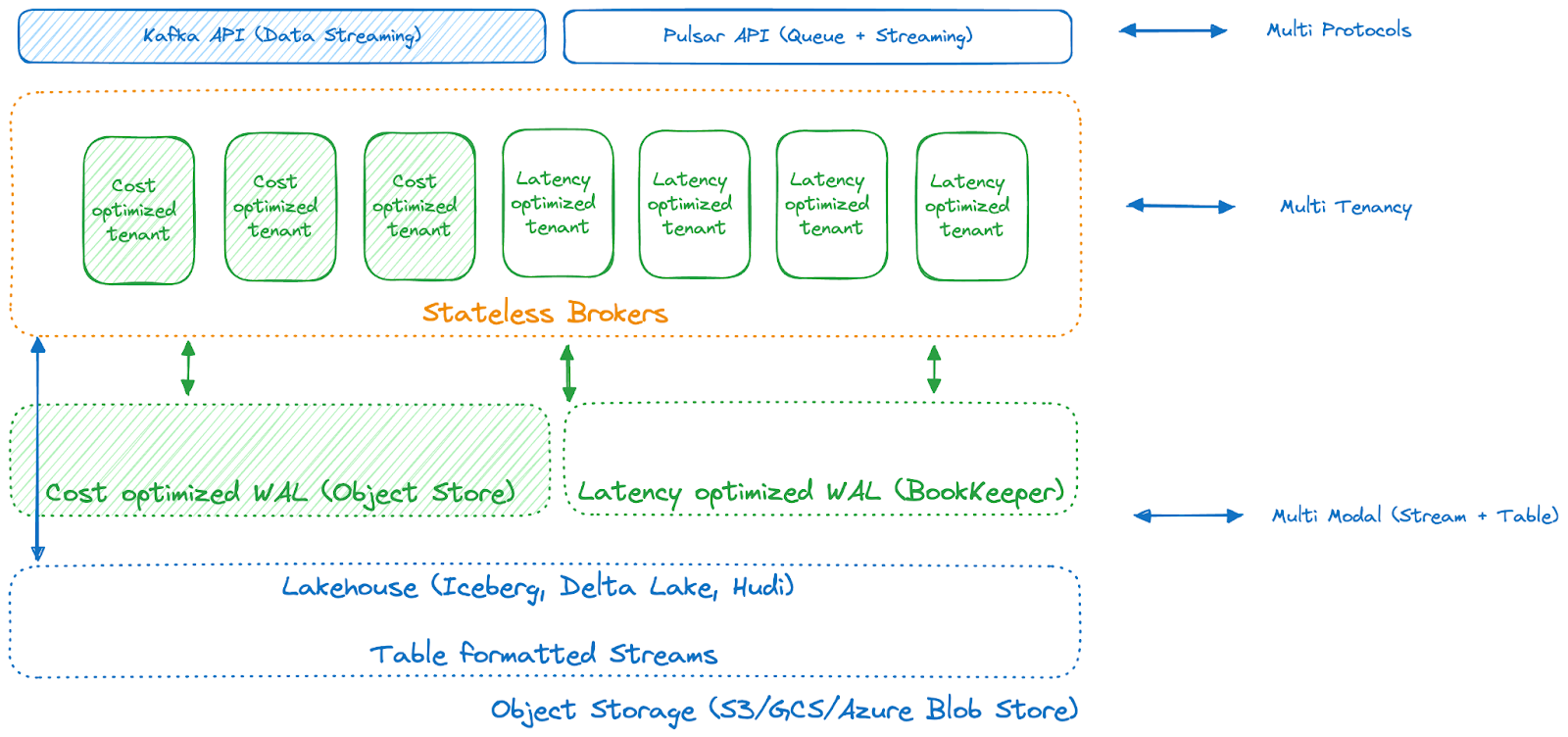
That’s a lot to digest, so let’s unpack it by highlighting three major features within Ursa.
- Kafka API Compatibility
- Native Lakehouse Storage
- No Keepers
Kafka API Compatibility - Embracing the Best of Pulsar & Kafka
The development of the Ursa engine began with a project called KoP (Kafka-on-Pulsar). The original idea of KoP was to develop a Kafka API-compatible layer using the distributed log infrastructure of Apache Pulsar and its pluggable protocol handler framework. The project gained significant traction in the Apache Pulsar community and has been adopted by large-scale tech companies (such as WeChat, Didi, etc) to migrate their Kafka workloads to Apache Pulsar.
However, we quickly realized that more than KoP was needed to fulfill the mission of building a data streaming engine directly on a lakehouse. We needed to revolutionize the Kafka and Pulsar protocol implementations to fit the broad vision we had laid out with Ursa.
Hence, we took the experience gained in building KoP and evolved it into KSN (Kafka-on-StreamNative), which became the core foundation of the Ursa Engine.
The Ursa Engine is compatible with Apache Kafka versions from 0.9 to 3.4. Modern Kafka clients will automatically negotiate protocol versions or utilize an earlier one that Ursa accepts. In addition to the basic produce and consume protocols, Ursa also supports Kafka-compatible transaction semantics and APIs and has built-in support for a schema registry.
With the Ursa Engine, your Kafka applications can directly work and run on StreamNative Cloud without rewriting your code. This eliminates the costs of rewriting and migrating your existing Kafka applications to the Apache Pulsar protocol. Ursa incorporates interoperability between Kafka and Pulsar protocols, enabling you to either begin developing new streaming applications with Pulsar's unified protocol, continue using the Kafka protocol if you already have Kafka developers, or start migrating some of your existing Kafka applications immediately. This also allows you to immediately enjoy the benefits of Apache Pulsar (such as multi-tenancy, geo-replication, etc.) along with a robust Kafka ecosystem. You get the best of both worlds.
Built on top of Lakehouse - Unify Data Streaming and Data Lakehouse
Ursa is built on top of lakehouse, enabling StreamNative users to store their Pulsar & Kafka topics and associated schemas directly into lakehouse tables. Our goal with Ursa is to simplify the process of feeding streaming data into your lakehouse.
Ursa utilizes the innovations we have developed to evolve the Pulsar tiered storage. Pulsar was the first data streaming technology to introduce tiered storage, which offloads sealed log segments into commodity object storage like S3, GCS, and Azure Blob Store. While trying to enhance the offloading performance and streamline the process, we realized that tiered storage could evolve for data destined for lakehouses. We asked ourselves: Why can't we store the data directly in lakehouses?
Taking a step back, Pulsar stores the data first in a giant, aggregated write-ahead log (WAL) backed by Apache BookKeeper (as illustrated in Figure 4 below), consolidating data entries from different topics with a smart distributed index for fast lookups.
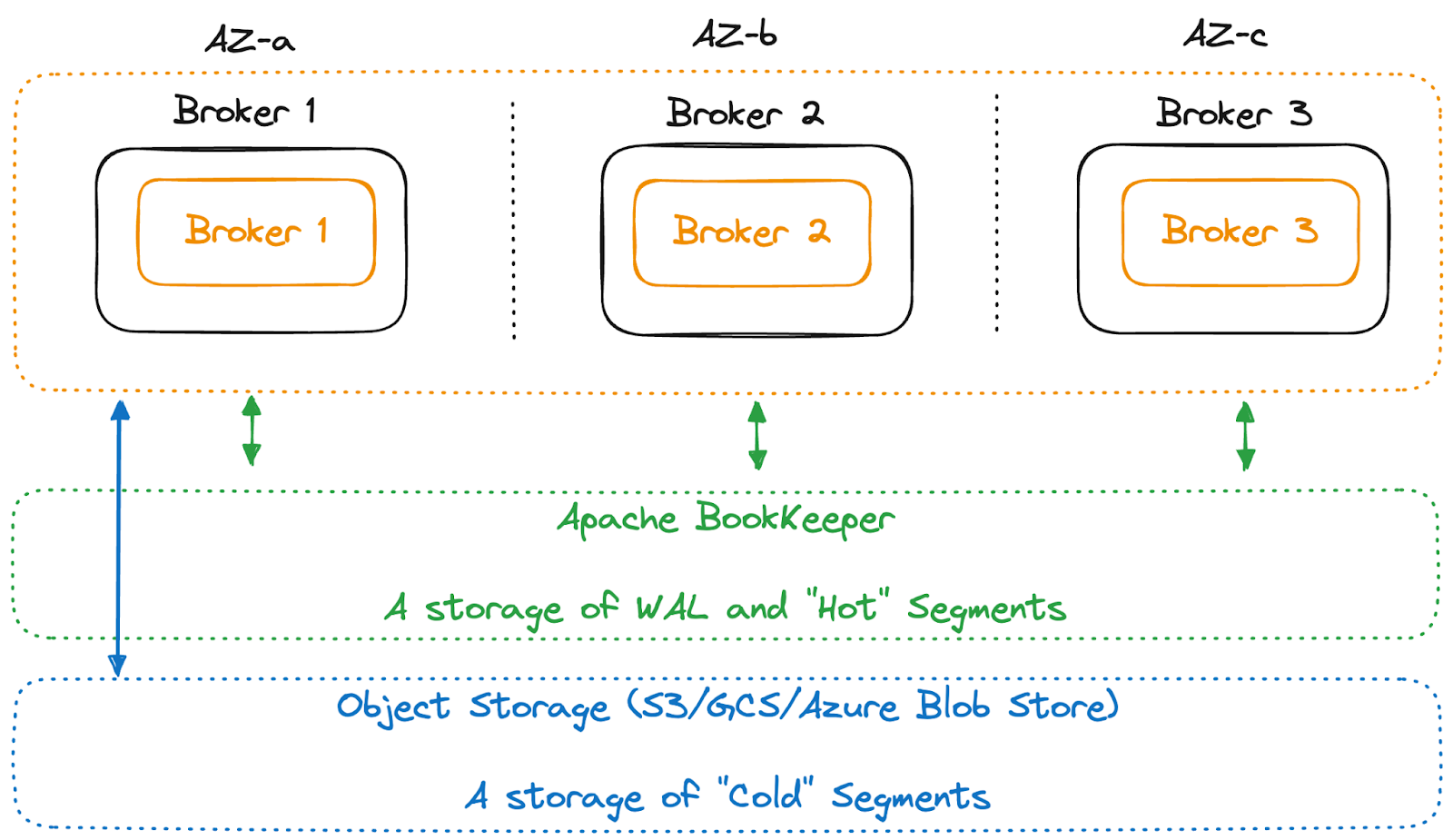
After the data is persisted to the WAL, it will be compacted and stored as continuous data objects in commodity object storage. Thus, in Pulsar’s design, there is no actual data tiering. Writing or moving data to object storage is effectively a “compaction” operation that reorganizes the data stored in WAL into continuous data objects grouped by topics for faster scans and lookups.
Given this capability, if the system is intelligent enough when compacting data, we can leverage schema information to store the data in columnar formats directly in standard lakehouse formats. This approach would make the data immediately available in the lakehouse, eliminating the need for bespoke integration between a data streaming platform and a data lakehouse.
These insights have led to the development of Lakehouse Storage, which now serves as Ursa's primary storage. We now refer to it simply as "Lakehouse Storage," eliminating traditional data "tiering." The data can be made immediately accessible in the lakehouse.
Hence, in the Ursa engine, instead of compacting the data into Pulsar’s proprietary storage format, the Ursa engine can now compact the data into other open standard formats, like lakehouse formats such as Apache Hudi, Apache Iceberg, and Delta Lake. Ursa taps into the schema registry during this compaction process to generate lakehouse metadata while managing schema mapping, evolution, and type conversions. This system eliminates the need for manual mappings, which often break when the upstream application updates. Data schemas are enforced upstream as part of the data stream contract—ensuring that incompatible data is detected early and not processed.
In addition to managing schemas, Ursa continuously compacts small parquet files generated by the streaming data into larger files to maintain good read performance. We are collaborating with lakehouse vendors such as Databricks, OneHouse, and others to offload some of these complexities, enabling users to optimize their use of these products for superior performance.
Lakehouse storage is currently available as a Public Preview feature in StreamNative Hosted and BYOC (Bring Your Own Cloud) deployments. StreamNative users can now access their data streams as Delta Lake tables, with the development of Iceberg & Hudi tables coming soon.
No Keepers
Pulsar is designed as a modular system with distinct components for different functionalities, such as ZooKeeper for metadata management and BookKeeper for ultra-low latency log storage. While this design capitalizes on the elasticity of Kubernetes, it also introduces overhead that can challenge beginners. As a result, this inherent barrier has prompted initiatives within the Pulsar community and StreamNative to replace these 'Keeper' services, including ZooKeeper and BookKeeper.
No ZooKeeper
Traditionally, Apache Pulsar has relied on Apache ZooKeeper for all coordination and metadata. Although ZooKeeper is a robust and consistent metadata service, it is difficult to manage and tune. Instead of simply replacing ZooKeeper, we adopted a more sophisticated approach by introducing a pluggable metadata interface, enabling Pulsar to support additional backends such as Etcd. However, there remains a need to design a system that can effectively overcome the limitations of existing solutions like ZooKeeper and Etcd:
- Fundamental Limitation: These systems are not horizontally scalable. An operator cannot add more nodes and expand the cluster capacity since each node must store the entire dataset for the cluster.
- Ineffective Vertical Scaling: Since the maximum dataset and throughput are capped, the next best alternative is to scale vertically by increasing CPU and IO resources on the same nodes. However, this stop-gap solution doesn’t fully resolve the issue.
- Inefficient Storage: Storing more than 1 GB of data in these systems is highly inefficient due to their periodic snapshots. This snapshot process repeatedly writes the same data, consuming all the IO resources and slowing down write operations.
Oxia represents a step toward overcoming these limitations and scaling Pulsar’s ability to support from 1 million topics to hundreds of millions, with efficient hardware and storage. Oxia is currently available for public preview on StreamNative Cloud. For more details about Oxia, you can check out our blog post.
No BookKeeper
BookKeeper is a high-performance, scalable log storage system that is the secret behind Pulsar’s ability to achieve a rebalance-free architecture and deliver vastly greater elasticity than Apache Kafka. However, BookKeeper’s design depends on replicating data across multiple storage nodes in different availability zones to ensure high availability. It is ideally suited for latency-optimized workloads. Deploying BookKeeper for high-volume data streaming workloads involves significant inter-AZ traffic, making operating in a multi-AZ deployment expensive. The cost of inter-AZ data transfer from replication can balloon for high-throughput workloads, accounting for up to 90% of infrastructure costs when self-managing Apache Kafka. Although deploying Pulsar in a single-zone environment could reduce cross-AZ network traffic, it would trade off availability for cost and performance.
Since Ursa already utilizes object storage, what if we eliminate the need for BookKeeper as a WAL storage solution and instead directly leverage commodity object storage (S3, GCS, or ABS) as a write-ahead log for data storage and replication? This approach would eliminate the need for inter-AZ data replication and its associated costs. This is the essence of introducing a cost-optimized WAL based on object storage, which is at the heart of the Ursa engine (as illustrated in the diagram below).
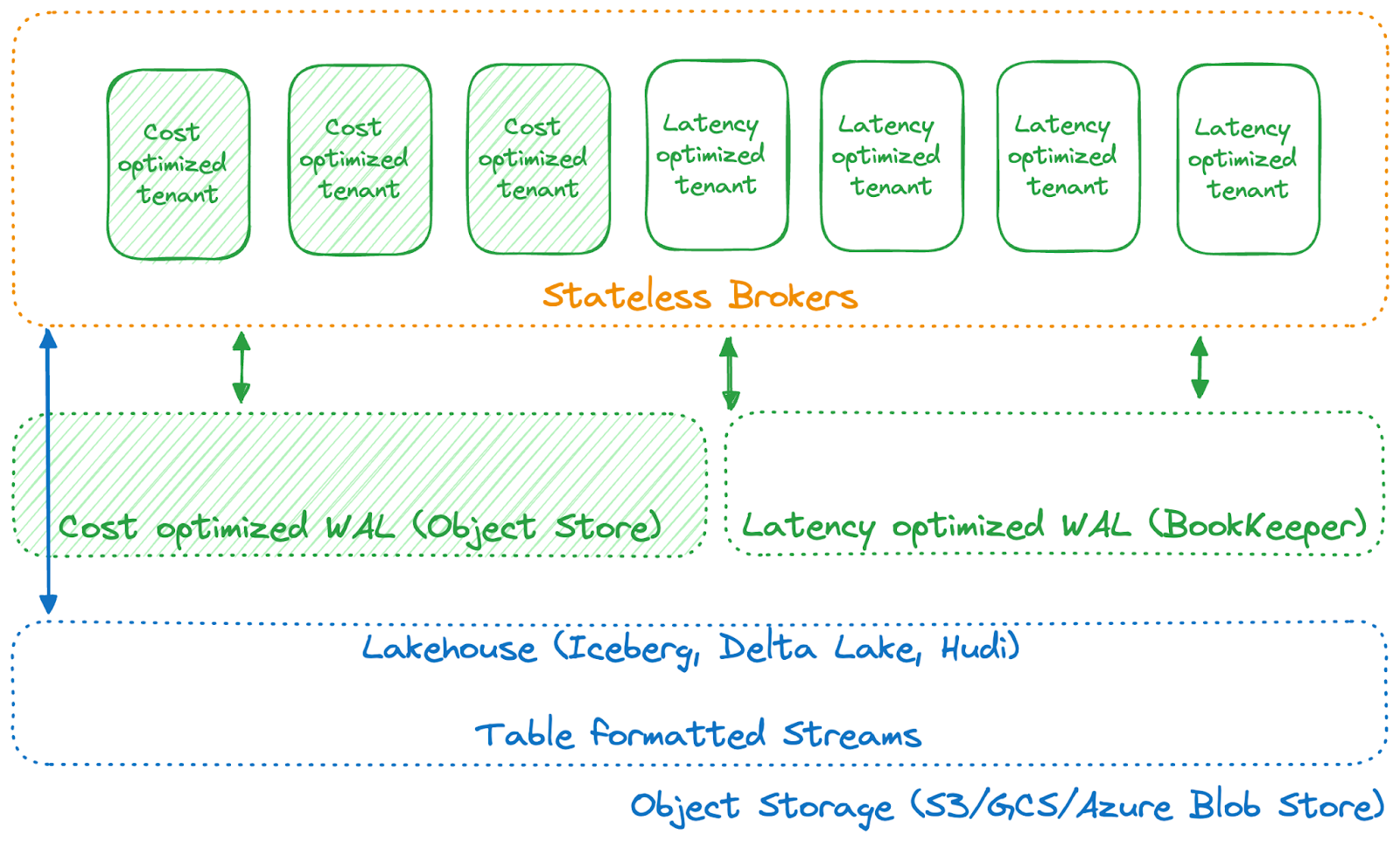
With this cost-optimized WAL, we can eliminate almost all cross-AZ traffic, significantly reducing the total infrastructure costs of running high-throughput, latency-relaxed workloads.
Due to its unbeatable durability and cost, Ursa was designed to use cloud object storage as a major storage layer. However, as most workloads need lower latency than what object stores typically provide, we didn't choose one implementation over the other; instead, we incorporated multi-tenancy features that allow users to select the most optimized storage profiles based on their needs for throughput, latency, and cost.
Therefore, you can optimize your tenants and topics based on latency versus cost. Workloads optimized for latency can continue using a latency-optimized WAL without converting data to lakehouse formatted tables. High-throughput and latency-relaxed workloads can choose a cost-optimized WAL to avoid costly cross-AZ data transfers. Data can be stored in lakehouse table formatted streams for longer-term storage and analytical purposes.
With this multi-model and modular Ursa storage engine, we are developing a unified data streaming platform that supports all types of workloads not only with the Kafka API for data streaming and the Pulsar API for messaging queues but also with lakehouse formats as the emerging standard for feeding your analytics systems.
Our Ambition: Unify Data Streaming and Data Lakes
The Ursa Engine, available on StreamNative Cloud, represents the culmination of years of development and operational experience with Pulsar and Kafka. It's designed to meet the evolving needs of StreamNative customers with a new data streaming engine to support a modern, cost-conscious data streaming cloud. Key developments include full support for the Kafka protocol, a transition from tiered storage to lakehouse storage, the introduction of the more robust metadata management with Oxia, and a shift to make BookKeeper optional by utilizing a WAL system based on commodity object storage.
The rollout of Ursa is structured into distinct phases:
- Phase 1: Kafka API Compatibility. Achieved general availability on StreamNative Cloud in January 2024.
- Phase 2: Lakehouse Storage. Set for a private preview on StreamNative Cloud in May 2024.
- Phase 3: No Keepers. Plans to remove ZooKeeper with Oxia entering public preview by Q2 2024 and to remove BookKeeper later in the year.
- Phase 4: Stream <-> Table Duality. Ursa currently enables the writing of data streams as data tables for storage, with future ambitions to allow users to consume Lakehouse Tables as Streams.

The rollout of Ursa engine dramatically reduces the time to insights on your data by uniting data streaming and data lakehouse technologies. We are thrilled about the advancements our team has made and the potential that the launch of the Ursa engine has for both your data streaming platform (DSP) and your lakehouse:
- For the Lakehouse: Data remains perpetually fresh. It is received, processed, and made available in real time, ensuring it's ready for immediate analysis.
- For the Data Streaming Platform: Stream processing jobs benefit from access to the entire historical dataset, simplifying tasks such as reprocessing old data or performing complex joins.
Additionally, we are streamlining the data ingestion pipeline to make it more robust and efficient, ensuring that defined data streams seamlessly integrate into your lake without the need for manual intervention.
Ursa Next Steps
Ursa represents a significant advancement in data streaming. We're simplifying the deployment and operation of data streaming platforms, accelerating data availability for your applications and lakehouses, and reducing the costs of managing a modern data streaming stack.
While Ursa is still in its early stages, our ambitions are high, and we are eager for you to experience its capabilities. The Ursa engine, featuring Kafka API compatibility, Lakehouse storage, and the No Keeper architecture, is available on StreamNative Cloud. If you want to learn more or try it out, sign up today or talk to our data streaming experts.




