
At StreamNative, we understand the challenges organizations face in today’s economic environment: rising costs, data sovereignty concerns, data accessibility issues, and the need for economic scalability. Our vision is to simplify data streaming by offering an affordable, accessible, and scalable solution that addresses these pain points directly. With our Ursa Engine, we empower users to optimize storage by selecting the most cost-effective storage classes without sacrificing availability or performance. This flexibility allows businesses to balance their data needs with budget constraints, ensuring seamless data streaming even in uncertain times. Our recent partnership with Ververica brings us closer to realizing this vision. This collaboration is built on a foundation we call BYOC², offering a Managed Flink service to our customers.
BYOC² stands for "Bring Your Own Compute" and "Bring Your Own Cloud." Your data remains in your own bucket, and you bring your own engine to process it—all within your cloud account with a fully managed experience.
We envision BYOC² as a model for how we partner with compute engine vendors to bring the most affordable and secure data streaming solution to our customers. Let's delve deeper into the model, the rationale behind this strategic partnership, its origins, and the direction we are heading.
BYOC: Bring Your Own Compute
The first part of the equation is Bring Your Own Compute.
The concept of Bring-Your-Own-Compute (BYOC) has been present in data lakes, data warehouses, and lakehouses for many years. With the emergence of S3 as the primary storage and the adoption of open table formats as a standard for storing structured tabular data in S3, BYOC is evident. You own your data in your bucket, and you can plug in your processing engine to access that data. This paradigm is well-established in the broader data ecosystem, often referred to as "Headless Data Storage", where all your data is stored in a central repository, and the engines plug in to process it.
However, this concept has not been as popular in data streaming. One major barrier to the mainstream adoption of data streaming is the high cost, especially networking expenses. Unlike batch processing in lakehouses, stream processing engines using the Kafka protocol heavily depend on networking, as it requires streaming data in and out, which can be expensive, as we have previously discussed as part of the New CAP theorem.
This has started to change, particularly as more data streaming vendors transition from using S3 as tiered storage to using S3 as primary storage. The concept of stream-table duality has now become a reality. Our Ursa Engine represents an innovative approach that evolves the storage engine into a headless, multi-modality storage solution for both streams and tables. Essentially, you only need to store one copy of the data and can consume it either through stream semantics or table semantics. This reduces the cost, complexity, and redundancy of storing data across different systems.
With a headless, multi-modality storage engine and standard streaming APIs like Pulsar or Kafka, Bring-Your-Own (Streaming) Compute becomes a reality for data streaming. You can keep your data in your bucket, consume it as a table or stream, and bring the streaming compute engine into your account, eliminating inter-account or inter-zone traffic.
Our Managed Flink offering, announced in partnership with Ververica, is built on this concept of BYO-Compute. Through our strategic OEM partnership, we bring Apache Flink closer to where the data resides. Your Kafka or Pulsar data stays in your cloud, while Flink jobs run in your own VPC. You maintain ownership of the data, incur no expensive networking costs, and enjoy the same fully managed experience.
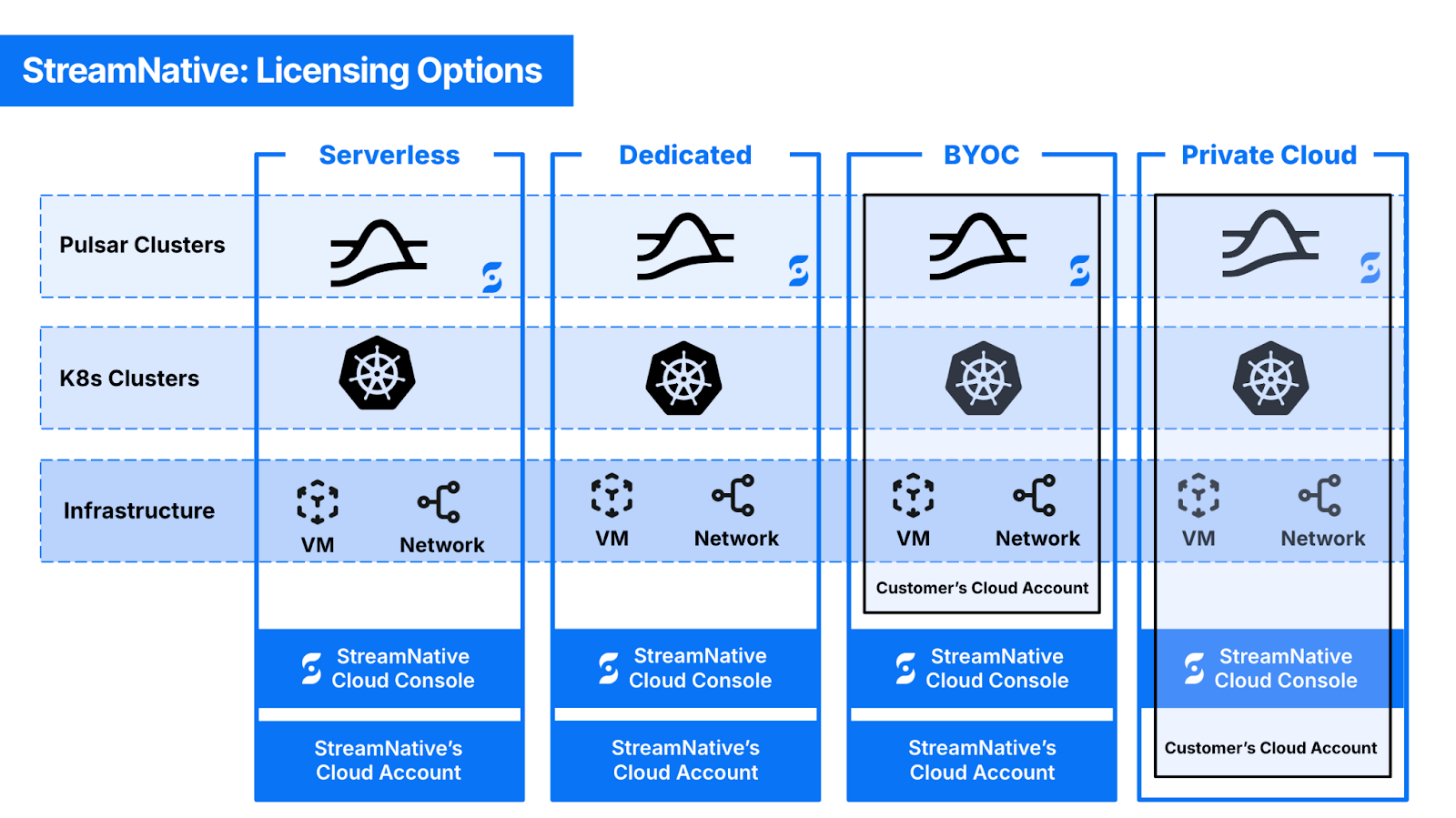
BYOC, Dedicated, Private - All You Need is a Portable Data Plane
The other part of the equation is BYO-Cloud. BYO-Cloud has gained attention recently, partly due to the WarpStream acquisition. In our view, whether it's BYO-Cloud, Dedicated/Serverless, or self-managed in a Private Cloud, what organizations truly need is a Portable Data Plane. This allows them to choose the deployment option that best suits their needs (balancing data sovereignty, a fully managed experience, and cost) while providing the flexibility to switch between options.
A Data Streaming Platform is unique in the data infrastructure landscape. It serves as both a data platform and an integration platform, crucial for an enterprise's multi-cloud and hybrid-cloud strategies. Many use cases for data streaming involve moving data between public and private clouds. Therefore, having a portable data stack that can operate seamlessly in the public cloud as a fully managed SaaS or BYOC, and in a private cloud as a self-managed solution, is essential.
While Pulsar or Kafka can run in any cloud environment, ensuring the same fully managed experience across different environments is much more challenging. To make data streaming accessible to organizations of all sizes, we designed our data plane to be a Portable Data Plane from day one.
A Portable Data Plane is one that is portable across different deployment options—suitable for Dedicated & Serverless, BYOC, and Private deployments. To make a Data Plane portable, the entire data stack running in the data plane must have no external dependencies. The unavailability of any other data plane or the centralized control plane should not affect the applications interacting with the services in the data plane.
The first step to ensure a data plane is portable is adopting the concept of immutable infrastructure, aligned with cloud-native computing philosophies. This means the entire data plane can be described as code or configuration (e.g., Terraform states, Kubernetes manifests). This code and configuration can be used to rebuild the data plane, enabling quick migration from one location to another—from one public cloud to another, or between public and private clouds.
With a portable data plane, the control plane can become lightweight and avoid being a bottleneck or a single point of failure, serving primarily as the orchestration layer.
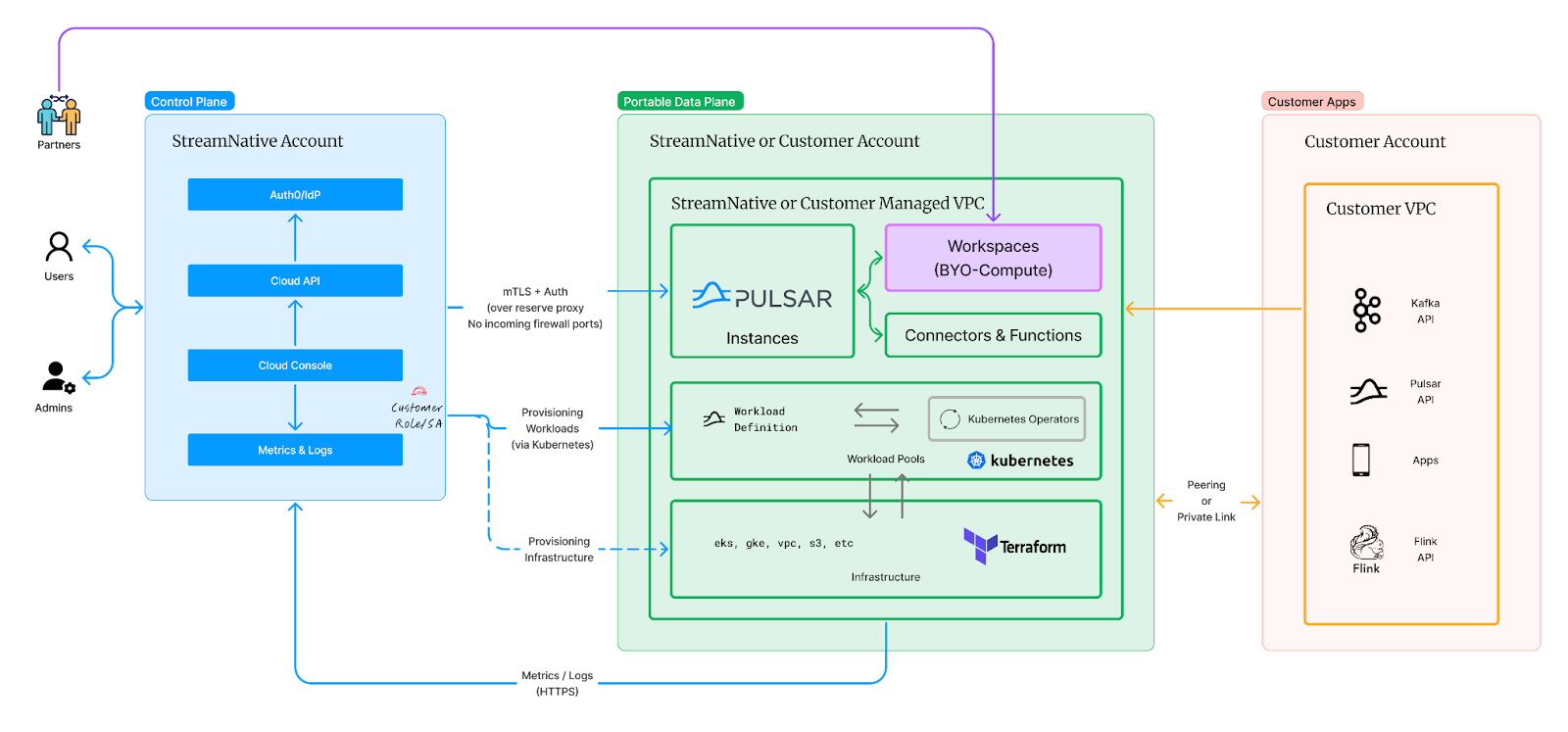
Build A Simplified Portable Cloud on Kubernetes
We have designed our Portable Data Plane in layers and embraced open standards as much as possible. Our Portable Data Plane is built around Kubernetes, the cornerstone of cloud-native computing. We divided resource provisioning into two layers: Infrastructure and Workloads. The Infrastructure layer provisions workload pools, which are collections of Kubernetes clusters used for deploying workloads. A workload can be a Pulsar cluster, a UniConn connector, a Pulsar function, or a Flink job. The infrastructure layer is managed with Terraform. Within the workload pools, all workloads are defined as Custom Resources and managed by Kubernetes operators.
In this model, the distinction between different deployment options lies in infrastructure provisioning and management. In the Dedicated/Serverless deployment model, we own, provision, and manage the infrastructure. In the BYOC deployment model, customers own the resources, and we provision and manage them on their behalf. In a Private deployment model, customers own, provision, and manage the infrastructure.
Once infrastructure is provisioned, all workloads are provisioned and managed by Kubernetes operators, making everything uniform.
The security model for BYOC becomes straightforward. We can use cross-account IAM permissions for provisioning infrastructure or delegate infrastructure provisioning to the customer using our Terraform scripts. Once infrastructure is provisioned, our control plane only requires management permissions to access the Kubernetes clusters and provision and manage workloads. The control plane's role is to propagate the manifests describing workload changes. The operators running in the data plane reconcile the state to apply these changes.
This model is simple, powerful, and secure. No closed-source agents need to be installed—everything is executed via Kubernetes API and standards, ensuring an open approach. Changes are auditable through Kubernetes tools, allowing for self-auditing. Unlike an agent-based approach, you do not have to blindly trust the vendor's promises.
If desired, you can disconnect the entire data plane by revoking our control plane's permissions to access your Kubernetes cluster, halting the propagation of changes to the clusters.
BYOC²: A New Approach Towards Data Sovereignty
Your data remains in your bucket, and you bring your own engine to process it—all within your cloud account with a fully managed experience.
Fully managed SaaS services provide excellent building blocks to develop real-time AI applications faster and bring ideas to fruition more rapidly. However, with the increasing complexity of regulations and geopolitical situations, sovereignty has become a major concern for many enterprises. While startups can quickly bring ideas to reality with fully managed SaaS services, they often relinquish ownership of their data and, consequently, access to it. In many cases, data becomes confined by SaaS providers. A simple query can incur significant costs, and access to the data is restricted to a specific API.
With BYO-Cloud, you retain ownership of the data in your bucket. We are extending this concept by collaborating with partners in the ecosystem to bring Compute Engine to the data. We believe BYOC² represents a new approach to data sovereignty throughout the entire data lifecycle, offering a more affordable solution.
We are not alone in this vision. The partnership between StreamNative and Ververica exemplifies the BYOC² model, and we are excited to collaborate with other stream processing engine vendors to provide the best tools to our customers. The future looks promising with a straightforward, portable cloud under the BYOC² framework.
We look forward to discussing these topics further at the upcoming Data Streaming Summit, scheduled for October 28-29, 2024, at the Grand Hyatt SFO. Join us for this engaging event focused on all aspects of data streaming.




