
Delivering optimal services to users while ensuring cost-effectiveness - this is the age-old problem. How can a data streaming platform be leveraged to achieve this dream?
Elastic horizontal scalability is a key feature in what makes a reality.
Indeed, a horizontally scalable system allows for supporting a significant workload by distributing it across multiple nodes on commodity hardware. A horizontally scalable system can handle a workload of any size, provided it has enough nodes available.
To maintain cost-effectiveness, resources should be allocated to match the workload, scaling the system up by adding nodes or down by removing them as needed.
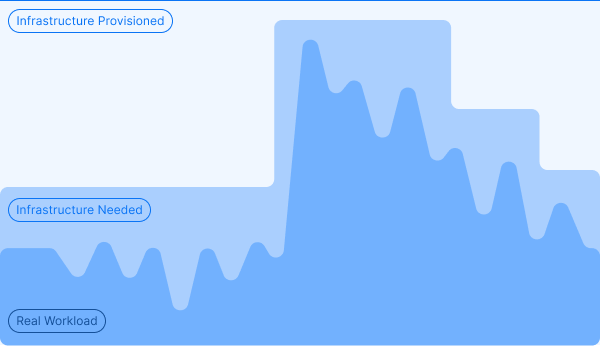
However, in the world of data streaming, not all platforms are equally elastic.
This blog post will explore scaling challenges through the experiences of Kafka users and Pulsar users.
Meet Kevin, a Kafka aficionado, and Patricia, a Pulsar professional. They work at competing e-commerce companies. Both face the task of expanding their clusters. How will their journeys unfold as they encounter challenges related to scaling a customer application, scaling the broker, and scaling the storage?

Challenge #1: scaling a consumer application
Both companies share the same architecture pattern: a microservice within their e-commerce platform generates 'Order Placed' events and publishes them to a designated topic.
There are several applications subscribing to this topic, including:
- A processing payment system. If the payment isn't successfully processed, the order will not be confirmed, and the customer will not receive their order.
- A system performing real-time analytics on the 'order placed' events, requiring a strong ordering guarantee to ensure accurate analytics.
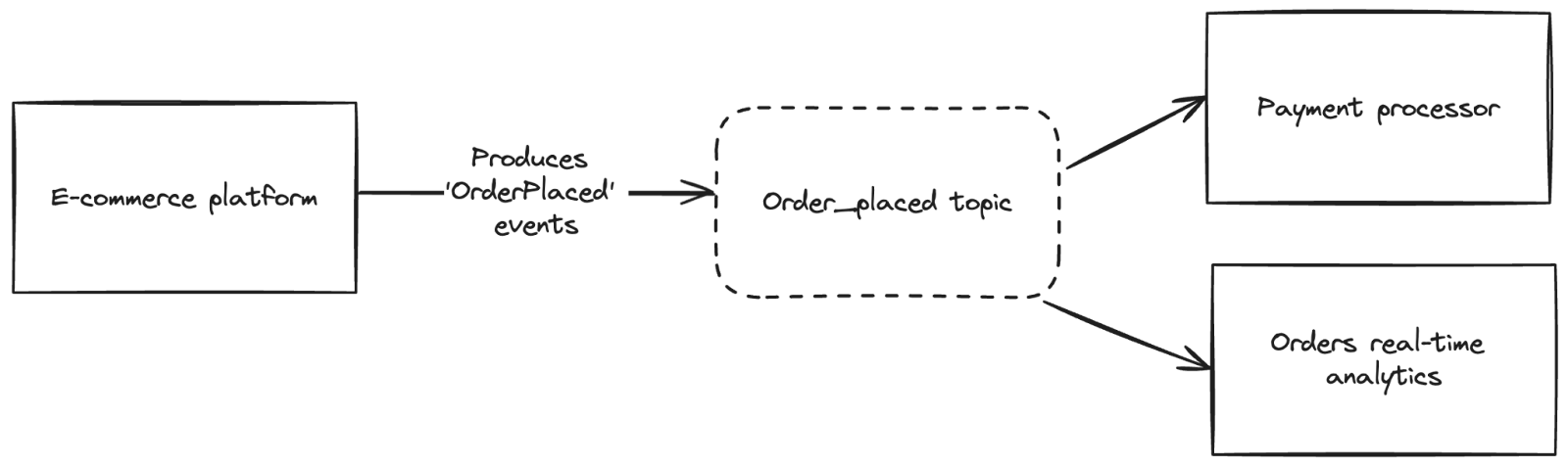
Kevin’s experience with Kafka
Kevin has received an alert indicating that the average order payment processing time is increasing, resulting in a bad experience for the customers, and a bottleneck in the processing that impacts the bottom line. He understands that the payment processing system can no longer keep up with the pace.
Fortunately, since the payment system is horizontally scalable, Kevin can launch additional consumer instances to manage the load spike and catch up on processing the remaining orders.
That sounds easy, right?
The system has 3 active consumer instances. Kevin needs to allocate 3 more to bring their number to 6.
The topic was initially structured in 3 partitions. Since with Kafka, you cannot have more active consumers than partitions in the same consumer group, Kevin must then increase the topic from 3 to 6 partitions.
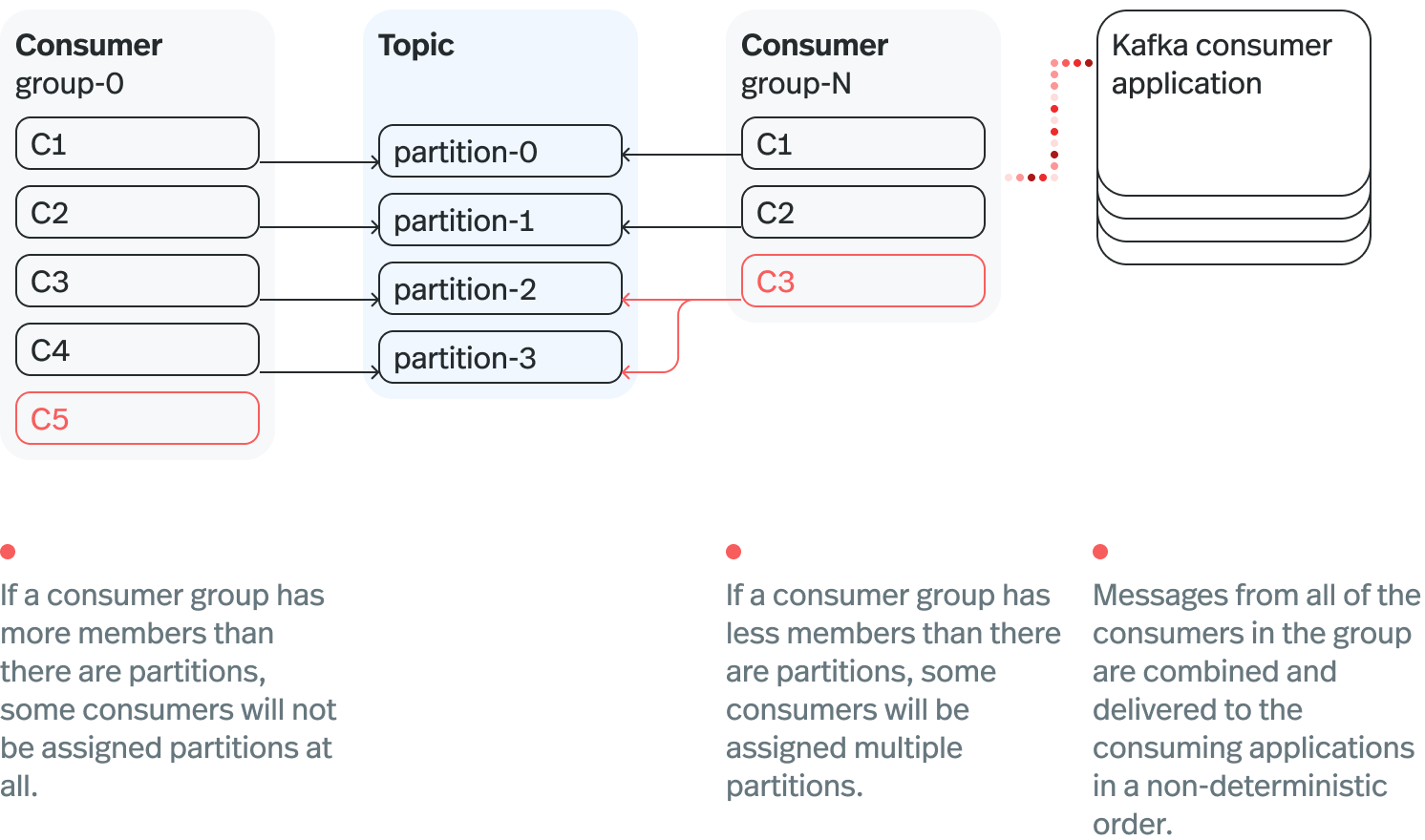
Kevin has to perform a partition rebalance to increase the number of partitions.
As a Kafka user, Kevin gets stressed out by repartitioning, especially under heavy load. But Kevin carries out the repartitioning because he has no other choice, and consequently, what he dreaded happens:
- Changing the number of partitions also disrupts the other consumer systems because it changes the order in which messages are consumed, resulting in incorrect analytics outcomes.
- Moreover, during the repartitioning, consumption has been blocked for several long minutes, worsening the customer experience.
Kevin has lost precious time, costing him customers.
Since repartitioning can be both painful and risky, Kevin needs to carefully plan the number of partitions in advance to be well-prepared for the anticipated workload. But you can’t expect the unexpected… Or can you?
Choosing the right number of partitions in advance is, indeed, a common challenge, as demonstrated by the plethora of resources on choosing the right partition count for a Kafka topic.
Kevin wonders how to prevent this issue from happening again. He might then be tempted to create extra partitions to prepare for such an unexpected surge in workload, but that leads to overprovisioning. And he still has to figure out how many of those extra partitions to create.

Patricia’s experience with Pulsar
Patricia receives the same alert. She calmly responds, simply adding new consumer instances by scaling up the pods without needing additional operations.
She almost immediately observes a decrease in the order payment processing time.
The issue is resolved in under ten minutes, without any side effects.
Thanks to the Pulsar Shared Subscription feature, Patricia doesn’t need to concern herself with the topic's structure. In Pulsar, scaling consumer instances is independent of the underlying data storage distribution, offering flexibility in system scalability.
Moreover, Patricia contemplates that implementing auto-scaling for consumers could have automatically resolved the issue, eliminating the need for her manual intervention. She realizes the simplicity of doing this with Pulsar and plans to explore it soon.
Challenge #2: expanding the cluster processing power
Kevin has a Kafka cluster scaled for a specific load and storing 100TB+ of data. As his system gains popularity, it attracts more consumers and producers and manages more topics, pushing the cluster to its limits. Kevin needs to enhance the cluster's processing power by adding new nodes to accommodate the growing demand.
Scaling Kevin’s Kafka Cluster
However, as an experienced Kafka user, Kevin knows this process can be challenging.
Indeed, the new nodes don't immediately contribute to handling the extra load. Kevin must first rebalance the data across the cluster, a resource-intensive task that affects performance and increases costs. Only after the data rebalance is complete can Kevin finally relax, knowing the cluster has been successfully scaled up.
Kevin is disappointed because when he urgently needs more processing power, he has to restructure the data storage, which impedes the system's ability to adapt to workload fluctuations quickly. Kevin recognizes that he should have anticipated this change, embodying the principle of "expecting the unexpected." However, even if you can accurately anticipate your future needs, if you request those partitions ahead of time, you will be wasting that storage until you scale up to the amount requested. As we now know, re-partitioning in the future is also costly, so there is really no way to plan for the future when expansion is painful either way.
Kevin dreams of a solution where processing power and data storage are separate entities, enabling more efficient adaptability to change.
Scaling Patricia’s Pulsar Cluster
On the other hand, Patricia simply adds more broker nodes to her Pulsar cluster to manage the increased load. That's all there is to it! There's no need for Patricia to perform any data movement; the newly added node becomes instantly available. For Patricia, Kevin's dream of decoupling storage and computing is a reality.

Challenge #3: expanding the storage capacity
Kevin must create a Kafka topic that can hold up to 100 TB of data.
Since Kevin is using Kafka, he must determine the number of partitions he needs to hold this much data, and since each of his Kafka broker nodes has 4TB of attached storage, he decides that 25 will be enough.
Kevin’s experience with expanding the storage capacity
After a few months, Kevin sees that the Kafka broker nodes are starting to fill up. This is because he forgot to account for the replica storage. So he fixes it and thinks it’s done. But…
Now, the storage requirement for this topic has increased by 20%. Kevin has to increase the number of partitions on the topic AGAIN…
It means performing a partition rebalance, moving huge amounts of data across the broker, impacting the performance… Kevin feels wary of this. He feels like he should have anticipated this, but how?
Kevin understands that enabling tiered storage may not significantly alleviate his concerns due to several factors:
- The rate of incoming data exceeds the rate at which old data is offloaded. Since the data is coming in faster than the old data can be offloaded, he will still run out of space for the new data.
- When data needs to be read from tiered-storage, it must be stored on a local disk before it is read. Since Kevin’s cluster disk space is limited, then it doesn't have space to write it, making it inaccessible. See https://aiven.io/docs/products/kafka/concepts/tiered-storage-how-it-works#data-retrieval
Patricia’s experience with expanding the storage capacity
On the other hand, Patricia, as a Pulsar user, just creates a topic with a single partition and lets the Pulsar segment-based storage layer take care of the rest. She does not need to plan the number of partitions in advance.
Each of her storage nodes comes with 4TB of attached storage, yet there's no immediate need to set up 25 nodes to store the final 100TB. For the time being, 2 nodes suffice since the topic is nowhere near reaching 100TB for now, and she requires 4 additional nodes to ensure data replication.
After a few days, the volume of data stored in the topic is approaching the maximum accumulated storage capacity of the nodes. At this point, Patricia adds 3 more nodes, and that's all there is to it—no rebalancing, no data migration, and no downtime. Just the right amount of nodes, and the new ones are instantly ready to store more data.
Patricia is quite confident in her ability to smoothly expand storage, all thanks to Pulsar's segment-based architecture that intelligently distributes the data across the cluster.

Challenge #4: cutting cluster costs
Scaling down the cluster to cut costs is a smooth process for Patricia, but for Kevin, that's a tricky proposition.
Now that the workload has been reduced, Kevin ends up with an overprovisioned Kafka cluster.
Kevin faces challenges in reducing his cluster size. Shrinking means a complex rebalancing act, AGAIN, risking system availability and performance. Kevin knows it isn’t just about pulling plugs; careful planning and execution are needed to avoid disruptions. Kevin wonders: ‘What if I could have a truly elastic platform?’
Patricia, on the other hand, has a more flexible setup with Pulsar. Downscaling consumers? Just tear down consumer instances. Downscaling the cluster? Just tear down broker nodes. Shrinking the storage? Just offload the data to external, cheap storage like S3, then remove bookie nodes. All these capabilities are built into Pulsar and have been battle-tested for years in production.
Essentially, while Kevin navigates a tightrope to optimize costs with Kafka, Patricia finds it effortless with Pulsar.

Recap
Below is a summary of Kevin and Patricia's experiences.
Challenge
Kevin - Kafka
Patricia - Pulsar
Scaling out consumers to manage an unexpected workload surge
The topic does not have enough partitions to parallelize consumption sufficiently. Kevin must then struggle to repartition the topic while minimizing the impact as much as possible.
The Pulsar partitionless subscription model allows Patricia to add more consumer instances seamlessly with peace of mind.
Expanding the processing power on the cluster
Kevin must wait for the data to rebalance across the cluster before the newly added nodes can take on the extra workload.
Patricia adds new broker nodes, immediately handling the additional workload.
Expanding the storage capacity on the cluster
Kevin must meticulously plan for the necessary storage, overprovisioning partitions and nodes.
Patricia is less concerned about these considerations. She can effortlessly expand storage capacity by adding more nodes.
Downscaling to cut costs
Shrinking the cluster by removing nodes means a painful rebalancing act for Kevin.
Patricia simply removes nodes.
Want to learn more?
To go further into these topics, feel free to:
- join David on February 22 as he delves into those challenges and explains how Pulsar addresses them: Decoding Kafka Challenges - free webinar
- Read our blog post in which Caito Scherr explores the differences between partitioning and segmentation: Data Streaming Patterns: What You Didn't Know About Partitioning
If you would rather be in Patricia's shoes instead of Kevin's:
- I invite you to try out Pulsar here: Get started | Apache Pulsar
- An excellent way to quickly get started with Pulsar in production is through StreamNative: Book a demo
Want to grasp Pulsar concepts in 10’?




