Apache Pulsar is a distributed messaging system that offers robust features such as geo-replication, which allows for the replication of data across multiple data centers or geographical regions. In this blog, I will discuss the following topics:
- How geo-replication works in Pulsar;
- How Pulsar synchronizes consumption progress across clusters;
- The problems during consumption progress synchronization in Pulsar and how we optimized the existing logic for our use case at Tencent Cloud;
- How to migrate Pulsar tenants across clusters using geo-replication.
Understanding geo-replication in Pulsar
Geo-replication in Pulsar enables the replication of messages across multiple data centers or geographical regions, providing data redundancy and disaster recovery for Pulsar topics. This ensures that your entire system remains available and resilient to failures or regional outages, maintaining data consistency and enabling low-latency access to data for consumers in different locations.
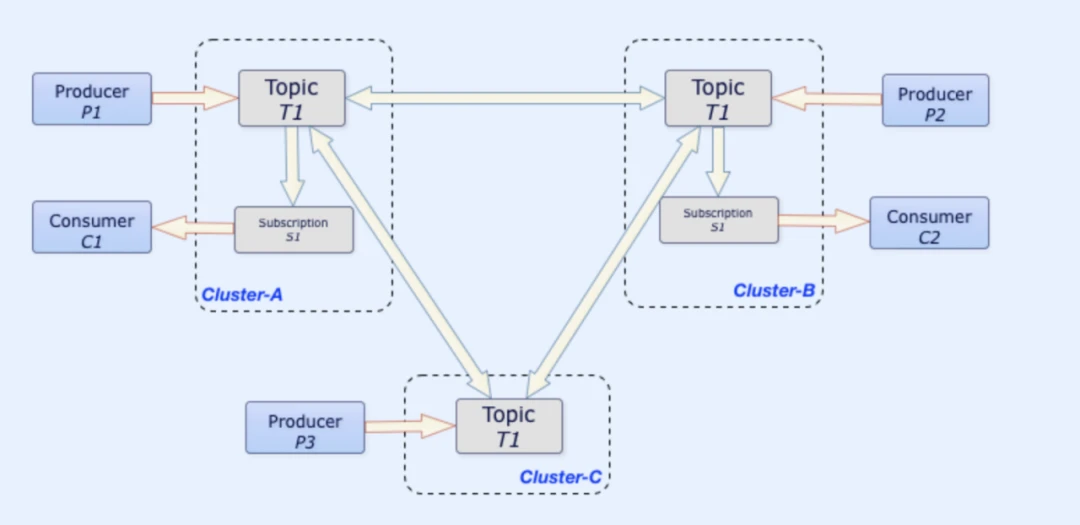 Figure 1. Geo-replication in Pulsar
A typical use case of geo-replication is that producers and consumers can be located in separate regions. For example, producers can be located in San Francisco while consumers may be in Houston. This can happen in cases where latency requirements between message production and consumption are low. The benefit is that it ensures all writes occur in the same place with a low write latency. After data is replicated to different locations, consumers can all read messages no matter where they are.
Figure 1. Geo-replication in Pulsar
A typical use case of geo-replication is that producers and consumers can be located in separate regions. For example, producers can be located in San Francisco while consumers may be in Houston. This can happen in cases where latency requirements between message production and consumption are low. The benefit is that it ensures all writes occur in the same place with a low write latency. After data is replicated to different locations, consumers can all read messages no matter where they are.
How does geo-replication work?
The logic behind Pulsar's geo-replication is quite straightforward. Typically, if you want to replicate data across regions (without using Pulsar’s geo-replication), you may want to create a service that includes both a consumer and a producer. The consumer retrieves data from the source cluster, and the producer sends the data to the target cluster. Pulsar’s geo-replication feature follows a similar pattern as depicted in Figure 2.
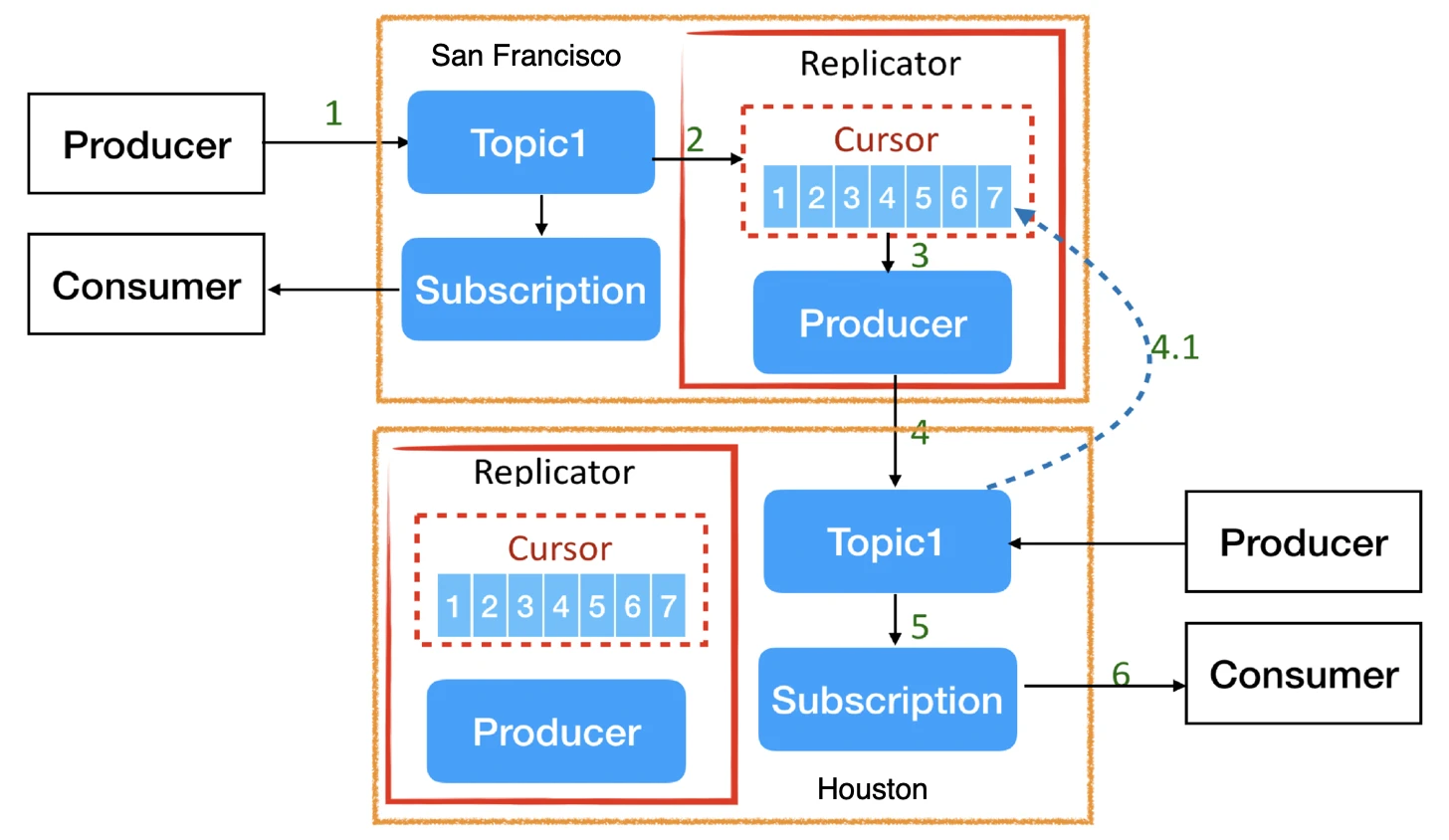 Figure 2. How geo-replication works in Pulsar
If you enable geo-replication, Pulsar creates a Replication Cursor and a Replication Producer for each topic. The Replication Producer retrieves messages from the local cluster and dispatches them to the target cluster. The Replication Cursor is used to track the data replication process using an internal subscription. Similarly, if a producer sends messages to the target cluster, it can also create its own Replication Cursor and Producer to dispatch the messages back to the source cluster. The replication process does not impact message reads and writes in the local cluster.
Figure 2. How geo-replication works in Pulsar
If you enable geo-replication, Pulsar creates a Replication Cursor and a Replication Producer for each topic. The Replication Producer retrieves messages from the local cluster and dispatches them to the target cluster. The Replication Cursor is used to track the data replication process using an internal subscription. Similarly, if a producer sends messages to the target cluster, it can also create its own Replication Cursor and Producer to dispatch the messages back to the source cluster. The replication process does not impact message reads and writes in the local cluster.
Understanding consumption progress synchronization
In some use cases, it is necessary to synchronize the consumption progress of subscriptions between clusters located in different regions. In a disaster recovery scenario, for example, if the primary data center in San Francisco experiences an outage, you must switch to a backup cluster in Houston to continue your service. In this case, clients should be able to continue consuming messages from the Houston cluster from where they left off in the primary cluster.
If the consumption progress is not synchronized, it would be difficult to know which messages have already been consumed in the primary data center. If a client starts consuming messages from the latest position, it might lead to message loss; if it starts from the earliest message, it could result in duplicate consumption. Both ways are usually unacceptable to the client. A possible compromise is to rewind topics to a specific message and begin reading from there. However, this approach still can’t guarantee messages are not lost or repeatedly consumed.
To solve this issue, Pulsar supports consumption progress synchronization for subscriptions so that users can smoothly transition to a backup cluster during disaster recovery without worrying about message duplication or loss. Figure 3 shows an example where both messages and consumption progress are synchronized between Cluster-A and Cluster-B.
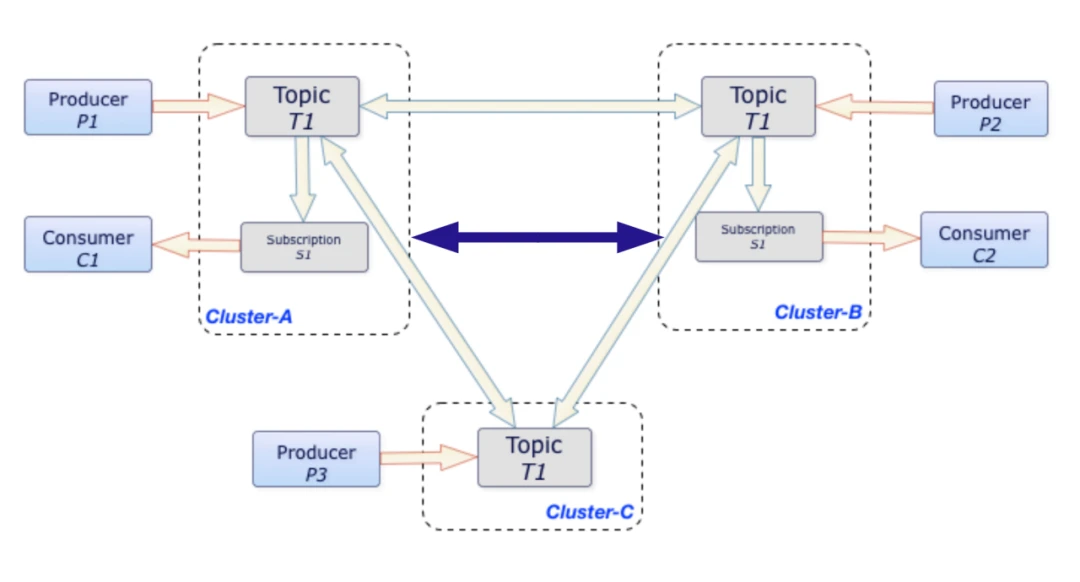 Figure 3. Consumption progress synchronization between Cluster-A and Cluster-B
Figure 3. Consumption progress synchronization between Cluster-A and Cluster-B
How does Pulsar track consumption progress?
Before I explain how consumption progress is synchronized between clusters, let’s first understand the consumption tracking mechanism in Pulsar, which leverages two important attributes - markDeletePosition and individuallyDeletedMessages.
markDeletePosition is similar to the consumer offset in Kafka. The message marked by markDeletePosition and all the preceding messages have been acknowledged, which means they are ready for deletion.
individuallyDeletedMessages is what sets Pulsar apart from most streaming and messaging systems. Unlike them, Pulsar supports both selective and cumulative acknowledgments. The former allows consumers to individually acknowledge entries, the information of which is stored in individuallyDeletedMessages.
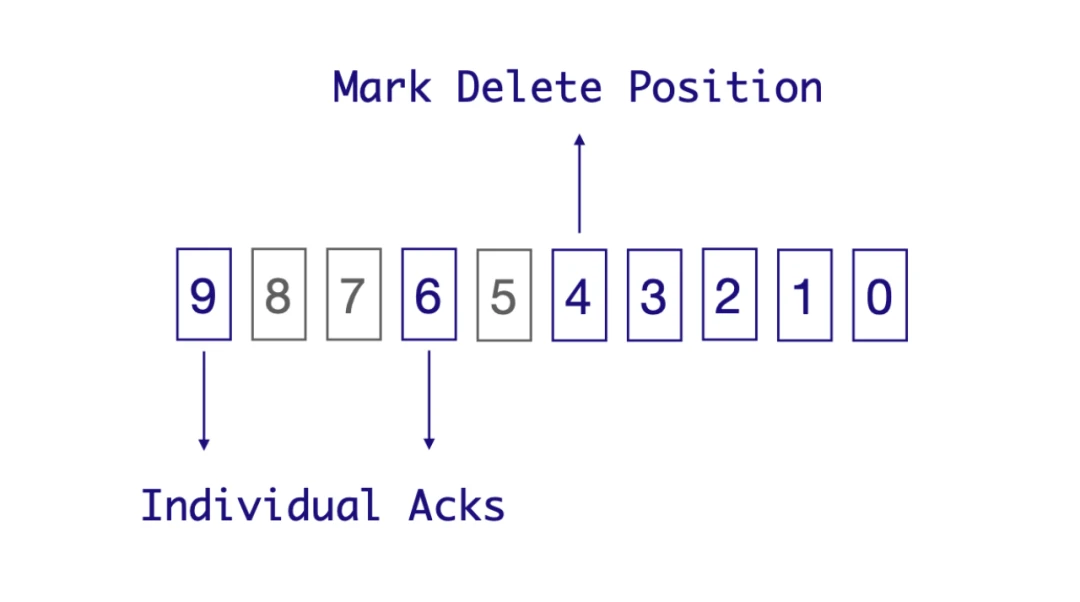 Figure 4. markDeletePosition and individuallyDeletedMessages
As illustrated in Figure 4, let’s consider a shared subscription with multiple consumer instances. Messages from 0 to 9 are distributed to all of them. Each consumer may consume messages at different speeds, so the order of message delivery and acknowledgment may vary. Suppose messages 0, 1, 2, 3, 4, 6, and 9 have been acknowledged, while messages 5, 7, and 8 have not. The markDeletePosition marker, which represents the consumption progress, points to message 4, indicating that all messages before 4 (inclusive) have been successfully consumed. If you check the statistics of the topic (pulsar-admin topics stats), you can see that markDeletePosition and individuallyDeletedMessages have the following values:
Figure 4. markDeletePosition and individuallyDeletedMessages
As illustrated in Figure 4, let’s consider a shared subscription with multiple consumer instances. Messages from 0 to 9 are distributed to all of them. Each consumer may consume messages at different speeds, so the order of message delivery and acknowledgment may vary. Suppose messages 0, 1, 2, 3, 4, 6, and 9 have been acknowledged, while messages 5, 7, and 8 have not. The markDeletePosition marker, which represents the consumption progress, points to message 4, indicating that all messages before 4 (inclusive) have been successfully consumed. If you check the statistics of the topic (pulsar-admin topics stats), you can see that markDeletePosition and individuallyDeletedMessages have the following values:
"markDeletePosition": "1:4",
"individuallyDeletedMessages": "[(1:5‥1:6], (1:8‥1:9]]",
These values are essentially message IDs and intervals. A message ID consists of a ledger ID and an entry ID. A left-open and right-closed interval means the message at the beginning of this interval has not been acknowledged while the message at the end has.
Message ID inconsistency across clusters
The complexity of consumption progress synchronization lies in the ID inconsistency of the same message across different clusters. It’s impossible to ensure that the ledger ID and the entry ID of the same message are consistent. In Figure 5, for example, the ID of message A is 1:0 in cluster A while it is 3:0 in cluster B.
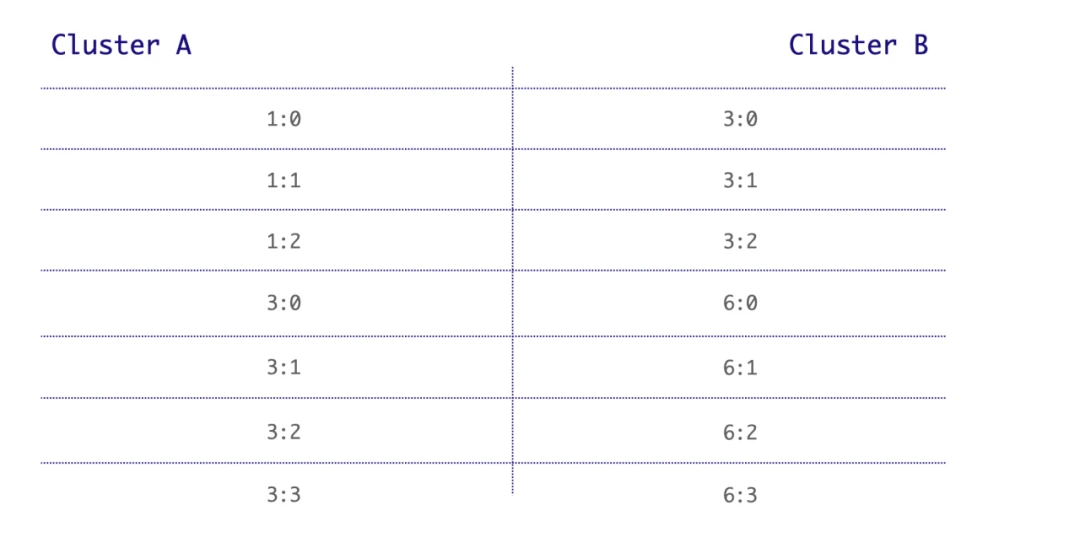 Figure 5. Message ID inconsistency across clusters
If the message IDs for the same message were consistent across both clusters, synchronizing consumption progress would be very simple. For instance, if a message with ID 1:2 is consumed in cluster A, cluster B could simply acknowledge message 1:2. However, messages IDs can hardly be the same across clusters and without knowing the relation of different message IDs across clusters, how can we synchronize the consumption progress?
Figure 5. Message ID inconsistency across clusters
If the message IDs for the same message were consistent across both clusters, synchronizing consumption progress would be very simple. For instance, if a message with ID 1:2 is consumed in cluster A, cluster B could simply acknowledge message 1:2. However, messages IDs can hardly be the same across clusters and without knowing the relation of different message IDs across clusters, how can we synchronize the consumption progress?
Cursor snapshots
Pulsar uses cursor snapshots to let clusters know how different message IDs are related to each other.
As shown in Figure 6 and the code snippet below, when acknowledging a message, Cluster A immediately creates a snapshot and sends a ReplicatedSubscriptionsSnapshotRequest to both Cluster B and Cluster C. It requires them to tell it the respective IDs of this message in Cluster B and Cluster C.
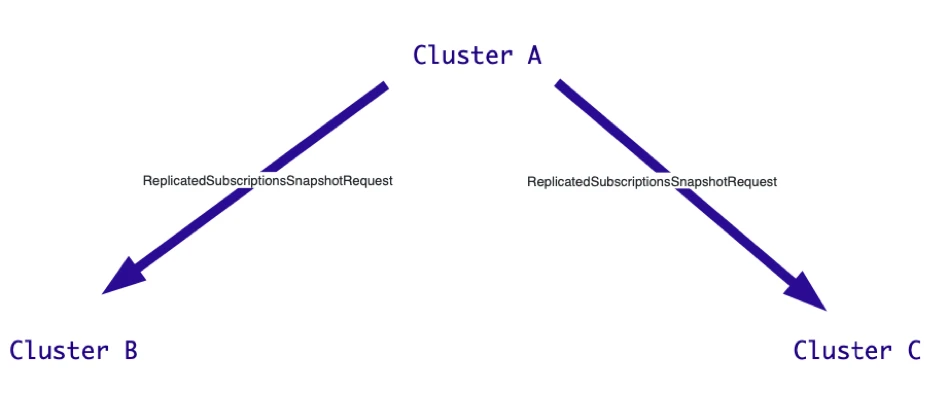 Figure 6. Cluster A sends a ReplicatedSubscriptionsSnapshotRequest to both clusters
Figure 6. Cluster A sends a ReplicatedSubscriptionsSnapshotRequest to both clusters
"ReplicatedSubscriptionsSnapshotRequest" : {
"snapshot_id" : "444D3632-F96C-48D7-83DB-041C32164EC1",
"source_cluster" : "a"
}
Upon receiving the request from Cluster A, Cluster B (and Cluster C) responds with the ID of this message in its cluster. See the code snippet below for details.
"ReplicatedSubscriptionSnapshotResponse" : {
"snapshotid" : "444D3632-F96C-48D7-83DB-041C32164EC1",
"cluster" : {
"cluster" : "b",
"message_id" : {
"ledger_id" : 1234,
"entry_id" : 45678
}
}
}
After receiving the message IDs from Cluster B and Cluster C, Cluster A stores them in the cursor snapshot as below. This allows Pulsar to know which messages should be acknowledged in Cluster B and Cluster C when the same message is acknowledged in Cluster A.
{
"snapshot_id" : "444D3632-F96C-48D7-83DB-041C32164EC1",
"local_message_id" : {
"ledger_id" : 192,
"entry_id" : 123123
},
"clusters" : [
{
"cluster" : "b",
"message_id" : {
"ledger_id" : 1234,
"entry_id" : 45678
}
},
{
"cluster" : "c",
"message_id" : {
"ledger_id" : 7655,
"entry_id" : 13421
}
}
],
}
Let’s look at the implementation in more detail. Based on cursor snapshots, Pulsar creates the corresponding snapshot markers and puts them between messages within the original topic. When the consumer reaches the snapshot marker, it will be loaded into memory. With message 3 acknowledged in Cluster A (i.e. markDeletePosition moves to message 3), the markDeletePosition of the same messages in Cluster B and Cluster C will also be updated.
 Figure 7. Snapshot marker
In the example in Figure 8, Cluster A has two snapshots on message 1:2 and message 1:6 respectively. When the markDeletePosition of Cluster A points to message 1:4, the markDeletePosition of Cluster B can move to message 3:4 as it knows the same message has already been acknowledged according to the snapshot.
Figure 7. Snapshot marker
In the example in Figure 8, Cluster A has two snapshots on message 1:2 and message 1:6 respectively. When the markDeletePosition of Cluster A points to message 1:4, the markDeletePosition of Cluster B can move to message 3:4 as it knows the same message has already been acknowledged according to the snapshot.
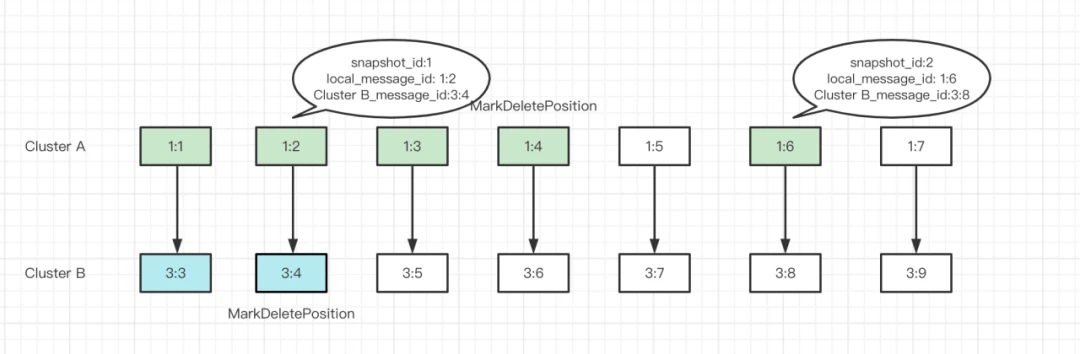 Figure 8. How cursor snapshots work in Pulsar
Note that Figure 8 is a very simple illustration of how Pulsar synchronizes consumption progress across clusters. This process includes many details and explaining all of them requires a separate blog post. If you are interested in this topic, I am willing to share more in the Pulsar community.
Figure 8. How cursor snapshots work in Pulsar
Note that Figure 8 is a very simple illustration of how Pulsar synchronizes consumption progress across clusters. This process includes many details and explaining all of them requires a separate blog post. If you are interested in this topic, I am willing to share more in the Pulsar community.
Problems in consumption progress synchronization
Before diving into tenant migration across clusters, I would like to analyze three major problems during consumption progress synchronization. These issues are the primary obstacles in tenant migration.
No synchronization for individuallyDeletedMessages
The current implementation ensures that markDeletePosition is synchronized across different clusters but individuallyDeletedMessages is not. This can lead to a large number of unacknowledged messages (namely acknowledgment holes), particularly impacting scenarios with delayed messages. If a topic contains a delayed message set to be delivered one day later, the acknowledgment of it will be postponed by a day. In this case, markDeletePosition can only point to the latest acknowledged message before the delayed message; if you switch to a new cluster, it will result in duplicate message consumption. This is because the new cluster does not know which individual messages after markDeletePosition have already been acknowledged in the primary cluster (in other words, individuallyDeletedMessages is not synchronized).
Synchronization blocked by message backlogs
In the previous examples (Figure 6 and Figure 7), Cluster A doesn’t send requests through an RPC interface. Instead, snapshot markers are written into the topic alongside other messages. If the target cluster (Cluster B) has a large message backlog, requests sent by the primary cluster (Cluster A) may remain unprocessed for a long time (there is an internal timeout mechanism waiting for the target cluster's response for 30 seconds). As a result, the snapshot cannot be successfully created, preventing synchronization of consumption progress and markDeletePosition.
Periodic creation of cursor snapshots
Pulsar does not create a cursor snapshot for every message. Instead, snapshots are created periodically. In Figure 8, only message 1:2 and message 1:6 have snapshots; it is impossible for Cluster B to know markDeletePosition points to 1:4 in Cluster A, so it cannot acknowledge the same message in its own cluster.
Optimizing the consumption progress synchronization logic
The issues mentioned above can cause duplicate consumption of messages. For our online business, a small amount of short-term and controllable duplicate consumption may be acceptable, but it makes no sense if clients need to consume an excessive number of duplicate messages.
As such, we optimized the existing logic by synchronizing both markDeletePosition and individuallyDeletedMessages before migration. However, establishing the connections of message IDs for the same messages between different clusters still remained the most challenging part.
To solve this issue, we added the originalClusterPosition and the entry position to the message’s metadata when sending a message from the original cluster to the target cluster. originalClusterPosition is used to store the message ID in the original cluster. See Figure 9 for details.
 Figure 9. Introducing originalClusterPosition in the message metadata
The updated logic allows us to easily retrieve the ID of a message in the primary cluster according to originalClusterPosition and compare it with the information of individuallyDeletedMessages synchronized to the target cluster. This way, messages that have already been acknowledged in the primary cluster will not be sent to the consumers of the target cluster.
Figure 9. Introducing originalClusterPosition in the message metadata
The updated logic allows us to easily retrieve the ID of a message in the primary cluster according to originalClusterPosition and compare it with the information of individuallyDeletedMessages synchronized to the target cluster. This way, messages that have already been acknowledged in the primary cluster will not be sent to the consumers of the target cluster.
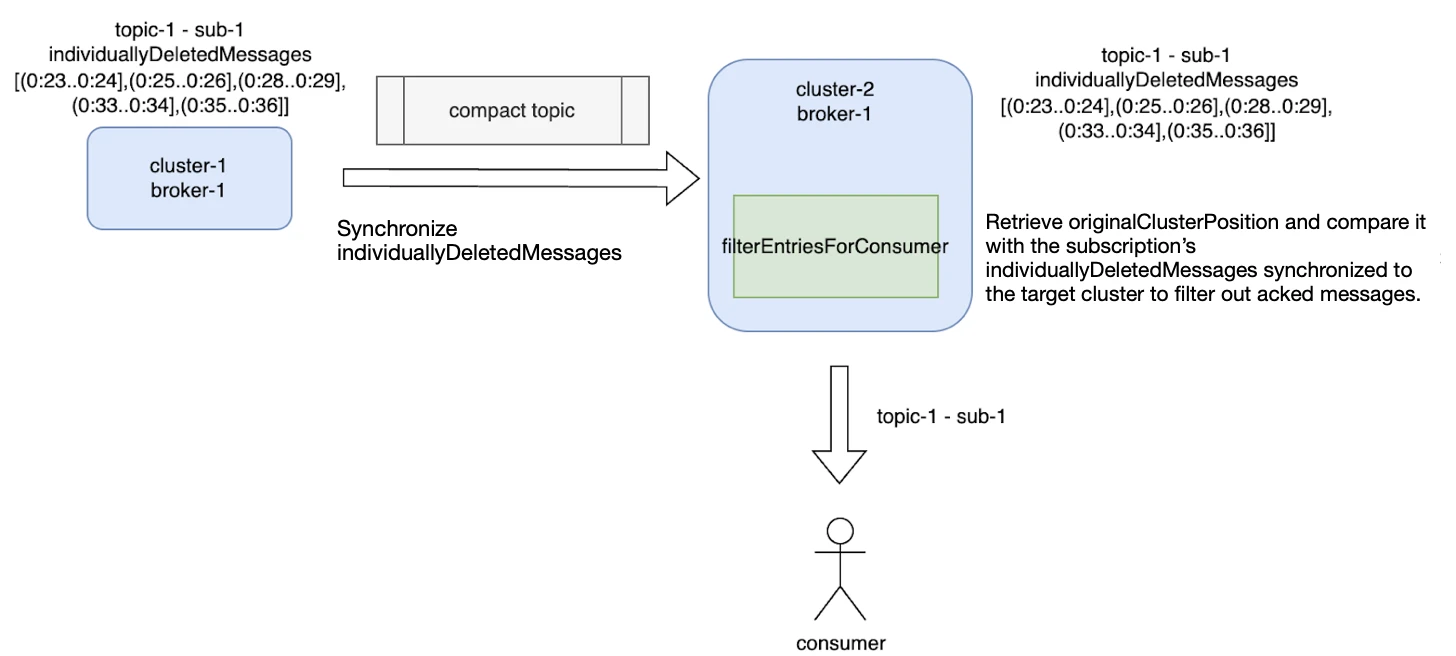 Figure 10. How acknowledged messages are filtered out with the updated logic
Figure 10 shows the implementation logic in more detail. Before migration, we need to synchronize individuallyDeletedMessages from the primary cluster (cluster-1) to the target cluster (cluster-2). Before sending messages to consumers, we use the filterEntriesForConsumer method to filter out messages already consumed in cluster-1 and only push unacknowledged messages to the consumers of cluster-2.
Figure 10. How acknowledged messages are filtered out with the updated logic
Figure 10 shows the implementation logic in more detail. Before migration, we need to synchronize individuallyDeletedMessages from the primary cluster (cluster-1) to the target cluster (cluster-2). Before sending messages to consumers, we use the filterEntriesForConsumer method to filter out messages already consumed in cluster-1 and only push unacknowledged messages to the consumers of cluster-2.
The updated logic above represents “a shift in thinking”. In the original implementation, the primary cluster periodically creates snapshots to figure out the relations of messages between clusters. After messages are acknowledged in the primary cluster, they can be acknowledged in target clusters based on the snapshots. By contrast, our implementation puts message position information directly into the metadata instead of using a separate entity to synchronize the consumption progress. This approach keeps duplicate consumption within an acceptable range.
Migrating tenants across Pulsar clusters
Previously, we were using shared physical clusters at Tencent Cloud to support different business scenarios. However, this could lead to mutual interference between users. Additionally, different users may have different service SLA requirements. For those who demand higher service quality, we may need to set up a dedicated cluster to physically isolate resources to reduce the impact on other users. In such cases, we need a smooth migration plan.
Figure 11 shows the diagram of our internal implementation for tenant migration across Pulsar clusters. The core module, LookupService, handles clients’ lookup requests. It stores the map of each tenant to the corresponding physical cluster. When a client’s lookup request arrives, we forward it to the associated physical cluster, allowing the client to establish connections with the broker. Note that LookupService also acts as the proxy for getPartitionState, getPartitionMetadata, and getSchema requests. However, it does not proxy data stream requests, which are sent directly to the cluster via CLB or VIP without going through LookupService.
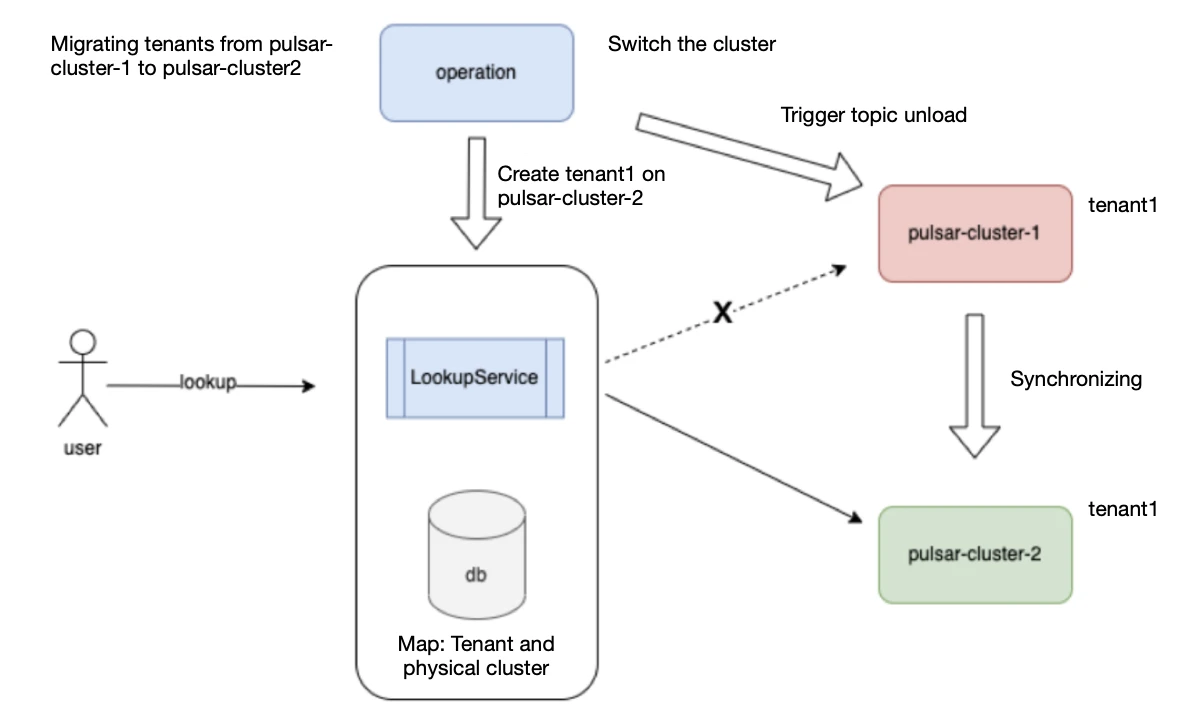 Figure 11. Tenant migration
Figure 11. Tenant migration
Note: LookupService is not designed specifically for cross-cluster migration. Its primary purpose is to provide centralized processing of different network service routes for cloud clusters. During cross-cluster migration, we used LookupService to ensure a smooth cluster switch while utilizing Pulsar’s geo-replication feature to synchronize data.
Now, let’s look at the five steps during migration:
 Figure 12. Data migration process
Figure 12. Data migration process
- Synchronize metadata: Create the corresponding resources on the target cluster, such as tenants, namespaces, topics, subscriptions, and roles.
- Synchronize topic data: Enable geo-replication to migrate the topic data of each tenant.
- Synchronize consumption progress: Enable consumption progress synchronization to synchronize each subscription’s individuallyDeletedMessages and markDeleteMessages to the target cluster.
- Switch to the new cluster: Modify the tenant-to-physical cluster map in LookupService and trigger topic unload so that clients can renew the server’s IP address. LookupService will return the address of the new cluster based on the new map.
- Clean up resources: Delete unnecessary resources in the original cluster after the migration is complete.
Conclusion
There are many ways to migrate your data across clusters. In this article, I shared a method with low implementation costs, less complexity, and high reliability on the public cloud. This approach allows for a smooth migration without modifying Pulsar’s protocol on the client and server sides.
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community driving innovation and improvements to the project. Check out the following resources to learn more about Pulsar.
- Start your on-demand Pulsar training today with StreamNative Academy
- Geo-replication use cases
- Doc Geo-replication
- Blog Client Optimization: How Tencent Maintains Apache Pulsar Clusters with over 100 Billion Messages Daily
- Blog 600K Topics Per Cluster: Stability Optimization of Apache Pulsar at Tencent Cloud




