
As organizations modernize their data platforms, the convergence of real-time streaming and lakehouse architectures is becoming essential. Enterprises increasingly want the ability to move streaming data directly into governed lakehouse tables without complex pipelines, duplicate storage, or operational overhead.
Today, StreamNative is announcing that we've collaborated with Google Cloud to integrate StreamNative's Kafka service with BigLake metastore. The integration is now available in Private Preview.
With StreamNative's Kafka service powered by Ursa, organizations can more seamlessly stream Kafka topics into Apache Iceberg tables managed by the BigLake, enabling a unified real-time data foundation for analytics and AI workloads.
This integration enables StreamNative to bridge operational streaming systems and analytical lakehouse platforms through open standards such as Apache Iceberg and the Iceberg REST catalog, simplifying how enterprises build real-time lakehouse architectures.
Bringing Streaming and the Lakehouse Together
Traditionally, Kafka data needed multiple connectors, ETL jobs, and batch pipelines before it could be analyzed in a lakehouse. This introduced:
- Data duplication
- Operational complexity
- Pipeline latency
- Governance fragmentation
StreamNative's lakehouse architecture eliminates these challenges by enabling direct streaming from Kafka topics into Iceberg tables registered in BigLake metastore, simplifying both ingestion and governance.
As outlined in the architecture, StreamNative enables streaming topics to be materialized directly as Iceberg tables governed through BigLake metastore services.
How the Integration Works
StreamNative Kafka service uses its lakehouse integration capabilities to stream topic data into Iceberg tables while leveraging BigLake metastore for metadata management and governance.
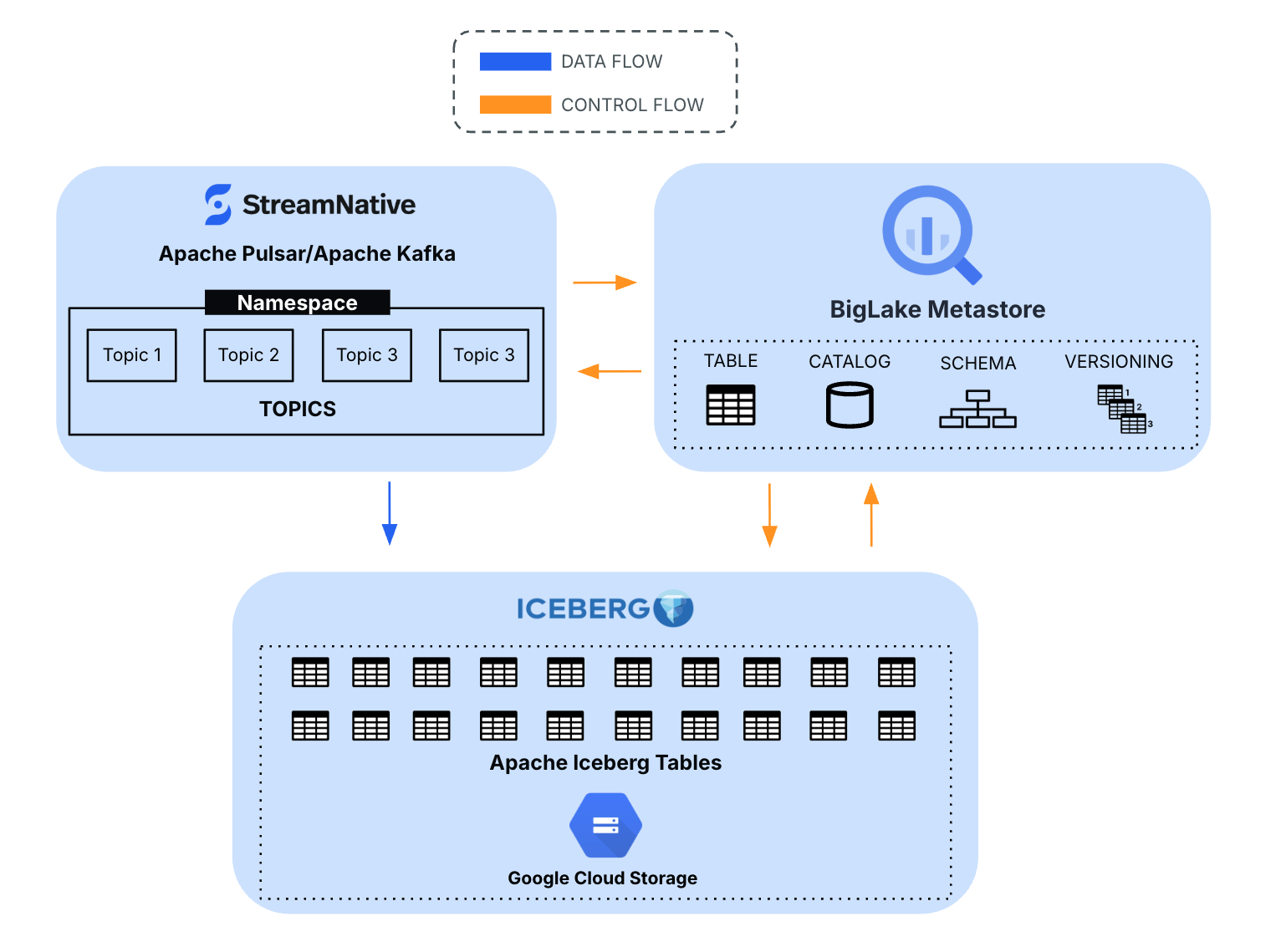
Integration Flow
- Applications produce data into StreamNative Kafka topics
- StreamNative Ursa writes data into Iceberg table format
- Iceberg metadata is managed through BigLake metastore APIs
- Data is stored in Google Cloud Storage
- BigQuery and other analytics engines can query the data
This approach allows organizations to treat streaming data as immediately queryable analytical datasets.
The integration supports:
- Streaming topics as Iceberg tables
- Native integration with BigLake metastore
- Apache Iceberg REST catalog support
- Development preview availability
Architecture Overview
StreamNative Kafka service uses Ursa's decoupled compute and storage architecture to enable efficient lakehouse integration.
Key architectural capabilities include:
- Leaderless architecture - Reduces inter-zone data transfer costs.
- Object storage based persistence - Uses Google Cloud Storage for cost-efficient storage.
- Compute-storage separation - Enables independent scaling of streaming and storage workloads.
- Native lakehouse streaming - Eliminates connector overhead.
- Catalog integration - Reduces duplicate data copies through unified metadata.
These design principles allow organizations to significantly reduce Kafka infrastructure costs while improving analytical readiness.
Built on StreamNative Ursa Lakehouse Architecture
This integration is powered by Ursa, StreamNative's cloud-native storage engine designed to unify streaming and lakehouse architectures.
Ursa enables:
- Direct streaming into Iceberg tables
- Separation of compute and storage
- Multi-protocol access (Kafka and Pulsar)
- Multi-modal workloads (stream + table)
The architecture allows Kafka topics to become governed lakehouse datasets with minimal operational overhead.
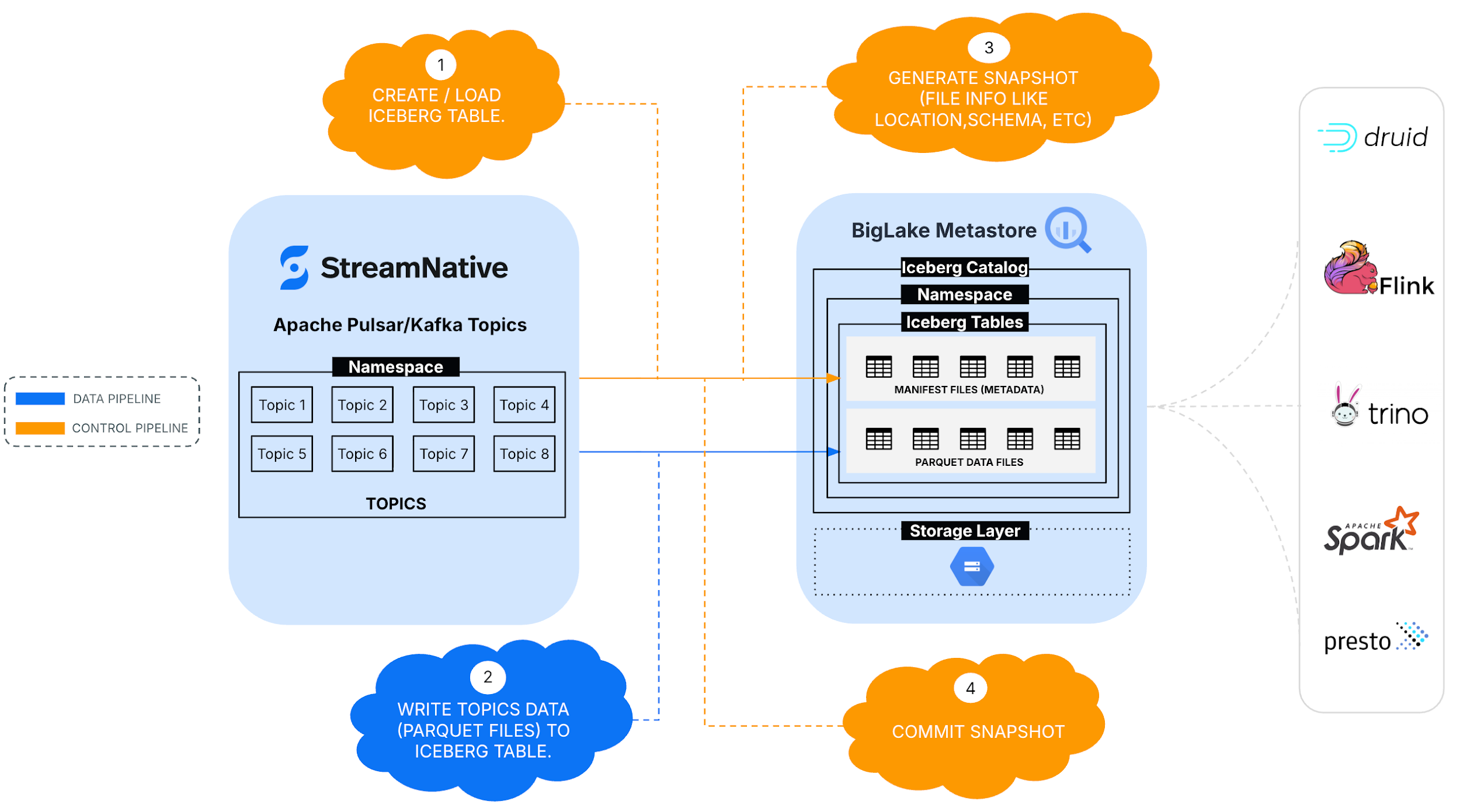
Streaming Topics data to Managed Iceberg Tables
This section outlines the steps required to configure StreamNative's Kafka service to stream data into BigLake metastore's catalog as Iceberg tables.
Step 1: Register the BigLake metastore catalog in StreamNative Cloud
Register your BigLake metastore catalog in StreamNative Cloud to enable topic-to-table streaming.
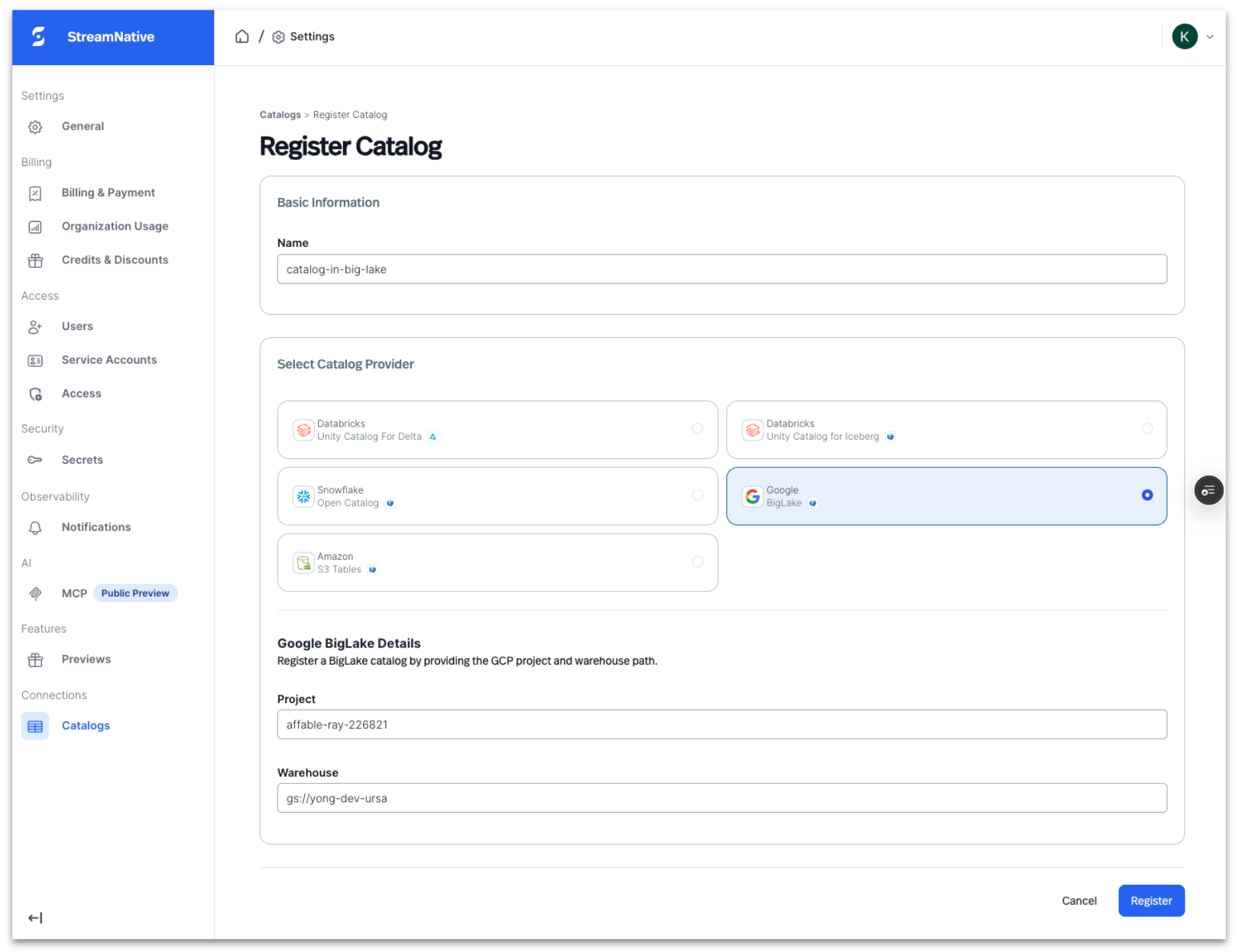
- Navigate to Lakehouse Catalogs in StreamNative Cloud
- Select Register Catalog and choose the BigLake metastore catalog
- Provide Google Cloud project id, Warehouse name (Catalog name)
- Validate connectivity to enable metadata discovery
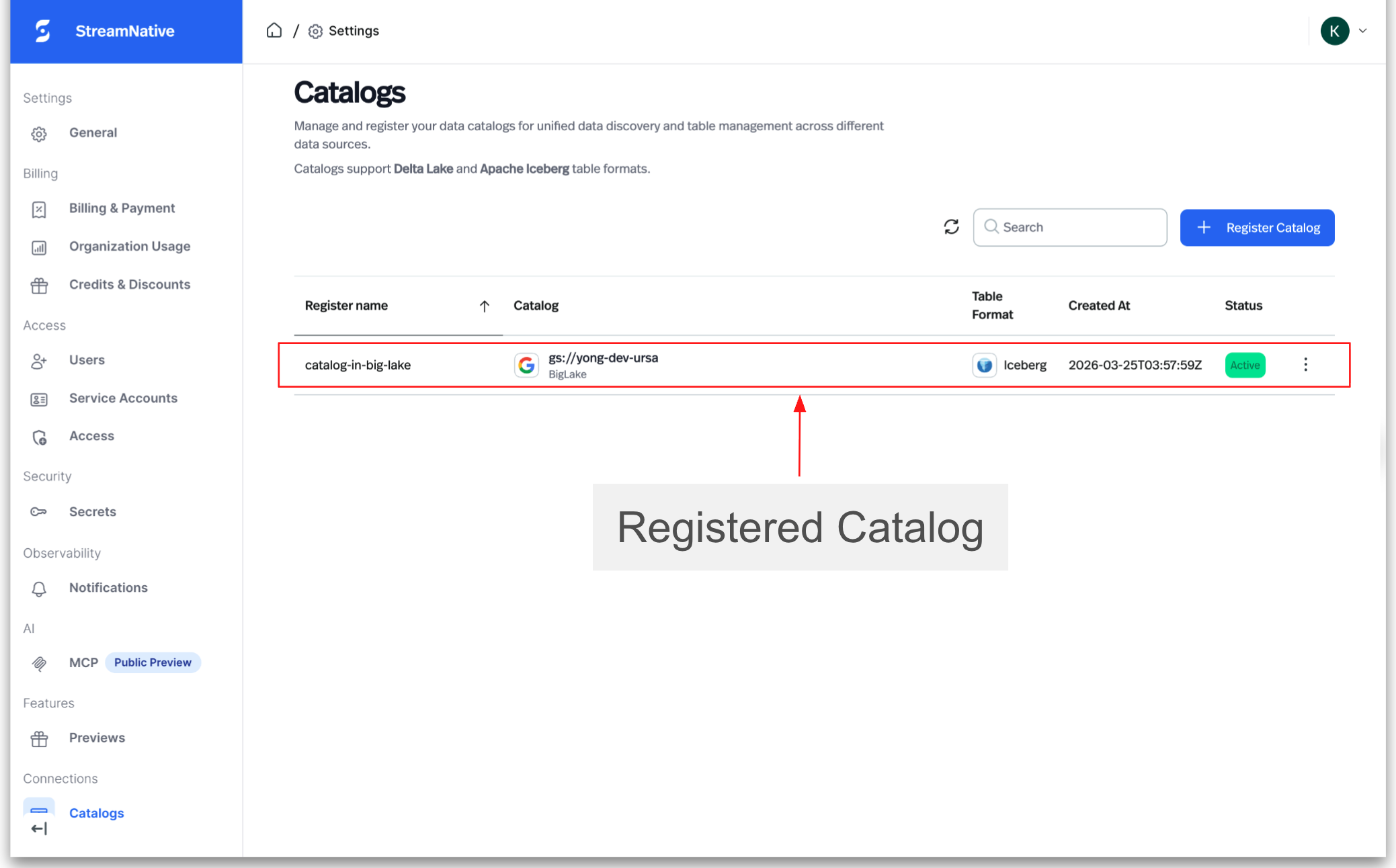
Once registered, StreamNative can map Kafka topics to Iceberg tables within the selected catalog.
Step 2: Create a Kafka Cluster In StreamNative Cloud
- Create a Kafka cluster in StreamNative Cloud and associate it with the registered catalog.
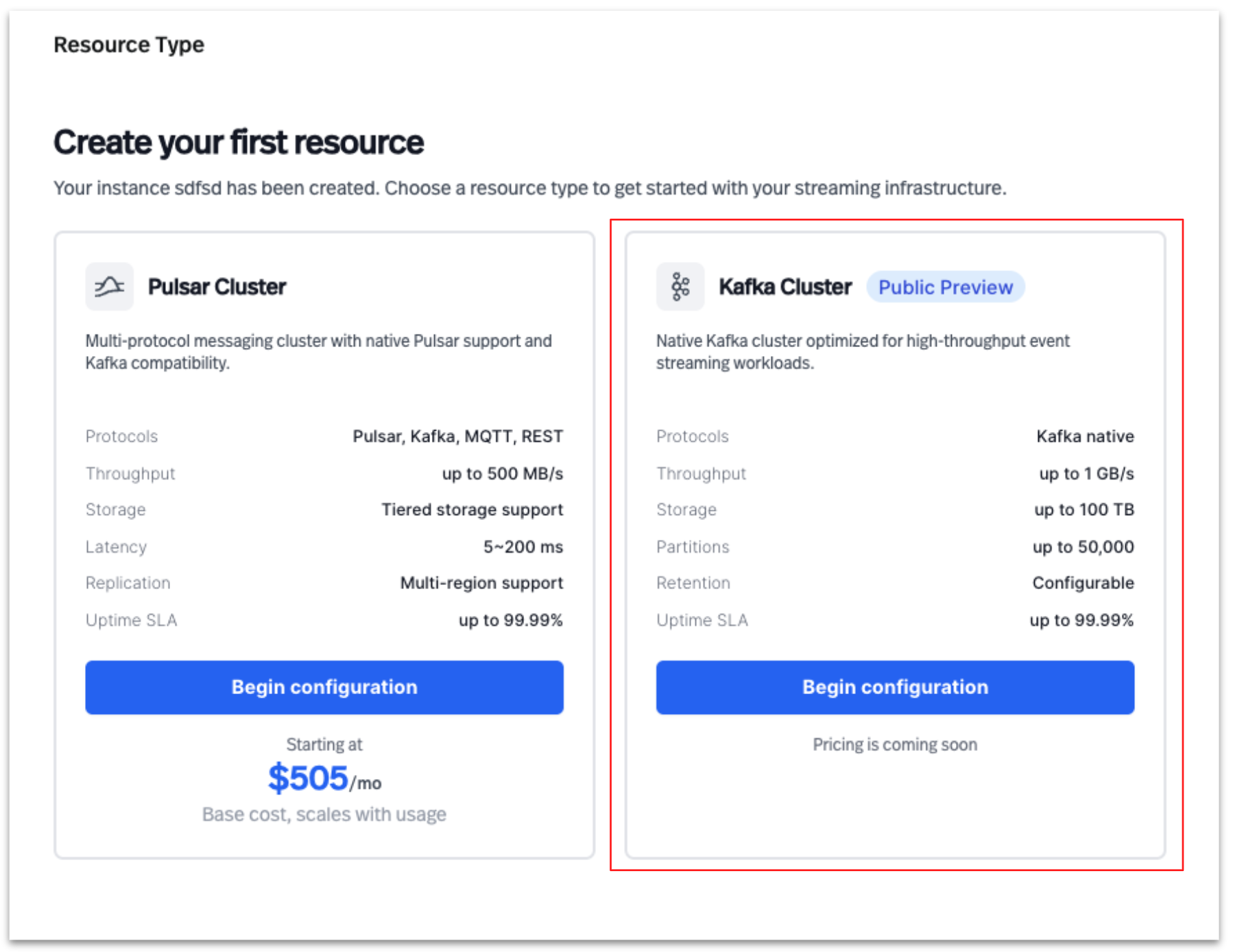
- Create a Kafka cluster
- Select Kafka Cluster to create a new cluster in StreamNative Cloud
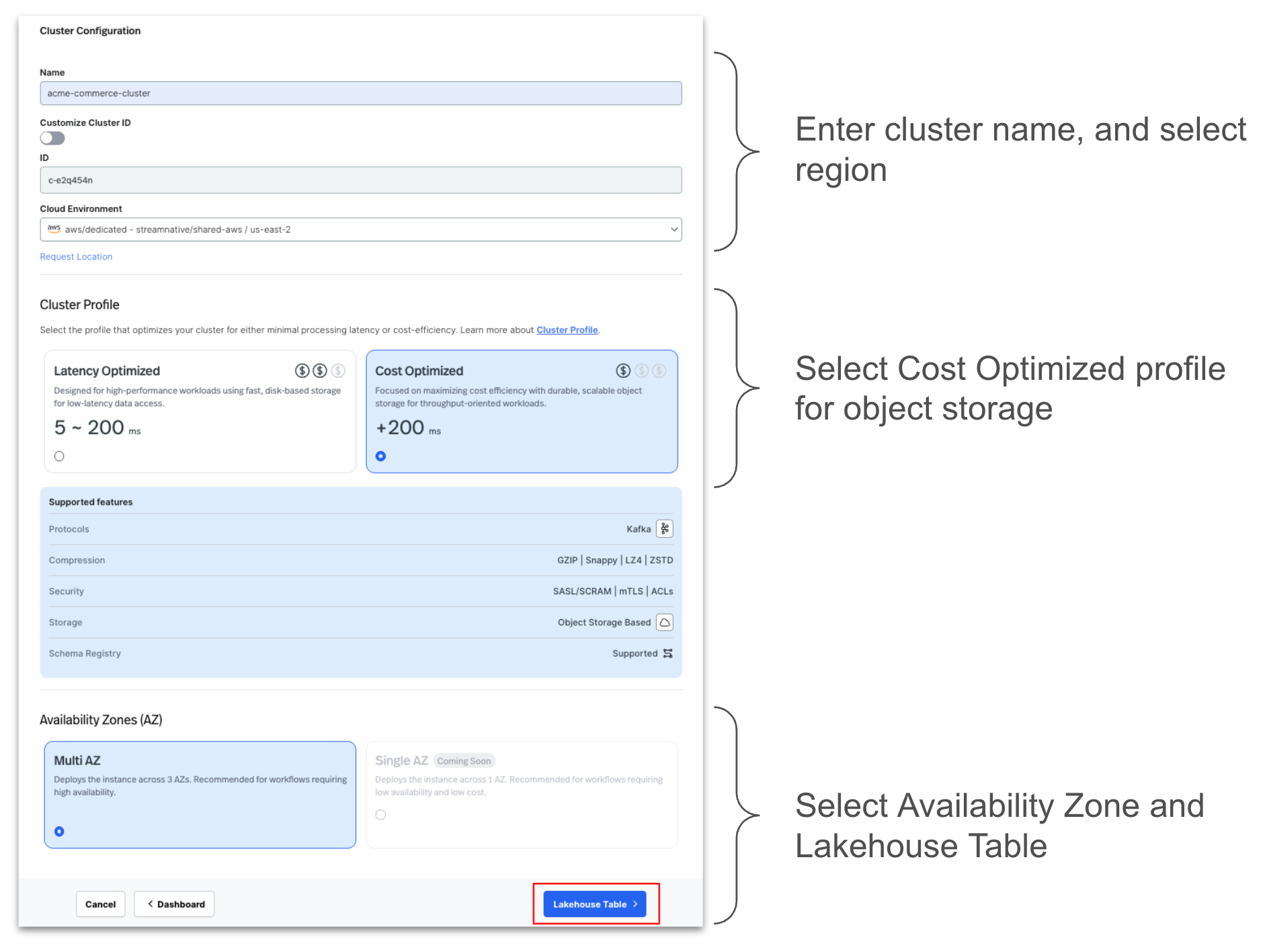
- Configure cluster by entering the details as shown below.
- Select the registered BigLake catalog during setup.
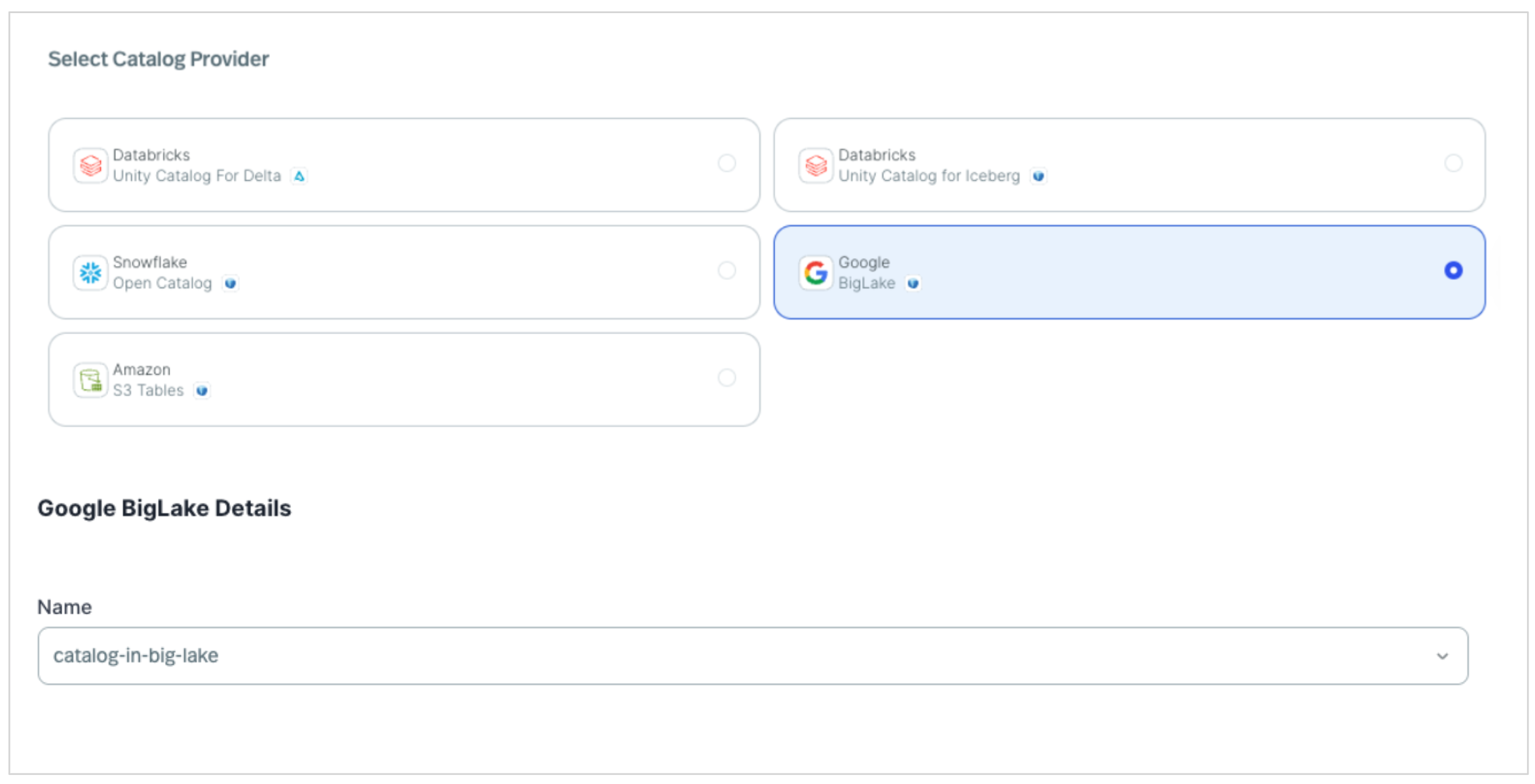
Note: While this example uses a StreamNative Kafka service Dedicated cluster, this lakehouse integration capability is also supported with StreamNative Pulsar clusters. Currently, this integration is supported on Dedicated clusters in Public Preview, with support for Serverless and BYOC deployments planned for future releases.
Credentials Vending Mode
Credential vending mode in BigLake metastore allows the metastore to securely provide temporary, scoped cloud credentials to authorized compute engines instead of requiring long-lived storage keys. StreamNative's BigLake integration supports credential vending mode, enabling StreamNative Kafka service and Pulsar workloads to securely access Iceberg tables managed by BigLake without directly managing Google Cloud Storage credentials.
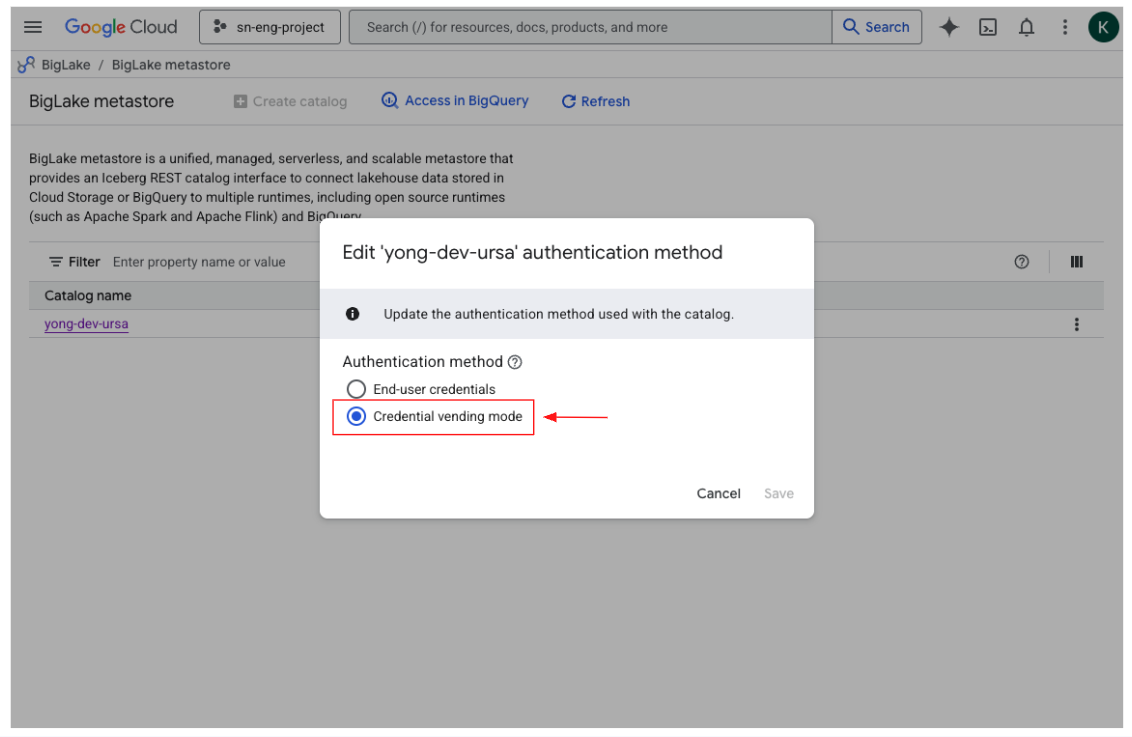
By leveraging BigLake's IAM-based access controls and short-lived credentials, StreamNative helps ensure secure, governed, and simplified authentication while maintaining centralized data access policies.
Step 3: Review ingested data in BigLake metastore catalog
Once configured, StreamNative automatically streams Kafka topic data as managed Iceberg tables in BigLake metastore catalog.
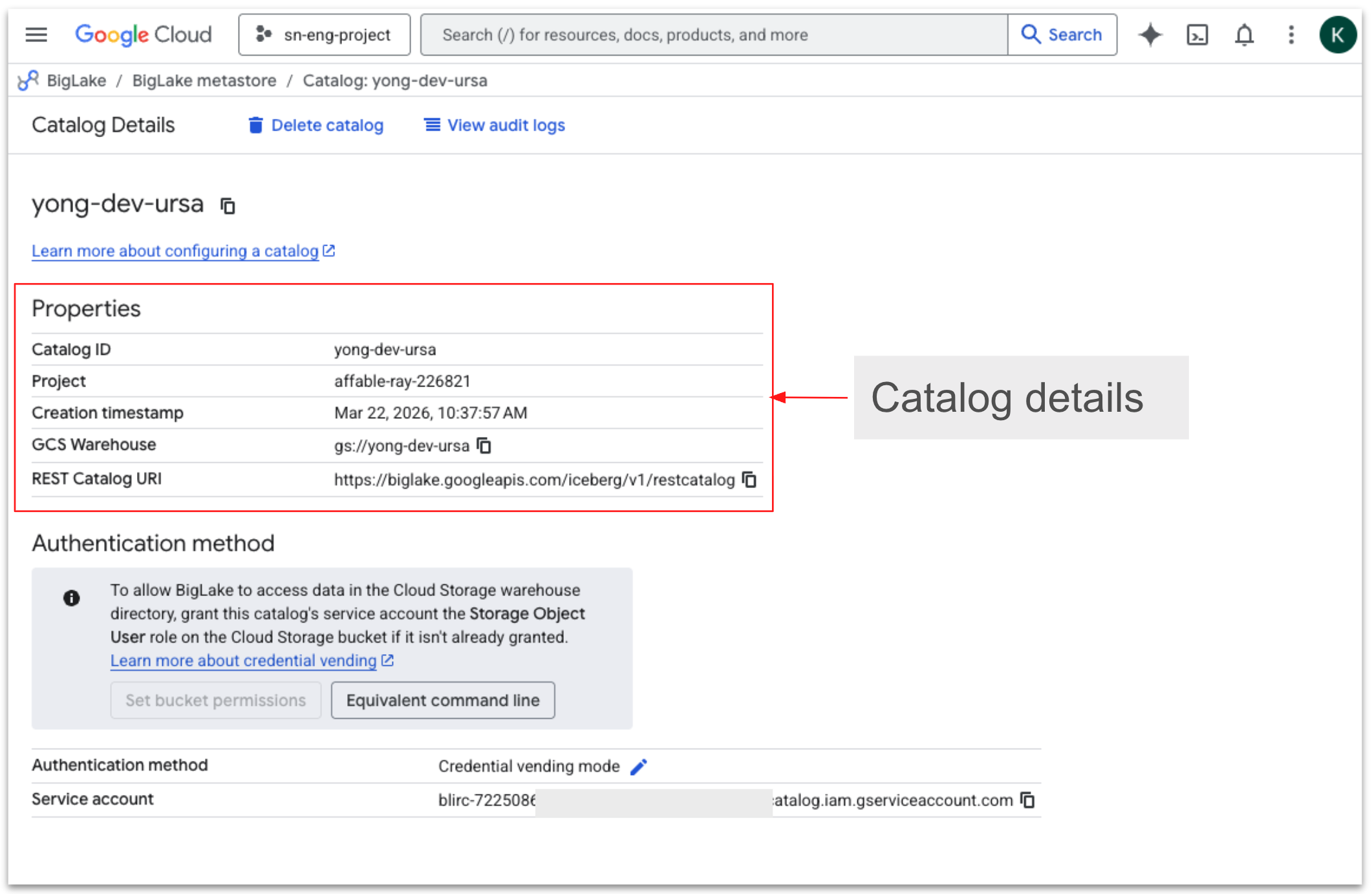
In BigLake metastore, catalog details define how StreamNative connects to the metastore, including the catalog name, catalog URI (Iceberg REST endpoint), and warehouse storage location. These settings allow StreamNative Cloud to register Kafka or Pulsar topic data as Iceberg tables with centralized governance and metadata management.
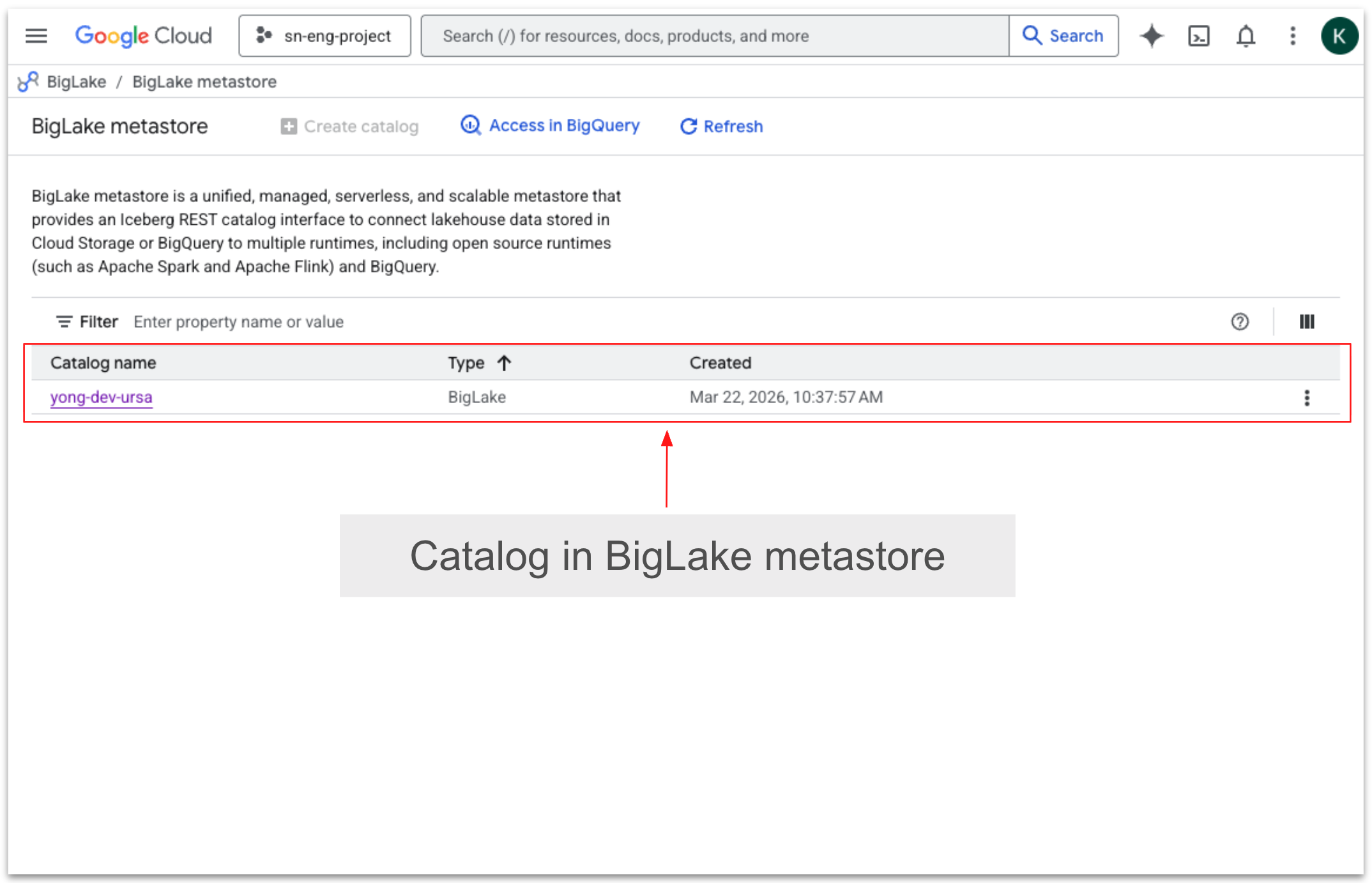
In BigLake metastore, a target catalog acts as the logical container where table metadata is registered and managed. When streaming data from StreamNative Cloud, topics from StreamNative Kafka service or Pulsar are continuously written to lakehouse storage in Apache Iceberg format and registered within a specified BigLake catalog.
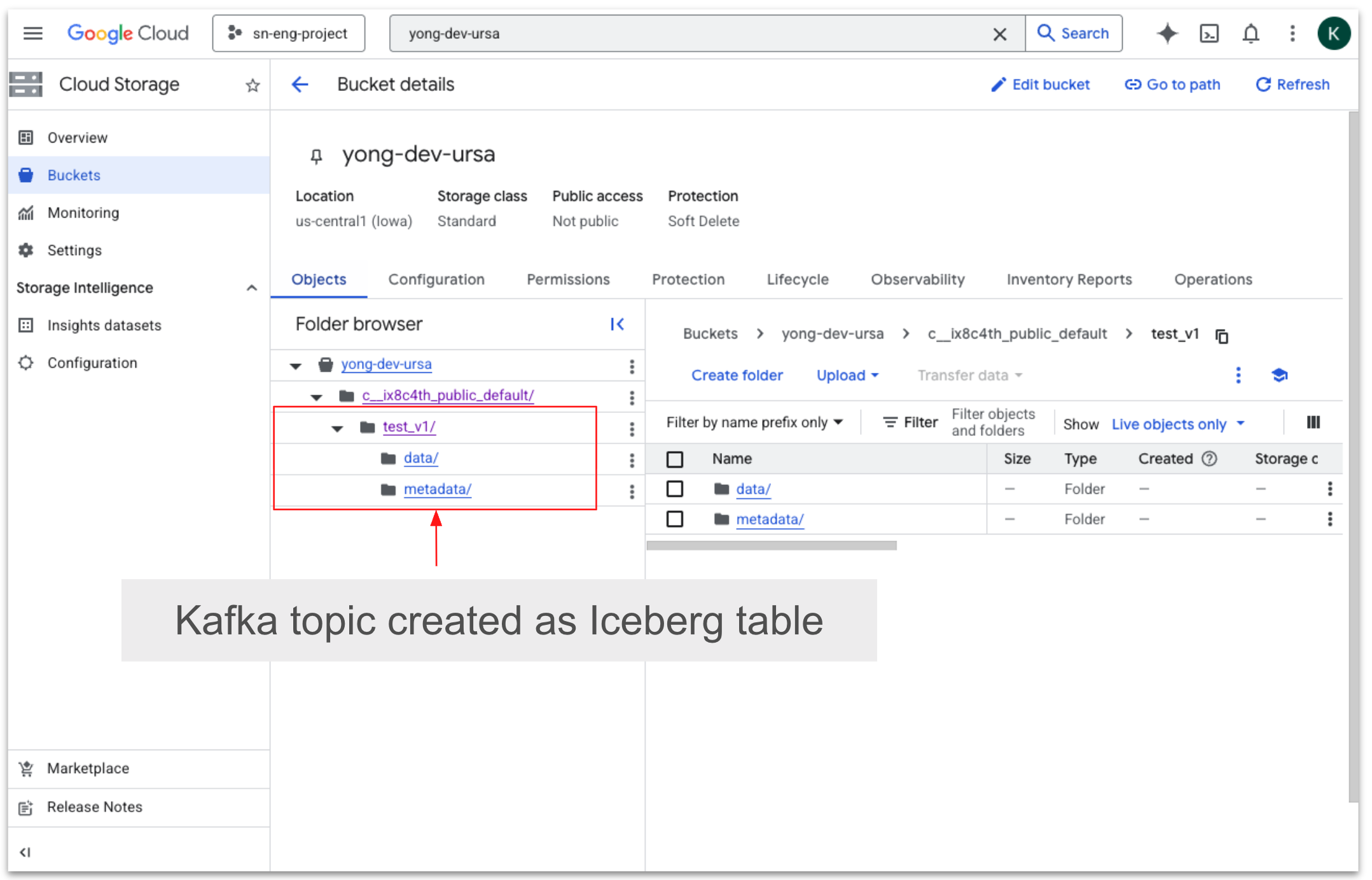
This targeted catalog organizes the ingested datasets into schemas and tables, enabling downstream analytics engines---such as BigQuery or Spark---to discover, query, and govern the streaming data using BigLake's centralized metadata, access controls, and governance capabilities.
Step 4: Query Iceberg tables in BigLake metastore catalog
Once streaming data from StreamNative Cloud is registered as Apache Iceberg tables in the BigLake metastore catalog, it can be queried using Apache Spark.
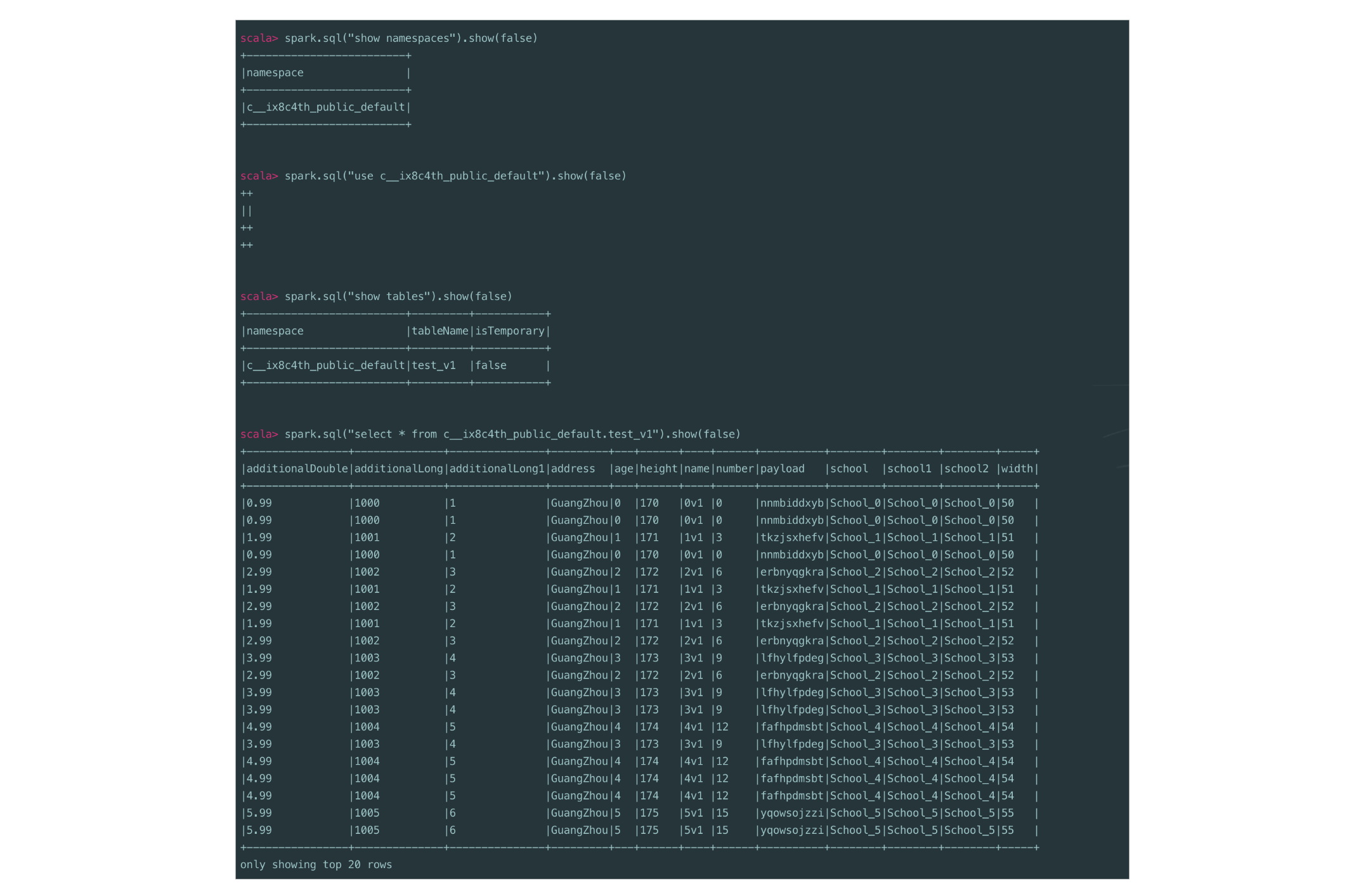
By connecting Spark to the BigLake Iceberg REST catalog, users can run standard SQL queries to analyze streaming datasets, enabling batch and real-time analytics on continuously ingested data with consistent governance and metadata management.
Conclusion
StreamNative's integration with BigLake metastore enables organizations to stream Kafka and Pulsar data into governed Apache Iceberg tables for real-time and batch analytics. By combining StreamNative's real-time data platform with BigLake's centralized governance, teams can simplify data access, improve security, and accelerate lakehouse analytics using tools like Apache Spark and BigQuery.
Get Started
Support for streaming topic data into BigLake metastore as Apache Iceberg tables is now available in StreamNative Cloud through a Private Preview.
To learn more:
- Try it yourself: Sign up for a free trial to experience how Kafka data from StreamNative can be seamlessly ingested into the Snowflake Horizon Catalog. Use promo code UFK1000 between April 7 and April 14 to receive $1,000 in credits.
- Watch a demo of StreamNative Kafka service





