
When we founded StreamNative, we set out to build the world's best data streaming platform. We succeeded --- but the more interesting discovery came from what we found along the way: streaming, on its own, is only part of the story.
StreamNative was founded by the original creators of Apache Pulsar, a system born inside Yahoo to handle unified messaging and real-time data movement at a scale few organizations ever face. When we open-sourced that work and brought it to the broader market, we believed the core problem was speed and scale. We were right --- but we were asking a narrower question than the industry actually needed us to answer.
What enterprises kept running into wasn't a streaming problem in isolation. It was an integration problem: how does real-time data coexist with the analytical systems, storage layers, and AI workloads that define the modern data stack? The answer, we came to realize, points toward something bigger than streaming --- a unified lakehouse architecture where real-time and historical data aren't siloed, but genuinely converge.
This post is about that journey: from building a streaming company, to recognizing a fundamental architectural shift --- and why we believe it matters for every organization serious about making data a competitive advantage.
We call it Lakestream.
Starting with Pulsar -- and Learning the Limits of Protocols
When we built Apache Pulsar at Yahoo, we were solving a problem that didn't have a good answer yet: how do you build a multi-tenant, unified messaging and streaming platform capable of handling millions of topics, billions of messages, and the operational complexity of a global internet company --- all on shared infrastructure?
Some of the architectural decisions we made turned out to be more consequential than we realized at the time.
The first was compute-storage separation. While other streaming systems tightly coupled brokers to local disks, we built Pulsar around Apache BookKeeper as an independent, distributed storage layer. Brokers were stateless. Storage was durable and decoupled. In 2012, this was an unconventional bet. Today, it's a foundational design pattern across virtually every large-scale data system --- from cloud data warehouses to modern streaming platforms. We didn't predict the future; we just kept following the engineering logic until it led somewhere interesting.
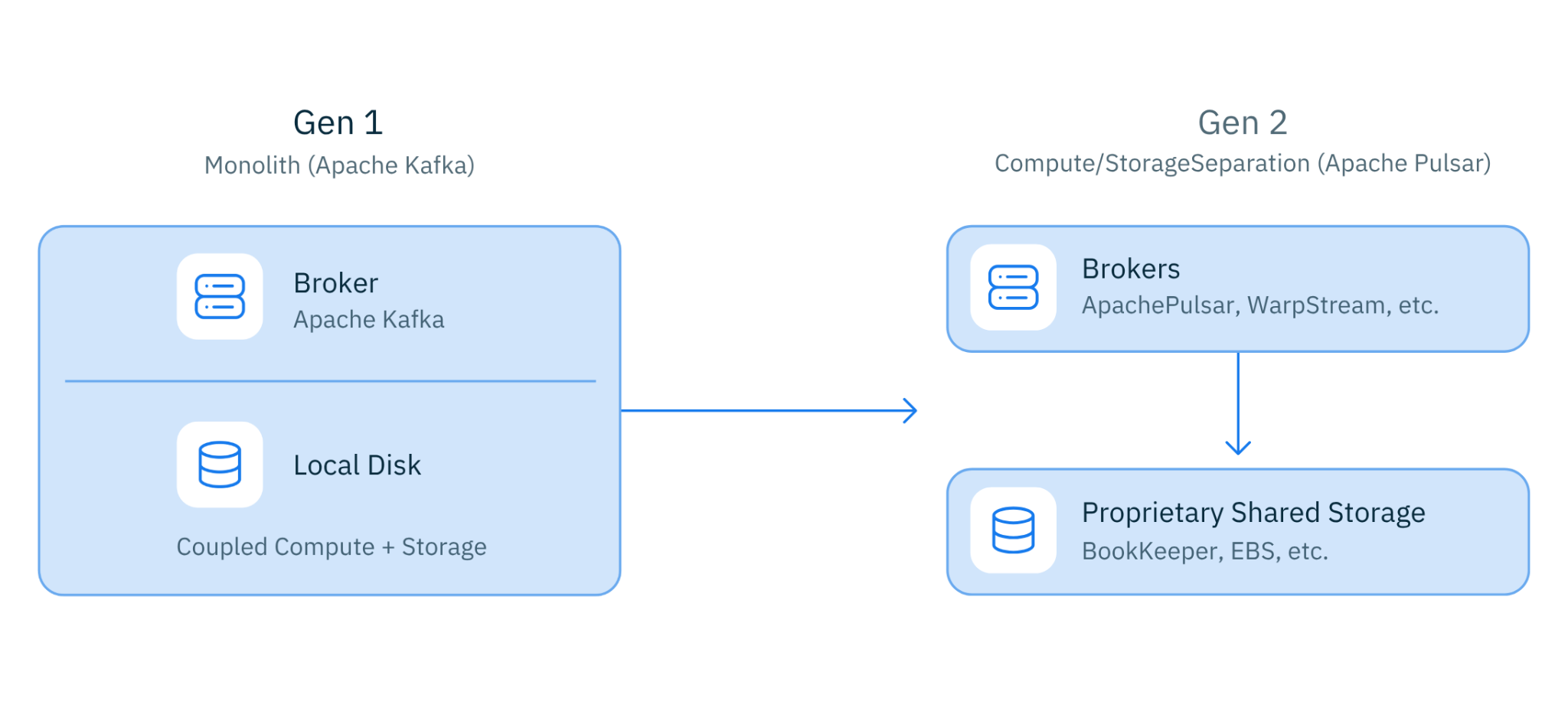
Figure 1. From Monolith to Compute/Storage Separation
The second was messaging semantics. We embedded rich subscription models --- including shared subscriptions --- directly into the client protocol from the beginning, because real enterprise workloads demanded them. Kafka added shared subscriptions more than a decade later. We're not pointing this out to score points; we're pointing it out because it reflects something important about what happens when you design for the full complexity of enterprise use cases from day one, rather than optimizing narrowly and retrofitting later.
Getting these things right taught us something, too: good architecture creates options. And the options Pulsar's design left open would matter more than we initially expected.
From Managed Service to Market Reality
When we founded StreamNative, we brought Pulsar to the cloud as a fully managed service. Enterprises adopted it quickly for their most demanding workloads --- financial transaction processing, IoT telemetry at scale, real-time fraud detection. Pulsar's multi-tenancy, geo-replication, and unified messaging model made it a natural fit for use cases where reliability and operational isolation aren't optional.
But as our customer base grew, a pattern emerged --- and it was remarkably consistent.
Most enterprises were running a split world. They used StreamNative for mission-critical messaging and queuing --- the workloads where transactional guarantees and tenant isolation matter most. But their data streaming and ingestion pipelines ran on Kafka. Not because Kafka was architecturally superior for those use cases, but because the Kafka protocol had become the industry's lingua franca. Every connector, every SaaS tool, every cloud service spoke Kafka. Switching meant rewriting integrations, not just swapping infrastructure.
So we made a pragmatic call: we made StreamNative Kafka-compatible. First came KoP (Kafka-on-Pulsar), an open-source protocol handler letting Pulsar brokers speak the Kafka wire protocol natively. Then came KSN (Kafka-on-StreamNative) --- a more deeply integrated, production-hardened compatibility layer built for enterprise scale.
This worked. Customers could consolidate their Kafka workloads onto our platform without changing application code. But it taught us our first crucial lesson:
Lesson 1: Protocol compatibility is table stakes, not a differentiator.
By the time we shipped KSN, every major streaming vendor was racing toward Kafka compatibility --- including Confluent itself, which acquired WarpStream, a Kafka-compatible alternative. The protocol wasn't a moat anymore; it was becoming commodity infrastructure. If we were going to build something with lasting value, it had to live somewhere deeper than the wire protocol.
That realization forced a harder question: if the protocol layer was being commoditized, what actually mattered?
Rethinking Storage -- and the Moment Everything Clicked
By 2023, we were operating large-scale streaming clusters across three major cloud providers, and we were seeing the same problem everywhere --- regardless of industry, workload, or team size.
Cross-AZ replication costs were eating 60-90% of infrastructure budgets. The root cause was structural. Kafka's leader-per-partition architecture --- and most streaming systems like it --- requires every write to be replicated from a leader broker to follower brokers, typically across availability zones. In on-premises environments, that's an architectural inconvenience. In the cloud, where cross-AZ data transfer is metered, it becomes the single largest line item on the bill. We watched operational teams spending more cycles managing infrastructure costs than shipping products. Something was fundamentally broken about the economic model.
The rest of the industry was attacking this at the broker layer. Some were rewriting streaming engines in C++ for raw throughput gains. Others were offloading cold log segments to S3 as tiered storage, or adding object storage as a secondary backend. These were legitimate engineering efforts --- but they were addressing symptoms rather than the underlying cause. They were making an expensive architecture incrementally more efficient, without stepping back to ask whether the architecture itself needed rethinking.
We asked a different question.
"What if streaming data didn't need its own storage format at all? What if it could live natively in the lakehouse?"
This question changed everything.
We built a new storage foundation from the ground up -- leaderless, diskless, writing directly to object storage in open lakehouse formats. Instead of Kafka's local log segments or Pulsar's BookKeeper ledgers, data went straight to S3, GCS, or Azure Blob Storage as Parquet files in Apache Iceberg or Delta Lake format. A distributed write-ahead log (WAL) handled the low-latency append path, ensuring producers got sub-second acknowledgments. But the durable, queryable data wasn't waiting to be exported or transformed into a lakehouse format downstream --- it was a lakehouse table from the moment it was committed.
This wasn't tiered storage. It wasn't an export pipeline. It was a fundamental reconception of where streaming data lives --- and what it can do from the moment it arrives.
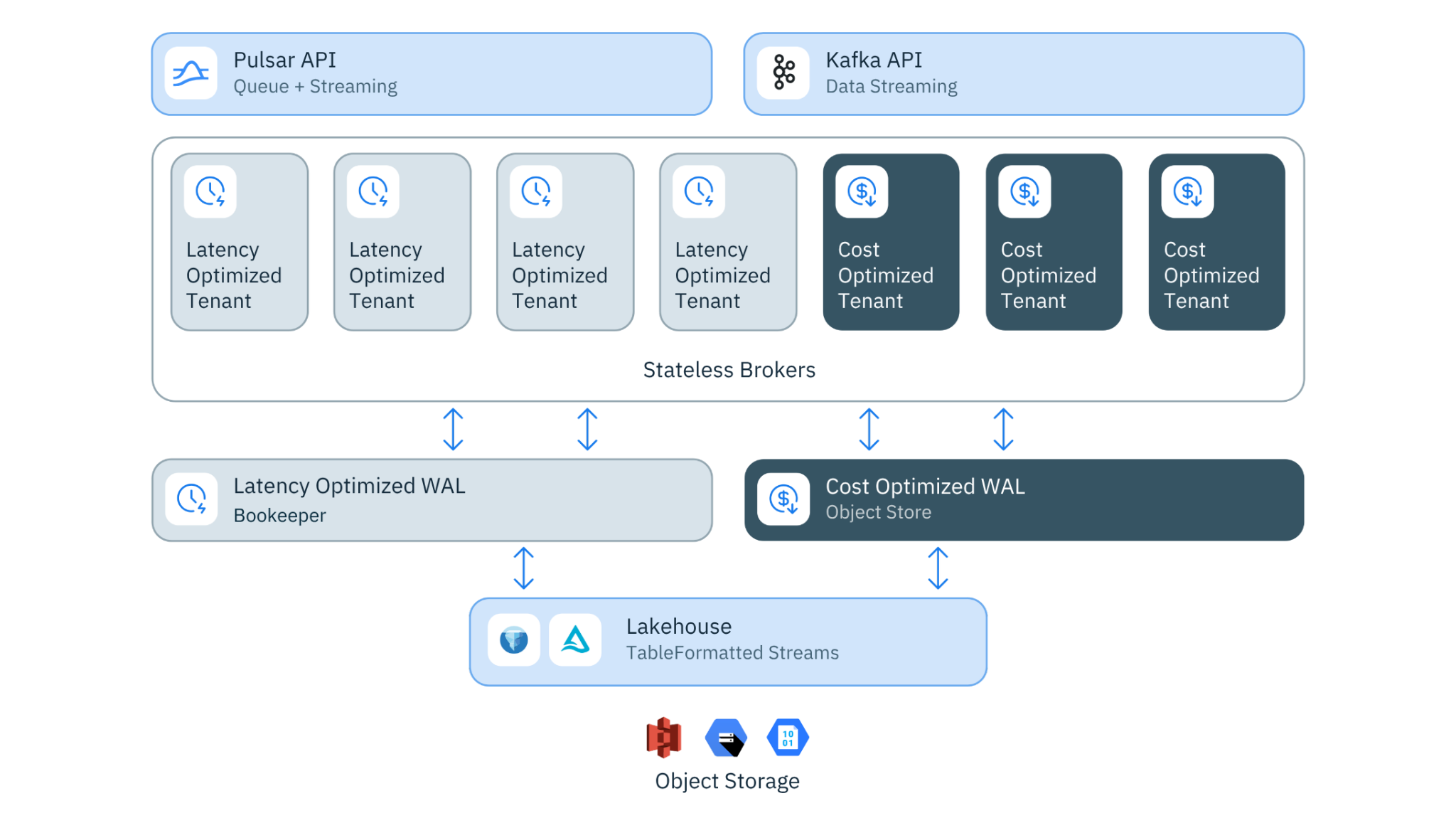
Figure 2. Ursa Architecture
The Results --- and the Surprise They Revealed
The architectural payoff was immediate and measurable. No proprietary segment format. No inter-broker replication. No cross-AZ data transfer for durability --- that responsibility shifted to the object store itself, which delivers eleven-nines durability at a fraction of the cost of traditional streaming infrastructure.
The economics were stark: up to 95% cost reduction at 5 GB/s sustained throughput. We published the benchmark and the architecture openly. The work was subsequently recognized with a Best Industry Paper award at VLDB 2025 --- one of the most respected academic venues in data management --- selected over submissions from Databricks, Meta, and Alibaba. We share this not to collect trophies, but because independent validation from the research community matters when you're asking the industry to rethink a foundational assumption.
But the cost savings, as dramatic as they were, turned out to be the least interesting part of what we'd built.
As we deployed this new storage layer with customers, something unexpected kept happening. Engineers would produce data to a Kafka topic --- same client code, same producers, same workflows they'd always used. Then they'd open Spark, Snowflake, or Databricks, and discover they could query that exact data. No Kafka Connect. No sink connector. No materialization pipeline. No batch ETL window to wait out.
The data was already there. Already in Iceberg format. Already a table.
"Wait," they'd say. "My Kafka topic IS a table?"
Yes. That's exactly what it is.
That moment --- repeated across customer after customer --- is when we understood what we'd actually built. Not a cheaper streaming engine. Not a better Kafka. Something that dissolved the boundary between streaming infrastructure and the lakehouse entirely. The storage layer wasn't a cost optimization with a happy side effect. It was a unification --- one that made a decades-old architectural divide simply disappear.
Lesson 2: The real breakthrough wasn't cost savings. It was discovering that streaming data and lakehouse data can be the same thing -- and that the bridge between them isn't a connector. It's the storage layer itself.
The Convergence Nobody Planned -- and What the Industry Got Half-Right
We weren't alone in recognizing the gap between streaming and the lakehouse. By the time we were deep in this problem, the entire industry was trying to close it --- just from different directions, with different foundational assumptions.
One camp built bridges. Confluent's Tableflow, Kafka Connect with Iceberg sinks, and similar approaches treat streaming and the lakehouse as separate systems and materialize data between them. These solutions work --- but they work by adding complexity: another pipeline to manage, another failure mode to monitor, and an irreducible latency between when data is produced and when it's queryable downstream.
Another camp added streaming capabilities to lakehouse platforms. Databricks has Spark Structured Streaming and Delta Live Tables. Snowflake has Snowpipe Streaming and Dynamic Tables. These are genuinely powerful tools for analytics teams --- but streaming as an analytics feature is categorically different from streaming as infrastructure. You cannot build a mission-critical messaging system, a financial transaction backbone, or a real-time fraud detection pipeline on Spark Structured Streaming. The operational guarantees simply aren't there.
A third camp attempted something more ambitious: entirely new unified architectures. Ververica's Streamhouse concept --- combining Apache Flink with Apache Paimon --- is a serious and thoughtful approach. But it asks organizations to adopt a new ecosystem wholesale, which means leaving Kafka compatibility, existing tooling, and years of operational investment behind.
Each approach solves part of the problem. None of them questions the assumption underneath it.
They all treat streaming and the lakehouse as fundamentally separate systems that need to be connected --- and compete on how elegantly they build that connection.
What if that assumption is wrong?
The historical parallel is hard to ignore. In 2020, Databricks introduced the lakehouse concept with a deceptively simple insight: data warehouses and data lakes didn't need to be separate systems connected by ETL pipelines. You could implement warehouse-grade capabilities --- ACID transactions, schema enforcement, fine-grained governance --- directly on top of cheap, open-format lake storage. The lakehouse didn't build a better bridge. It made the bridge unnecessary.
The streaming industry is standing at the same inflection point.
For years, we've accepted that real-time event streaming and analytical data infrastructure are different systems with different storage formats, different operational models, and different teams responsible for keeping them in sync. The connector ecosystem exists to paper over that divide. But connectors are a symptom, not a solution --- evidence of an architectural boundary that perhaps shouldn't exist in the first place.
We weren't setting out to write a manifesto. We were trying to fix infrastructure costs. But the storage architecture we built kept pointing toward the same conclusion: streaming and the lakehouse don't need to be separate either.
Naming What We Built: Lakestream
Looking back, the through-line was always there. Pulsar's compute-storage separation. Kafka protocol compatibility. Lakehouse-native storage. Each felt like a distinct product decision at the time. In retrospect, they were pieces of the same architectural argument --- we just didn't have a name for it yet.
Now we do.
We call it Lakestream -- a lakehouse-native streaming architecture that treats streams as first-class lakehouse primitives alongside tables. Not a streaming system that exports to the lakehouse. Not a lakehouse that ingests from streams. A unified foundation where the distinction stops being meaningful.
Just as the lakehouse dissolved the boundary between data warehouses and data lakes, Lakestream dissolves the boundary between data streaming and the lakehouse. Not by building better bridges. By making the bridge unnecessary.
Key Principle: Lakestream is NOT a replacement for the lakehouse. It is an extension that augments the lakehouse with real-time streaming capabilities -- adding streams as first-class primitives alongside tables.
The Core Insight: Push Interoperability Down the Stack
Most streaming systems today solve interoperability at the protocol layer --- translating between Kafka, Pulsar, MQTT, and other protocols at the top of the stack. It's a reasonable approach, and it's where most of the industry's engineering energy has gone. But it has a structural consequence: every protocol becomes its own data silo, and connecting them requires maintaining point-to-point translation at the application layer indefinitely.
Lakestream takes a different approach. Rather than pushing interoperability up to the protocol, we push it down --- to the storage and catalog layers, where it can be solved once and inherited by everything above it.
The result is an architectural property that's easy to state but hard to overstate: the protocol becomes a choice of interface, not a choice of data silo. Write via Kafka. Consume via Pulsar. Query via SQL. Subscribe via MQTT. The data underneath is identical --- the same Iceberg tables, the same catalog entries, the same durable objects in your object store.
This is what makes Lakestream structurally different from compatibility layers and connector ecosystems. Those approaches translate between silos. Lakestream eliminates the silo.
The Architecture
Lakestream is built on three layers -- each one a direct consequence of something we learned along the way:
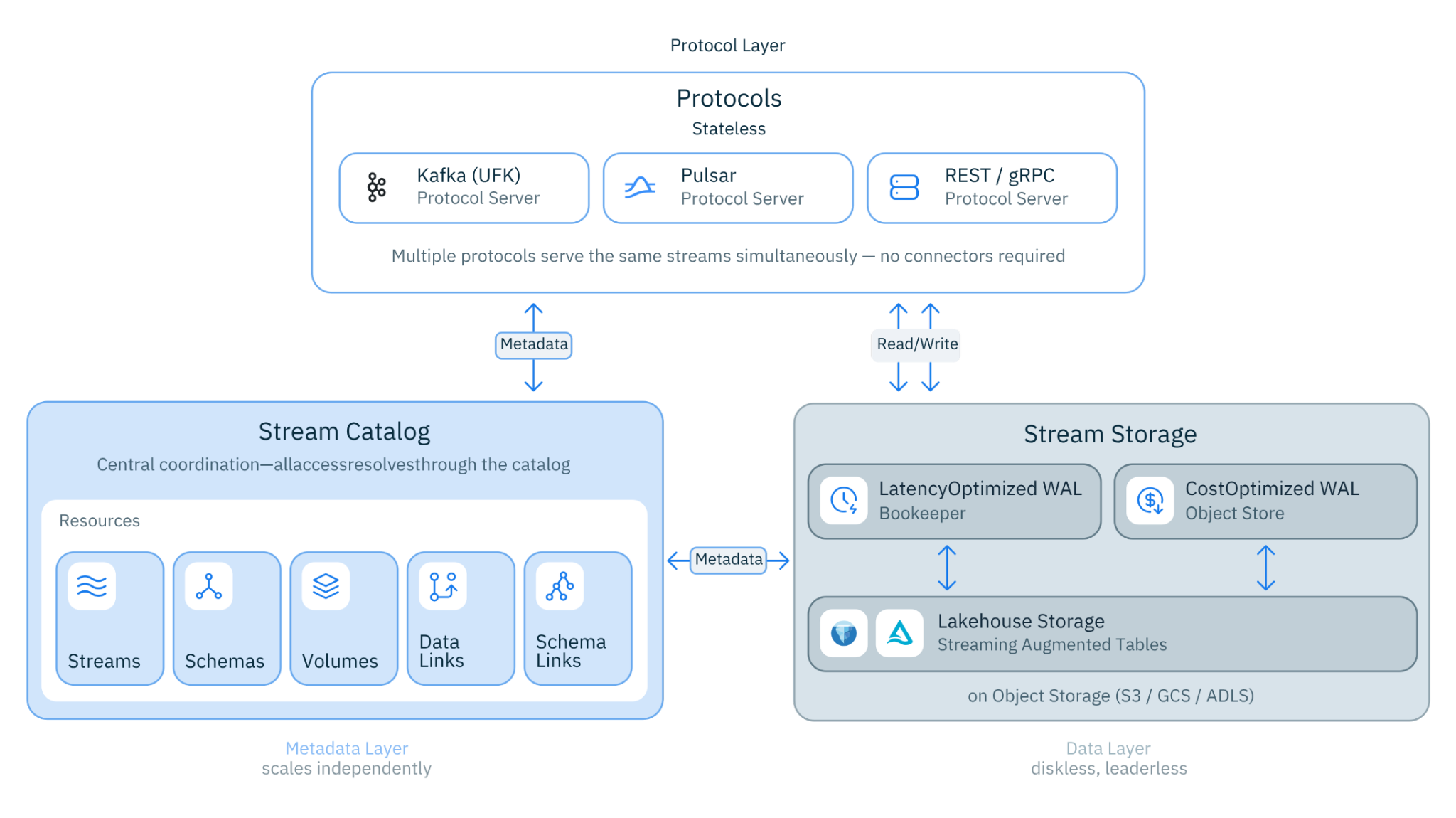
Figure 3. Lakestream Architecture
1. The Data Layer: Cloud-Native Stream Storage
The foundation is lakehouse-native stream storage, and it's where the economics of Lakestream begin.
A distributed write-ahead log handles real-time ingestion with sub-second producer acknowledgments. But rather than writing to proprietary broker-local storage, data is durably committed to object storage --- S3, GCS, or Azure Blob --- as Parquet files organized as Apache Iceberg or Delta Lake tables. The architecture is leaderless and diskless: any broker can serve any partition, and no local disks are required for durability.
The consequences are significant. Cross-AZ replication costs disappear --- durability is delegated to the object store, which provides eleven-nines reliability at commodity pricing. The result is up to 95% lower infrastructure cost compared to traditional streaming deployments at equivalent throughput.
But the deeper consequence isn't the cost. It's that streaming data is lakehouse data from the moment it's written --- no transformation, no export, no pipeline in between.
2. Metadata Layer: The Lakestream Catalog
If the data layer unifies how streams are stored, the catalog layer unifies how they're understood.
The Lakestream Catalog provides a single metadata plane for both streams and tables, organized around a three-level namespace --- catalog.namespace.stream --- that will feel immediately familiar to anyone working in modern data platforms. Every stream has a corresponding lakehouse table, and the catalog maintains that linkage automatically. Producers don't need to think about it. Consumers don't need to configure it. It's just there.
Critically, the Lakestream Catalog federates with the catalogs organizations already use --- Databricks Unity Catalog, Snowflake Horizon Catalog, and others. This means streams become discoverable in the same metadata layer as batch tables, governed by the same policies, and visible to the same tools. Streaming data stops being invisible infrastructure and starts being a first-class asset in your data platform.
3. Protocol Layer: Stateless Protocol Servers
The protocol layer is where Lakestream meets the world as it actually exists --- and where one of our hardest-learned lessons shaped the design most directly.
We've lived through what happens when an industry consolidates around a single protocol. Kafka's dominance brought enormous ecosystem benefits --- ubiquitous tooling, broad cloud integration, a generation of engineers who know it deeply. But it also meant the industry inherited Kafka's limitations as fixed constraints. Messaging semantics that enterprises needed --- shared subscriptions, exclusive consumers, failure queues --- simply weren't there. We built those capabilities into Pulsar over a decade ago because real-world workloads demanded them. Kafka added shared subscriptions years later, after the absence had already forced countless teams into workarounds.
The lesson isn't that Kafka is wrong. It's that betting your entire data architecture on a single protocol's roadmap is a structural risk --- one that compounds over time as your use cases grow beyond what that protocol was originally designed to handle.
Lakestream is built on the opposite principle: no single protocol owns the architecture.
Kafka, Pulsar, REST, gRPC --- all implemented as stateless protocol servers writing to the same underlying storage layer. Your existing producers and consumers work without code changes. Your existing connectors and tooling work without reconfiguration. Adding support for a new protocol means deploying a new stateless server --- not migrating data, not redesigning pipelines, not waiting years for a standards committee to catch up to your use case.
This modularity is only possible because interoperability lives at the storage layer, not the protocol layer. When the data underneath is protocol-agnostic, the protocol above it becomes a genuine choice --- not a lock-in decision made once and lived with indefinitely.
The protocol is an interface. The data belongs to everyone who needs it. And when the next protocol matters --- because it will --- you add it without touching anything underneath.
What This Changes
Lakestream isn't a product feature. It's an architectural shift --- and like most genuine architectural shifts, its implications extend well beyond the layer where the change actually happens.
Stream-Table Duality is the most immediate consequence, and the one that consistently surprises people when they see it for the first time. Every stream is simultaneously a table. Produce to a Kafka topic and query it from Spark, Snowflake, or Databricks --- not after a connector runs, not after a batch job completes, but immediately, because the data was never anywhere else. The pipeline between streaming and analytics doesn't get faster. It ceases to exist.
Governed Self-Service Streaming follows naturally from the catalog layer. When streams live in the same metadata plane as batch tables, they inherit the same access controls, the same audit trails, and the same schema governance --- automatically. Data teams stop managing streaming infrastructure as a separate operational concern and start treating streams as first-class assets in the same platform they already govern. This is what makes streaming accessible to the broader organization, not just the engineers who built the pipelines.
Multi-Protocol, Single Data means the protocol fragmentation that has quietly balkanized data organizations for years simply stops. Write via Kafka. Consume via Pulsar. Query via SQL. Subscribe via MQTT. The data underneath is identical. Teams can use the interface that fits their workload rather than the one that fits the infrastructure they inherited.
Universal Linking replaces the brittle point-to-point connector topology that most organizations have quietly accumulated over years of growth. Replicating data across clusters, regions, or systems happens through the shared storage and catalog layer --- not through a web of connectors, each one a potential failure mode and a maintenance burden. The architecture gets simpler as it scales, rather than more fragile.
Freedom to Evolve may be the most important long-term consequence, and the hardest to appreciate until you've been burned by protocol lock-in. By decoupling the protocol from the storage layer, Lakestream makes the storage layer independently improvable. New compression schemes, new indexing strategies, new query optimizations --- none of these require protocol changes, client updates, or application migrations. The architecture can absorb innovation without disruption, which is a property that compounds in value over time.
Taken together, these aren't five separate benefits. They're five expressions of the same underlying idea: when streaming and the lakehouse share a foundation, the constraints that have defined the streaming category for a decade stop being constraints.
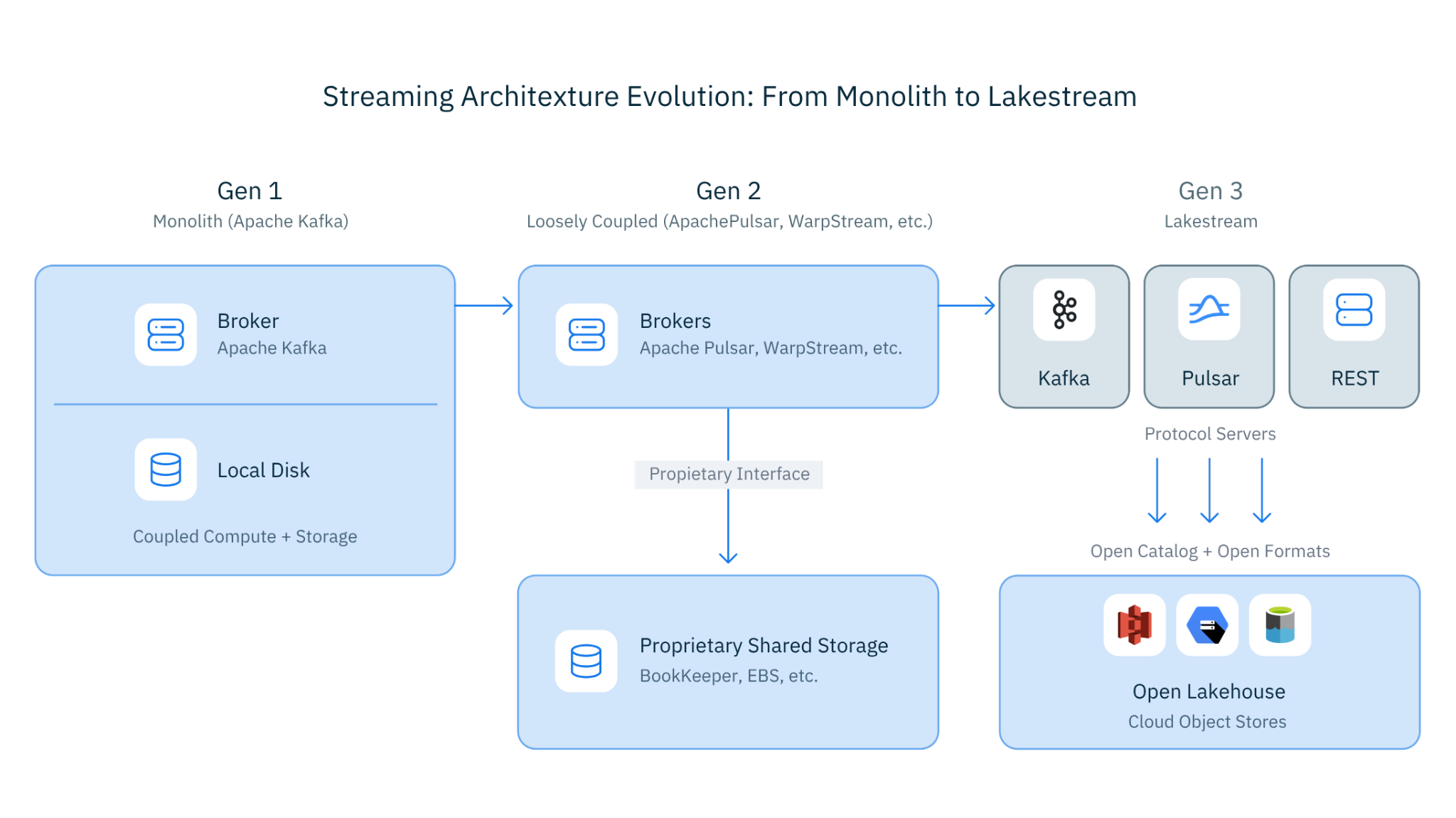
Figure 4: Streaming Architecture Evolution: From Monolith to Lakestream
The Road Ahead
This week, we're moving from architecture to practice.
We're launching Ursa for Kafka (UFK) --- a native Kafka service built on the Lakestream foundation. And when we say native, we mean it precisely: not Kafka-compatible, not a translation layer, but Apache Kafka itself running on Lakestream's lakehouse-native stream storage. Any Kafka workload becomes lakehouse-native with zero code changes. No migration. No reconfiguration. No compromise on the Kafka semantics your applications already depend on. We'll cover the full details in our companion post.
We're also committed to open-sourcing Ursa and the core Lakestream components in the coming months. We've thought carefully about this, and our conviction is straightforward: an architectural shift of this magnitude belongs to the community, not to any single vendor. The lakehouse succeeded in part because its foundations --- Parquet, Iceberg, Delta Lake --- were open and composable. We intend to build Lakestream the same way.
Seven years ago, we thought we were building a better streaming platform. And in the narrow sense, we were. But looking back at the full arc --- Pulsar's compute-storage separation, the Kafka compatibility work, the lakehouse-native storage breakthrough --- it's clear that each step wasn't a detour. It was the path.
We weren't building a better version of what already existed. We were working, iteratively and sometimes without knowing it, toward something the industry didn't have a name for yet.
Now it does.
Lakestream.
If you're rethinking your streaming architecture --- or questioning assumptions you've held for years about where streaming ends and the lakehouse begins --- we'd like to think through it with you. The shift we're describing isn't something one company builds alone. It's something the industry figures out together.
Let's get started!










