
In our companion post, we shared the story of how our journey -- from Pulsar to lakehouse-native streaming -- crystallized into a new architectural paradigm we call Lakestream. Today, we're showing what Lakestream looks like in practice - We are excited to announce a Native Kafka service enters Limited Public Preview together with a set of partners in the broader Kafka & Lakehouse ecosystem.
Ursa For Kafka (UFK) is native Apache Kafka -- not compatible, native -- running on Lakestream's lakehouse-native foundation. Every Kafka topic is a lakehouse table. No connectors. No ETL. Just Kafka, reimagined for the lakehouse era.
Why We Built UFK
Lakestream's core insight is that interoperability belongs at the storage and catalog layers, not the protocol layer. If that's true, then any streaming protocol should be able to plug into Lakestream's foundation -- and work better for it.
We'd already proven this with Kafka-compatible access to our lakehouse-native storage. It worked -- customers ran Kafka workloads at up to 95% lower cost, and we won the VLDB 2025 Best Industry Paper award, validating the architecture at 5 GB/s sustained throughput. But compatibility layers have limits. Edge cases in protocol behavior. Features that don't translate cleanly across the abstraction boundary. The gap between "compatible" and "native" -- small in benchmarks, real in production.
So we asked: why not make Kafka itself -- native Apache Kafka -- run on Lakestream's foundation? Not Kafka-compatible. Not Kafka-on-something. Apache Kafka with lakehouse-native storage underneath.
That question became UFK. And the answer turned out to be remarkably elegant: take Apache Kafka 4.2, extend its local disk storage with Lakestream's storage layer, and let the rest of the Kafka ecosystem work exactly as it always has. The protocol stays the same. The storage becomes lakehouse-native. The data becomes immediately available for analytics.
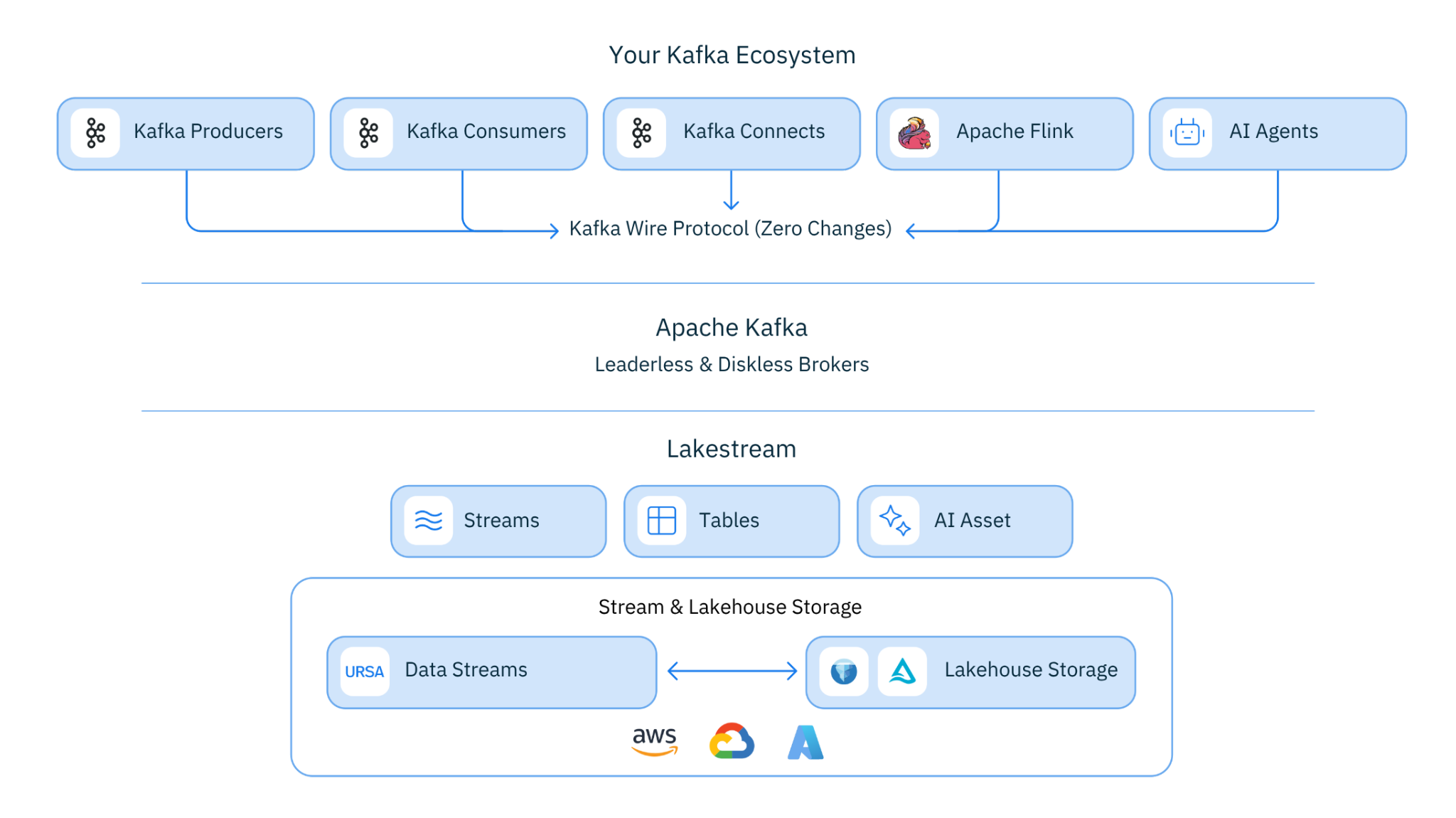
Figure 1. Ursa For Kafka Architecture
What Is Ursa For Kafka?
UFK is a native Apache Kafka fork -- built on Kafka 4.2+ -- that extends Kafka's local disk storage with Lakestream's lakehouse-native storage foundation. It's the lakehouse-native Kafka engine where every topic is simultaneously a live event stream and an up-to-date lakehouse table.
UFK extends Kafka with lakehouse-native storage -- it doesn't force you to abandon what you have. Mixed storage in one cluster: Keep some topics on traditional disk-based storage while moving others to lakehouse-native storage. No separate clusters needed. Dual profiles: Support both cost-optimized (lakehouse-native, up to 95% cheaper) and latency-optimized (disk-based, single-digit ms) topic profiles in the same cluster. Rollout at your own pace: Start with high-volume, latency-relaxed topics -- your biggest cost drivers. Expand to more topics when you're ready. No big bang migration required.
How It Works
The architecture is straightforward -- and that's the point:
- Kafka clients produce data through the standard Kafka protocol. Zero code changes. Every existing Kafka client, tool, and connector works.
- Kafka brokers receive the data and write to Lakestream's storage layer: a distributed WAL (Write-Ahead Log) buffers writes for low-latency acknowledgment; object storage (S3, GCS, or Azure Blob) stores data durably in Parquet format; the Lakestream Catalog registers the data as Iceberg or Delta Lake table updates.
- Kafka consumers read through the standard Kafka protocol -- exactly as they always have.
- Analytics engines -- Spark, Trino, Snowflake, Databricks -- query the same data as tables. No connectors needed. The data is already in their native format.
The write path and read path for Kafka clients are unchanged. What's different is what happens underneath: data lands in the lakehouse the moment it's committed, not hours later via a batch pipeline.
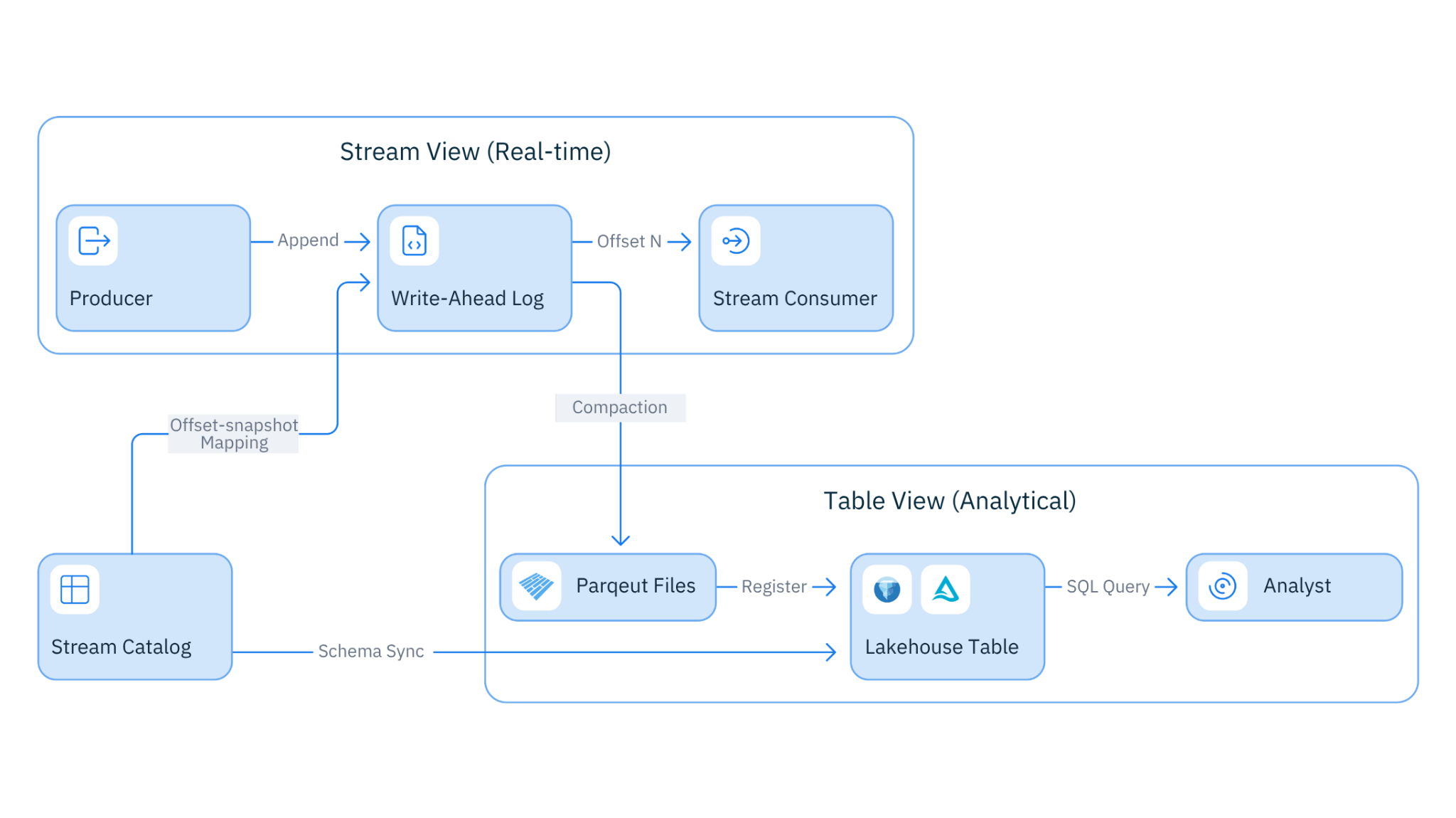
Figure 2. Stream-Table Duality
Key Capabilities
- Native Kafka Protocol: Apache Kafka 4.2+ fork. Every Kafka client, tool, and connector works with zero modifications. This isn't a compatibility layer -- it IS Kafka.
- Lakehouse-Native Storage: Every topic is stored as Iceberg or Delta Lake tables on object storage. Query your streaming data from any analytics engine that reads open table formats.
- Leaderless Architecture: No leader elections. No partition rebalancing storms. Any broker can serve any partition. Brokers are stateless compute -- add or remove them like web servers.
- Up to 95% Cost Reduction: Eliminates cross-AZ replication -- the single largest cost in cloud streaming infrastructure. Validated at 5 GB/s sustained throughput in production benchmarks.
- Zero-Connector Lakehouse Integration: No Kafka Connect. No materialization pipelines. No sink connectors. Your Kafka topics ARE your lakehouse tables. Produce to a topic, query it from Snowflake.
- Catalog Integrations: Works with Databricks Unity Catalog, Snowflake Open Catalog, and AWS S3 Tables out of the box. Your streaming data is governed by the same catalog as your batch data.
UFK Proves the Lakestream Vision
In our Lakestream post, we described the core insight: push interoperability from the protocol layer down to storage and catalog. If the foundation is right, any protocol can become a lakehouse citizen.
UFK is the clearest validation of this principle.
We didn't build a new protocol. We took the world's most popular streaming protocol -- Apache Kafka, used by tens of thousands of organizations worldwide -- and plugged Lakestream underneath it. The protocol stayed the same. The storage became lakehouse-native. The data became immediately available for analytics.
UFK didn't require reinventing Kafka. It just gave Kafka a Lakestream foundation.
That's the beauty of the Lakestream approach: the value isn't in the protocol. It's in the storage and catalog. Once those layers are right, every protocol benefits. Kafka is the first -- and given its dominance, the most impactful. But the same foundation already powers Pulsar workloads, and it's designed to support any protocol that needs lakehouse-native streaming.
Kafka is just the beginning.
What UFK Unlocks for Your Organization
For Data Engineers
Stop maintaining Kafka Connect pipelines to your lakehouse. With UFK, every topic IS a lakehouse table. Your producer code doesn't change. Your consumer code doesn't change. But now your analytics team can query the same data from Spark or Trino -- immediately, not after a batch window.
No more "connector jungle" -- the fragile web of sink connectors, schema converters, dead-letter queues, and materialization jobs that break at 2 AM and page you on weekends. The connector between streaming and the lakehouse is the storage layer itself. There's nothing to break.
For Platform Teams
UFK's leaderless architecture means no more partition rebalancing storms during scaling events. No more leader election cascades when a broker goes down. No more careful capacity planning to ensure leaders are evenly distributed. Brokers are stateless compute -- add or remove them like web servers behind a load balancer.
The cost impact is significant: up to 95% cost reduction on streaming infrastructure, validated at 5 GB/s sustained throughput. The savings come from eliminating cross-AZ replication -- the single largest cost driver in cloud-deployed streaming. At that kind of throughput, the difference between traditional Kafka and UFK is hundreds of thousands of dollars per month.
For Data and Analytics Teams
Real-time data in your lakehouse without waiting for batch ETL windows or connector lag. Query a Kafka topic as an Iceberg table from Snowflake, Databricks, or any engine that reads open table formats. The data is fresh -- not hours old, not minutes old, but current to the last committed write.
Governed by the same catalog as your batch tables -- Unity Catalog, Snowflake Horizon Catalog, or AWS S3 Tables. One set of access policies. One audit trail. One source of truth. No more governance gaps where real-time data lives outside the catalog.
For Architects
One less system to operate. The streaming platform and the lakehouse ingestion layer collapse into one. Instead of Kafka + Kafka Connect + schema converter + sink connector + monitoring for all of the above, you have UFK. Simpler architecture. Fewer failure modes. Faster time to insight.
The total cost of ownership story compounds: you save on streaming infrastructure (leaderless, no cross-AZ replication), you save on connector infrastructure (no Kafka Connect clusters to operate), and you save on engineering time (no pipelines to maintain). The architecture is not just cheaper -- it's fundamentally simpler.
Getting Started
UFK is available in Limited Public Preview starting April 7, 2026.
- Cloud support: Available on AWS and GCP today, with Azure expansion planned
- Kafka compatibility: Works with existing Kafka clients version 0.9 and above -- zero code changes required
- Table formats: Supports Apache Iceberg and Delta Lake
- Catalog integrations: Databricks Unity Catalog, Snowflake Horizon Catalog, and AWS S3 Tables
- Migration: Move from existing Kafka clusters via Universal Linking -- replicate topics from any Kafka deployment (Confluent, MSK, Redpanda, self-managed) into UFK with continuous synchronization
If you are operating some of the largest Kafka clusters in your industry and would like to explore having UFK enabled via in-place upgrade, we would love to help and explore a partnership. Talk to us -- we love to chat.
Connecting the Arc
Every step of our journey -- from Pulsar's compute-storage separation to Kafka compatibility to lakehouse-native storage to UFK -- has been building toward one vision: making streaming a first-class citizen of the lakehouse.
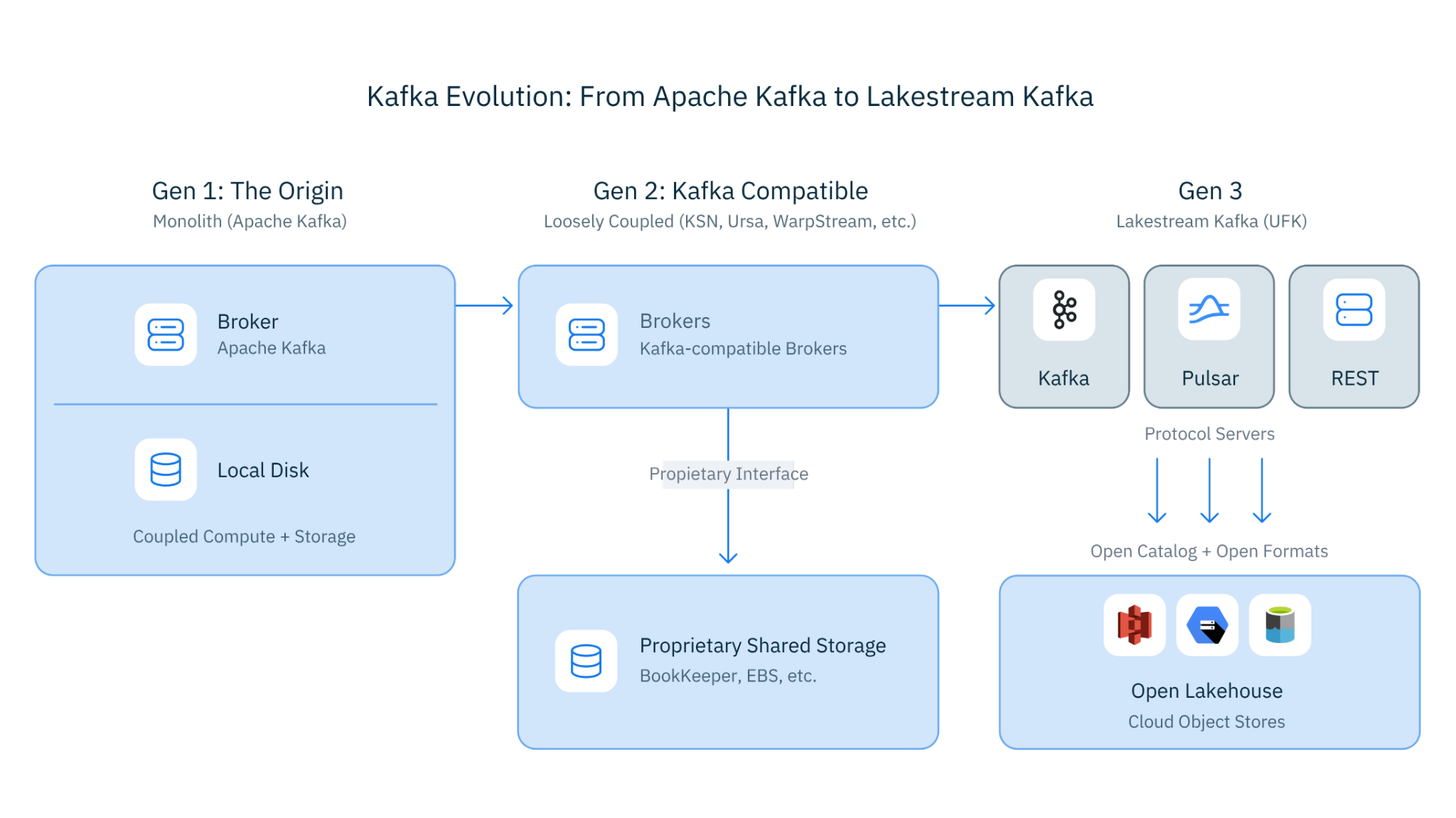
Figure 3. From Apache Kafka to Lakestream Kafka
That vision is Lakestream.
UFK is the moment where that vision meets the Kafka world. Native Kafka. Lakehouse-native storage. No compromises.
This is more than a product launch -- it's the first proof that the Lakestream architecture delivers on its promise. Take the world's most popular streaming protocol, plug Lakestream underneath, and everything just works -- except now your streaming data is also your lakehouse data.
This is what Lakestream looks like in practice. And we're just getting started.
Let's build the future -- together.







