
In the era of real-time AI, bridging data streaming with data lakehouses has become essential to ensure AI models and applications are continuously fed with high-quality, trustworthy data. Enterprises rely on AI-driven insights, but traditional architectures often fail to deliver governed, real-time data efficiently.
AI models are only as good as the data they learn from, making data acquisition essential for accurate predictions and insights. High-quality, diverse, and real-time data enables AI to adapt, detect patterns, and make informed decisions. Without a continuous flow of reliable data, AI models risk becoming outdated, biased, or ineffective in real-world applications.
While acquiring high-quality data is crucial for AI success, setting up a scalable, real-time data platform presents challenges in integration, governance, and ensuring seamless data flow across streaming and analytical systems.
The Rise of AI Increases Data Acquisition Costs
As AI-driven applications scale, the demand for real-time data acquisition grows, leading to higher infrastructure costs. When using data streaming technology for data acquisition, traditional leader-based architectures such as kafka exacerbate this by introducing bottlenecks, hotspots, and complex failover scenarios. Additionally, producers and writers face expensive cross-AZ traffic and replication costs, making data acquisition increasingly inefficient and costly.
By adopting a leaderless architecture with a lakehouse-native storage approach, Ursa eliminates inter-zone network costs—one of the biggest expenses in leader-based deployments like Kafka and Redpanda—while also reducing storage costs through cloud-native object storage and efficient columnar formats. This approach further enables real-time and batch analytics without the need for costly ETL transformations, streamlining data processing and reducing infrastructure expenses. Learn more on this blog.
AI Requires Unified Data Governance
Once data is ingested, in AI-driven analytics, maintaining unified data governance is critical, but connector-based pipelines often introduce gaps by bypassing centralized catalogs. This fragmentation leads to inconsistent access controls, lack of visibility, and compliance risks, making it difficult to ensure data integrity and security across the enterprise.
This blog post explores StreamNative’s vision for seamless integration with leading Data Catalogs, including Unity Catalog and Iceberg Catalogs, enabling enterprises to unlock AI-driven use cases by providing a unified, real-time data foundation for machine learning and analytics.
How Data Catalogs Simplify Data Governance, Discovery, and Security
The Lakehouse architecture combines the best features of data lakes and data warehouses, offering a unified platform for both analytical and operational workloads. At the core of this architecture are Data catalogs, like Apache Iceberg catalogs and Unity Catalog, which provide centralized metadata management to streamline data discovery, governance, and security. These catalogs enable fine-grained access controls, automate data lineage tracking, and enforce consistent security policies across the organization. By offering built-in governance features and simplifying regulatory compliance, Data catalogs help enterprises maintain secure, well-managed data environments, making it easier to discover, trust, and leverage data for decision-making.
As enterprises manage multiple teams consuming data, Data Catalogs play a critical role in data governance. Whether leveraging Unity Catalog or Iceberg-based catalogs, these solutions empower governance teams to secure data assets, monitor access, and ensure regulatory compliance, offering a centralized and auditable framework for effective data management.
StreamNative’s vision is to simplify the complexities of building a scalable, real-time data platform by bridging data streaming and lakehouse storage with a unified approach. We aim to address challenges in integration, governance, and performance, enabling enterprises to harness real-time data for AI and analytics seamlessly. While we lead in this space, other industry peers are also working toward similar goals, collectively driving innovation to make real-time data infrastructure more accessible and efficient.
Empowering AI with Catalogs: Simplifying Data Discovery and Accessibility
A data catalog is a centralized collection of data assets, accompanied by details about those assets. It provides resources to assist users in locating reliable data, comprehending its purpose, and utilizing it correctly. Serving as a metadata repository, it delivers the context required for effective data utilization.
Catalogs play a critical role in the success and usability of open lakehouse architectures. They act as the metadata backbone, enabling seamless data discovery, governance, and operations across open table formats like Apache Iceberg, and Delta Lake.
A catalog, in the context of data management and analytics, is a centralized metadata repository that stores and organizes information about data assets. It helps users discover, understand, and manage data efficiently. Here's the type of information typically stored in a catalog:
- Metadata about datasets
- Data location
- Data quality and profiling
- Versioning and lineage
- Access and governance
- Enrichment and annotations
- Operational details
- Integration with other systems
- Custom attributes
Benefits of Data Catalogs
Data Catalogs provide a range of benefits, some of which are outlined below.
- Centralized Metadata Management Store and centralize metadata, ensuring consistent data access and interpretation across tools. Transactional Consistency
- Enable ACID transactions, ensuring safe concurrent reads and writes for accurate data. Data Discovery and Lineage
- Make datasets searchable and track data lineage for governance and compliance. Interoperability Across Tools
- Unify metadata, enabling tools like Spark, Trino, and Flink to work seamlessly together. Schema and Version Control
- Support schema evolution and time travel, enabling reproducible analytics workflows. Data Governance and Security
- Enforce fine-grained access control, protecting sensitive data while ensuring accessibility. Orchestration of Real-Time and Batch Data
- Manage hybrid workflows, enabling real-time ingestion and batch queries. Facilitating AI/ML Workflows
- Streamline metadata management for training, monitoring, and detecting data drift.
There are numerous Data Catalogs available, but this post will specifically focus on StreamNative’s integration with Unity Catalog ,Snowflake Open Catalog and AWS S3 Tables.
StreamNative Cloud: Bridging the Gap with Data Catalog Integrations
StreamNative Cloud aims to deliver a fully managed, out-of-the-box service that enables seamless data ingestion into various Data Catalogs within seconds. Users can effortlessly activate catalog integration and select their preferred catalog from supported vendors. StreamNative includes support for Delta Lake through Unity Catalog and Apache Iceberg via multiple catalog implementations, such as Snowflake’s Open Catalog and Amazon S3 Tables.
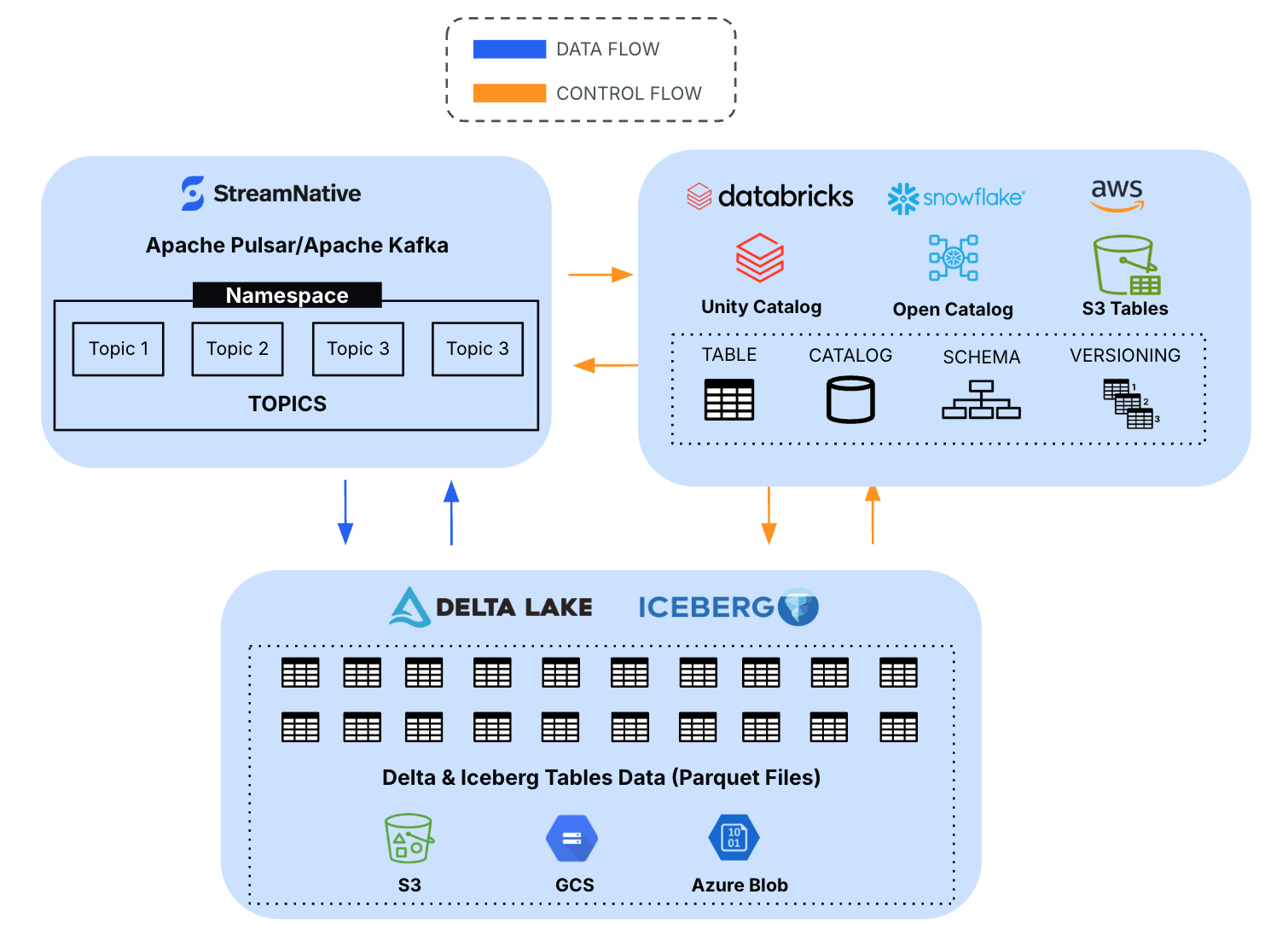
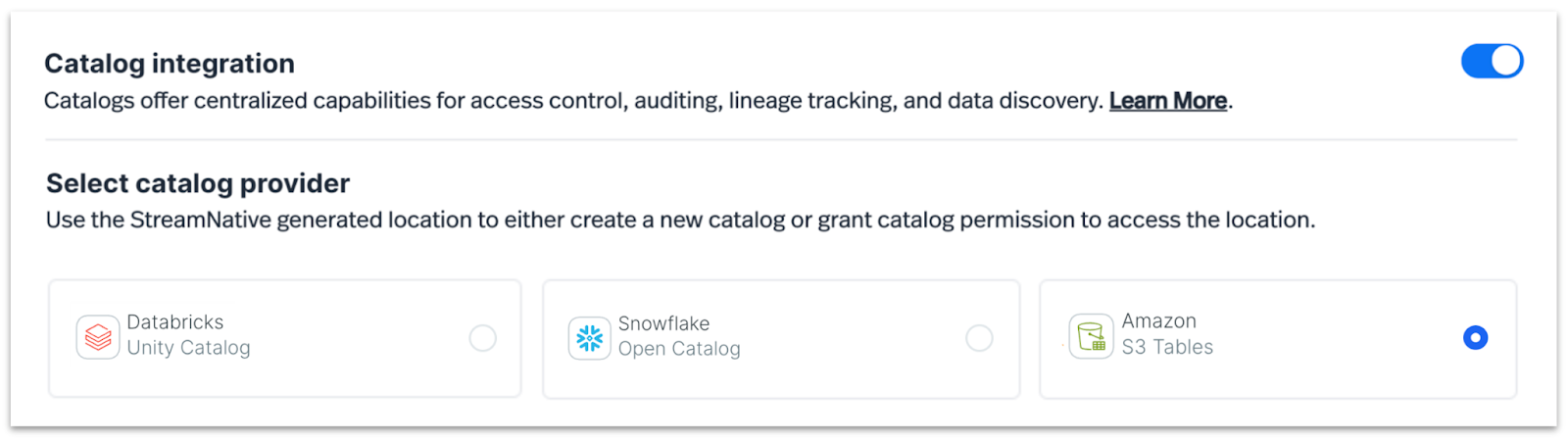
During the creation of a StreamNative Ursa Cluster, users have the option to enable Data Catalog Integration, select a preferred catalog provider, configure the necessary settings, and proceed with cluster deployment.
Databricks Unity Catalog: A unified governance solution from Databricks, offering fine-grained access control, data lineage, and metadata management for Delta Lake and other open data formats. Learn more about StreamNative’s integration with Databricks Unity Catalog.
- Snowflake Open Catalog: Part of Snowflake's advanced capabilities, it supports hybrid data management across structured and semi-structured data, empowering unified analytics and governance. A blog on this topic will be published soon.
- Amazon S3 Tables: An AWS S3 Table stores tabular data in S3 for efficient querying with Athena or Redshift Spectrum, using formats like Parquet and managed via AWS Glue.A blog on this topic will be published soon.
With this comprehensive support, StreamNative Cloud ensures organizations can leverage the best-in-class capabilities of these catalogs to simplify governance, enhance interoperability, and accelerate data-driven innovation.
Once a catalog is enabled, StreamNative begins writing cluster data to the designated storage location, with the data seamlessly published in the catalog. Users can effortlessly discover and query data directly from the catalog.
Conclusion
As AI becomes mainstream, enterprises need a cost-effective, scalable way to ingest and govern real-time data. Traditional ETL pipelines are slow and expensive, while legacy streaming architectures introduce inefficiencies that drive up costs. StreamNative’s Ursa Engine, built on a leaderless architecture, eliminates these challenges—cutting real-time data ingestion costs by 90% and seamlessly integrating with leading Data Catalogs to unify governance across both streaming and batch data.
- Seamless Data Streaming & Metadata Management: StreamNative Cloud integrates open Data Catalogs, enabling real-time data streaming with robust metadata management.
- Native Integration Advantage: Eliminates the need for connector-based pipelines that do not publish data to catalogs, ensuring a more efficient approach.
- Broad Catalog Support: Supports Unity Catalog, Snowflake Open Catalog, and S3 Tables for simplified data governance and interoperability.
By bridging real-time streaming with lakehouse storage and governance, StreamNative enables enterprises to maximize the value of their AI and analytics investments—eliminating data silos, reducing infrastructure costs, and ensuring AI models operate on fresh, high-quality, and trusted data.
Here are a few resources for you to explore:
- Watch our workshop: Augment Your Lakehouse with Streaming Capabilities for Real-Time AI to get an end-to-end overview of StreamNative’s integration with Databricks Unity Catalog.
- Documentation for Unity Catalog Integration : Follow these steps to integrate StreamNative Cloud with Databricks Unity Catalog.
- Documentation for Snowflake Open Integration : Follow these steps to integrate StreamNative Cloud with Snowflake Open Catalog
- Documentation for Amazon S3 Tables : Follow these steps to integrate StreamNative Cloud with Amazon S3 Tables
- Check out StreamNative's recent benchmark about Ursa Engine: See how Ursa sustains a 5GB/s Kafka workload at just 5% of the cost of traditional streaming engines like Kafka and Redpanda.
- Read the detailed architectural blog post of Ursa Engine: Learn how leaderless architecture and lakehouse storage reduce 95% of Kafka cost.
- Watch our recent webinar with Databricks: Watch the Databricks and StreamNative webinar, where we discussed about the native integration with Unity Catalog.
Try it yourself: Sign up for a trial to explore StreamNative's Ursa Engine and experience the power of real-time data in action.




