
Last week, I had the opportunity to present "Ursa: Augment Iceberg with Kafka Data Streaming Capabilities" at the Apache Iceberg Bay Area Meetup. After that event, our team also released a blog post benchmarking the cost comparison between Ursa and other data streaming engines. We demonstrated that Ursa can run a 5 GB/s Kafka workload at just 5% of the infra cost of traditional leader-based data streaming solutions. This has sparked increasing interest in how we drastically cut infrastructure costs.
While we have more technical papers coming soon, I’d like to use this blog post to share insights about two key innovations in Ursa Engine that enable these cost reductions:
- Leaderless architecture: Eliminating inter-zone client traffic costs via a leaderless design.
- Lakehouse-native storage: No inter-zone data replication via direct writes to cloud object storage and leveraging open table formats.
This blog post will break down how these architectural choices lead to massive cost reductions while maintaining the performance and durability required for data streaming workloads.
Challenges of Leader-Based Architectures
As discussed in our previous blog post, “The Evolution of Log Storage in Modern Data Streaming Platforms”, and the keynote presentation “Data Streaming: Past, Present, and Future” in Data Streaming Summit 2024, the evolution of storage engines for data streaming has moved from leader-based to leaderless architectures. But what does this really mean?
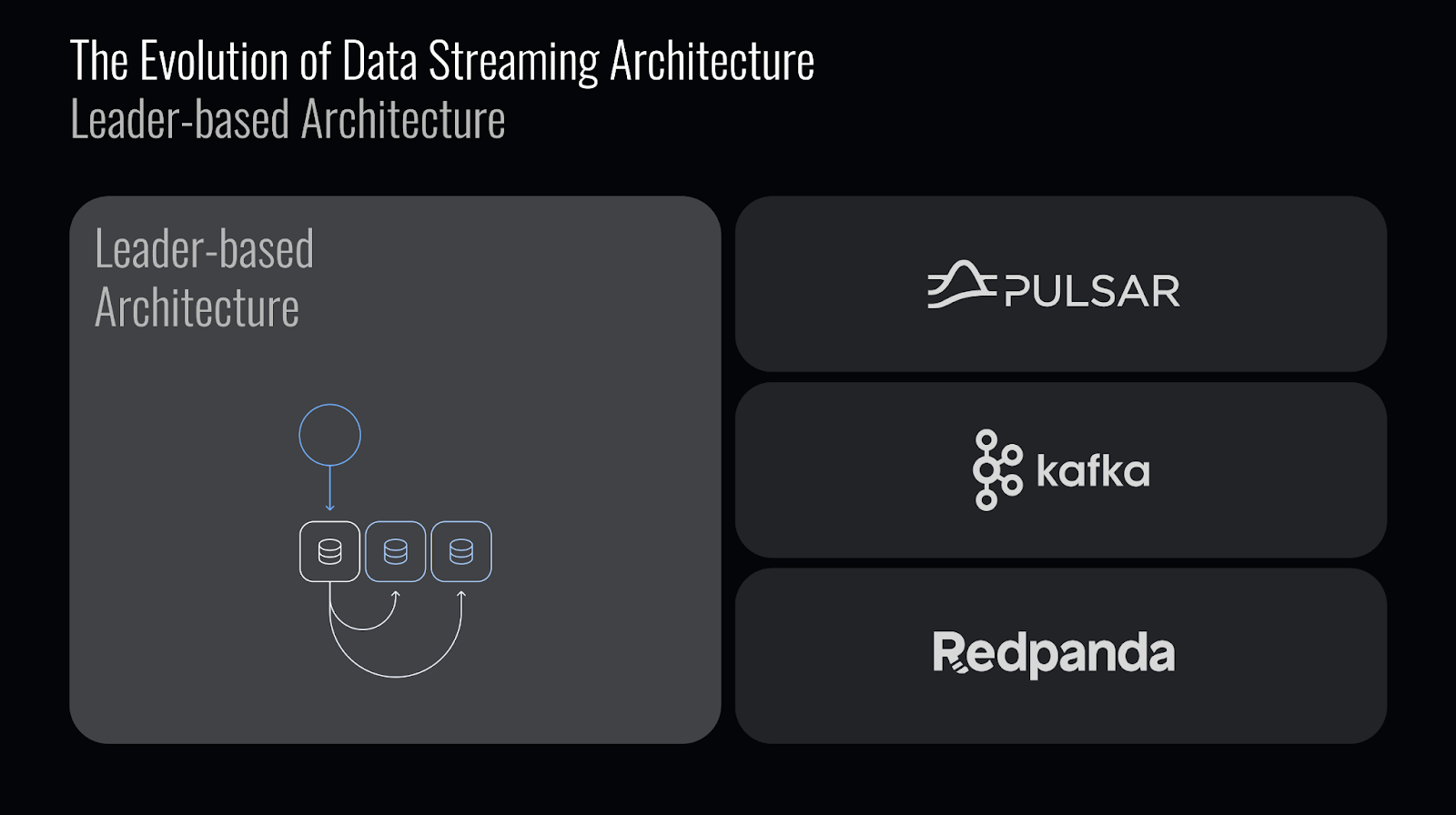
Most traditional data streaming engines, including Apache Kafka, Apache Pulsar, and Redpanda, deploy a leader-based data replication model. In this model:
- Each topic partition has a designated leader broker responsible for handling incoming data and serving consumers.
- Data is replicated from the leader to multiple followers across availability zones (AZs) to ensure durability and fault tolerance.
- Different replication algorithms are used: Kafka employs ISR replication, Redpanda relies on Raft, and Pulsar utilizes a Paxos-variant via BookKeeper.
The Hidden Costs of Leader-Based Replication
Leader-based replication is essential for achieving ultra-low latency (typically single-digit to sub-100 milliseconds). Our previous Pulsar benchmark report demonstrated that Pulsar consistently achieves latencies below 5 milliseconds. This architecture is useful for workloads demanding extreme low-latency guarantees.
However, the majority of data streaming workloads don’t require ultra-low latency, nor should they have to pay a premium for an over-killed architecture. For example, ingesting data into data lakehouses does not necessitate single-digit millisecond latency. Instead, the focus is on efficiently handling large volumes of data, which calls for a highly cost-effective data streaming engine to feed data into Iceberg or Lakehouse. This need has become even more urgent with the rise of DeepSeek disrupting AI infrastructure, pushing companies to confront soaring costs—not only for training and deploying AI models but also for data acquisition and ingestion.
Cost Challenges in Leader-based Data Streaming:
- Inter-zone client traffic: Since each partition has a leader broker, producers often have to cross AZ boundaries to send data, increasing network costs.
- Inter-zone data replication costs: Every write operation triggers costly cross-AZ replication.
- Broker hotspots: Leaders often become bottlenecks, leading to uneven workload distribution.
- Failover complexity: When a leader fails, a new leader election occurs, triggering additional replication, cross-AZ traffic, and operational delays.
While solutions like Apache Pulsar decouple storage from compute to minimize rebalancing overhead, the fundamental cost problem remains unsolved in leader-based systems.
Leaderless Architecture: Breaking Free from Leader-based Constraints
Ursa Engine eliminates leader-based replication entirely, adopting a leaderless architecture—an approach now also being explored by innovations like Confluent’s Freight Clusters and WarpStream.
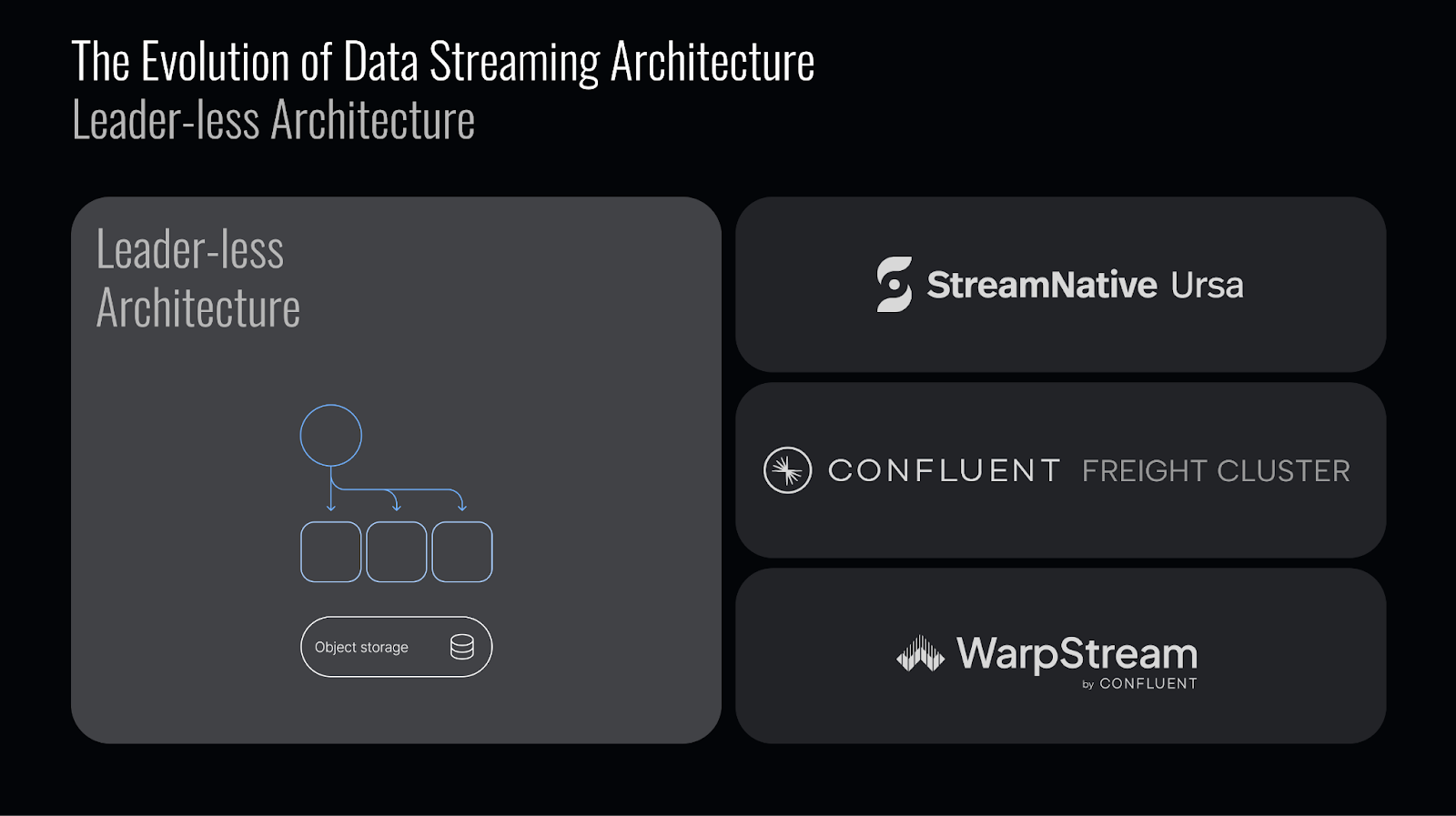
How It Works
In our "Evolution of Log Storage" blog post, we introduced the concept of index/data split (originally pioneered in Pulsar). This approach stores log segment indexes in a centralized metadata store, keeping log segments remote and decoupled from brokers. This avoids data rebalancing overhead.
Ursa’s leaderless architecture takes this concept further:
- Offset tracking and sequencing coordination are moved to a centralized metadata/index service - Oxia.
- Brokers no longer handle sequencing, indexing, or offset tracking—instead, this is managed by Oxia, a scalable metadata/index service developed by StreamNative.
- This fully decouples metadata operations from data operations, enabling: Shared storage for durability (e.g., AWS S3).
- Shared metadata/index service for sequencing, indexing, and offset tracking.
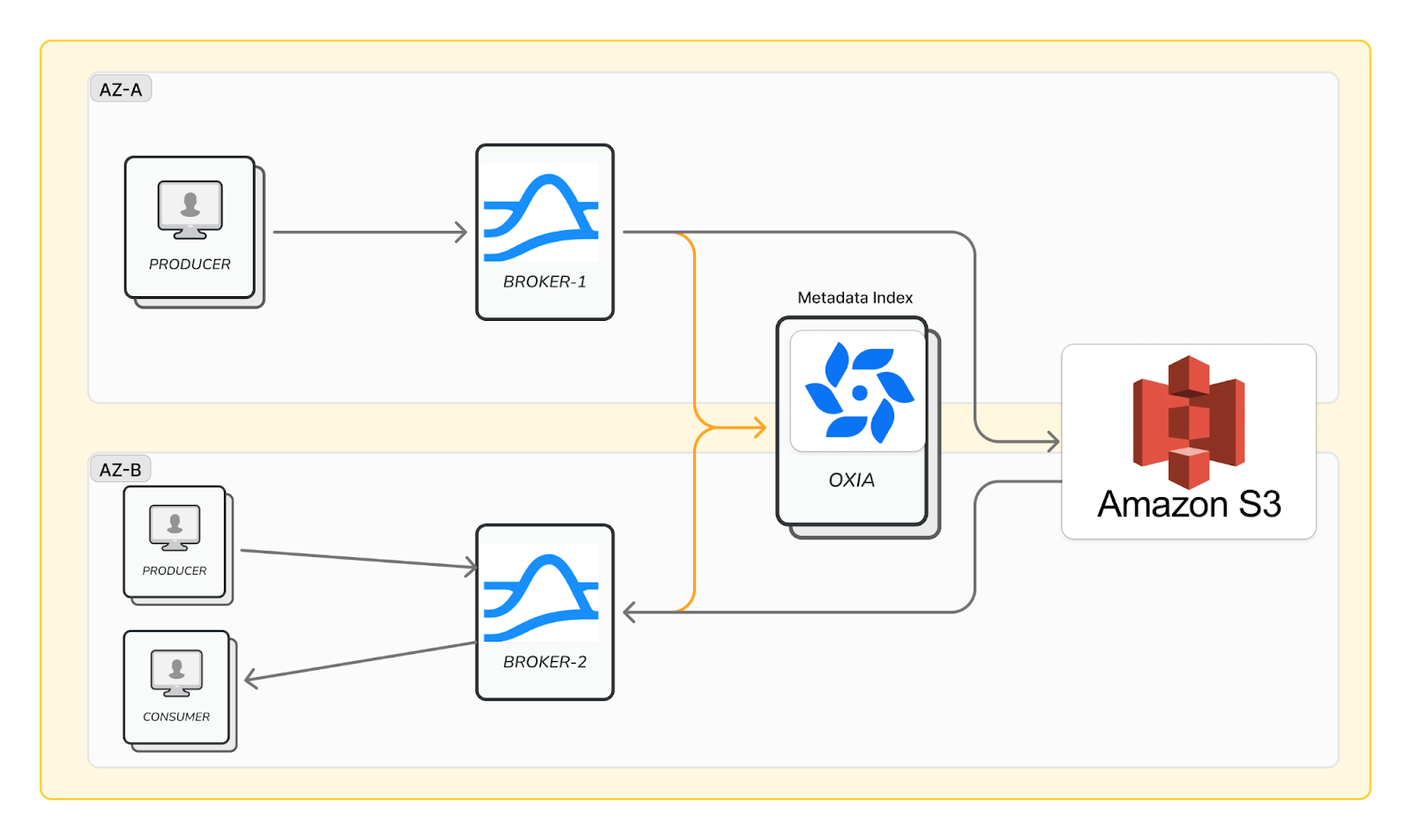
The diagram above illustrates how a leaderless system operates.
Equal brokers: Every broker is equal—any node can accept writes and independently store them in a shared storage service, such as AWS S3. This eliminates the need for clients to traverse availability zones to locate a broker leader, thereby removing inter-zone client traffic.
Direct writes to object storage: Data is persisted directly in object storage for durability, eliminating the need for brokers to replicate data across availability zones. In Ursa’s case, data is written directly to cloud object storage (more on this in the next section).
Reduced network costs: By removing both inter-zone client traffic and inter-zone data replication, this approach significantly reduces cloud network costs—one of the biggest hidden expenses in traditional leader-based deployments like Kafka and Redpanda.
After brokers independently write data to object storage, they commit metadata updates to Oxia. While this generates some cross-AZ metadata traffic, it is significantly smaller than the actual data movement, making it negligible.
This leaderless approach enables linear scalability while dramatically reducing network costs, making high-throughput workloads far more efficient than traditional leader-based systems.
Lakehouse-Native Storage: Eliminating Inter-Zone Replication
The Hidden Cost of Leader-based Data Replication
Traditional leader-based streaming engines store data on local disks and replicate it across AZs for durability. This means that each byte is replicated at least three times, traversing inter-AZ boundaries twice, driving up storage and network costs.
Additionally, these engines store data in row-based formats (e.g., AVRO, JSON, Protobuf), which are inefficient for analytical workloads, requiring costly ETL processes before use in data lakehouses.
Ursa’s Approach: Direct Writes to Lakehouse
Ursa Engine eliminates these inefficiencies by adopting a lakehouse-native storage model:
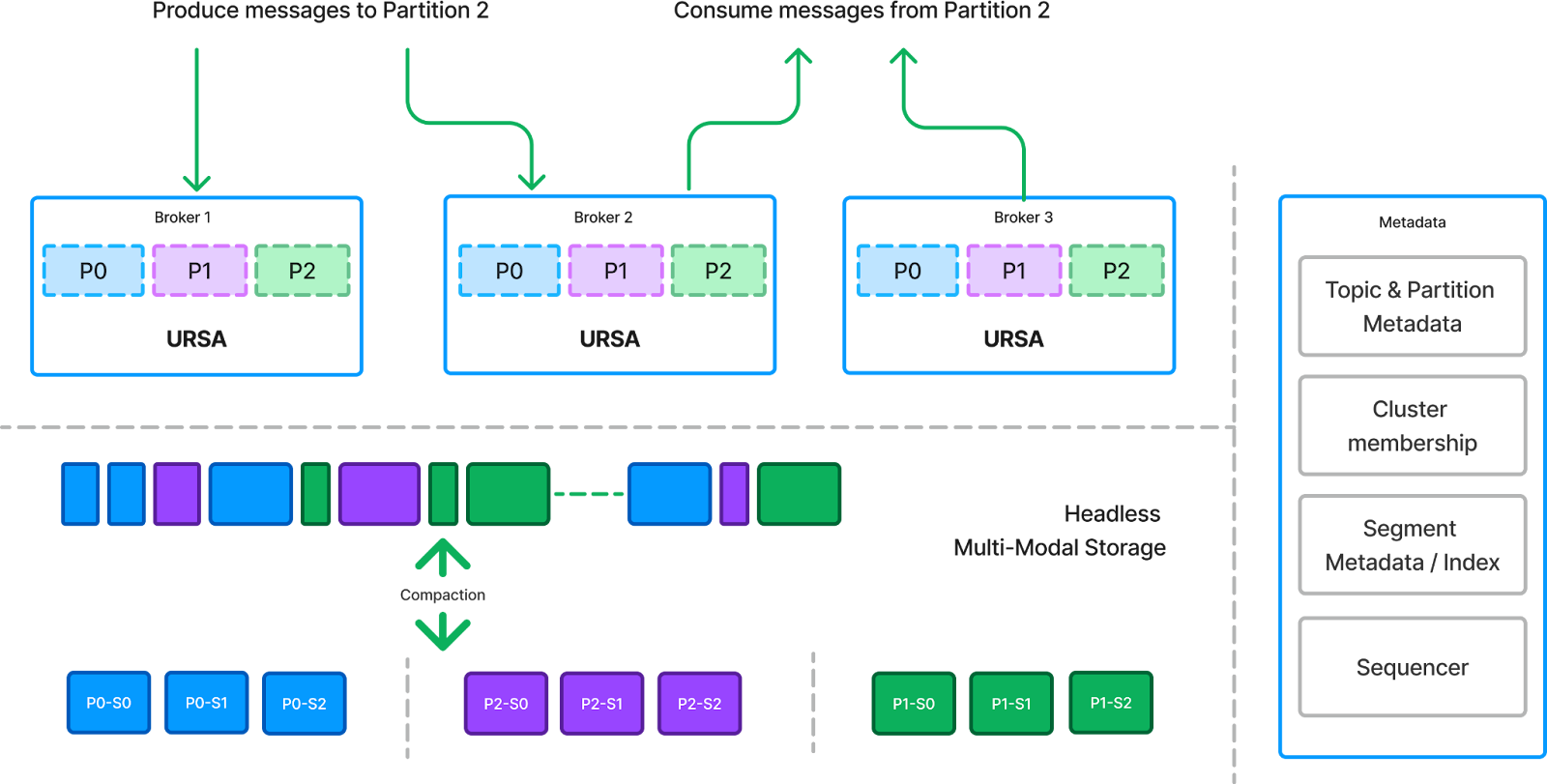
The entire storage engine is designed around the concept of augmenting the lakehouse tables with a write-ahead log (WAL) for data streaming, which achieves the “stream-table” duality by offering both streaming and table accesses over the same data sets.
The Write-Ahead Log (WAL) component stores the original records produced via Kafka or Pulsar protocols. Data from different topics is multiplexed into a broker-level write buffer and flushed out as a WAL file object. The records are stored in row format, and writes go directly to cloud storage (S3, GCS, or Azure Blob Store), eliminating the need for brokers to replicate data across availability zones.
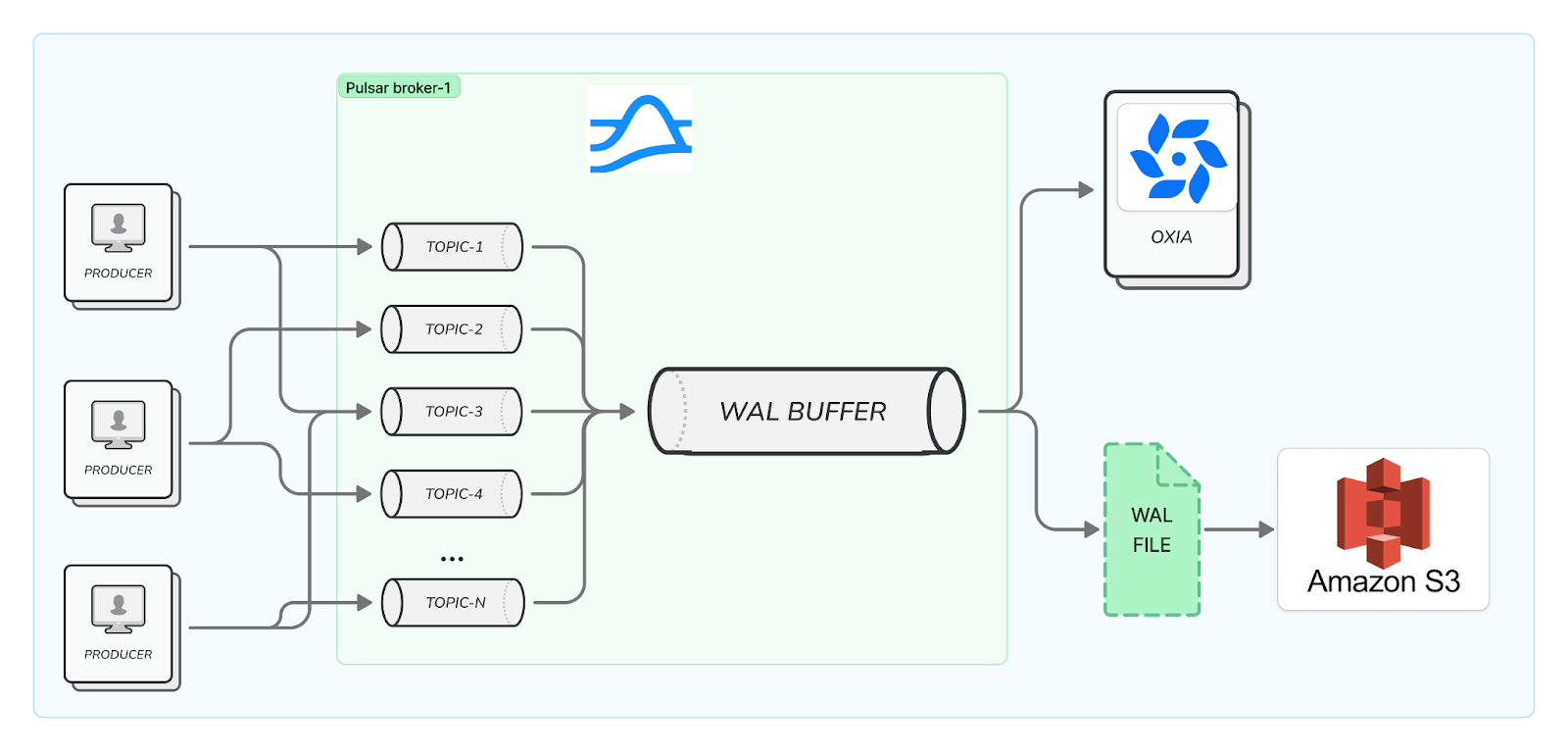
With this multiplexed write-ahead log approach, we minimize write latency and reduce the number of write requests to object storage. It also maximizes the size of compacted data, enabling more efficient reads from object storage when compacting data into columnar formats.
Once data is persisted in the write-ahead log, the produce request is completed and returned to the client. The data remains buffered in the broker for tailing reads, ensuring no delay in dispatching messages.
If data retention is short, WAL data can expire quickly. However, for workloads requiring longer retention, Ursa runs a background compaction service that processes WAL files. Instead of compacting WAL files into another row-based format, we leverage schema information to infer record structures and convert data into columnar formats, saving them as Parquet files. These Parquet files are then organized into open lakehouse formats like Apache Iceberg and Delta Lake, allowing long-term data to be directly stored in columnar format and accessed via open lakehouse standards. This enables seamless integration with the lakehouse ecosystem.
Despite data being compacted into Parquet files, you can still use the Kafka protocol to replay or catch up on historical data. Leveraging schema information and columnar storage reduces costs through efficient compression while optimizing queries for downstream analytics and Kafka-based replays.
This approach represents Ursa’s key innovation in bridging data streaming and the lakehouse ecosystem with a "Stream-Table" dual format—storing a single copy of data while enabling access via either a table format or a stream format. We will publish a detailed technical blog post outlining the specifications of this stream format soon.
The Benefits of Lakehouse-Native Storage
- Zero inter-zone replication costs: Since data is written directly to a write-ahead log powered by cloud object storage, there is no need to replicate data across availability zones.
- Massive storage cost reduction: Storing long-term data in Parquet rather than raw log segments reduces storage footprint and improves compression efficiency.
- Seamless analytics integration: Data can be queried directly using Spark, Trino, Databricks, or Snowflake without the need for expensive ETL pipelines.
By eliminating local broker storage and persisting data directly to cloud storage using open lakehouse formats, Ursa reduces both network and storage costs while enabling real-time and batch analytics on the same dataset.
If you're interested in learning more about the concept of "Stream-Table Duality," check out our previous blog post: Stream-Table Duality and the Vision of Enabling Data Sharing.
A Note on Iceberg Integration
Integrating data streaming engines with Iceberg—and open lakehouse formats in general—is an increasingly popular trend. Solutions like Confluent’s Tableflow, Redpanda’s Iceberg topics, and other data streaming vendors have introduced similar concepts for incorporating Iceberg into their systems. However, not all Iceberg integrations are created equal. Ursa takes a more comprehensive approach compared to the solutions mentioned above.
In Ursa, Iceberg—and lakehouse storage in general—is implemented in two modes:
- Stream Backed by Table (aka Ursa Managed Table)
- Stream Delivered to Table (aka Ursa External Table)
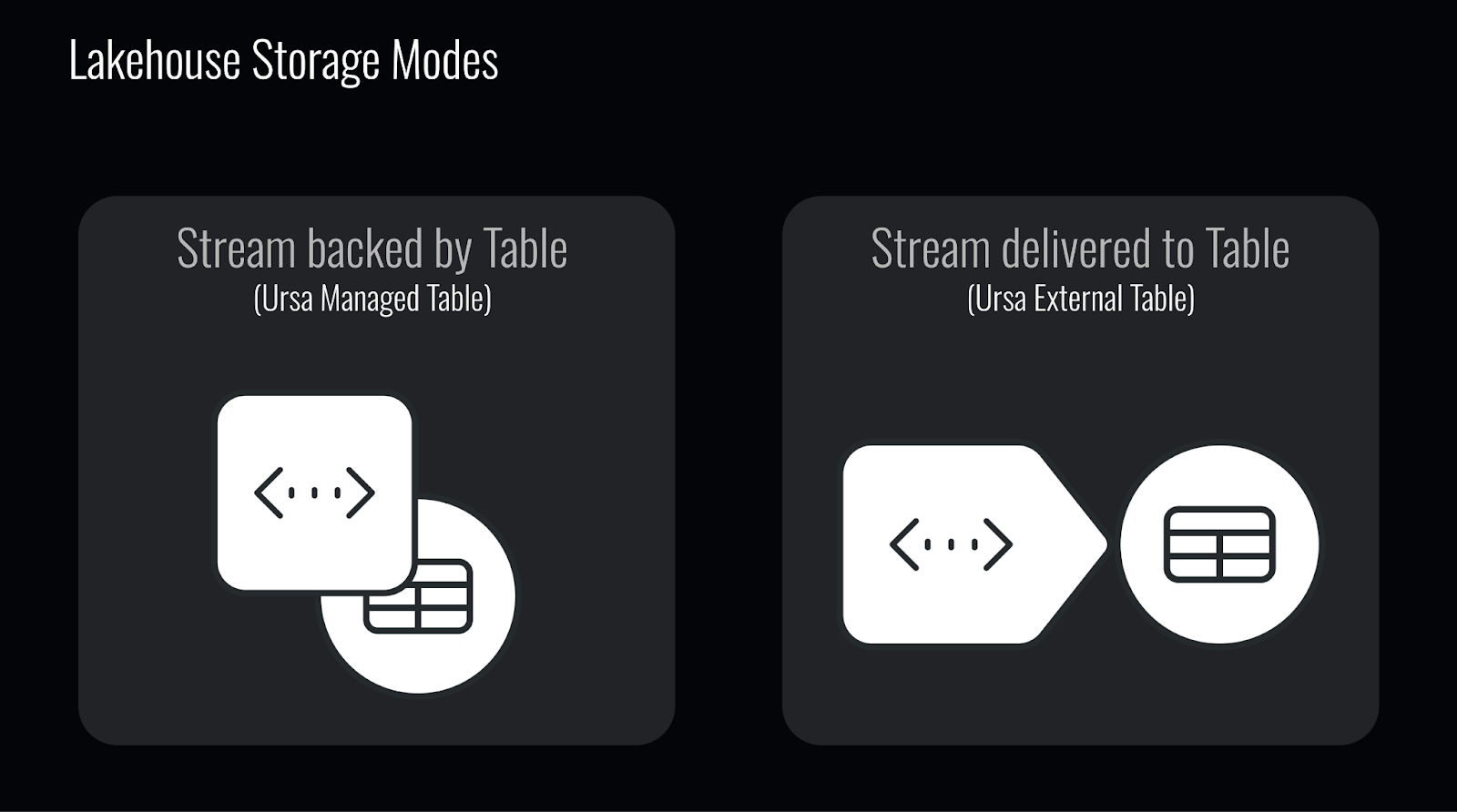
Stream Backed by Table – Ursa Managed Table
Ursa’s default lakehouse-native storage follows the "stream backed by table" concept. This approach, as described earlier, compacts all streaming data into columnar Parquet files, organizing them into Iceberg or Delta Lake table formats. As a result, only one copy of the streaming data is stored, and all streaming-related metadata—such as offsets and ordering—is preserved.
This means you can replay the entire stream by reading the Parquet files from the backed table. This is how we achieve “stream-table duality” while maintaining a single copy of data governed by a catalog service.
We call this “Ursa Managed Table” because Ursa manages the entire lifecycle of the data based on retention requirements and registers the table in a data catalog for easy discovery.
✅ Best for: Storing bronze tables in the lakehouse, which retain all historical data for replay and auditing purposes.
Stream Delivered to Table – Ursa External Table
By contrast, Stream Delivered to Table is the Iceberg integration that most data streaming engines have implemented. The idea is to move connector-based data streaming and lakehouse integration into the streaming engine as a native feature.In this model, data streaming engines only deliver data to an external lakehouse table—they do not manage its lifecycle. This typically means:
- Two copies of data are stored: Log segment data (row-based format) for streaming read/write.
- Lakehouse-formatted data for analytics.
- Streaming reads via the Kafka protocol are not possible from the lakehouse table.
Since the lifecycle of Stream and Table is decoupled, this mode is better suited for storing compacted data using upsert operations. Streaming engines can either append or upsert changes into the external table, providing more flexibility in organizing data via different partitioning strategies.
We call this “External Table” because Ursa does not manage the table’s lifecycle—instead, it is typically managed by a data catalog service provider, which may also offer table maintenance services to optimize tables.
✅ Best for: Storing compacted, curated, and transformed data—such as silver and gold tables in the lakehouse.
Ursa takes a more holistic approach in defining “Stream-Table Duality”, seamlessly integrating data streaming with lakehouses to deliver a well-integrated, end-to-end data solution.We hope this note clarifies the different Iceberg/lakehouse integration approaches and helps distinguish the unique advantages of Ursa's design.

Cost Breakdown: Kafka / Redpanda vs. Ursa
Now that we’ve explored Ursa’s innovations, let’s compare the costs of running data streaming workloads in a cloud environment.
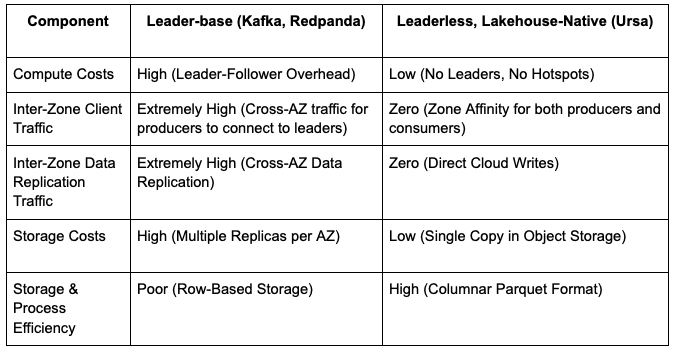
With Ursa, the combination of a leaderless architecture and lakehouse-native storage results in an order-of-magnitude cost reduction (up to 10x). This makes high-throughput data streaming and data ingestion into a lakehouse economically viable at scale.
Conclusion
We are at an exciting moment in the convergence of streaming, lakehouse, and AI. Innovations in data and AI infrastructure are reshaping the landscape, and Ursa represents a fundamental shift in how real-time data streaming is architected for the AI and lakehouse era.
By moving away from leader-based architectures and embracing a leaderless architecture with lakehouse-native storage approach, Ursa has:
✅ Eliminated inter-zone network costs (both client and data replication traffic), one of the largest expenses in leader-based deployments like Kafka and Redpanda. ✅ Reduced storage costs by leveraging cloud-native object storage and efficient columnar formats. ✅ Enabled real-time + batch analytics without the need for expensive ETL transformations.
The result?
A 5 GB/s Kafka-compatible workload running for just $50 per hour—a fraction of the cost of traditional leader-based architectures.Ursa isn’t just an incremental improvement—it’s a revolutionary rethinking of data streaming for lakehouses in the AI era. If you're looking to cut costs while scaling your data streaming workloads or ingesting data into lakehouses, it’s time to give Ursa a spin.
Want to learn more?
📩 Get in touch with us to see Ursa in action! 🔔 Stay tuned—more Ursa updates are coming next week!




