
We were thrilled to unveil our new data streaming engine at this week's Pulsar Summit. Ursa is not something entirely new; those familiar with Pulsar and StreamNative will recognize it as the culmination of years of development by our talented engineering team at StreamNative.
Ursa is a Kafka API-compatible data streaming engine built on top of Lakehouse, and it simplifies management by eliminating the need for ZooKeeper and BookKeeper. Our journey toward Kafka API compatibility began with KoP (Kafka-on-Pulsar), evolved into KSN (Kafka-on-StreamNative), and has now officially been made generally available as part of the Ursa engine. The concept of Lakehouse storage, initially introduced in 2021 as part of offloading in columnar formats, was developed into a streaming offloader for Lakehouse Tiered Storage and presented at the Pulsar Summit in 2023. It has now become the primary storage solution for the Ursa engine. Oxia, introduced in 2022 as a replacement for ZooKeeper, has become the robust metadata plane of the Ursa engine (I deliberately use "metadata plane" rather than "metadata storage"). Making BookKeeper optional is the final piece of our long-standing "No Keepers" initiative, which is expected to achieve GA status soon. While the "No Keeper" approach is forward-thinking, we must acknowledge that BookKeeper remains essential for achieving ultra-low latency in data streaming and is particularly suitable for on-premise or cloud deployments without concerns about inter-AZ traffic costs.
While there are many technical details to explore behind these developments, we will continue to delve deeper into each in future blog posts. In this blog, I want to unpack the technology vision behind Ursa—enabling effective data sharing across teams, departments, and even organizations.
Data Sharing, Cost-Efficiency, and The First Principle
Cost is obviously a top priority for everyone. We want to help people reduce the total cost of ownership, enable them to reinvest the saved capital in other business innovations, and accelerate their time to market.
Strategies like separating compute from storage to avoid overprovisioning, saving data in more cost-effective storage mediums, reducing cross-AZ traffic, or even rewriting code in C++ or Rust are all tactics to achieve cost efficiency. It is common for vendors to periodically rewrite technologies to align with the underlying technological cycle, a typical pattern seen in the tech industry. Eventually, everyone catches up in one way or another.
So, the most important question is: What is the First Principle we should follow to achieve cost-effectiveness?
A data streaming platform's primary focus is sharing data between machines, services, teams, departments, and organizations. So, we asked ourselves, how can we share data efficiently?
When we created Pulsar, we had the answer almost from day one: “Save one copy of data and consume it in different ways the businesses need.” This is the fundamental principle behind Pulsar’s unified protocol (queuing and streaming) and multi-tenancy.
- Unified Queuing and Streaming: The concept of unified queuing and streaming involves storing the data in a single copy, which can be consumed as a stream or as a queue (competing consumers). This means you don’t need to save multiple copies.
- Multi-Tenancy: The idea of multi-tenancy is to store the data once and allow multiple teams to use the same data within the same cluster without needing to copy it to another location.
We extend this principle further in Ursa: if we already have operational and transactional data coming in as streams and queues, why not keep just one copy of the data and make it available to analytical processors? This concept, known as the stream-table duality, allows for the sharing of transactional/operational data with analytical processors. I'll explore this concept further later in the blog post. Before that, I want to discuss “Unified” and “Data Sharing”.
Unified vs Data Sharing
You probably hear much about "unify" and "unification" from the industry and the market. Common terms include unifying queuing and streaming, batch and streaming, etc. We used to discuss “unified messaging” quite extensively. However, this is actually a trap, as it creates data gravity by leading people to adopt certain protocols, which contradicts the openness and data-sharing nature of data streaming.
We are escaping this trap by elevating the Kafka protocol to a first-class citizen, evolving from a single protocol to a multi-protocol platform. We have opened up the underlying stream storage engine to support various protocols, enabling data sharing among teams who can choose the most suitable protocol for their business needs.
This mindset also extends to our goal of making operational and transactional data in the data streams available for analytical processors. Instead of unifying batch and stream processing on the compute engine side, we are reversing this approach. By implementing the Stream-Table duality in the storage engine layer, we make the data shareable and usable by analytical processors. Thus, you can bring your own compute (yet another BYOC) to process the tables materialized in the lakehouse.
Clearly, this Stream-Table duality would not be possible without the rise of the lakehouse and its open standard storage formats. Without adhering to a standard lakehouse table format, we would risk creating data gravity that forces people to adopt a vendor’s proprietary table format.
Hopefully, you understand our vision and the first principle behind building Ursa and StreamNative. Let’s dive deeper into the technology to understand how we follow this First Principle and how we built Ursa as a data streaming engine enabling data sharing.
Data Streams: Turning Tables Inside-Out
If you're familiar with Kafka and stream processing, you probably know the concept of "turning tables inside-out." This idea, championed by Martin Kleppmann and Confluent in 2014, has influenced the entire data streaming technology and industry. Data streams have become a primitive for sharing in-motion data between microservices, business applications, and more. Vendors like Confluent, StreamNative, and many others have built their platforms around this concept, each with its unique implementation flavor.
Pulsar is notably unique. In the market, there are many different flavors of Kafka, but there is only one Pulsar. We have written various blog posts and presented numerous talks about Pulsar, so I won’t delve deeper here; I'll discuss this at a higher level.
The fundamental component powering a data streaming engine is a store of data streams or logs. Most implementations manage logs on a per-topic basis, known as the "partition-based" storage model.
Pulsar deviates significantly from this norm. It can be thought of as a giant write-ahead log that aggregates data from various topics (streams), with each topic represented by a different collar in the diagram below (Figure 1).
- All writes from different topics are first aggregated and appended to this giant write-ahead log. This approach allows efficient batching from millions of topics, supporting extremely high throughput without compromising latency. This secret sauce allows Pulsar to handle millions of topics, with ambitions to support hundreds of millions.
- After data is appended to this write-ahead log, it is compacted by relocating messages or entries from the same topics into continuous data blocks (shown as “Data Segments” in the diagram), accompanied by a distributed index (shown as “Distributed Index” in the diagram). This index, used for locating the data segments and the data within those data segments, ensures fast data scans and lookups.
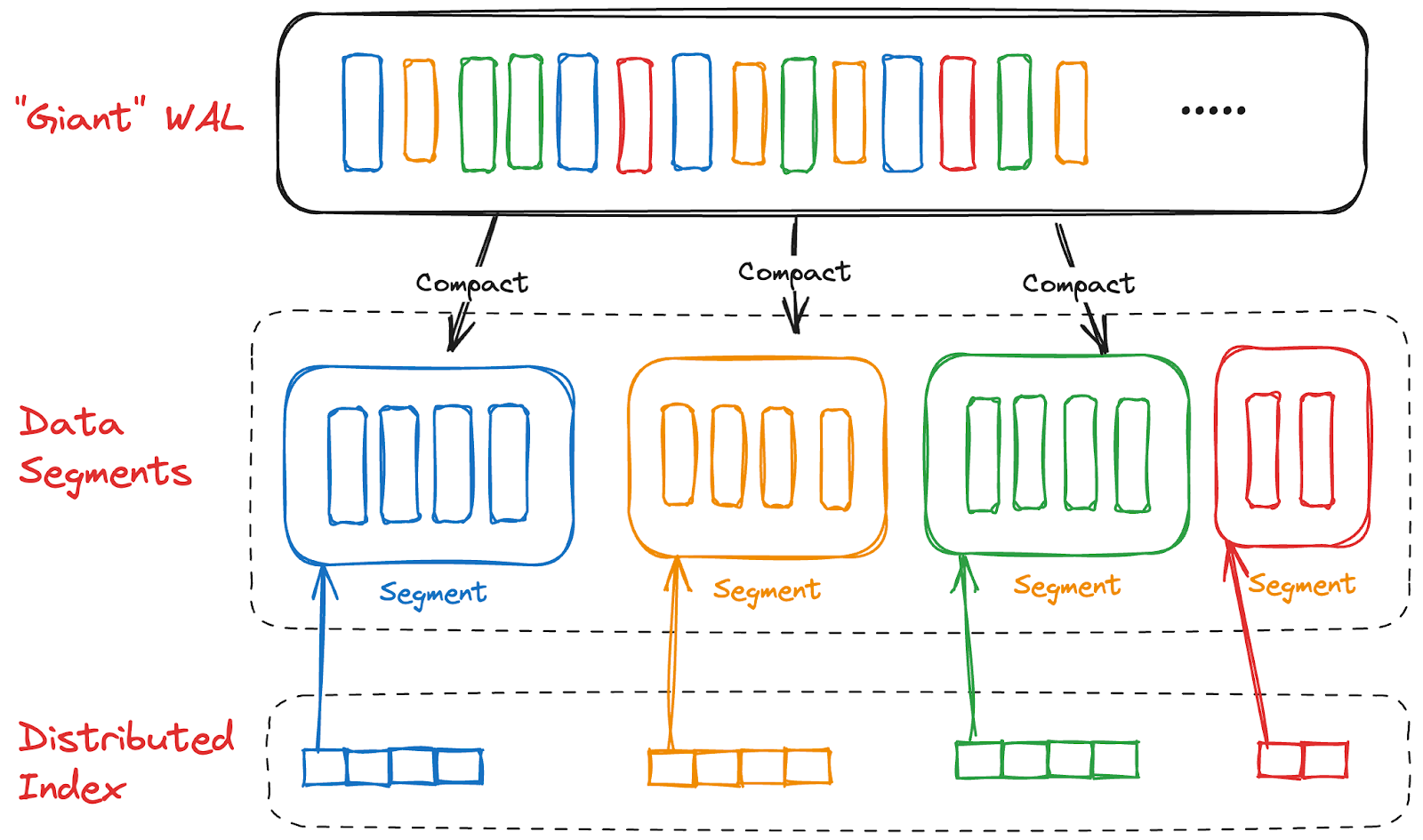
The entire storage engine comprises three logical components:
- Write-Ahead Log (WAL): A giant WAL aggregates data for fast writing.
- Data Segments: Compacted, continuous data blocks designed for quick scans and lookups.
- Distributed Index: An index to locate and read the data segments.
Originally, Pulsar used BookKeeper for low-latency log storage, utilizing inter-node (inter-AZ, in the context of the cloud) data replication for high availability and reliability. In this setup, BookKeeper stores both the giant write-ahead log and the data segments. At the same time, BookKeeper and ZooKeeper manage the distributed index—the latter indexing the segments and the former indexing the data within those segments.
Now, with all these logical components in place, a natural way to reduce costs is data tiering by relocating those data segments from BookKeeper to Object Storage. This led to the introduction of tiered storage, a concept now widely adopted by many vendors. It has become a must-have feature for any data streaming platform.
Lakehouse Tables: Turning Streams Outside-In
But do we really need data tiering here? Implementing tiered storage often creates another layer of data gravity around the data streaming platform, as almost all tiered storage implementations use their own proprietary formats. This means the only way to retrieve the data is through the data stream API, whether Kafka or Pulsar. This does not align with our vision of enabling data sharing.
More importantly, the rationale behind generating data segments is not “data tiering.” The data is already appended to this giant WAL for durability. Data Segments are continuous blocks compacted from the giant WAL and designed for fast scans and lookups. What if we leverage the schema information already present in the data streams and convert the row-based data written in the giant WAL into columnar data formats, making the streams available as tables in the lakehouse? This process of data compaction is actually turning the streams outside-in into tables. This is the logic and principle behind the “Lakehouse Tiered Storage” concept, presented at the Pulsar Summit in 2022 and 2023. It is now called “Lakehouse Storage'' in the Ursa engine, and we have removed “tiered” because there is no actual “data tiering” involved.
With this storage model, we can convert and materialize the WAL data into any format we want to support as part of the compaction process. This approach takes our vision of enabling data sharing to an extreme, allowing us to break the wall between the transactional & operational realm and the analytical realm, share the same copy of data across different use cases, and meet diverse business requirements.
Latency and Cloud Economics
This brings us to the last two components of the entire storage engine: the write-ahead log (WAL) and the distributed index. We don’t believe that one model fits all. We operate in hybrid and complex environments: some companies move to the cloud while others revert; some people require ultra-low, single-digit millisecond latency, while others need solutions that align with cloud economics. We believe in understanding trade-offs, so we introduced the concept of the New CAP theorem to explain the necessary compromises when selecting technology.
These trade-offs can be transformed into options that help enterprises find the right balance. This is the idea behind introducing a cost-optimized WAL while keeping BookKeeper as a latency-optimized WAL. Users can choose the best option based on the latency profiles of their workloads.
- Suppose your workload demands ultra-low latency, or you operate in an environment without cloud economic concerns around inter-AZ traffic (e.g., on-premise, private cloud, or certain public cloud environments). In that case, you can continue to use BookKeeper as your storage engine. That remains our secret sauce.
- Alternatively, suppose your workload can tolerate higher latency, or you prefer to prioritize cost over latency. In that case, you can use a cost-optimized WAL implementation, which will soon be generally available (GA).
- Furthermore, suppose you wish to make your transactional data available for analytical purposes. In that case, you can flip a switch to convert your data streams into lakehouse tables or vice versa.
Linking this back to a multi-tenancy model, there is no need to set up separate clusters for low-latency and high-throughput workloads. Everything can reside in one cluster, configured on a per-tenant basis. This enables effective data sharing across your teams and departments without adding operational burdens.
The Future of Ursa
It has been a long journey to realize our vision of enabling data sharing across various teams, departments, and organizations, culminating in the Ursa engine. We believe that a data streaming platform is fundamentally different from other platforms. The Ursa engine is inherently open and designed to enhance organizational capabilities by facilitating data sharing between services and people. The future of data streaming platforms will be multi-protocol, multi-tenant, and multi-modal, much like Ursa.
If you want to try out the Kafka API capabilities in Ursa, sign up for StreamNative Cloud today. If you want to learn more about the industry's direction, please consider signing up for our upcoming Gigaom webinar. Sign up for our newsletter to stay updated on our products and news.




