In 2013, Jay Kreps wrote a pivotal blog post, "The Log: What Every Software Engineer Should Know About Real-Time Data’s Unifying Abstraction". This post laid the conceptual foundation for Apache Kafka and catalyzed the development of the modern data streaming ecosystem. The core premise was both simple and transformative: the log is the backbone of real-time data streaming architectures, serving as a fundamental abstraction for managing and processing data streams. It simplifies critical concerns like state management, fault tolerance, and scalability.
In the decade since, the landscape has shifted dramatically, especially with the advent of cloud-native environments. The ecosystem has expanded to include a wide array of platforms, such as Apache Pulsar, Redpanda, and other commercial offerings. The rise of S3 as a primary storage layer for data streaming has further reshaped the conversation, with many vendors claiming their solutions are significantly more cost-efficient than self-managed Kafka. As a result, we are navigating a far more complex and diverse environment today.
This blog post explores this evolution by focusing on log storage and how data streaming engines have evolved. We will examine key architectural shifts and analyze the direction the industry is heading in terms of scalability, cost-efficiency, and integration with cloud-native storage technologies.
Let’s start with some basics.
What is a Log?
At the core of any data streaming system lies the concept of a log. A log is an append-only sequence of records that are added in a strict order and never modified. Each record is assigned a unique sequential identifier, usually called an "offset," which allows developers to quickly locate the record within the log.
The ordering of records in a log establishes a notion of "time"—records appended earlier are considered older than those appended later. This sequential identifier can be thought of as a logical "timestamp" for each record. Importantly, this concept of ordering is decoupled from any physical clock, which is critical in distributed systems where consistency and ordering guarantees are paramount.
Each record in the log consists of a payload—typically a bag of bytes. The structure of this payload is determined by a schema, which defines the data format and provides a contract between data producers and consumers for interpreting the data.
In many ways, a log is conceptually similar to both a file in a filesystem and a table in a relational database, though with key differences. A file is an unstructured sequence of bytes without inherent record boundaries, giving applications complete flexibility in interpreting the data. A table, on the other hand, is an array of records that can potentially be updated or overwritten. A log is essentially an append-only version of a table, with records arranged in a strict order. This leads to the principle of table-stream duality, a concept we’ll revisit later.
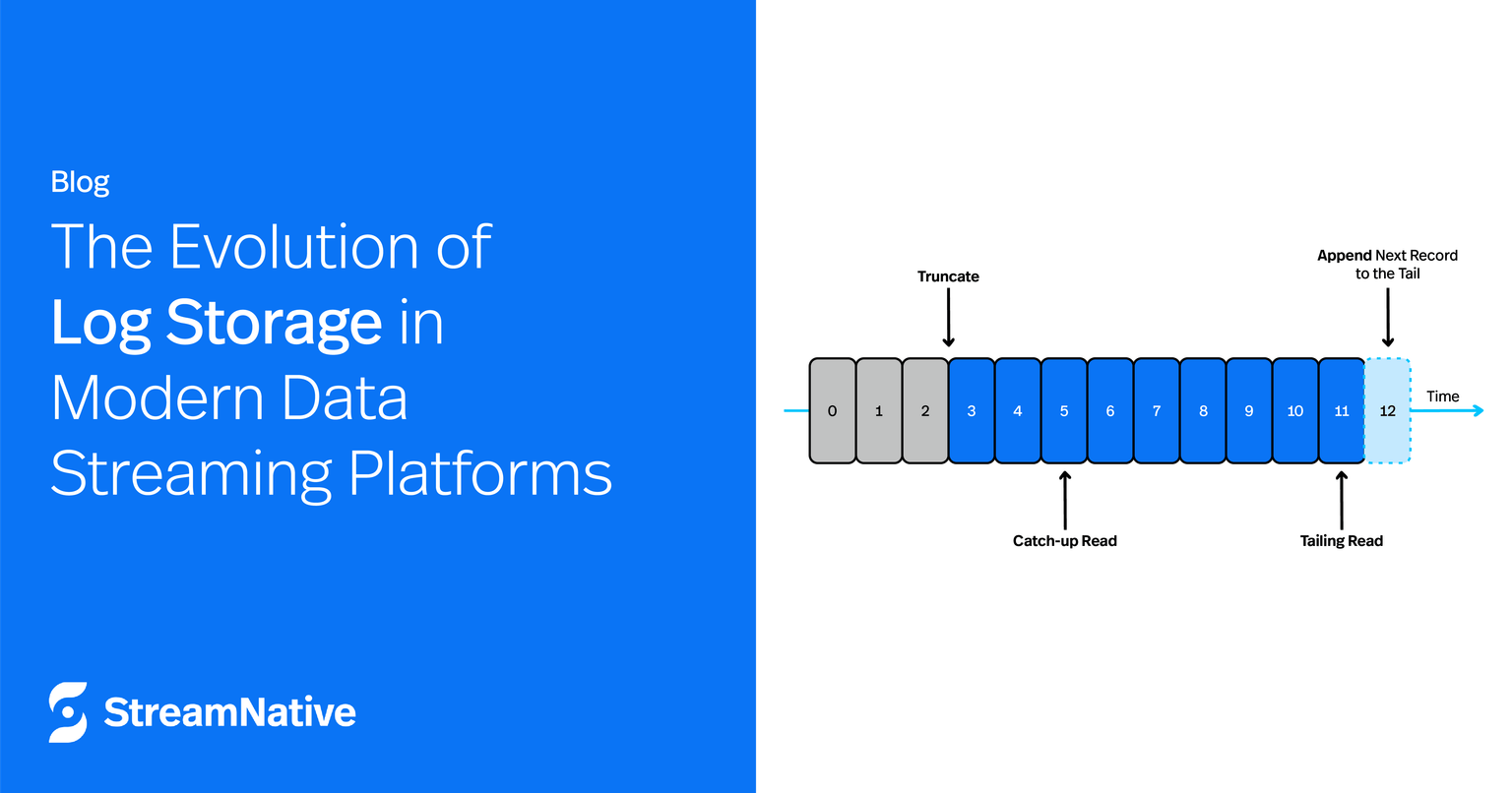
Due to its immutability, operations on a log are simple and predictable:
- Write: Unlike a table, where records can be updated or deleted, a log's records are immutable once appended. The write operation is straightforward—records are appended sequentially to the end of the log. Each append returns a unique sequential identifier, commonly referred to as an offset in Kafka or a message ID in Pulsar.
- Read: While relational databases support point lookups by key or predicate, reading from a log is simpler. Log reads follow a seek-and-scan pattern: consumers specify the offset where they want to start reading, and the system seeks to that offset and scans the records sequentially. Depending on the starting offset, the read can be classified as either:some textTailing Read: The consumer is close to the log’s tail and reads new records as they are appended, keeping up with the producer.
- Catch-up Read: The consumer starts reading from an older offset and processes the backlog of records to eventually catch up to the log’s tail.
In addition to the seek-and-scan behavior, log implementations usually track consumer state, which refers to the offset in the log that the reader has reached. This typically involves tracking offsets for consumer groups, allowing the system to monitor the "lag" between a consumer’s current offset and the tail of the log. Some systems go beyond simple offset tracking—for example, Pulsar provides individual acknowledgments for shared and key-shared subscriptions, allowing fine-grained control over which records have been consumed. This topic is complex and deserves a deeper dive in a future post. For simplicity, we will focus on simple offset tracking in this discussion.
Finally, a log system must manage its size over time. Continuously appending records to the log would eventually exhaust storage, or the older data would become obsolete. To handle this, logs support retention policies, which can be time-based, size-based, or explicitly managed via truncation. A truncate operation is used to reduce the log’s size by discarding old or unneeded records according to the retention rules.
Up to this point, we’ve covered the core fundamental operations that any log system needs to support. To summarize, if you were to build a log system from scratch, you would need to account for the following key concepts:
- Write: Append records to the log and return an offset as a unique sequential identifier.
- Read: Provide an API to seek a specific offset and scan records from that point onward.
- Offset Tracking: Track offsets for each reader to allow resuming from the last position.
- Truncate: Implement a truncate operation to discard older records at a specified offset.
While implementing a system for a single log is straightforward, the real challenge arises in building a platform capable of efficiently managing thousands or even millions of logs concurrently. This need has driven significant innovation in the storage layer of data streaming platforms over the past decade. Let’s explore how modern data streaming systems have evolved to meet these demands.
Apache Kafka: The First Practical Implementation
To create a data streaming platform that manages a large number of logs within a distributed cluster, three key challenges must be addressed:
- Distribution: How can logs be distributed across different nodes within the cluster, so clients know where to append and read records?
- Sequencing: How can writes be sequenced to maintain the order of records within a log?
- Truncation: How can logs be truncated when necessary?
Apache Kafka was the first practical implementation that effectively managed thousands of logs in a distributed cluster setup. Originally developed by engineers at LinkedIn, Kafka centers around the log concept as its primary architectural construct. In Kafka, topics represent logs that are partitioned for scalability and distributed across brokers for load balancing and fault tolerance. Let’s break down Kafka’s implementation.
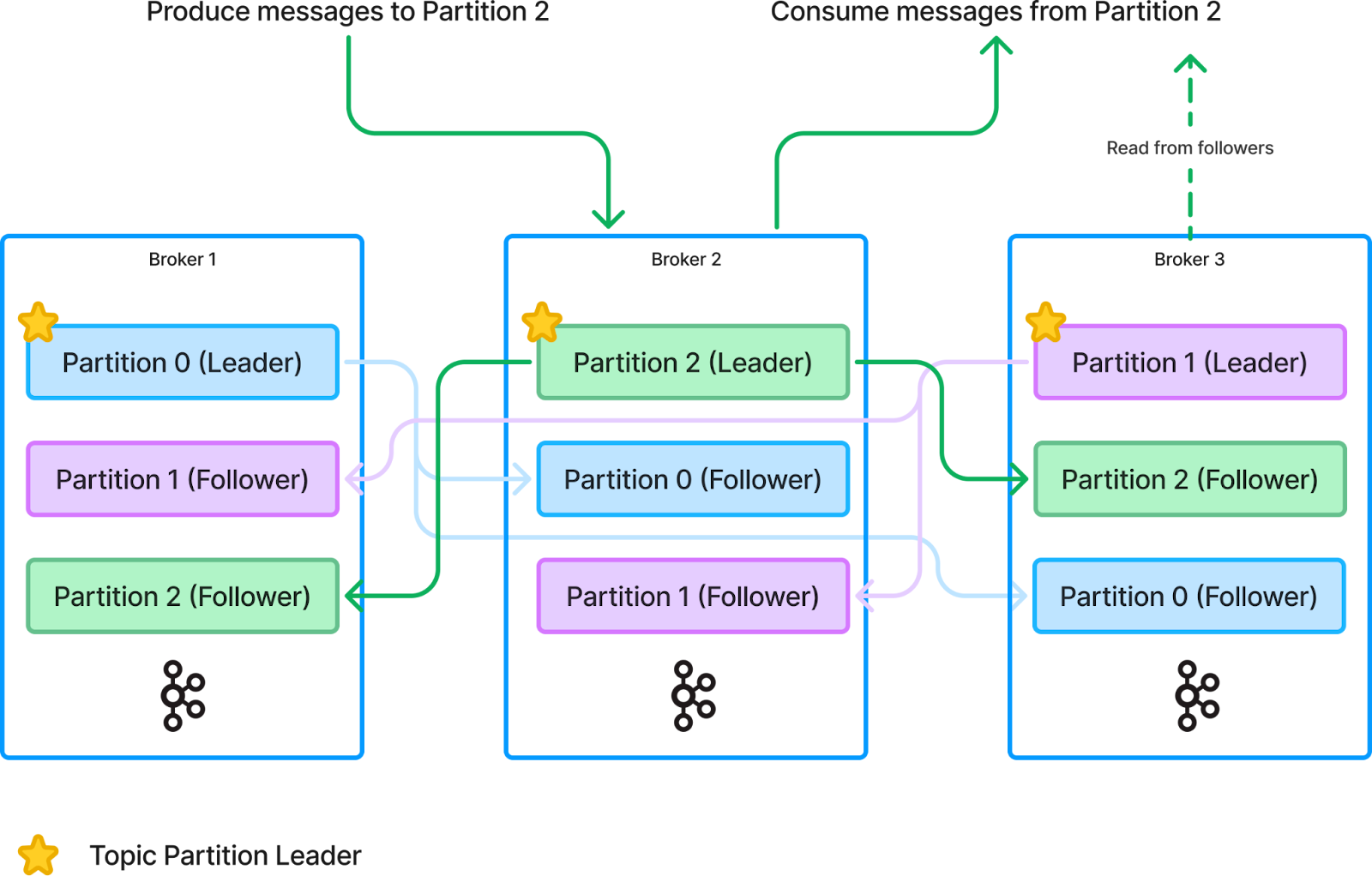
- Partitions: Each topic in Kafka is divided into partitions, with each partition serving as a log that represents a totally ordered sequence of messages (or records). This design allows Kafka to scale horizontally by distributing partitions across multiple brokers.
- Offsets: Every record within a partition is assigned a unique offset that acts as an identifier. This enables consumers to track their progress through the log without impacting ordering guarantees.
- Replication: Kafka ensures durability and fault tolerance through replication. Each partition has a configurable number of replicas, with one designated as the leader. The leader handles all reads and writes, while the other replicas, known as followers, replicate data from the leader. If the leader fails, one of the followers is promoted to leader, ensuring high availability.
- Log Segments: A partition in Kafka is not a single large file but is divided into smaller segments. Each segment is a file on disk, and Kafka retains only a portion of the log in memory for performance. Older segments are periodically flushed to disk, and retention policies—either time-based or size-based—determine how long data is kept.
- Data Retention: Kafka supports both time-based and size-based retention policies. After reaching a specified threshold, older data may be deleted or compacted. The log compaction feature allows Kafka to retain the most recent state of a key, making it suitable for use cases like event sourcing.
Now, let’s examine how Kafka addresses the challenges outlined earlier:
- Distribution: Kafka distributes partitions across brokers, with each partition owned by a set of brokers consisting of a leader and its followers. This ownership information is stored in a centralized metadata store, initially implemented with ZooKeeper and now replaced with KRaft-based coordinators. Locating the log involves querying the metadata storage to find the topic owner. Once identified, all writes are sequenced by the leader broker, while reads can be served by either the leader or the followers. Kafka brokers maintain local indexes to enable consumers to seek to a given offset, effectively locating the corresponding log segment file on local disks.
- Sequencing: The leader broker is responsible for sequencing writes, ensuring the order of records within the log is preserved.
- Truncation: Log truncation is managed via time-based or size-based retention policies. Since data is organized into log segment files, outdated log segments can be deleted according to these retention rules.
To summarize, Kafka’s implementation showcases several key highlights that influence how a data streaming platform manages its log storage layer:
- Partition-centric: Kafka employs a partition-centric approach, where partition locations are maintained in a centralized metadata store or determined through distribution algorithms. Once a partition is located, all operations are performed by the nodes storing and serving that partition. Local offset-based indexes facilitate effective seeking.
- Leader-based: The system relies on a leader-based and replication-based approach. The leader is responsible for storing and serving logs, sequencing writes, and ensuring the log's ordering properties.
- Replication-based: Fault tolerance is achieved via a disk-based replication algorithm from the leader to followers.
The partition-centric, leader-based, and replication-based approach is a common implementation for the storage layer of most Kafka or Kafka-like data streaming platforms. Systems like Redpanda and AutoMQ also adopt this model. For example, Redpanda re-implements Kafka using C++, with the primary difference being its use of the Raft consensus algorithm for replication instead of Kafka's in-sync replica (ISR) mechanism. Despite this change, Redpanda’s architecture remains largely partition-centric and leader-based.
While this relatively straightforward approach worked well in a monolithic architecture, it is not well suited for the cloud-native world. As autoscaling becomes the norm, data partition rebalancing during scaling becomes a significant challenge. Scaling, which ideally should be automated and seamless, often requires intervention from SREs, risking uptime and impacting error budgets. We have explored these challenges in previous blog posts.
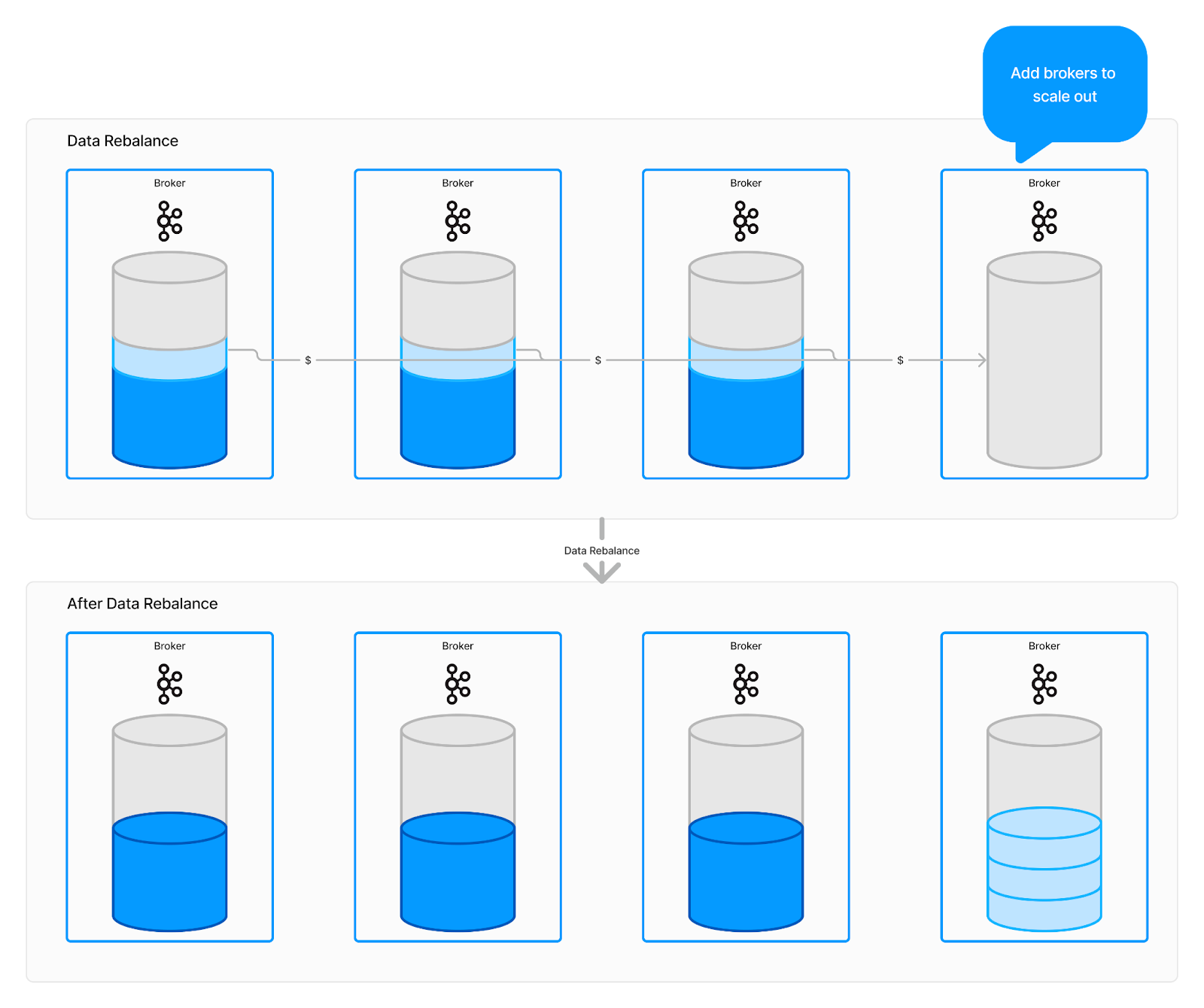
Apache Pulsar: Address Data Rebalancing Challenges via Separation of Compute and Storage
Unlike other Kafka alternatives, Apache Pulsar, initially developed by Yahoo!, employs a distinct strategy to address the challenges of scaling and operational complexity. To mitigate the issues arising from the coupling of data storage and serving, Pulsar separates its storage layer from the brokers, which are designed solely for serving requests. This separation shifts the storage model from a partition-centric approach to a segment-centric one.
In this new storage model:
- Logical Partitions: Partitions in Pulsar are treated as logical entities. Brokers manage the ownership of topic partitions but do not store any data locally. Instead, all data is stored in a remote segment storage system called Apache BookKeeper.
- Distributed Segments: Data segments are distributed across multiple storage nodes (or "bookies") and are not tied to a specific broker, allowing for greater flexibility and scalability beyond the limitations of physical disk capacity.
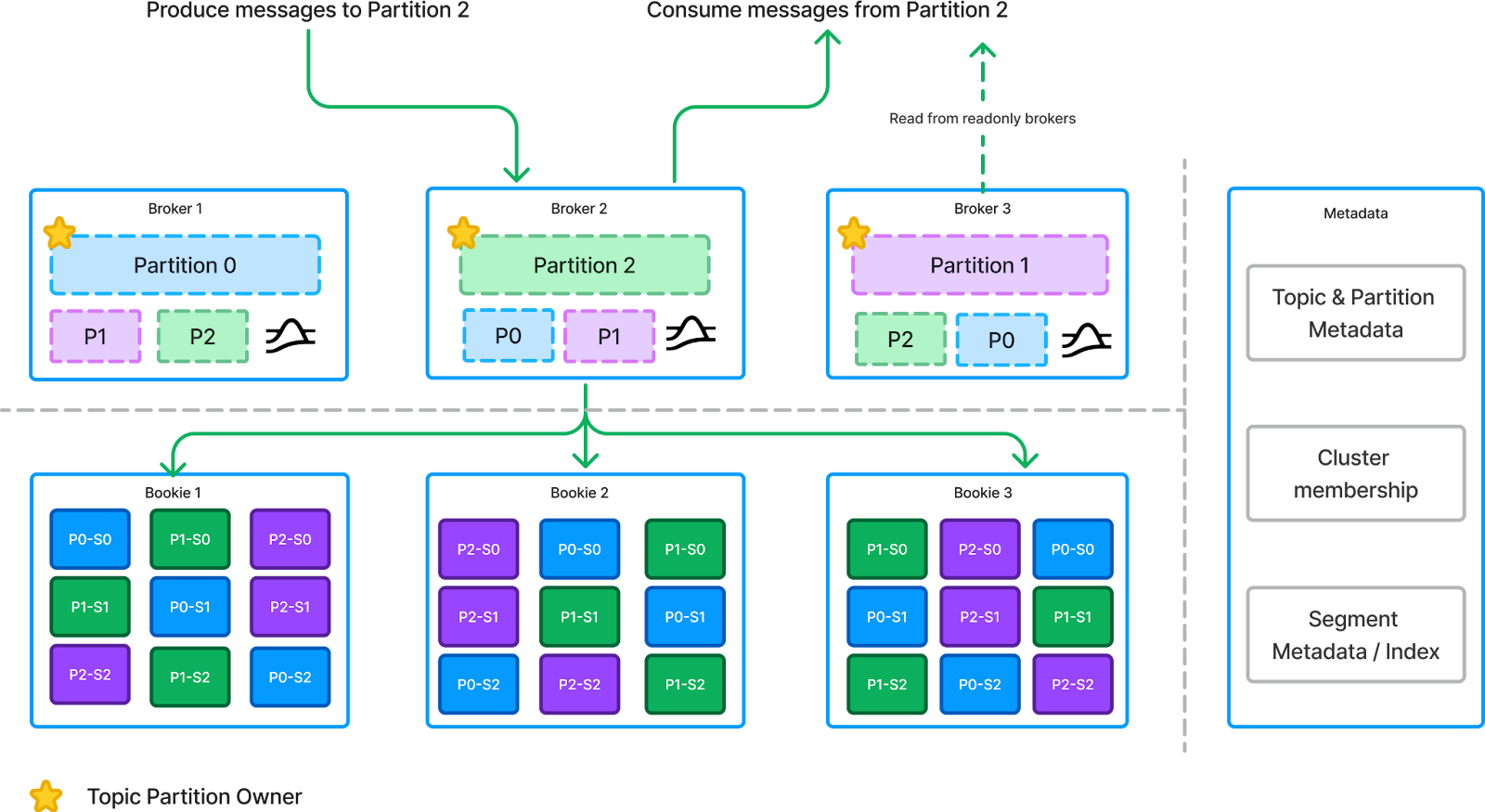
Now, let’s explore how Pulsar effectively addresses the previously outlined challenges:
- Distribution: Pulsar’s architecture features two layers of distribution:some textFirst, while partitions are still distributed across brokers, the partitions now become logical partitions, which are not bound to physical brokers, unlike in Kafka. Brokers manage the ownership of these logical partitions, with ownership information stored in a centralized metadata store. Unlike Apache Kafka, Pulsar organizes topics into namespace bundles to leverage its multi-tenancy capabilities, assigning these bundles to brokers for efficient resource management.
- Second, data segments are distributed across multiple bookies, ensuring redundancy and fault tolerance. Locating a partition involves querying the metadata store to identify the topic owner. Once identified, all write operations are sequenced by the owner broker, while read requests can be fulfilled by either the owner broker or designated read-only brokers. Pulsar brokers utilize metadata about log segments to pinpoint the appropriate storage node for reading data. Sequencing: The owner broker is tasked with sequencing writes, ensuring that the order of records within each log is maintained. This is crucial for applications that rely on ordered event processing.Truncation: Log truncation in Pulsar is managed through time-based or size-based retention policies, as well as explicit truncation after all data has been acknowledged by all subscriptions. Since data is organized into log segments, acknowledged and expired segments can be safely deleted according to these retention rules. In summary, while Apache Pulsar continues to employ a leader-based and replication-based approach, it shifts from a partition-centric model to a segment-centric architecture, effectively decoupling the storage layer from the serving layer. I refer to this as a "Giant Write-Ahead Log" approach in the "Stream-Table Duality" blog post.
Tiered Storage - A Must Have
In this new storage model, where topic partitions are treated as logical and virtual entities, the introduction of a distributed segment storage architecture provides an effective abstraction for log segments. These log segments can be stored in a low-latency, disk-based replication system like Apache BookKeeper or as objects in object storage solutions such as S3, Google Cloud Storage, or Azure Blob Storage. This distributed segment storage abstraction introduces the concept of tiered storage into the data streaming landscape, making it a must-have feature for modern data streaming platforms.
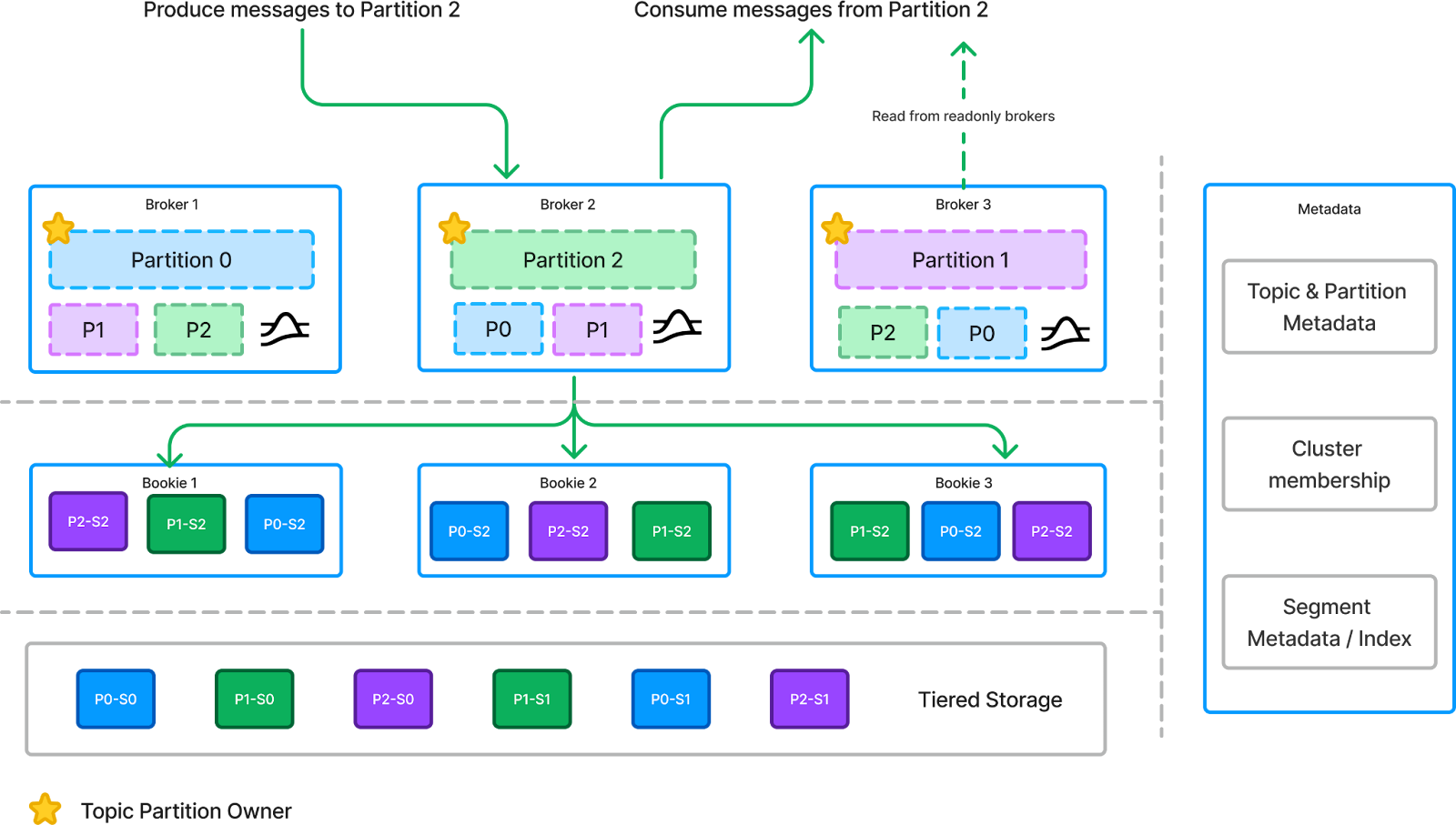
However, not all tiered storage implementations are created equal. Most Kafka-based tiered storage solutions focus on moving log segments to tiered storage while still maintaining local indexes within brokers for locating those segments. While this approach may reduce the impact of data rebalancing, it does not eliminate the need for it. During scaling operations, the system must move both the local indexes and any log segments that have not yet been offloaded to different brokers.
In contrast, Pulsar stores the indexes of log segments in a centralized metadata store, allowing log segments to remain completely remote and decoupled from the brokers. Consequently, during scaling operations, there is no need to rebalance either the log segments or their indexes. We refer to this important concept as the "index/data split" or "metadata/data split," which will ultimately set the stage for the future evolution of the storage layer in data streaming. I will explain it further in the following paragraphs.
From Leader-Based to Leaderless: Addressing Cost Challenges with S3 as Primary Storage for Data Streaming
2024 is set to be a pivotal year for data streaming as the trend shifts from using object storage as a secondary option through tiered storage to adopting it as the primary storage layer. Notable examples in this trend include WarpStream (acquired by Confluent), Confluent's Freight Clusters, and StreamNative's Ursa engine, all leveraging S3 as their main storage solution.
Cost is the key driving force behind this transition. Leveraging S3 as primary storage allows organizations to use it not only as a storage medium but also as a replication layer. By relying on S3, organizations can eliminate traditional disk-based replication solutions, which typically involved managing replicas across brokers or storage nodes, requiring extensive cross-availability zone network traffic and complex coordination to ensure data redundancy and availability. This approach significantly reduces the costs of operating a data streaming platform on public cloud infrastructures. Many organizations adopting S3 as their primary storage claim to be 10x cheaper than self-managed Kafka, primarily due to reduced networking costs.
Beyond cost savings, this object-storage-based approach also represents a significant architectural shift from a leader-based to a leaderless approach in data streaming. In this approach, brokers create batches of produce requests and write them directly to object storage before acknowledging them to clients. The leaderless approach allows any broker to handle produce or fetch requests for any partition, improving availability by eliminating a single point of failure. However, these savings come with trade-offs: produce requests must wait for acknowledgments from object storage, introducing latency, although this is potentially offset by cost reductions of up to 90%.
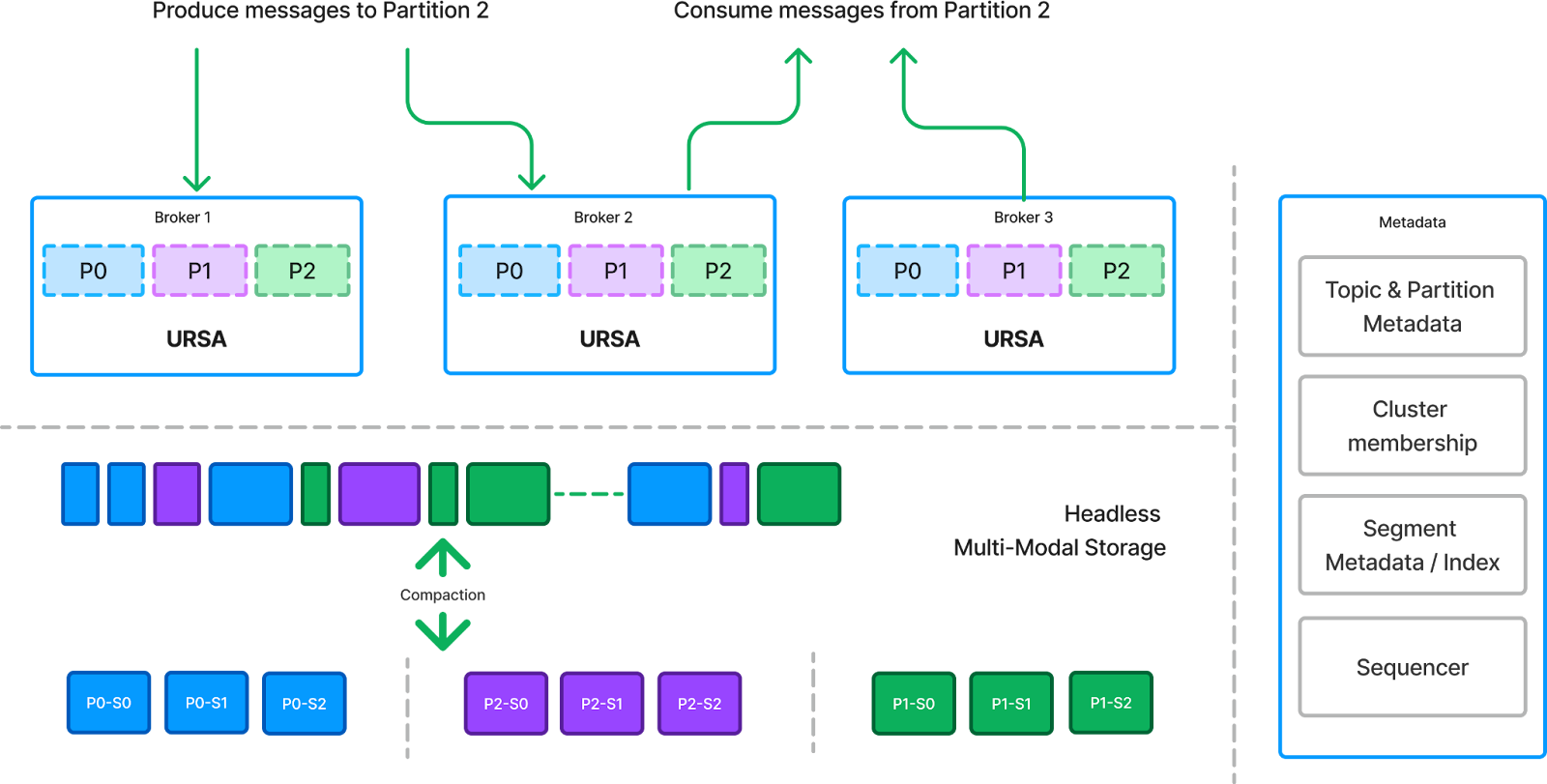
This trade-off explains why Confluent offers a separate cluster type known as "Freight Clusters," while StreamNative provides configurable storage classes as part of tenant and namespace policies. Not all applications can tolerate higher latency, particularly those handling mission-critical transactional workloads.
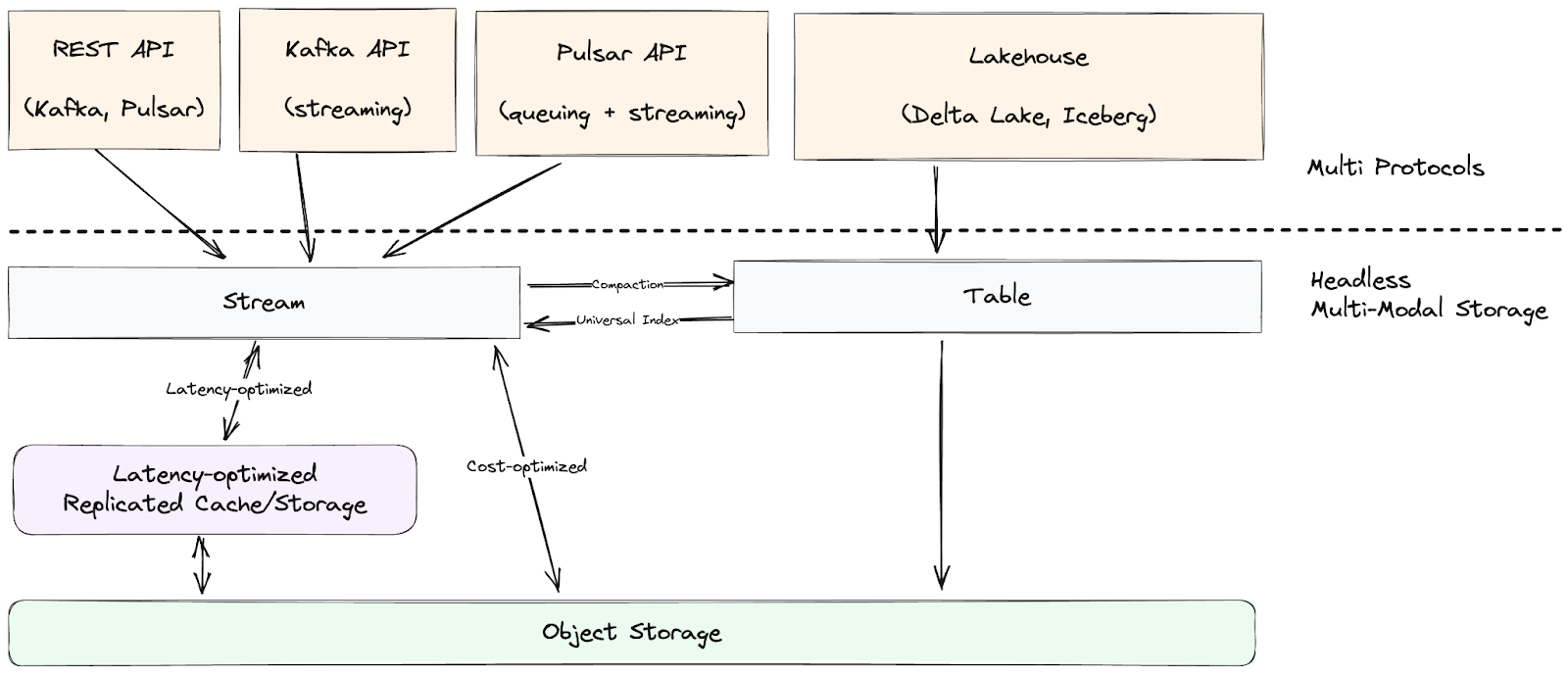
Transitioning to a leaderless, object-storage-based architecture marks a significant step forward in aligning data streaming with the data lakehouse paradigm, where object storage serves as the headless storage layer for both streaming and batch data. This headless storage layer stores data independently of any specific compute nodes or services, providing greater flexibility in accessing and processing data without dependency on a particular storage server or broker. The key to this architectural shift is taking the index/data split concept a step further by moving all metadata and index information for both partitions and log segments, as well as the sequencing work, to a centralized metadata store. This enables all brokers to efficiently access the information needed to locate partitions and log segments and generate sequences in a decentralized manner.
Now, let’s examine how a leaderless data streaming platform effectively addresses the previously outlined challenges:
- Distribution: With the index/data split, all metadata (index) is stored in a centralized metadata store, allowing any broker to access the necessary information to locate partitions and their corresponding log segments. This enables any broker to serve write and read requests efficiently.
- Sequencing: In the absence of a leader broker, sequencing tasks are managed in the metadata layer. Brokers accepting write requests commit their writes to the metadata storage, which then generates the sequences for those writes to determine the order. This approach is not entirely new; it has been utilized for many years, as introduced by Facebook/Meta’s LogDevice. For a deeper comparison, check out a blog post by Pulsar PMC member Ivan Kelly, which contrasts Apache Pulsar with LogDevice.
- Truncation: With all metadata/index managed in a centralized location, truncating logs becomes straightforward. Truncating a log is as simple as removing indices from files in the centralized metadata storage.
The index/data split, which has been a foundational element of Pulsar since its inception, underpins this latest evolution in the data streaming landscape. This concept facilitates a seamless transition from a leader-based to a leaderless architecture—an evolution likely to be embraced by all data streaming vendors.
The Index/Data Split, Multi-Modality, and Stream-Table Duality
In addition to S3 reshaping the design of storage layers for distributed data infrastructures, several other paradigm shifts are influencing the broader data landscape. One such shift is the notion that "batch is a special case of streaming". Coined nearly a decade ago, this idea has faced practical implementation challenges. Over the years, various efforts have aimed to consolidate batch and stream processing across different layers. Notably, Apache Beam introduced a unified model and set of APIs for both batch and streaming data processing. Additionally, frameworks like Spark and Flink have sought to integrate these processing paradigms within the same runtime and engine. However, because these efforts primarily occur above the data storage layer, they often lead to some form of Lambda architecture.
The concept that unbounded data encompasses bounded data, where both batch and streaming jobs have windows (with batch jobs having a global window), makes logical sense but has proven difficult to execute—especially when historical sources and real-time streaming sources originate from different systems. With the emergence of S3 as the primary storage for data streaming, along with the index/data split, achieving stream-table duality and supporting multi-modality over the same set of physical data files is now possible. Confluent's Tableflow and StreamNative's Ursa engine are moving forward in this direction.
Returning to the initial discussion, it's important to recognize that a stream is fundamentally similar to an append-only table. A lakehouse table is essentially a collection of Parquet files. These Parquet files can be indexed by a Write-Ahead Log (WAL) in Delta Lake, manifest files in Apache Iceberg, or a timeline in Apache Hudi. In essence, lakehouse tables are composed of a set of files (representing the data) and an index (representing the metadata), encapsulating the concept of the index/data split discussed in data streaming (see the diagram below).
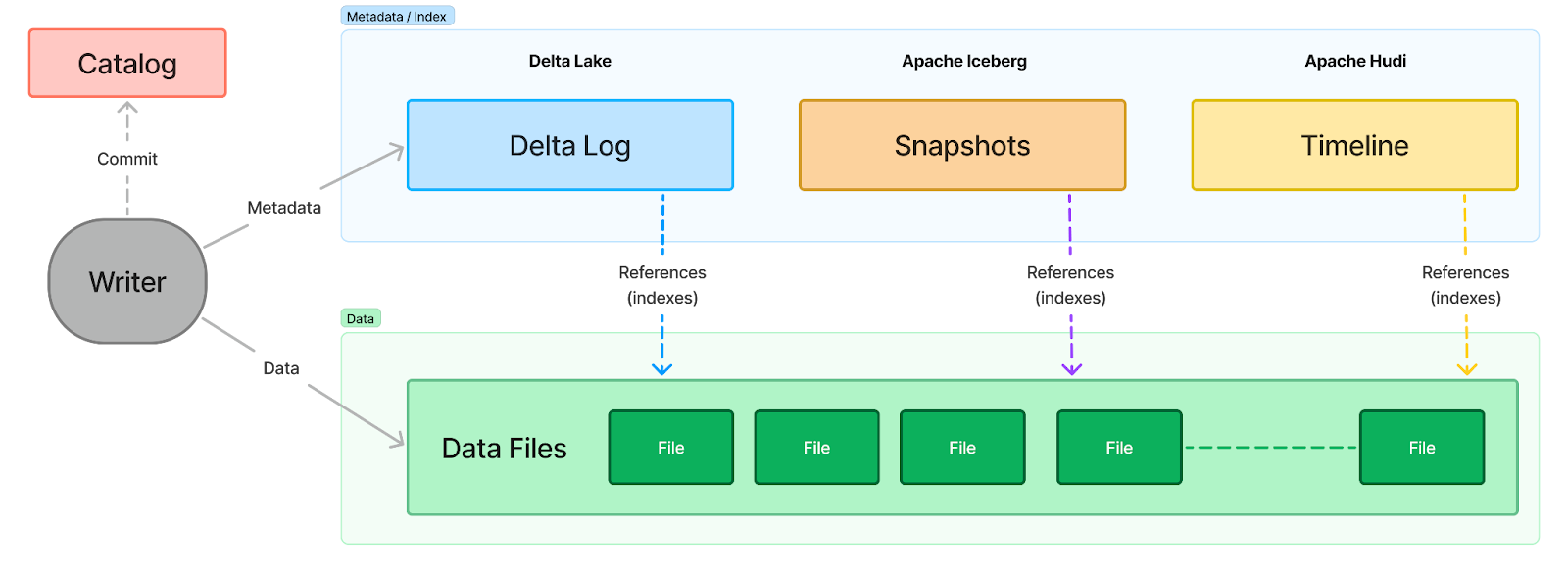
With S3 as the primary storage in the data streaming space, a stream can be seen as equivalent to a table in a lakehouse. A stream consists of a collection of data files (appended in row formats and compacted into columnar table formats) indexed by "time" (sequential numbers generated by the streaming system). This structure supports append-only write operations, seek-and-scan read operations, and offers either time-based or size-based retention policies for removing outdated data.
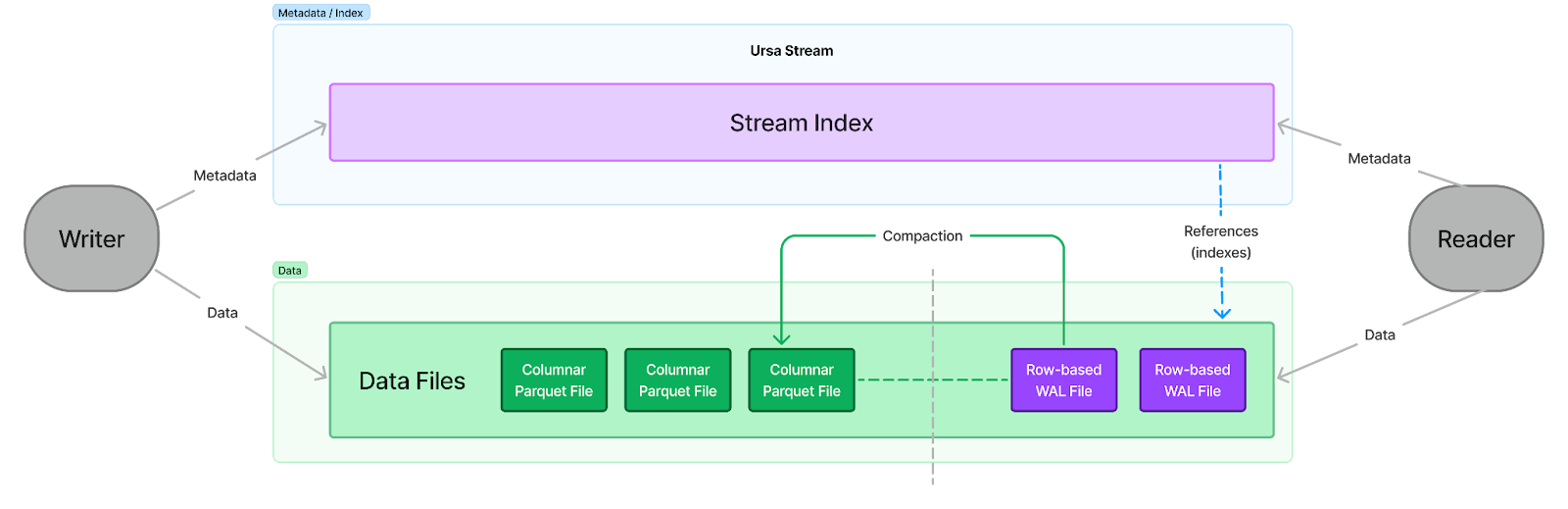
We have now reached a point where we can maintain a single physical copy of data (stored as either row-based WAL files or columnar Parquet files) while providing different indexes for streaming and tabular access. This construct is referred to as "Headless Multi-Modal Storage", a key aspect of the "Streaming-Augmented Lakehouse" concept. Data streamed into this storage is appended to WAL files, compacted into Parquet files, and organized as lakehouse tables—eliminating the need for separate copies of the data. Changes made to lakehouse tables can be indexed as streams and consumed through Kafka or Pulsar protocols.
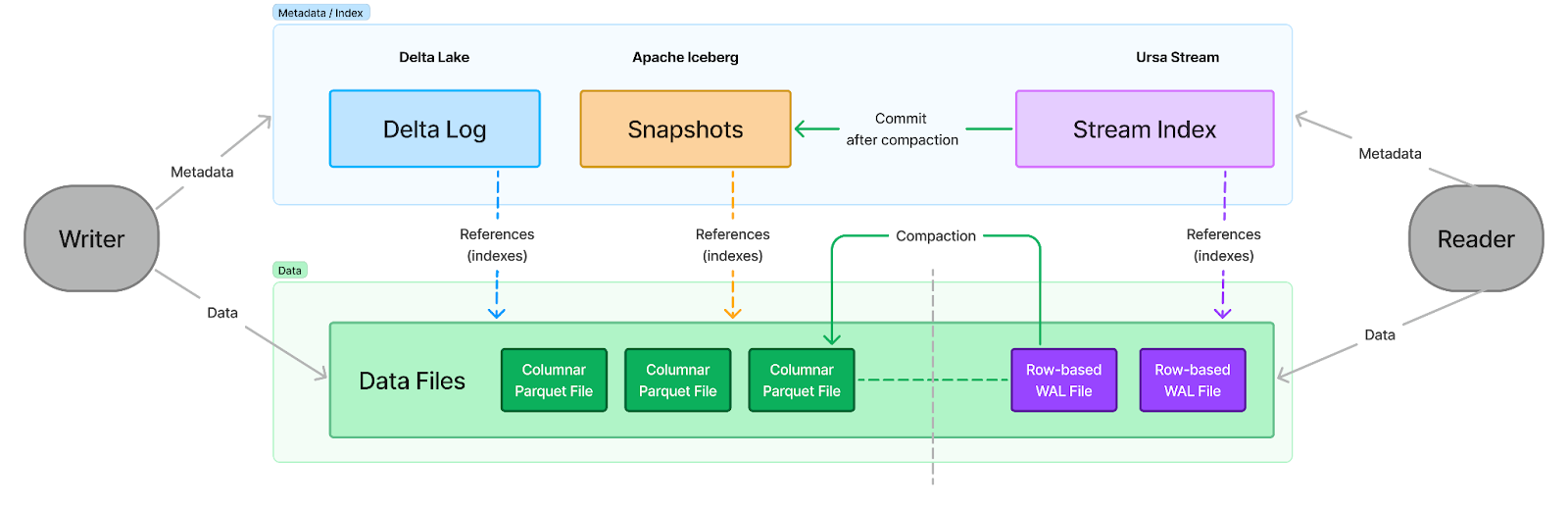
By building multiple modalities (stream or table) over the same data, the system becomes headless, enabling various processing semantics. Data can be processed as continuous streams using engines like Flink or RisingWave or as cost-effective tables with batch query engines like Databricks or Trino. This architecture seamlessly integrates real-time streams and historical tables, providing the flexibility to use the right processing tool for each specific use case.
Final Thoughts
The evolution of log storage has been pivotal in shaping the modern data streaming ecosystem. Over the past decade, we have seen a transformation from partition-centric, leader-based models like Apache Kafka to more flexible, segment-centric architectures such as Apache Pulsar. The adoption of S3 and other cloud-native object storage as a primary storage layer marks a significant shift, driving cost-efficiency and simplifying operations by eliminating traditional disk-based replication. This has enabled a transition towards leaderless, headless architectures that align more closely with the data lakehouse paradigm.
As we move into the age of AI, these advancements are accelerating. The convergence of data streaming and lakehouse technologies has led to headless, multi-modal data storage solutions that seamlessly integrate streaming and batch data, creating a robust foundation for real-time generative AI. Lakehouse vendors are beginning to adopt streaming APIs for real-time ingestion, while streaming platforms are incorporating lakehouse formats to provide more versatile data processing capabilities.
The evolution of data streaming storage is ongoing, and headless, multi-modal architectures are emerging as the backbone for real-time generative AI. We look forward to discussing these topics further at the upcoming Data Streaming Summit, taking place at the Grand Hyatt SFO on October 28-29, 2024. We invite you to join us for this exciting event focused on the future of data streaming.




