
Since the launch of the StreamNative Kafka Service on April 7, 2026, we've continued to rapidly expand the capabilities of our cloud-native Kafka offering powered by StreamNative Ursa (UFK).
Our vision remains the same: deliver Kafka streaming without Kafka operational complexity --- powered by a modern lakehouse-native architecture that separates compute and storage while enabling real-time and analytical workloads on a unified platform.
Today, we're excited to announce several major enhancements to the StreamNative Kafka Service portfolio across deployment flexibility, messaging semantics, cloud support, and pricing models.
What's New
1. StreamNative Ursa Now Available on Private Cloud (Private Review)
StreamNative Ursa, the lakehouse-native storage engine behind StreamNative's next-generation streaming architecture, is now available for StreamNative Private Cloud deployments in Private Review for Pulsar Clusters.
This release brings Ursa-powered lakehouse-native architecture to customers running self-managed or highly regulated environments, enabling:
- Separation of compute and storage
- Ursa as a tiered storage extension for Apache Pulsar clusters
- Real-time streaming with queryable open table formats
- Simplified operations for large-scale Pulsar deployments
- Unified streaming and lakehouse-native storage architecture
In addition, Private Cloud deployments can leverage Lakehouse Table capabilities, enabling a zero-ETL integration that automatically converts streaming data from Apache Pulsar topics into open table formats such as Apache Iceberg and Delta Lake, stored directly on object storage including:
- Amazon S3
- Google Cloud Storage
- Microsoft Azure Blob Storage
This allows organizations to unify streaming and analytics access to the same data without building or maintaining separate ETL pipelines, helping simplify modern real-time and AI-ready data architectures.
With Ursa support in Private Cloud, organizations can now standardize on a unified streaming architecture across public cloud, BYOC, and private cloud environments for Pulsar-based workloads.
When it comes to Lakehouse Table capabilities, there is now feature parity between the lakehouse integration capabilities available across StreamNative Cloud and StreamNative Private Cloud, enabling customers to adopt a consistent lakehouse-native streaming architecture across deployment models.
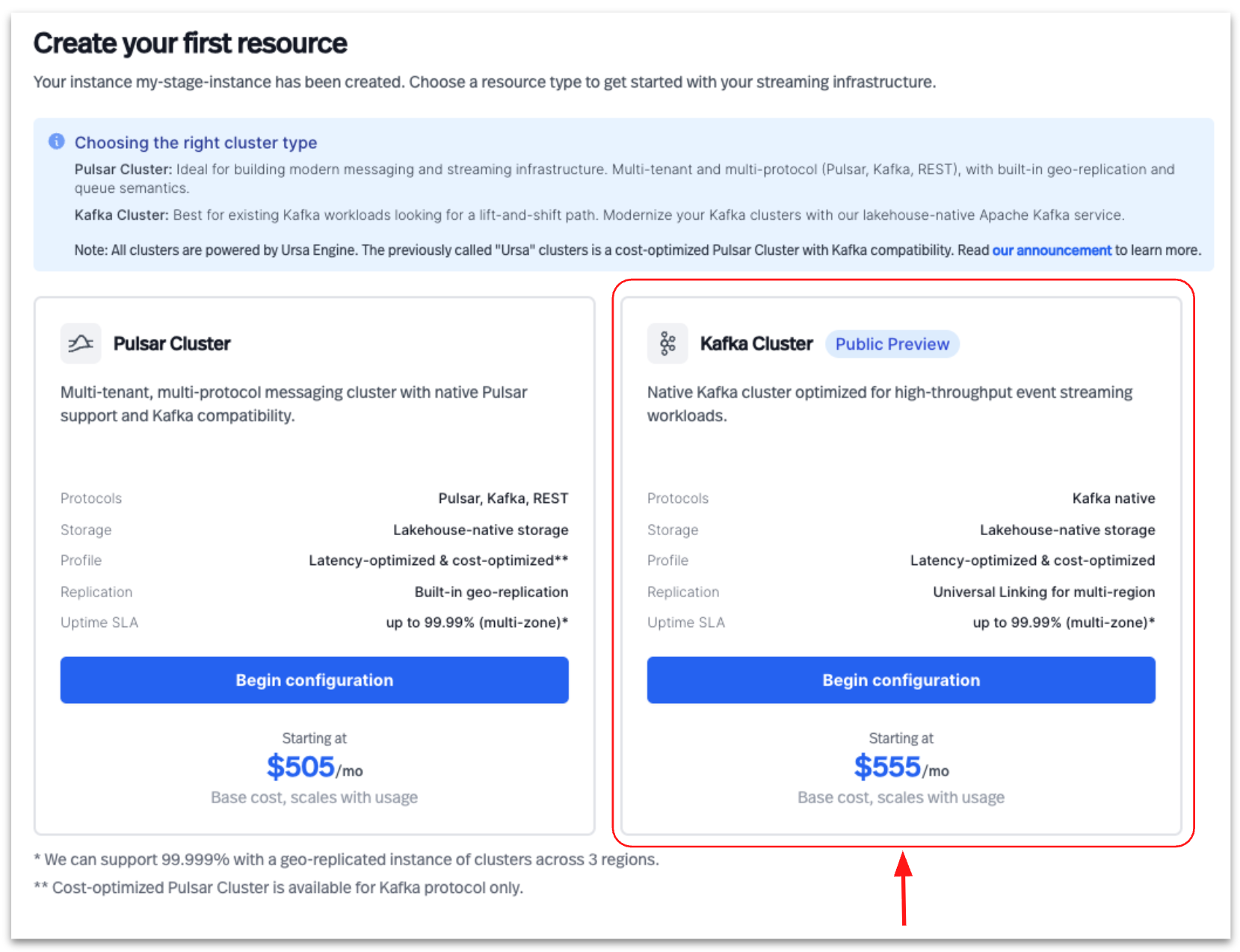
2. StreamNative Kafka Service Now Supported on Azure
At this time, Ursa support in StreamNative Private Cloud is focused on Apache Pulsar protocol workloads and does not yet include support for the StreamNative Kafka Service protocol stack. StreamNative Kafka Service is now available on Microsoft Azure.
With this release, customers can deploy StreamNative Kafka Service across all three major cloud providers:
- Amazon Web Services
- Google Cloud
- Microsoft Azure
Deployment options currently supported include:
- Dedicated Clusters
- Bring Your Own Cloud (BYOC)
Azure support provides customers with greater deployment flexibility and enables organizations to align Kafka infrastructure with existing enterprise cloud strategies.
3. New Storage Pricing for Dedicated Cost-Optimized Clusters
We are also expanding the pricing and deployment model flexibility for StreamNative Kafka Service, particularly for customers adopting the new Cost-Optimized profile powered by StreamNative Ursa.
Dedicated Clusters
StreamNative Kafka Service on Dedicated clusters now supports Reserved Throughput Pricing for Kafka workloads, providing customers with predictable pricing and capacity planning for production-scale streaming deployments.
In addition, customers can now take advantage of differentiated storage architectures across deployment profiles:
| Dedicated Cluster Profile | Storage Architecture | Pricing Focus |
|---|---|---|
| Latency-Optimized | Disk-based persistent storage | Performance optimized |
| Cost-Optimized | Diskless object-storage architecture | Storage cost optimized |
Storage pricing for the Latency-Optimized profile was already available as part of existing Dedicated cluster deployments using persistent disk-based storage infrastructure.
With this release, StreamNative is extending pricing support to the new Cost-Optimized profile, which leverages a diskless architecture backed by object storage. This architecture is designed to significantly reduce infrastructure and storage costs for high-volume Kafka workloads while maintaining Kafka compatibility and long-term data durability.
The Cost-Optimized profile is particularly well-suited for:
- Large-scale retention workloads
- AI-ready streaming data pipelines
- Lakehouse-native streaming architectures
- Analytics-heavy Kafka deployments
- Workloads prioritizing storage efficiency over ultra-low latency
By separating compute and storage and leveraging object storage as the durable persistence layer, organizations can optimize storage economics while continuing to scale Kafka workloads elastically.
To learn more about storage pricing for StreamNative Cloud Dedicated clusters, including Cost-Optimized and Latency-Optimized deployment profiles, please reach out to the StreamNative sales team.
Bring Your Own Cloud (BYOC)
StreamNative Kafka Service on BYOC deployments will use:
- Elastic Throughput Unit pricing
This model allows customers to dynamically scale Kafka throughput within their own cloud accounts while leveraging the operational simplicity of StreamNative Cloud-managed services.
Serverless Availability
StreamNative Kafka Service is not yet available on Serverless deployments. Support for Serverless Kafka is planned for a future release.
Pricing Model Summary
| Deployment Type | Profile Type | Availability | Pricing Model |
|---|---|---|---|
| Dedicated | Latency-Optimized | Available | Reserved Throughput Pricing |
| Dedicated | Cost-Optimized | Available | Reserved Throughput Pricing |
| BYOC | Supported Profiles | Available | Elastic Throughput Unit Pricing |
| Serverless | N/A | Not Available Yet | Coming Soon |
4. Kafka Queues Support in StreamNative Kafka Service
StreamNative Kafka Service now supports Kafka Queues across both:
- Latency-Optimized profiles (disk-based storage)
- Cost-Optimized profiles (diskless storage)
Kafka Queues bring queue-style messaging semantics natively into Kafka using the new Share Groups consumption model introduced in modern Apache Kafka architectures. This enables organizations to combine traditional event streaming and queue-based processing patterns on the same Kafka platform.
Traditional Kafka consumer groups rely on a strict 1:1 mapping between partitions and consumers, which often forces teams to over-partition topics in order to scale workloads during peak demand periods. Kafka Queues remove this limitation by allowing multiple consumers to cooperatively process records from the same partition through shared groups.
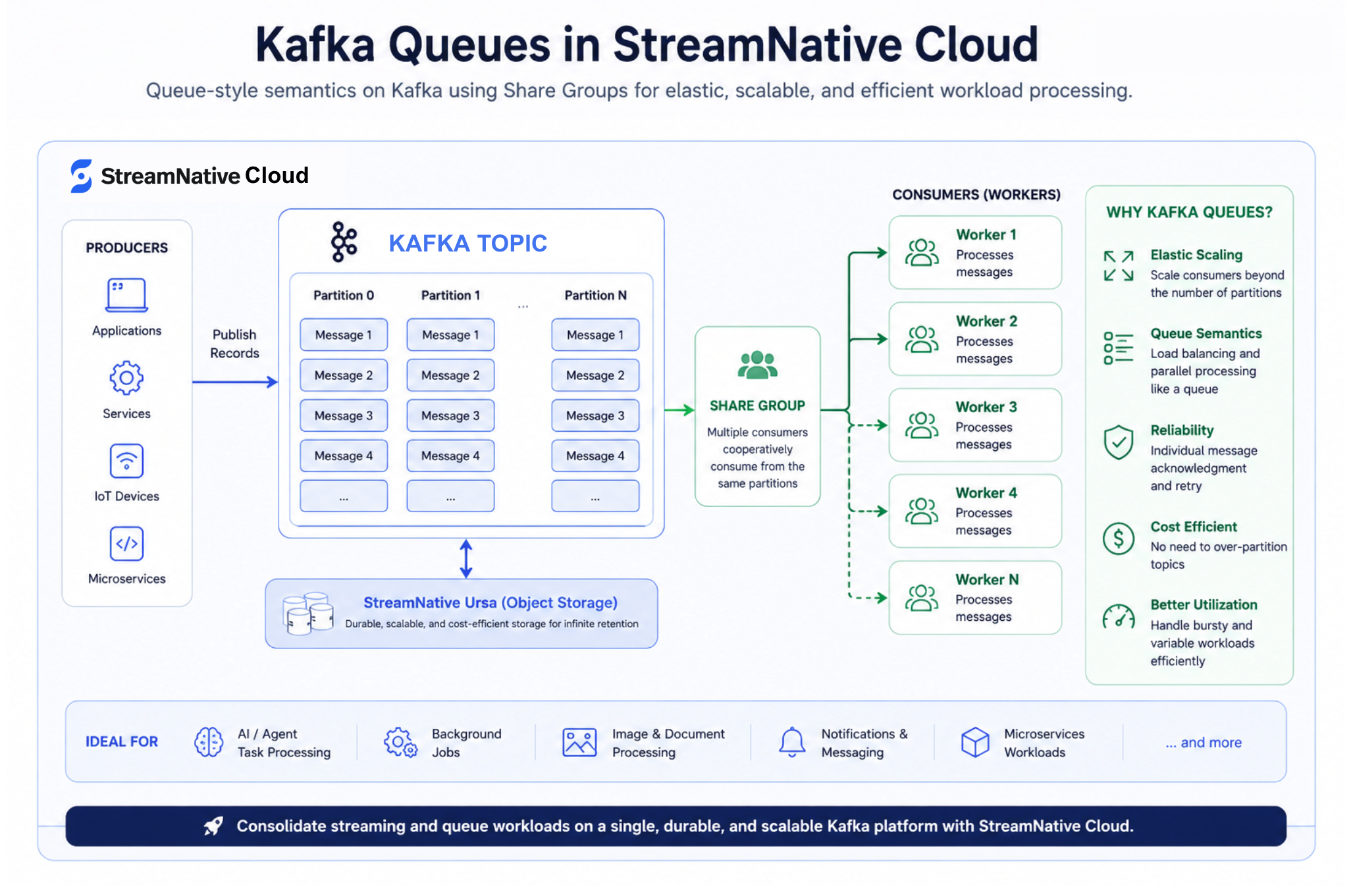
This enables several key capabilities:
- Elastic consumer scaling beyond partition count
- Queue-like task distribution semantics
- Individual message acknowledgment and retry handling
- Improved parallelism for independent workloads
- Reduced need for over-partitioning Kafka topics
- Better handling of bursty and variable-demand workloads
Kafka Queues are particularly well-suited for use cases where throughput and parallel processing are more important than strict ordering guarantees, including:
- AI and agent task orchestration
- Notification and messaging systems
- Image and document processing pipelines
- Job scheduling and asynchronous workers
- Background task execution
- Event-driven microservices
With Kafka Queues, StreamNative Kafka Service allows customers to consolidate streaming and queuing workloads onto a single cloud-native Kafka platform, reducing operational complexity and infrastructure sprawl while still leveraging Kafka durability, scalability, and long-term retention capabilities.
Kafka Queues in StreamNative Kafka Service support both deployment profiles:
| Profile Type | Storage Architecture | Kafka Queues Support |
|---|---|---|
| Latency-Optimized | Disk-based storage | Supported |
| Cost-Optimized | Diskless object-storage architecture | Supported |
This gives organizations the flexibility to choose the right balance of performance and cost efficiency while adopting modern queue semantics in Kafka.
Expanding the Lakestream Vision
It is important to note that Kafka Queues are optimized for independent parallel task processing workloads and may not be ideal for applications requiring strict per-partition ordering guarantees or exactly-once semantics. These enhancements continue to build on the Lakestream vision --- bringing together real-time streaming and lakehouse-native storage into a single unified architecture.
With support for:
- Native Kafka
- Queue semantics
- Multi-cloud deployments
- Private Cloud environments
- Flexible pricing models
StreamNative Kafka Service continues to evolve into a modern streaming platform designed for enterprise-scale real-time and AI-ready data infrastructure.
Whether customers are optimizing for low latency, cost efficiency, operational simplicity, or deployment flexibility, StreamNative Kafka Service provides a cloud-native Kafka experience built for the next generation of streaming applications.




