
Part 2 of 3: Tracing the complete data flow through UFK --- from produce request to queryable Parquet
When a Kafka producer sends a record to UFK, no local disk is written, no follower replication occurs, and within less than a minute that record is queryable as a row in an Iceberg table. Here's exactly how.
This is the second blog post of the Ursa For Kafka (UFK) Deep Dive series. Part 1 covered UFK's storage abstraction, leaderless architecture, and topic profiles. Part 3 will explore stream-table duality.
Introduction
In Part 1, we covered UFK's storage abstraction and leaderless architecture. Now let's trace exactly what happens when data flows through UFK --- from the moment a producer sends a record to the moment it's queryable as a Parquet file.
As we trace the data flow, each step maps to a layer of the Lakestream architecture: the Protocol Layer (the Kafka broker that receives and responds to requests), the Metadata Layer (the Lakestream Catalog, backed by Oxia, which assigns offsets and tracks storage locations), and the Data Layer (object storage where data is durably persisted). Understanding this mapping sets the stage for Part 3's discussion of stream-table duality.
We'll walk through three core mechanisms: the write path (how records get durably stored and indexed), data compaction (how raw WAL data becomes columnar Parquet), and the read path (how consumers retrieve data transparently across storage tiers). Along the way, we'll cover idempotent producers, what stays identical to vanilla Kafka, and the current limitations you need to know about.
The Write Path
In vanilla Kafka, a produce request triggers a synchronous write to the leader's local log, followed by synchronous replication to followers (with acks=all), and finally a high-watermark advance. Each step involves local disk I/O and cross-broker network traffic.
In UFK, the write path for disk-based topics is exactly the same as vanilla Kafka. However, the write path for diskless topics is fundamentally different. There is no local disk write. There is no inter-broker replication. Instead, the entire path is handled asynchronously through Ursa Storage. Let's walk through it step by step.
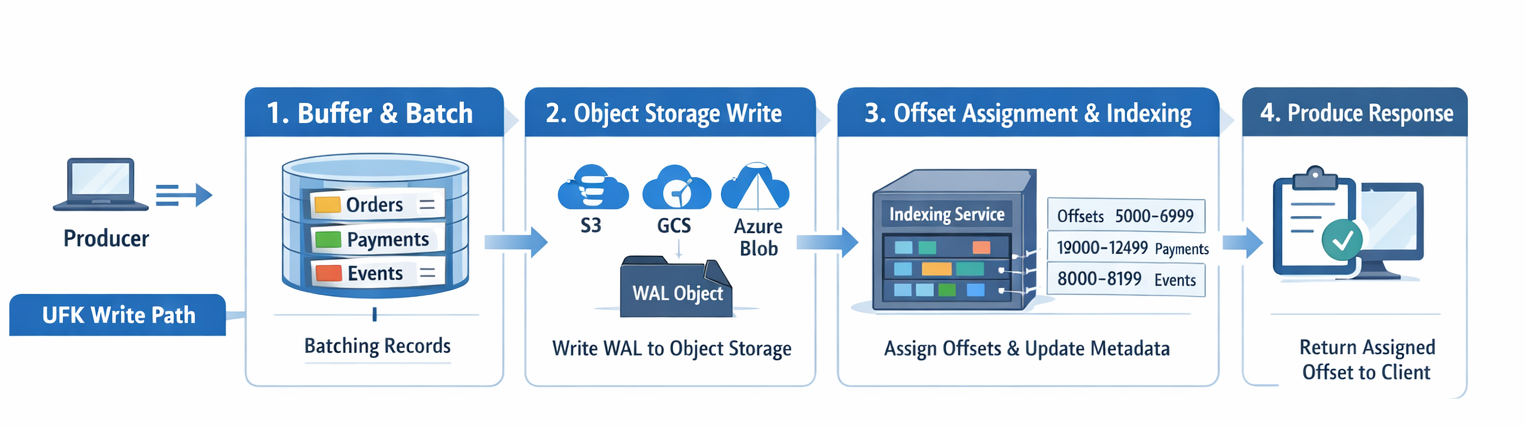
Figure 1. UFK data write flow for diskless topics
Step 1: Buffering and Batching (Protocol Layer)
Records are not written to object storage one by one. The broker accumulates incoming records in an in-memory buffer. This buffer is flushed when either a configurable size threshold is reached or a time interval elapses (default approximately 250ms). A single WAL (Write-Ahead Log) object may contain data from multiple topics and partitions.
This batching is critical to high throughput. Object storage systems charge per API call and perform best with larger objects. By accumulating records across topics and partitions before flushing, UFK amortizes the per-request overhead of object storage writes into a single efficient operation.
A note on produce latency. The p99 produce latency for diskless (cost-optimized profile) topics is sub-second --- typically 250--500ms, driven by the object storage flush interval. This is higher than disk-based (latency-optimized profile) topics, which deliver single-digit millisecond latency identical to traditional Kafka. This is an inherent trade-off of writing to object storage rather than local disk. Tailing consumers reading from the broker's in-memory cache experience end-to-end latencies on the order of the batching interval plus cache lookup time --- the object storage round-trip is avoided entirely. For latency-sensitive workloads requiring sub-10ms end-to-end latency, use latency-optimized (disk-based) topics in the same UFK cluster --- no separate clusters needed. The ability to run both profiles in a single cluster allows operators to match each topic's storage profile to its latency requirements.
Step 2: Object Storage Write (Data Layer)
When the buffer is flushed, the broker delegates batching to the Ursa Storage within the Data Layer. Ursa storage accumulates concurrent writes and flushes them as a single WAL object to the configured object store --- S3, GCS, or Azure Blob Storage. At this stage, no offsets have been assigned yet. The data is stored first; metadata comes after.
Object storage provides built-in durability across multiple availability zones. S3, for example, offers 99.999999999% (eleven nines) durability. This single write to object storage replaces Kafka's two-phase process of writing to the leader's local log and then replicating to followers. UFK eliminates cross-AZ replication traffic entirely --- the object store handles multi-AZ redundancy natively.
Step 3: Offset Assignment and Metadata Indexing (Metadata Layer --- Lakestream Catalog)
After the WAL object is persisted in object storage, the broker writes entry index metadata to the Lakestream Catalog (backed by Oxia). The Lakestream Catalog atomically assigns monotonically increasing offsets as part of the metadata write. This means offset assignment and index creation happen in a single atomic operation. A mixed WAL object containing data from multiple partitions results in multiple independent Oxia metadata updates, one per partition.
The entry index maps an offset range to the WAL object's physical location, along with the message count, entry size, and cumulative size. Because the catalog guarantees atomicity, multiple brokers writing concurrently never produce conflicting or duplicate offsets. Every partition's offset sequence remains strictly monotonic regardless of how many brokers are writing simultaneously. This per-partition atomicity allows Oxia to shard partition metadata across its cluster, enabling horizontal scaling of the metadata layer.
Step 4: Produce Response (Protocol Layer)
The broker returns a standard ProduceResponse containing the catalog-assigned offset. At this point, the record is durably stored in object storage, indexed in the Lakestream Catalog, and available for consumption through the Kafka Fetch protocol. The entire write path completes without any local disk I/O or inter-broker replication.
Concrete Example
Consider a producer sending 1,000 records to partition 0 of topic orders. The broker buffers these records alongside concurrent writes coming from other products to topics payments and events. After 250ms, the buffer -- containing data from all three topics -- is flushed as a single WAL object to S3. The broker then writes entry indexes to Oxia, which automatically assigns respective offsets to those 3 topics. Each entry index maps the offset range to the WAL object's storage location in S3, so any broker in the cluster can later locate and read these records by querying Oxia.
Request Pipelining
UFK supports multiple produce requests in-flight simultaneously. The broker does not block waiting for one write to complete before accepting the next request. Requests that arrive within the same flush interval are batched into a single object storage write, amortizing round-trip latency across all of them. This pipelining is key to achieving high throughput even with the inherent latency of object storage writes.
Data Compaction
As data accumulates, two things grow that require periodic maintenance: the number of entry index records in Oxia (one per write batch), and the number of WAL objects in object storage (containing mixed-topic data in row-oriented format). UFK addresses both through two complementary compaction processes.
Entry Index Compaction
Every write creates an entry index record in Oxia that maps a topic-partition offset range to an object-storage location. Over time, a high-throughput partition can accumulate millions of these small index records, making offset lookups slower and consuming Oxia's storage capacity.
Entry index compaction merges multiple small index records into fewer, larger ones. For example, if partition 0 of topic orders has accumulated 1,000 individual index records --- each covering a few hundred offsets from a single write batch --- compaction merges them into a handful of consolidated records covering broader offset ranges. The physical data in object storage is not touched during this process; only the Oxia metadata is reorganized. Oxia's atomic read-modify-write operations ensure that index records are merged safely --- no data is lost, no offset gaps are introduced, and concurrent reads continue to work correctly throughout the compaction.
Lakehouse Compaction: WAL to Parquet
WAL objects are optimized for write throughput: they are row-oriented, may contain data from multiple topics in the same object, and are not suitable for analytical queries. To enable stream-table duality --- reading the same data as both a Kafka stream and a lakehouse table --- the data must be reorganized into columnar Parquet format, with each compacted object containing data from only a single topic.
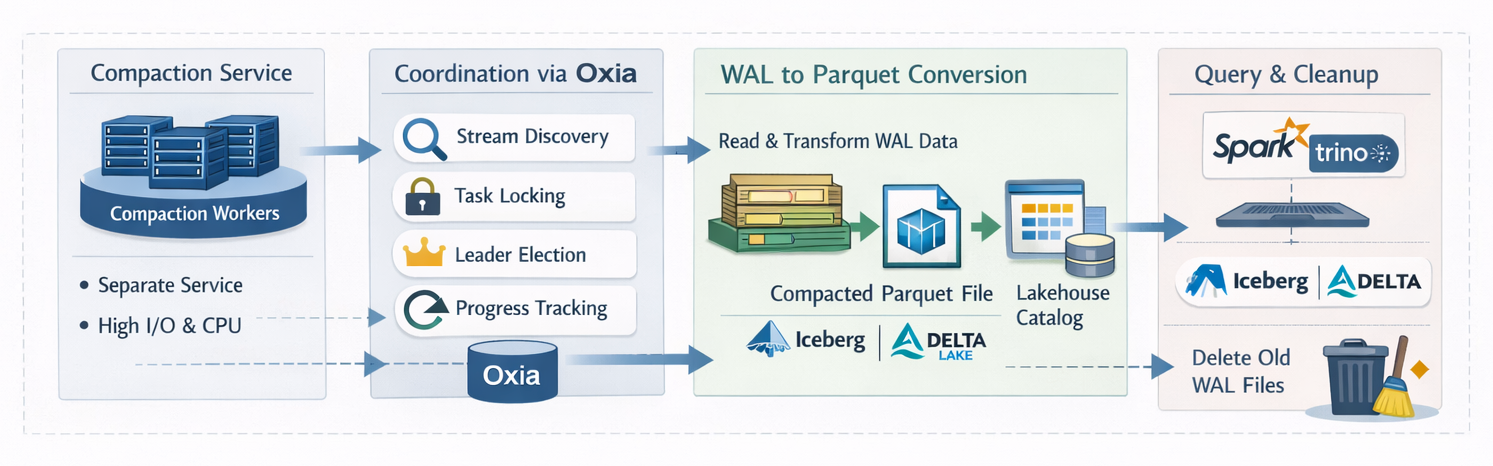
Figure 2. UFK data compaction flow
Separate Compaction Service
Lakehouse compaction runs as a separate service, independent of the Kafka brokers. This separation is a deliberate architectural choice: compaction is CPU and I/O intensive (reading row data, converting to columnar format, writing Parquet files), and running it on brokers would create contention with produce and fetch operations. The compaction service can be scaled independently --- more workers for higher throughput during peak hours, fewer during off-peak --- without affecting broker performance.
Distributed Coordination via the Lakestream Catalog
Multiple compaction workers coordinate through Oxia to ensure correctness and avoid duplicated work:
- Stream discovery: Workers query Oxia to discover which streams have un-compacted WAL data. Oxia tracks the compaction progress for each stream, so workers can quickly identify which partitions need attention.
- Task locking: Before compacting a stream partition, a worker acquires a distributed lock in Oxia. This prevents two workers from compacting the same partition simultaneously, which would produce duplicate Parquet files.
- Task coordination: Oxia's lease mechanism elects a coordinator among the compaction workers. The coordinator distributes compaction tasks across the available workers for balanced load distribution.
- Progress tracking: Each worker writes its compaction progress to Oxia at regular intervals. If a worker crashes mid-compaction, another worker can read the progress record, pick up the task, and resume where the failed worker left off rather than restarting from scratch.
The Full Compaction Lifecycle
The complete compaction lifecycle proceeds as follows:
- Discover un-compacted data across partitions
- Acquire a distributed lock for the target partition
- Read entry indexes from the Lakestream Catalog to identify WAL objects to compact
- Retrieve the WAL data from object storage
- Extract single-topic records from the multi-topic WAL objects
- Convert the extracted records to columnar Parquet format
- Write the Parquet files to the compacted storage tier
- Register the Parquet files via the Lakestream Catalog, which updates the linked Iceberg (or Delta) table metadata in the federated external catalog
- Update entry indexes in the Lakestream Catalog to point to the new Parquet locations
- Release the distributed lock
- Record progress for crash recovery
After Compaction
Once compaction completes, the same offsets that were previously served from WAL objects are now served from Parquet files. Kafka consumers see no difference whatsoever --- the data appears identical through the Fetch protocol. But the same data is now also queryable as an Iceberg or Delta table through standard SQL engines.
In production benchmarks at 5 GB/s sustained throughput, P99 compaction delay --- from WAL write to table visibility --- is under 5 seconds.
One write, two access patterns --- stream-table duality in action. This is the core value proposition of UFK's lakehouse integration.
Lakehouse access for disk-based topics. While the stream-table duality story above applies to cost-optimized (diskless) topics, latency-optimized (disk-based) topics can also be offloaded to lakehouse tables through the Ursa Storage Extension. In this mode, the compaction service reads from either disk segments or tiered storage segments and writes Parquet files to the lakehouse catalog, providing eventual lakehouse visibility for disk-based topics without impacting broker performance. This ensures that all topics in a UFK cluster, regardless of storage profile, can participate in the lakehouse.
WAL Cleanup
Once data has been compacted to Parquet and verified, the original WAL objects are deleted from object storage. There is no double-paying for storage --- you only store each record in one tier at a time.
Failure Handling
Distributed locks have a bounded TTL. If a compaction worker crashes, its lock expires automatically. Another worker detects the orphaned task, reads the progress recorded in the Lakestream Catalog, and resumes from where the failed worker left off. If a task fails repeatedly, it is quarantined and surfaced for operator investigation rather than blocking other compaction work.
The Read Path
The read path uses Ursa Storage's read API to resolve consumer offsets to physical locations via the Lakestream Catalog, then retrieves data from the appropriate storage tier. The consumer is completely unaware of whether its data comes from the in-memory cache, a WAL object, or a Parquet file.
Offset Resolution via the Lakestream Catalog
When a consumer requests data at a given offset, the broker queries the entry index in the Lakestream Catalog. The index reveals whether the requested data resides in a WAL object (recent, un-compacted data) or a Parquet file (compacted data). This resolution is entirely transparent to the consumer --- it doesn't know or care which tier serves its request.
Tiered Caching
UFK employs a tiered caching strategy to minimize object storage reads:
- In-memory cache: Recently written and recently read entries are cached in memory on the broker. This is the fast path for tailing consumers that are reading near the tip of the partition. The vast majority of reads for active consumers are served directly from cache without touching object storage.
- Object storage fallback: On a cache miss, the broker fetches data from the WAL object or Parquet file at the location recorded in the Lakestream Catalog. This path is used for backfill scenarios and historical reads where consumers are catching up from older offsets.
Historical and Backfill Reads
Historical reads on diskless topics are served directly from object storage (WAL objects or compacted Parquet files) without impacting the in-memory cache or the real-time write path. Because object storage provides massive read parallelism, multiple consumers can perform large backfills concurrently without degrading produce throughput or tailing-consumer latency. For latency-optimized (disk-based) topics, historical reads follow the standard Kafka path: local disk segments first, then tiered storage for older data.
Transparent WAL/Parquet Spanning
A single fetch request may need to source data from both tiers. For example, if a consumer requests offsets 5000--6000 and offsets 5000--5499 have been compacted to Parquet while 5500--6000 are still in a WAL object, the broker reads from both sources, assembles the records in order, and returns a single contiguous response. The consumer never knows the data came from two different storage formats.
Concrete Example
A consumer in group "analytics" fetches from orders partition 0 at offset 5000. The broker queries the Lakestream Catalog and finds that offsets 5000--5499 are in Parquet (compacted) and offsets 5500--5800 are in WAL. The broker reads both, assembles the response, and returns offsets 5000--5800 to the consumer. The consumer processes the batch and commits offset 5801 via __consumer_offsets --- exactly as it would with vanilla Kafka.
Prefetching
Sequential read patterns trigger background prefetching. While the consumer is processing the current batch, the broker retrieves the next batch in the background. This overlap of I/O and processing ensures the consumer never stalls waiting for data. The result is near-memory-speed throughput even when reading from remote object storage.
ListOffsets
The ListOffsets API queries the Lakestream Catalog for a partition's first and last entry indexes. The semantics are identical to vanilla Kafka. Tools like kafka-consumer-groups.sh and monitoring dashboards work without any modification.
Idempotent Producers
Kafka's idempotent producer protocol assigns a unique producer ID (PID) and sequence number per partition, allowing the broker to deduplicate retried produce requests.
UFK fully supports this protocol with one key difference in how state is persisted. UFK stores producer state snapshots to the Lakestream Catalog (backed by Oxia), keyed by (topicPartition, producerId). When a broker restarts, it loads producer state from the Lakestream Catalog rather than replaying the local log. This is actually an advantage over vanilla Kafka, where broker restart requires replaying potentially large log segments to reconstruct producer state.
If a crash occurs between sending an acknowledgment and persisting producer state, a replay mechanism reconstructs the state from entries committed by ManagedLedger to object storage. Deduplication remains correct across all failure scenarios.
Important: Transactions are NOT supported on diskless (cost-optimized profile) topics. Any attempt to use transactional producers on a diskless (Cost-Optimized) topic is rejected with INVALID_REQUEST. Transactions require atomic writes across partitions and a __transaction_state log that depends on local disk replication. However, idempotent producers (enable.idempotence=true without transactional.id) are fully supported.
What Stays the Same
A critical design goal of UFK is protocol-level compatibility with Apache Kafka. Here is what remains completely unchanged:
- Produce/Fetch protocol: Standard Kafka wire protocol. No client library changes required.
- Consumer groups: Group coordinator, assignment strategies (range, round-robin, sticky, cooperative-sticky), rebalancing, offset commit, and offset fetch all work identically.
- KRaft: Controller quorum, metadata log, and broker registration are identical to vanilla Kafka 4.0+.
- ListOffsets: Returns correct earliest and latest offsets for diskless partitions.
- Admin operations: CreateTopics, DeleteTopics, AlterConfigs, DescribeTopics, and other admin APIs work as expected.
- Client compatibility: Supports Kafka clients v0.9 and later --- the vast majority of all Kafka clients in production today.
- KIP-932 Queues: The shared-consumer-group model is fully supported.
From the client's perspective, UFK is Kafka. The storage engine has changed entirely, but the protocol surface is preserved.
Current Limitations
Transparency demands honesty about boundaries. Here are the current limitations of UFK's diskless (cost-optimized profile) topics:
- Transactional producers: NOT supported on diskless (cost-optimized profile) topics. Transactions require two-phase commit coordination through the __transaction_state log, which depends on local disk replication. Use disk-based (latency-optimized profile) topics for transactional workloads.
- Log compaction: cleanup.policy=compact is NOT supported on diskless topics. The equivalent functionality is achieved through external Parquet compaction --- periodic rather than continuous, but delivering the same end result of retaining only the latest value per key.
- Replication factor: Forced to 1 for diskless topics. Durability comes from object storage (S3 provides 3+ availability zone redundancy natively). This is an architectural choice reflecting the storage model, not a limitation to be fixed in a future release.
- Kafka Streams exactly-once: Kafka Streams applications using exactly-once semantics (EOS) require transactions, which are not supported on diskless (cost-optimized profile) topics. For stateful Kafka Streams processing with EOS, use disk-based (latency-optimized profile) topics. At-least-once processing with Kafka Streams works on either topic profile.
- Internal topics: __consumer_offsets and __transaction_state remain on local disk, requiring approximately 10 GB per broker. These use standard Kafka replication and compaction. This is small relative to user data volumes.
- KRaft metadata logs: Controller nodes need local disk for the metadata log, replicated via Raft. Typically under 1 GB.
Migration and In-Place Upgrade
Because UFK is a fork of Apache Kafka --- not a reimplementation --- it supports in-place rolling upgrades from existing Apache Kafka clusters. An operator can replace Kafka broker images (e.g., apache-kafka:4.1.0 → ufk:4.2.0) in a standard rolling restart. All existing Kafka state is preserved: KRaft metadata logs, local log segments, tiered storage data, consumer group offsets, and topic configurations. Existing disk-based topics continue to function identically. This has been validated with the Strimzi Kubernetes operator.
To enable cost-optimized (diskless) topics, operators must additionally deploy Oxia as the metadata store for Ursa Storage. Once Oxia is available, new topics can be created with ursa.storage.enable=true, or existing topics can be migrated to diskless storage. Rolling back to vanilla Kafka is safe --- operators lose only the diskless topics created while running UFK; all disk-based topics and cluster state are unaffected.
Critically, existing Kafka clients do not need to be upgraded or modified. Because UFK is built from the Apache Kafka codebase, it is the source of truth for protocol behavior. Every undocumented protocol edge case, every backward-compatibility guarantee that the Apache Kafka community maintains, is inherited by construction. This is a structural advantage over Kafka-compatible reimplementations, which must reverse-engineer protocol behaviors that are only fully specified by the Kafka source code itself.
Coming Up: Stream-Table Duality
We've now traced the complete data lifecycle through UFK: from produce request through buffering and batching, to durable storage in object storage, through metadata indexing in the Lakestream Catalog, into compaction from row-oriented WAL to columnar Parquet, and back out through the read path to consumers. Every step eliminates local disk dependency while preserving complete Kafka protocol compatibility.
The write path replaces leader writes and follower replication with a single object storage write. Compaction transforms streaming WAL data into queryable Parquet --- one write, two access patterns. The read path transparently spans both tiers, with caching and prefetching that deliver near-memory-speed performance.
In Part 3, we'll look at how UFK achieves stream-table duality --- how every Kafka topic simultaneously becomes a queryable lakehouse table through the Lakestream architecture. We'll cover the catalog integration, query engine compatibility, and what it means to unify streaming and batch in a single system.
This post is part of the UFK Deep Dive series. Read Part 1: "Storage Abstraction and Leaderless Architecture" for the foundation, and stay tuned for Part 3: "Stream-Table Duality and the Lakestream Architecture."





