Data Streaming Summit 2026 — Registration is Open!
Register Now >Real-Time Data Pipelines That Replace Batch ETL
Revolutionizing Streaming Data Pipelines with the Power of Real-Time Insights
Organizations across industries use StreamNative
• CHALLENGES
Why Batch ETL Breaks Down
Batch ETL Fragility
Overnight batch jobs fail silently, miss SLAs, and leave downstream systems with stale data. Recovery means re-running entire pipelines.
Connector Sprawl
Managing separate Kafka Connect clusters, Pulsar IO instances, and custom glue code across teams. Each connector is another operational burden.
Data Inconsistency
Batch windows create gaps. Different systems see different versions of the truth depending on when their last extract ran.
Scaling Bottlenecks
Traditional ETL tools weren't built for real-time volume. Scaling means bigger batch windows or expensive infrastructure upgrades.
• THE WAY OUT
The Game-Changing Paradigm: Streaming-Augmented Lakehouse (SAL)
The Streaming-Augmented Lakehouse is the next evolution in data architecture, blending the best of both worlds: lakehouses and real-time data streaming.
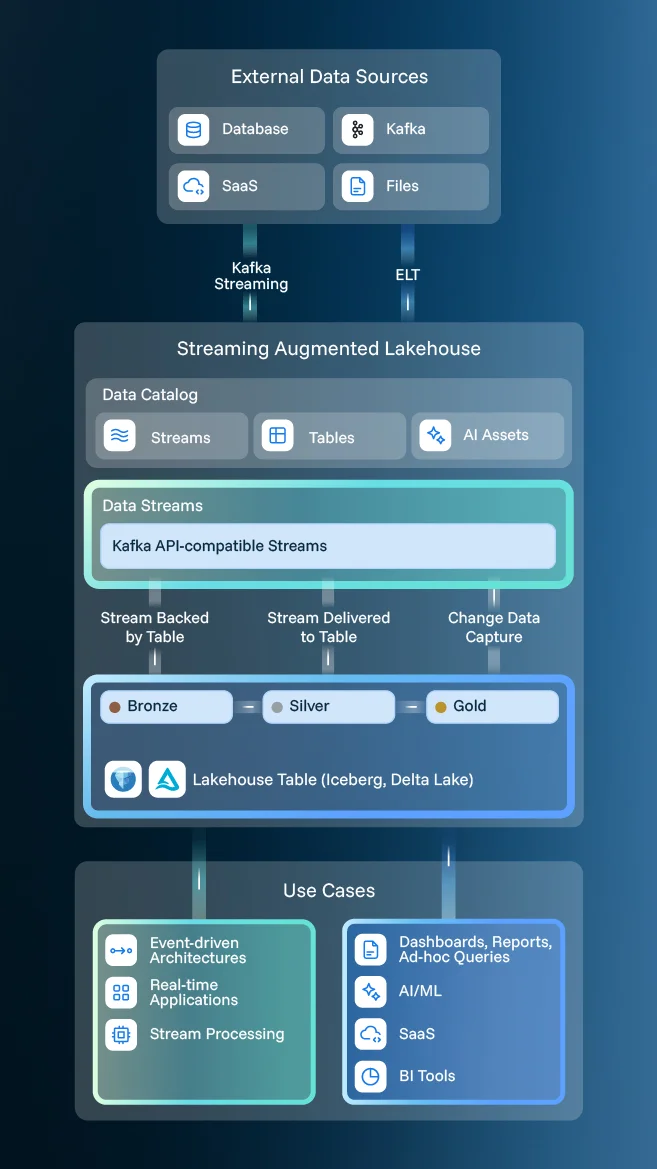
Continuous Data Movement
Every event in Kafka or Pulsar simultaneously lands as a row in Iceberg or Delta tables. No staging, no connectors.
Unified Connector Interface
Iceberg and Delta Lake tables work with Databricks, Snowflake, Trino, and Spark. No format lock-in.
Self-Healing Pipelines
BI dashboards and ML pipelines see fresh data within seconds, not hours.
• RELATED TOOL
Flink Managed Services
Run Apache Flink on StreamNative's fully managed service — tightly integrated with your streaming pipelines for real-time transformations, enrichment, and analytics.
Fully Managed
Fully managed Apache Flink operations for real-time stream processing
Automatic Scaling
Automatic Scaling, monitoring, and optimizations of Flink workloads
Seamless Integration
StreamNative's Pulsar-based ecosystem and SAL architecture enhance the power of your streaming data pipelines
• RESOURCES
Learn More About Streaming Data Pipeline



Start Building Data Pipelines Today
- Replace batch ETL with real-time streaming pipelines.
- Unify Kafka Connect and Pulsar IO with Universal Connect.
- Migrate from self-managed Kafka with zero downtime.