
We were excited to announce the release of catalog integration with Databricks Unity Catalog, along with a cost benchmark report comparing Ursa with other leader-based data streaming engines in the past few weeks. These efforts underscore our commitment to our vision of the Stream-Augmented Lakehouse.
What is Shift-Left?
Following its acquisition of Flink provider Immerok, Confluent introduced the concept of “Shift-Left” for data integration. Inspired by the software testing approach with the same name, this approach called for both data processing and governance to be performed closer to the source of the data. According to them, “Data lakes have turned into data swamps.”, and the shift-left approach is a more efficient and cost-effective solution to this problem.
Shift Left in data integration is a concept derived from software engineering principles, specifically Shift Left Testing. In this context, testing is performed earlier in the development lifecycle to improve software quality, accelerate time-to-market, and identify issues earlier.
Similarly, Shift Left in data integration involves performing data processing and governance closer to the source of data generation. By cleaning and processing data earlier in the data lifecycle, organizations can ensure that downstream consumers, such as cloud data warehouses, data lakes, and lakehouses, receive a single source of well-defined and well-formatted data.
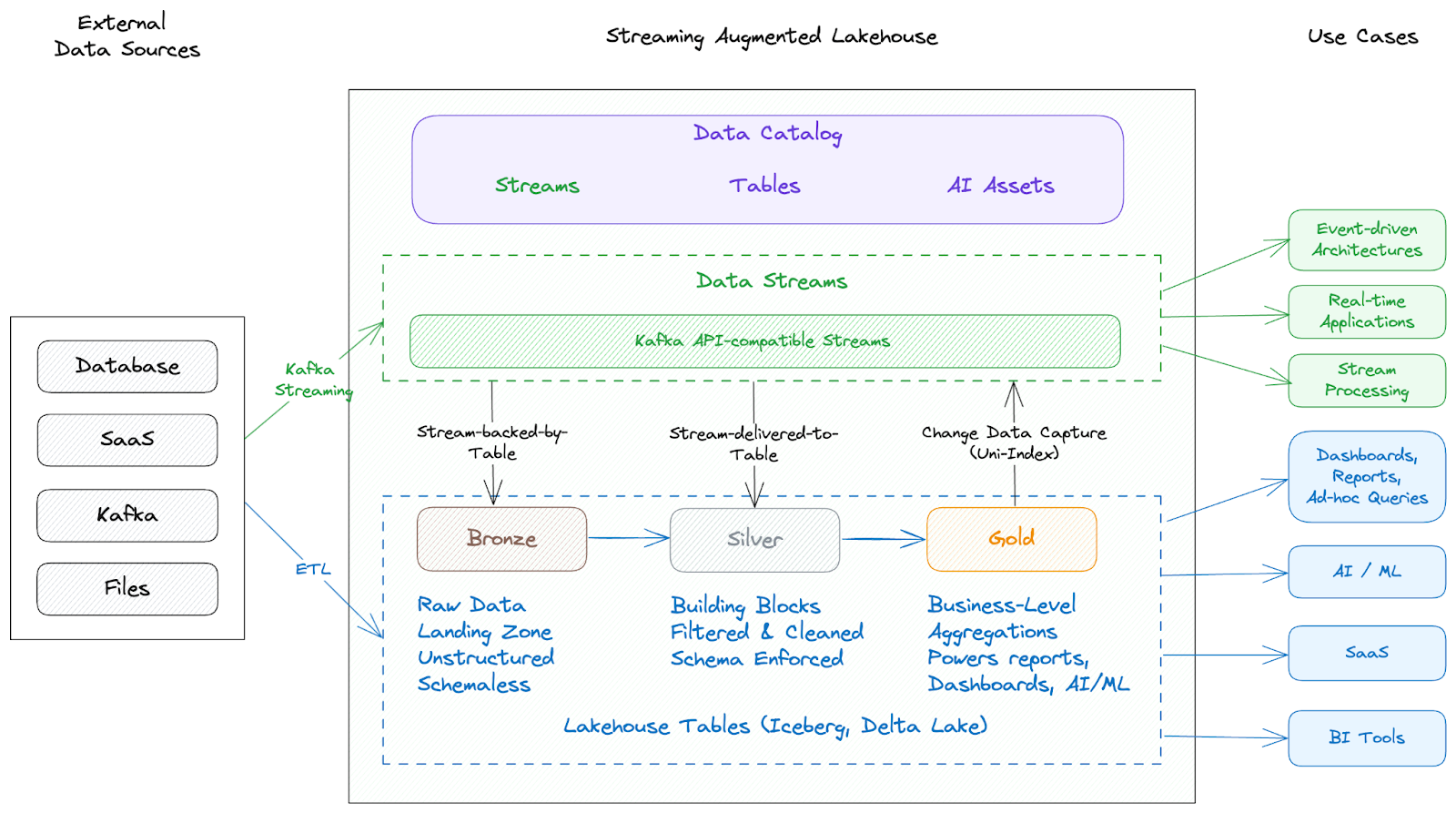
Among other things, the “shift-left” embraces the concept of medallion tiers for data based on data quality, as originally envisioned in the Lakehouse architecture. However, it shifts the bronze and silver datasets along with the necessary data cleansing, processing and governance to the data streaming platform rather than the Lakehouse, which hosts only the gold datasets.
While bringing schema enforcement, validation, and governance closer to data sources promises numerous benefits, such as improved data quality and reduced costs, it's important to weigh these benefits against the costs of adopting a streaming-first approach when it comes to your data before fully re-architecting your analytical platform to incorporate a streaming platform.
Lakehouse-First Streaming Architecture
While we agree that Shift-Left is an important data strategy for moving toward real-time streaming architectures, we have a different viewpoint on it. In our opinion, the foundation for real-time Gen AI applications must combine data streaming and lakehouses. This synergy is what we refer to as Streaming-Augmented Lakehouse (SAL).
Unlike Shift-Left, which aims to move entirely from batch and lakehouse architectures to real-time streaming, SAL acknowledges that lakehouses serve as the foundation where all data lands but emphasizes augmenting lakehouses with real-time data streams for greater flexibility, low-latency insights, and adaptability.
The Traditional Lakehouse Architecture
In 2021, the Databrick’s founders, in conjunction with colleagues from Stanford and UC Berkeley introduced the Lakehouse architectural pattern to address some of the shortcomings of the Data Lake model. It allows organizations to use low-cost storage for all types of data, while still providing data management features including transactions, and low-latency query performance.
At its core, the Lakehouse architecture relies on a metadata layer like Delta Lake, which integrates transactional capabilities, versioning, and additional data structures into files in an open format such as Apache Parquet. This enables seamless querying of the system through a range of APIs and engines, as evidenced by the sheer number of vendors who offer Lakehouse products and services. In our view, the Lakehouse paradigm elegantly distills the modern data stack into three core pillars, each of which plays a crucial role in enabling efficient and accessible data management:
- Format: This pillar establishes a standardized specification and protocol for data access. Essentially, it acts as an API for your data, built upon open standards. This standardization ensures that data can be consistently interpreted and accessed by various tools and systems within the Lakehouse ecosystem.
- Catalog: This pillar provides a unified governance mechanism for managing table metadata and data access. It serves as an API for metadata and data governance, ensuring that data is properly organized, described, and secured. The catalog allows users to discover and understand the data available within the Lakehouse, as well as control who can access and modify it.
- Engines: This pillar encompasses the various engines that interact directly with data and metadata. These engines leverage the open lakehouse formats and data catalogs to query and access data efficiently. They may include query engines, machine learning libraries, and other data processing tools that operate directly on the data stored within the Lakehouse.
By adhering to these three pillars, the Lakehouse architecture provides a robust and scalable foundation for data-driven applications and analytics. The combination of standardized data formats, unified metadata management, and flexible data access engines allows organizations to effectively store, manage, and analyze large volumes of data from diverse sources.
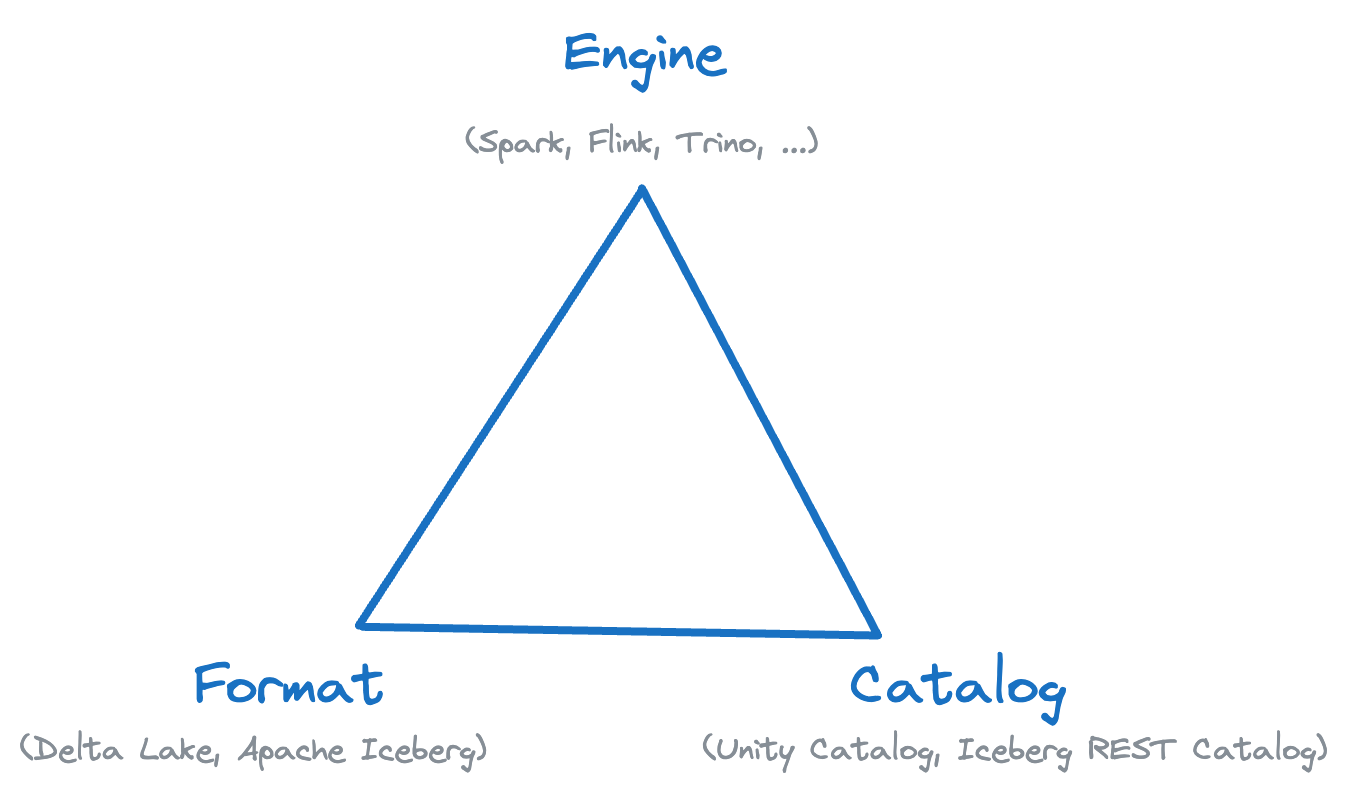
This Format-Catalog-Engine (FCE) framework’s open format ensures that all components within the Data Lakehouse are pluggable, eliminating vendor lock-in. We feel that standardizing on open data formats with metadata and governance via data catalogs is the proper approach for architecting modern data platforms, including streaming platforms.
Why Data Streaming Needs a Lakehouse-First Architecture
The data streaming ecosystem has historically been siloed, with applications and services interacting with data streaming engines via wire protocols like Apache Kafka and Apache Pulsar. This creates a separation between streaming and lakehouse environments. Bridging this gap has necessitated custom connectors and integrations, leading to challenges like costly data transfers, wasted resources, complex data transformations, and increased risk of errors.
However, with the rising adoption of open lakehouse formats for data storage and data catalogs for metadata governance, it is essential that data streaming aligns with this trend.
In an age of data explosion and AI models/applications demanding ever-more data, the ingestion engine will become increasingly critical. This is why the industry needs a solution of collecting data that is both cost-effective and aligned with open data formats supported by the Lakehouse architecture.
Traditionally, data streaming architectures have been built around leader-based paradigms. However, as data scales, it is evident that streaming needs to align with the same architectural principles that power modern Lakehouses. This means we need to rethink data streaming architectures to fit into the Format-Catalog-Engine (FCE) framework.
From a practical perspective, streaming data platforms should adopt a lakehouse-first approach by storing and accessing data in open formats such as Iceberg or Delta Lake. Data streams should be managed or integrated with catalogs like Databricks Unity Catalog or Iceberg REST Catalog to ensure proper organization and governance. This approach eliminates reliance on proprietary storage layers, enabling greater flexibility and interoperability.
Ursa: a Lakehouse-First Data Streaming Engine
We built Ursa using the Format-Catalog-Engine (FCE) framework as its architectural principle. With Lakehouse-First Thinking, Ursa supports data-intensive streaming and ingestion workloads in a highly cost-efficient way while providing native data catalog integration for unified metadata and governance.
We have shared additional architectural insights in our recent blog post—be sure to check it out for more details.
- Cut Kafka Costs by 95%: The Power of Leaderless Architecture and Lakehouse Storage
- The Evolution of Log Storage in Modern Data Streaming Platforms
- Ursa: Reimagine Apache Kafka for the Cost-Conscious Data Streaming
The outcome of adopting Lakehouse-First Architecture in Ursa is clear:
- Unification: Stream and batch data processing converge seamlessly.
- Interoperability: Any engine can interact with streaming data using the same open formats and catalogs.
- Cost-Efficiency: By leveraging object storage and lakehouse-native storage, we cut streaming infrastructure costs by 95% compared to traditional streaming engines. (Check out our benchmark blog post!)
- Future-Proofing: As more data systems adopt the FCE principle, Ursa ensures long-term compatibility with open data ecosystems.
Using a Lakehouse-First data streaming engine like Ursa Engine, you can augment your existing lakehouse to create a Streaming-Augmented Lakehouse—bringing real-time capabilities to your data platform to create a uniform data foundation for your organization.
The Future of Data Systems is Lakehouse-First
Looking ahead, I expect more and more data systems (“engines”) to be built using the FCE framework with Lakehouse-First Thinking. This shift is not just about data lakes or warehouses—it’s about rearchitecting the entire data stack to be truly open, interoperable, and cost-efficient in the age of AI.
Data streaming is evolving, and Ursa is at the forefront of this transformation. Join us as we redefine real-time data infrastructure with Lakehouse-First Thinking.





