
UFK Deep Dive Series — Part 1 of 3: How UFK extends Kafka with a diskless, leaderless,lakehouse-native storage architecture
Introduction
If you're running Kafka at scale, you already know the numbers: 60--80% of your infrastructure spend goes to cross-AZ replication. Half your provisioned disk sits empty. And somewhere, a Kafka Connect pipeline is failing at 2 AM---duplicating every byte just to land Kafka data in your lakehouse.
In our launch posts---From Streams to Lakestreams_ and Ursa For Kafka---we introduced the Lakestream paradigm and Ursa's place in it. This is the first in a three-part deep dive into how Ursa-For-Kafka (UFK) actually works under the hood.
Let's start with the basics. UFK is a fork of Apache Kafka 4.2+ that extends Kafka's local-disk storage with Ursa, a cloud-native stream storage engine built on object storage. This is not a proxy sitting in front of Kafka. It is not a compatibility layer translating Kafka protocol calls into something else. UFK is Kafka---the same request handlers, the same group coordinator, the same KRaft controller---with a lakehouse-native storage option alongside its traditional disk-based storage. Thousands of lines of Kafka code for protocol handling, group management, and admin operations continue to run unchanged.
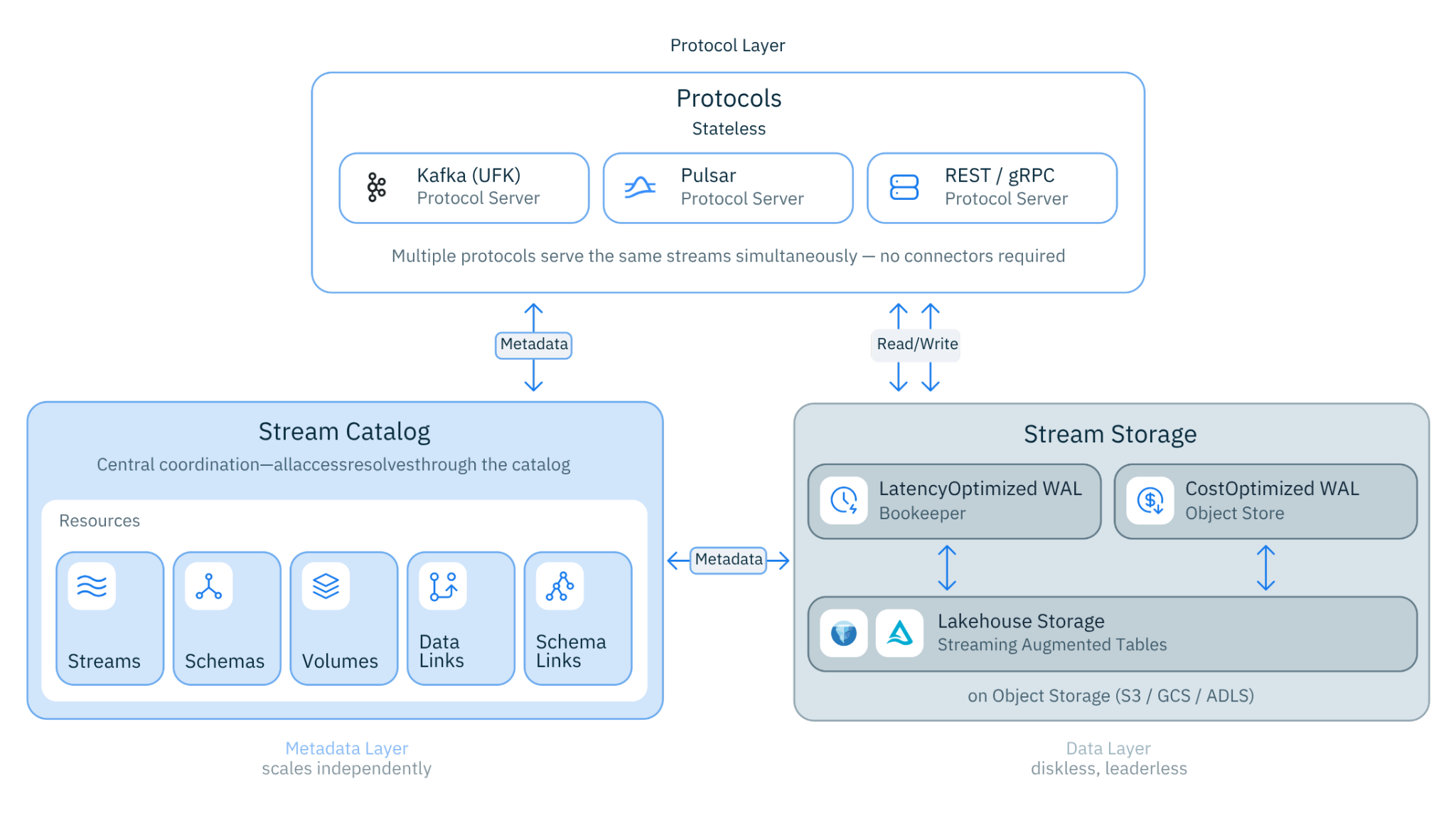
Figure 1. Lakestream Architecture
UFK is built on the Lakestream architecture, which separates concerns into three layers: the Data Layer (Ursa Storage on object storage), the Metadata Layer (the Lakestream Catalog, backed by Oxia), and the Protocol Layer (stateless Kafka brokers that translate wire protocol to storage operations). While this series focuses on Kafka, the same Lakestream foundation already powers Apache Pulsar workloads on StreamNative Cloud---StreamNative is a 'both, not either' company. This post focuses on the Data and Metadata layers. Part 3 will cover how all three layers come together for stream-table duality.
In this post, we'll cover two foundational topics: why Kafka's current architecture creates the problems it does, and how UFK's storage abstraction and leaderless broker design solve them. Parts 2 and 3 will trace the complete data flow and cover the operational model.
The Kafka Problem
Kafka is the de facto standard for event streaming. It is also, for many organizations, one of the most expensive and operationally demanding pieces of infrastructure they run. The root causes are structural---baked into Kafka's architecture---and no amount of tuning eliminates them. Let's walk through each one.
Cross-AZ Replication Cost
Kafka's durability model is built on replication. The default replication factor is 3, meaning every message your producers send gets written to three different brokers, typically spread across three availability zones. This is the right thing to do for durability---if one AZ goes down, two copies remain. But the cost is brutal.
Every replicated write crosses an AZ boundary, and cloud providers charge for cross-AZ data transfer. At AWS's rate of $0.01 per GB per direction, the math adds up quickly. In production benchmarks, UFK reduces total infrastructure cost from $52,000/month to $4,200/month at 5 GB/s sustained throughput---a 92% reduction. That gives you a sense of how much replication-related costs dominate at scale.
This isn't an edge case. For organizations running Kafka at scale, 60--80% of total Kafka TCO is replication-related infrastructure. The data itself might be worth pennies per gigabyte to store on S3, but Kafka's replication protocol turns it into dollars.
ISR Operational Burden
Kafka tracks which replicas are keeping up with the leader through the In-Sync Replica (ISR) set. When a broker falls behind---due to a slow disk, a GC pause, a network partition, or just a spike in traffic---it drops out of the ISR. If enough replicas drop, the partition becomes under-replicated.
This is where the operational pain starts. An under-replicated partition forces a choice: do you allow writes to continue with reduced durability (risking data loss if another failure occurs), or do you block producers until the ISR recovers (risking unavailability)? There's no good answer. The operator is stuck choosing between two bad outcomes, often at 3 AM.
ISR management is a constant source of operational toil. Brokers join and leave the ISR for all kinds of transient reasons. Each event requires monitoring, alerting, and often manual intervention. Organizations with large Kafka deployments typically dedicate one or more full-time engineers solely to Kafka operations---not building features, not shipping product, just keeping Kafka healthy.
Disk Provisioning Waste
Because Kafka stores data on local disks (or EBS volumes), operators must provision storage ahead of time. And because running out of disk space means dropped messages or broker crashes, they provision conservatively---for worst-case scenarios: seasonal traffic spikes, retention policy changes, onboarding of new topics from teams that haven't even asked yet.
The result is predictable: average disk utilization sits at 30--50%. Half the storage you're paying for is empty headroom. EBS volumes are charged whether they're full or not, and EBS pricing can reach $0.50 per GiB-month for high-IOPS volumes. Because resizing EBS volumes is slow and disruptive, operators tend to over-provision even further as a hedge. It's a tax on being cautious---and in infrastructure, being cautious is the right thing to do. More fundamentally, EBS volumes were designed to lift and shift legacy on-premises software into the cloud, not for cloud-native architectures. As retention requirements grow, the pain compounds: provisioned disk costs scale linearly with retention period.
The Connector Jungle
Kafka stores data in its own binary log format, optimized for sequential reads and writes. That's great for streaming consumers, but useless for analytics. If you want to query your Kafka data with SQL, train a model on it, or join it with data from other systems, you need to get it out of Kafka and into a format the analytics world understands.
So operators deploy Kafka Connect with Iceberg or Parquet sink connectors. Or they use Confluent's Tableflow. Or they write custom consumer applications that read from Kafka and write to S3. Each of these approaches has its own failure modes: connector lag, schema evolution mismatches, exactly-once delivery complexity, and operational overhead that compounds with every new topic.
The fundamental issue is that data gets written twice---once to Kafka's local disks for streaming consumers, and once to the lakehouse for analytical consumers. This doubles your storage costs and introduces minutes of latency between when a record is produced to Kafka and when it's queryable in the lakehouse. For many use cases, that gap is the difference between real-time and "kind-of-real-time."
UFK Storage Abstraction
At the core of UFK is a storage abstraction introduced at the replica management layer. This is where Kafka decides how to persist data for each partition. In vanilla Kafka, this always means the local log manager---write segment files to disk, manage indexes, handle retention. UFK introduces a branch point.
When a topic is created with ursa.storage.enable=true, all storage operations for that topic route through Ursa Storage instead of the local log manager. The decision is per-topic, which means a single UFK cluster can host both disk-based (latency-optimized profile) and diskless (cost-optimized profile) topics simultaneously1. This is critical for incremental migration. You don't flip a switch and move everything at once---you migrate topic by topic, validating as you go.
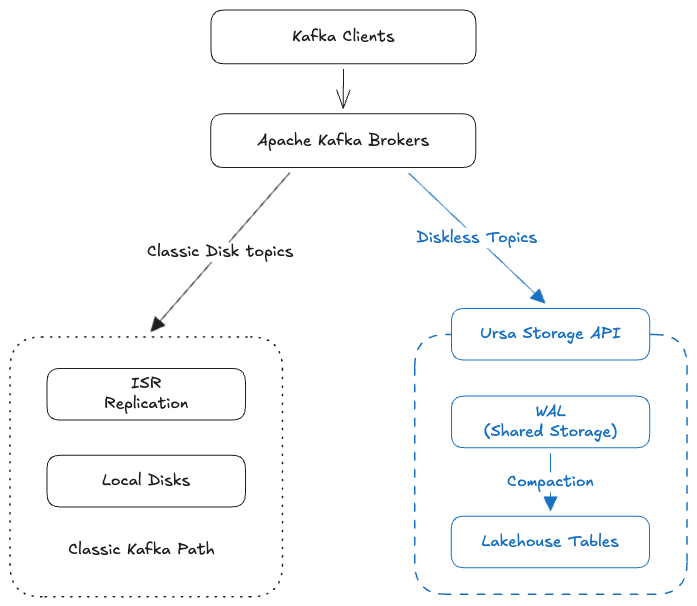
Figure 2. How we extend Kafka to support diskless topics using Ursa storage
Topic Profiles: Latency-Optimized and Cost-Optimized
UFK supports two topic profiles in the same cluster1:
- Latency-Optimized Profile (disk-based): Traditional local-disk storage with single-digit milliseconds produces latency. Full Kafka feature set---transactions, log compaction, Kafka Streams exactly-once semantics. Ideal for real-time transaction processing, fraud detection, and event-driven microservices where every millisecond matters.
- Cost-Optimized Profile (diskless/lakehouse-native): Lakehouse-native storage via Ursa with sub-second produce latency and up to 95% cost reduction. Every topic is simultaneously a live event stream and an Iceberg/Delta table. Ideal for IoT telemetry, lakehouse pipelines, clickstream analytics, and high-volume streaming where cost efficiency is the priority.
UFK supports traditional disk-based topics (latency-optimized profile) and diskless topics (cost-optimized profile) in the same cluster; operators choose per topic, enabling incremental migration without separate clusters. The recommended adoption path: start with high-volume, latency-relaxed topics (your biggest cost drivers), validate the behavior, then expand to more topics at your own pace. No big-bang migration required.
The rest of this series focuses primarily on Cost-Optimized (diskless) topics---the architectural innovation that makes UFK distinctive. Latency-Optimized topics behave identically to traditional Apache Kafka.
The abstraction preserves Kafka's contract completely. Produce requests return offsets. Fetch requests return record batches. ListOffsets returns the earliest and latest offsets. Every component above the storage layer---the request handler, the group coordinator, KRaft metadata management---is entirely unaware that the storage backend has changed. This is what makes UFK a true Kafka fork rather than a reimplementation: the Kafka code that handles protocol details, group management, and admin operations continues to run unchanged.
Ursa Storage: The Data Layer
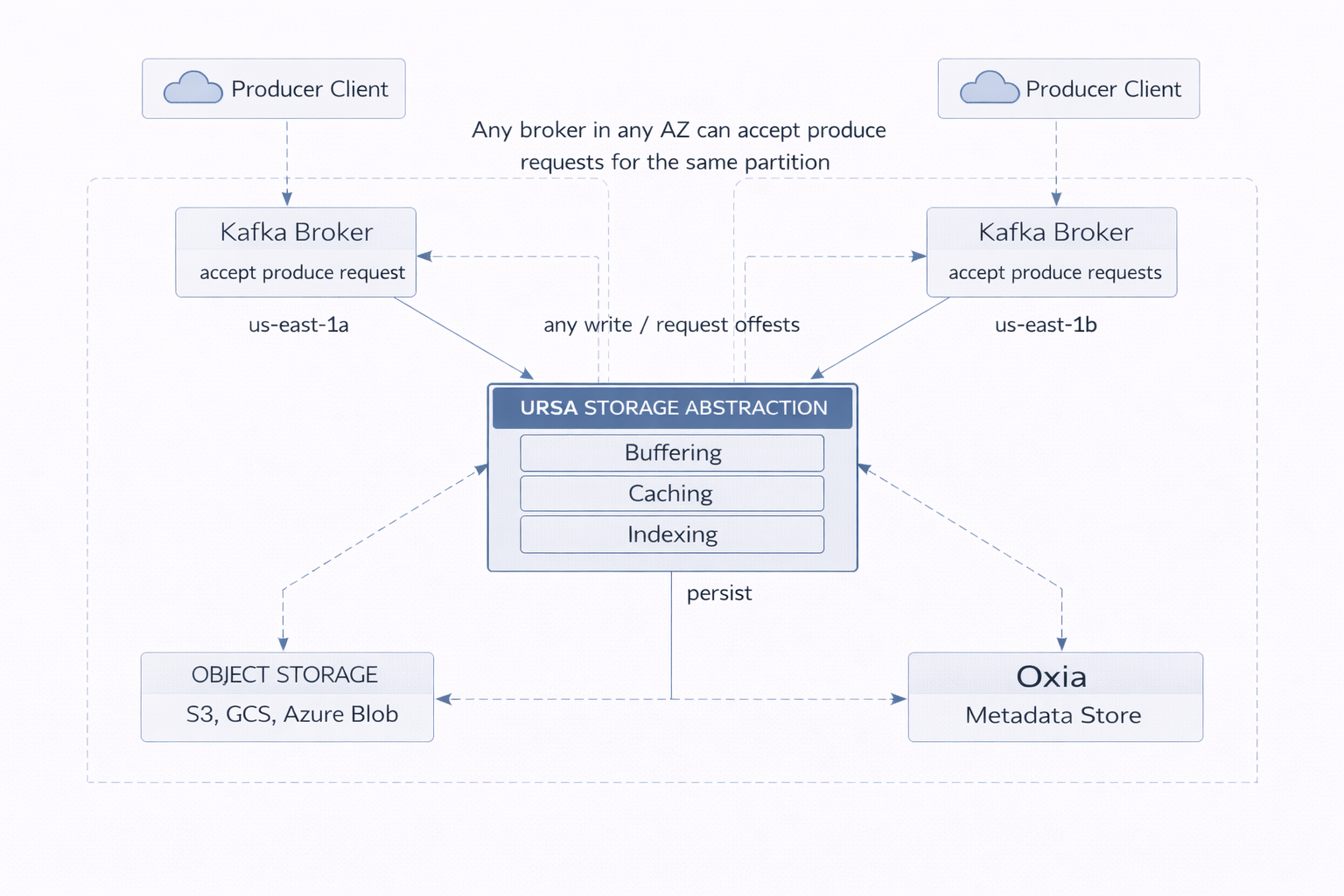
Figure 3. UFK Architecture
Ursa Storage is an embedded Java library running within each broker process (not a separate system). It implements the Data Layer of the Lakestream architecture. It is organized into three tiers, each with a distinct role in the data lifecycle:
Storage API tier. The top-level interface exposes operations for append, read, trim, and lifecycle management. All operations are asynchronous, returning completable futures. Broker threads are never blocked waiting on remote I/O---a critical design choice when your storage backend is object storage with millisecond-scale latencies instead of microsecond-scale local disk.
WAL tier (Write-Ahead Log). The write-ahead log tier lives on object storage---S3, GCS, or Azure Blob Storage. WAL objects are optimized for write throughput rather than read efficiency. A single WAL object may contain data from multiple topics, batched together to minimize the number of object storage API calls. This batching is essential for cost control: object storage charges per API call, so fewer, larger writes are dramatically cheaper than many small ones.
Compacted Data tier. A background compaction process continuously reorganizes WAL data into per-topic columnar Parquet files. These compacted files enable column pruning, predicate pushdown, and high compression ratios. This is where UFK eliminates the connector jungle: the same data that serves streaming consumers is automatically organized into the format the lakehouse expects. No Kafka Connect, no sink connectors, no dual writes.
Lakestream Catalog
The Lakestream Catalog is the Metadata Layer of the Lakestream architecture---the single source of truth for every stream's state. It tracks entry indexes (offset-to-physical-location mappings), stream properties, compaction tasks, and offset assignment. The Lakestream Catalog is backed by Oxia, a distributed key-value store purpose-built for metadata coordination. The detailed design of Oxia, including its sharding model and consistency guarantees, is described in the Ursa VLDB paper. Every storage operation in UFK involves two things: a data write to object storage (Data Layer) and a metadata operation on the Lakestream Catalog.
The Lakestream Catalog tracks several critical pieces of state:
- Entry indexes: the mapping from logical offset to physical location in object storage
- Stream properties: topic and partition metadata
- Compaction tasks: work items for the background compaction process
- Offset assignment: the atomic generation of new offsets for incoming records
When a single WAL object contains data from multiple partitions, each partition receives its own independent metadata update in the Lakestream Catalog. This per-partition granularity means that offset assignment, index creation, and compaction operations for one partition never block or interfere with another, enabling horizontal scaling of the metadata layer alongside data operations. The catalog handles offset assignment through Oxia's atomic key operations, which is the mechanism that makes leaderless writes possible. More on that next.
Leaderless Broker Assignment
In vanilla Kafka, the controller assigns a leader for every partition, brokers register ISR changes, and clients discover leaders via metadata requests. This leader-based model is essential when durability depends on replication---the leader is the single source of truth for offset assignment, and the ISR mechanism ensures replicas stay consistent.
UFK eliminates the leader concept entirely for diskless partitions. Since durability is handled by object storage (which provides its own replication and durability guarantees), there's no need for broker-level replication, and therefore no need for a leader to coordinate it.
How Offset Assignment Works Without a Leader
Offset generation is handled by the Lakestream Catalog (backed by Oxia), not by any broker. When a broker receives a produce request for a diskless partition, it writes the data to object storage and then the Lakestream Catalog atomically assigns the next offset (via Oxia's atomic key operations). Multiple brokers can write to the same partition concurrently---the Lakestream Catalog serializes offset assignment through Oxia's atomic key operations, ensuring that offsets are globally unique and monotonically increasing.
This is a fundamental architectural shift. In Kafka, the leader serializes writes. In UFK, the Lakestream Catalog serializes offset assignment while data writes happen in parallel. The broker is no longer a bottleneck for any individual partition.
Partition Distribution
Because any broker can serve any partition, UFK distributes partitions across all available brokers in the cluster. The current implementation uses a deterministic hash for this assignment, but the specific algorithm is an implementation choice, not an architectural requirement---it can support alternative strategies. No central controller or assignment protocol is needed: each broker can compute the partition mapping locally, and when the broker set changes, every node recomputes it independently.
Zone-Aware Routing
Because any broker can serve any partition, UFK can make routing decisions based on network topology rather than replica placement. Specifically, UFK selects a broker in the client's local availability zone. A producer running in us-east-1a sends to a broker in us-east-1a. No cross-AZ data transfer, no cross-AZ charges.
Compare this to vanilla Kafka, where a partition's leader might be in any AZ, and the producer has no choice but to send data wherever the leader happens to be. UFK's zone-aware routing directly addresses the cross-AZ cost problem described earlier.
Broker Scaling
When brokers are added or removed, the partition assignment naturally redistributes across the new broker set. Because no broker holds local partition state for diskless topics --- all data is in object storage and all metadata is in the Lakestream Catalog --- there is no data migration, no partition reassignment delay, and no rebalancing. New brokers begin serving immediately upon joining the cluster.
This is fundamentally different from vanilla Kafka, where adding a broker triggers partition reassignment that can take hours for large clusters as data is copied between brokers. In UFK, the same scaling operation completes in seconds because brokers carry no local partition data for cost-optimized topics.
ISR Is Gone
For diskless partitions, the ISR mechanism is bypassed entirely. There are no ISR expansion or shrinkage events, no under-replicated partition alerts, and no preferred leader elections. The concept doesn't apply---there are no replicas to track, because durability is provided by object storage, not by broker-level replication.
This eliminates an entire class of operational incidents. No more 3 AM pages about under-replicated partitions. No more choosing between data loss and unavailability. The durability guarantee is delegated to S3 (or GCS, or Azure Blob), which provides eleven nines of durability without any operator intervention.
This architecture---leaderless, diskless, lakehouse-native---was validated at 5 GB/s sustained throughput in production benchmarks.
Failure Handling
When a UFK broker fails, clients simply connect to another broker. There's no partition reassignment to wait for, no local state to recover, no ISR rebalancing. The new broker can serve the partition immediately because all state lives in the Lakestream Catalog and object storage---the broker itself is stateless.
Think about what this means for operations. In vanilla Kafka, a broker failure triggers a cascade: the controller reassigns leaders, followers need to catch up, ISR sets need to stabilize, and until all of that completes, some partitions may be unavailable or degraded. In UFK, a broker failure means clients reconnect to the next broker, and traffic continues. Recovery time is measured in seconds, not minutes.
The operational model shifts fundamentally: from "monitor replica health across N brokers per partition" to "ensure enough brokers are running to serve the workload." The former requires deep Kafka expertise and constant vigilance. The latter is standard capacity management that any platform team already knows how to do.
Getting to UFK
UFK offers two paths for existing Kafka deployments:
- In-place upgrade (for Kafka 4.0+ deployments): Because UFK is a fork of Apache Kafka --- not a reimplementation --- it supports in-place rolling upgrades. An operator can replace Kafka broker images (e.g., apache-kafka:4.1.0 → ufk:4.2.0) in a standard rolling restart. All existing Kafka state is preserved: KRaft metadata logs, local log segments, tiered storage data, consumer group offsets, and topic configurations. This has been validated with the Strimzi Kubernetes operator. To enable diskless topics, operators must additionally deploy Oxia as the metadata store for Ursa Storage. Rolling back to vanilla Kafka is safe --- operators lose only the diskless topics created while running UFK; all disk-based topics and cluster state are unaffected. Critically, existing Kafka clients do not need to be upgraded or modified.
- Universal Linking (for any Kafka deployment): Zero-downtime migration from Confluent, Amazon MSK, Redpanda, or self-managed Kafka. Universal Linking replicates topics into UFK with continuous synchronization at the object storage layer---not through the Kafka protocol---eliminating cross-AZ replication costs even during migration.
What's Next
In this post, we've covered the structural problems with Kafka's storage and replication model and how UFK addresses them through its storage abstraction and leaderless broker architecture. The storage abstraction lets UFK extend local disks with object storage while preserving full Kafka protocol compatibility. The leaderless design eliminates cross-AZ replication, ISR management, and the operational complexity that comes with leader-based coordination.
In Part 2, we'll trace the complete data flow through UFK---the write path from producer to object storage, the read path from fetch request to record batch, and the compaction pipeline that transforms WAL objects into queryable Parquet files. We'll show exactly how a produce request becomes a durable, queryable record without any connectors in between.
Stay tuned.
Notes
1. As part of Public Preview, StreamNative Cloud offers cost-optimized (diskless) and latency-optimized (disk-based) profiles at cluster-level. Topic-level storage profile can be configured via CLI.





