
Let me say something that might surprise you: We are a Kafka company, too.
Yes, us. StreamNative. Founded by the creators of Apache Pulsar. The Pulsar company. The "not Kafka" company.
And no, this isn't an April Fools' joke. (Although the timing is... convenient.)
The truth is, we've been on a journey that none of us fully anticipated when we started. That journey has gifted us a lot of experience that helped form the following conviction: we should operate a native Kafka service.
What in 2019 may have sounded to us like defeat - offering a competitor system as a first-class product - no longer holds true. In 2026 the majority of engineers no longer define Kafka as a system, they define it as a protocol.
Supporting another protocol seamlessly is an expression of a platform's strength. Let me explain:
The Power of Open Protocols
There's a pattern in data infrastructure that's worth understanding before we tell our story: when you integrate with an open protocol or format, you inherit an entire ecosystem overnight.
Consider what happened with open table formats. When Apache Iceberg and Delta Lake emerged as open standards for lakehouse storage, something remarkable followed. Any system that wrote data in these formats --- regardless of who built it --- instantly became queryable from Snowflake, Databricks, Spark, Trino, and dozens of other analytics engines (growing by the day). No partnerships required. No custom connectors. The format was the integration.
We experienced this firsthand ourselves. When our storage engine, Ursa, began writing directly to Iceberg and Delta Lake formats on object storage, we didn't need to build connectors to every analytics platform. Our streaming data was simply there --- immediately discoverable and queryable from any engine that reads open table formats. The open format did the work for us.
The same principle applies to streaming protocols. The Kafka wire protocol has become the lingua franca of data streaming --- not just because of Apache Kafka itself, but because dozens of systems collectively made the protocol ubiquitous. Every cloud service, every vendor, every connector, every monitoring tool, every tutorial speaks Kafka. The protocol has become the TCP/IP of streaming.
When you attach yourself to an open protocol, your product benefits automatically. That insight --- validated by our experience with lakehouse formats and now with the Kafka protocol --- is the thread that runs through everything we're about to share.
How We Got Here
We started StreamNative a few years ago with Apache Pulsar -- a system we built at Yahoo to handle the massive scale of unified messaging and data streaming. Pulsar had the right architecture from the start: compute-storage separation, multi-tenancy, multi-protocol support. It was designed for the cloud before "cloud-native" was a buzzword.
And enterprises loved it. They deployed Pulsar for their most mission-critical workloads -- the ones where downtime isn't an option and data loss is unthinkable.
But along the way, we noticed a pattern. A very consistent pattern.
Most of the world lives in a split world. Organizations run their mission-critical messaging and queuing workloads on Pulsar -- and their data streaming pipelines on Kafka. For better or for worse, the Kafka protocol had become the default --- not because Kafka was architecturally superior for those use cases, but because the sheer weight of ecosystem adoption made it the path of least resistance. Every vendor, every tool, every connector, every tutorial -- Kafka.
We have a long history of making StreamNative Kafka-friendly and are no strangers to the API. In 2020, we released KoP -- Kafka-on-Pulsar --- an open-source protocol handler that let Pulsar brokers speak the Kafka wire protocol. At the time, we weren't conceding anything --- we were hedging our bets, meeting users where they were. Then came KSN -- Kafka-on-StreamNative --- a more deeply integrated, production-grade Kafka compatibility layer. Each iteration brought us closer to full Kafka compatibility. Customers could bring their Kafka workloads to our platform without changing a line of code.
Over time, the picture became clear. It wasn't that Kafka-the-system beat Pulsar. It was that the Kafka protocol had won --- propelled not by Confluent nor the open source project alone, but by the dozens of Kafka-compatible systems that collectively made the wire protocol the industry standard.
Then we built Ursa -- a lakehouse-native streaming storage engine that writes directly to object storage in open formats like Iceberg and Delta Lake. The engine didn't require local disk, didn't require leader elections and didn't incur any cross-AZ replication costs. It happened to be really, really good at running Kafka workloads -- up to 95% cheaper, in fact. Good enough to win the VLDB 2025 Best Industry Paper award, beating submissions from Databricks, Meta, Alibaba, and many others.
And then we did something nobody expected -- including us.
Introducing Ursa For Kafka
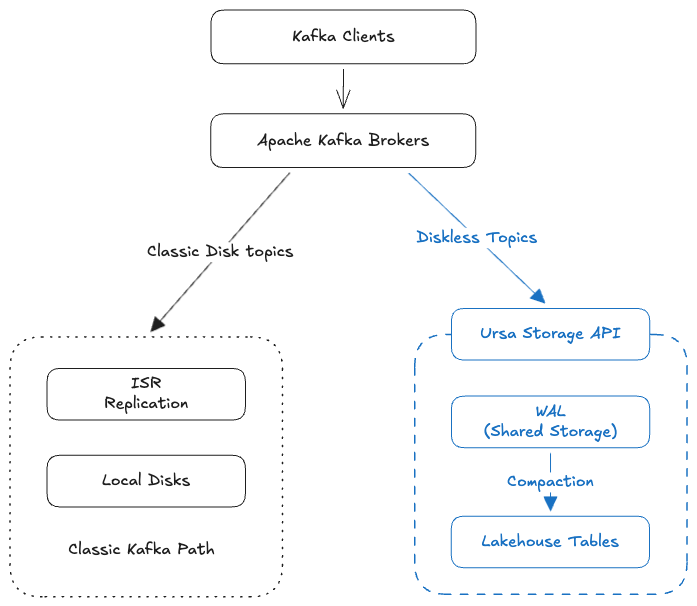
We took Apache Kafka 4.2, extended its storage layer with Ursa, and built a native Kafka service - Ursa For Kafka (UFK).
Not Kafka-compatible. Not Kafka-on-something. Native Kafka with its classic storage engine, AND with an additional lakehouse engine underneath.
Why build on Native Kafka?
A natural question. Why build directly on the Apache Kafka codebase instead of continuing to build protocol-compatible systems on top of different storage engines?
Because we tried that --- and learned exactly why it doesn't work long-term.
We spent years building Kafka protocol compatibility layers. Each generation got closer, but we kept hitting the same fundamental problem: the Kafka wire protocol is not just a specification --- it's a living system with undocumented behaviors, implicit client-broker contracts, and edge cases that no spec captures. Kafka has 89 live request families today, and when you account for backwards-compatible versions, you're looking at hundreds of protocol permutations to implement and maintain. Every time upstream Kafka evolved, we had to catch up --- and every new version meant new surprises hiding in the gaps between what the protocol says and what clients actually expect. We'll share the full catalog of war stories in an upcoming post, but the lesson was unambiguous: reimplementing the Kafka protocol is a treadmill with no finish line.
Building directly on native Apache Kafka changes the equation entirely. UFK inherits perfect protocol compatibility by simply using the same code. When upstream Kafka introduces new APIs, changes behavior or fixes a bug, we inherit it (for free). No reverse-engineering, no guessing at undocumented semantics, no playing catch-up. Our extension is scoped to the storage layer --- the Kafka protocol handling, client interactions, and API surface remain the real thing.
This is not a one-off April Fools experiment. It's a high-conviction strategic bet. We are extending native Apache Kafka with a lakestream foundation --- and we plan to open source this work and invest in it for the long term.
What does it mean in practice?
It's just Kafka with the potential for richer topic storage options.
- Your Kafka topics are simultaneously lakehouse tables -- because Ursa writes directly to Iceberg and Delta Lake on object storage. No expensive SSDs. No connectors. No ETL. No duplicate storage costs.
- No cross-AZ replication costs -- because Ursa's leaderless architecture eliminates the single largest cost driver in cloud streaming.
- No connectors to get data into your lakehouse -- because the data is already there. Produce to a Kafka topic, query it as an Iceberg table from Spark, Snowflake, or Databricks.
- Your Kafka clients work with zero changes -- because it IS the literal Kafka codebase. Every client, every tool, every connector you already use just work
We didn't replace Kafka. We gave it a lakehouse foundation.
UFK extends Kafka -- it doesn't replace it. You don't have to go all-in. Move some topics to lakehouse-native storage while keeping others on traditional disk-based storage -- in the same cluster. Support both cost-optimized (lakehouse-native, up to 95% cheaper) and latency-optimized (disk-based, single-digit ms) topic profiles side by side. Move topics between profiles as your needs evolve. Roll out at your own pace. Start with your highest-volume, latency-relaxed topics -- your biggest cost drivers. Expand when you're ready. No big bang migration required.
So... What About Pulsar?
Fair question. If you've followed us for any length of time, Pulsar is probably what you associate with StreamNative. And here's the honest answer:
Pulsar isn't going anywhere --- it's central to who we are. Pulsar continues to power the most mission-critical, business-impacting workloads for customers worldwide. Organizations choose Pulsar for its multi-tenancy, its ability to handle both point-to-point queuing and ordered log streaming in a single platform, its decoupled architecture and its battle-tested reliability -- those workloads continue to run, and we continue to invest in them.
But here's what Pulsar taught us -- and this is the part that matters most:
The future of streaming isn't about which protocol wins. It's about what's underneath the protocol.
Pulsar showed us that compute-storage separation changes everything. That decoupling the broker from its storage unlocks a fundamentally different operational model --- one where brokers are stateless, elastic, and cheap. We've been operating stateless, storage-separated streaming at scale for over seven years through Pulsar --- long before "diskless Kafka" became a trend. That operational experience is baked into every layer of Ursa and UFK.
But Ursa taught us something else, too --- something even more powerful. When we built Ursa and moved streaming data directly into open lakehouse formats, we discovered that lakehouse-native storage doesn't just save money. It completely dissolves the boundary between streaming and analytics, unifying it all into a single, queryable system.
Ursa For Kafka (UFK) will show that any streaming protocol -- even the world's most popular one -- can benefit from that foundation.
Pulsar remains at the heart of StreamNative --- it's the foundation that taught us everything about cloud-native streaming. But we are not a Pulsar company. We're not a Kafka company either. There are no such companies anymore - what truly matters is what is behind the protocol.
Instead, we define ourselves as a Lakestream company. We ship a streaming-meets-lakehouse solution that now speaks both protocols natively. UFK is how we bring our lakestream vision to the Kafka world.
Try It
UFK will be available as a Native Kafka service on StreamNative Cloud. It will enter Limited Public Preview soon.
Here's the deal: anyone who enrolls now will receive $1,000 in credits to use exclusively for Kafka clusters on StreamNative Cloud. No strings attached. Just sign up, spin up a Native Kafka cluster, point your existing Kafka clients at it, and see what happens.
What you'll find:
- Your existing Kafka clients, tools, and workflows -- they all just work with best-in-class support. Zero code changes.
- Your Kafka topics -- they're now also Iceberg and Delta Lake tables, queryable from Spark, Trino, Snowflake, and Databricks.
- Your infrastructure bill, transformed -- it's about to get a lot smaller.
If you use Pulsar, we are a Pulsar company. If you use Kafka, we're a Kafka company, too. Come see what that means.
Next week, we'll share more stories behind UFK. Stay tuned.




